







1 贝叶斯公式
P(A|B) = P(B|A)*P(A)/P(B)
事件A发生的情况下事件B发生的概率 = B发生的情况下A发生的概率*B发生的概率/A发生的概率
2 处理二值化(经过二值化后的数据)
代码:
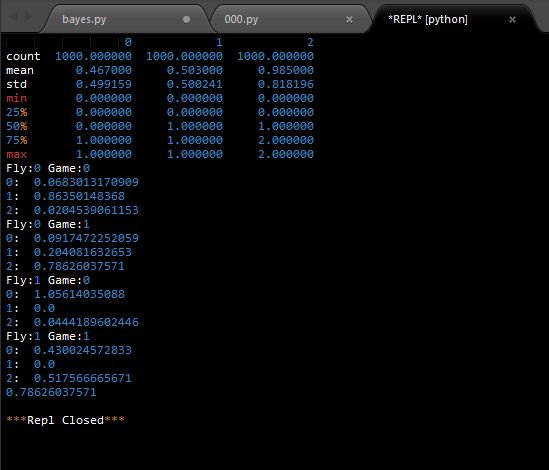
df = pd.read_csv('DATA/Fly_0_1.csv',header =None)
print(df.describe())
index_all = len(df)
Fly_s = df[0]
Game_s = df[1]
Table_s = df[2]
for x in range(2):
for y in range(2):
print('Fly:%s Game:%s'%(x,y))
for z in range(3):
FG = len( df[ (Fly_s == x) & (Game_s == y) ])/index_all
Fly = len( df[ (Fly_s == x) & (Table_s == z) ])/len(df[Table_s == z])
Game = len( df[ (Game_s == y) & (Table_s == z) ])/len(df[Table_s == z])
Table = Table_s[Table_s==z].count()/index_all
print('%s: '%z,Fly*Game*Table/FG)
代码解释:
# 读取二值化后的数据
df = pd.read_csv('DATA/Fly_0_1.csv',header =None)
# 打印出数据详情
print(df.describe())
# 数据的行数
index_all = len(df)
# 第一行数据
Fly_s = df[0]
# 第二行数据
Game_s = df[1]
# 第三行数据
Table_s = df[2]
for x in range(2):
for y in range(2):
print('Fly:%s Game:%s'%(x,y))
# 上面的代码是列举每个Fly 和 Game
# 总共为 00 01 10 11 四种
for z in range(3):
# z 表示对应的三种标签 0(didntLike) 1(smallDose) 2(largeDose)
# 标签 z 发生的情况下Fly == x 发生的概率 注意后面除以的是Table == z 的行数而不是全部行数len(df)
Fly = len( df[ (Fly_s == x) & (Table_s == z) ])/len(df[Table_s == z])
# 标签Z发生的情况下Game发生的概率
Game = len( df[ (Game_s == y) & (Table_s == z) ])/len(df[Table_s == z])
# 该标签发生的概率(无其他前提条件)
Table = Table_s[Table_s==z].count()/index_all
# 无其他前提条件下 Fly Game 发生的概率
FG = len( df[ (Fly_s == x) & (Game_s == y) ])/index_all
print('%s: '%z,Fly*Game*Table/FG)
# Fly*Game*Table/FG
# 贝叶斯公式 P(A|B) = P(B|A)*P(A)/P(B)
# 此处 P(B|A) 即某标签发生的情况下Fly Game 发生的概率 简化为Fly*Game
# P(A) 即Table 无其他前提条件下 改标签发生的概率
# P(B) 即无其他前提条件下 Fly Game 发生的概率 即为 FG3 这里 我举个例子
# 这里我们举个例子: Fly ==0 Game == 1 情况下 属于标签 2(largeDose)的概率:
# 贝叶斯公式 P(A|B) = P(B|A)*P(A)/P(B)
# P(B|A) ==Fly * Game
Fly = len( df[ (Fly_s == 0) & (Table_s == 2) ])/len(df[Table_s == 2])
Game = len( df[ (Game_s == 1) & (Table_s == 2) ])/len(df[Table_s == 2])
# P(A) == Table
Table = Table_s[Table_s==2].count()/index_all
# P(B) = FG
FG = len( df[ (Fly_s == 0) & (Game_s == 1) ])/index_all
# 因此 Fly == 0 Game == 1 情况下 属于标签 2(largeDose)的概率为:
print(Fly*Game*Table/FG)全部代码:
import time
import numpy as np
import pandas as pd
df = pd.read_csv('DATA/Fly_0_1.csv',header =None)
print(df.describe())
index_all = len(df)
Fly_s = df[0]
Game_s = df[1]
Table_s = df[2]
for x in range(2):
for y in range(2):
print('Fly:%s Game:%s'%(x,y))
for z in range(3):
FG = len( df[ (Fly_s == x) & (Game_s == y) ])/index_all
Fly = len( df[ (Fly_s == x) & (Table_s == z) ])/len(df[Table_s == z])
Game = len( df[ (Game_s == y) & (Table_s == z) ])/len(df[Table_s == z])
Table = Table_s[Table_s==z].count()/index_all
print('%s: '%z,Fly*Game*Table/FG)
# 这里我们举个例子: Fly ==0 Game == 1 情况下 属于标签 2(largeDose)的概率:
# 贝叶斯公式 P(A|B) = P(B|A)*P(A)/P(B)
# P(B|A) ==Fly * Game
Fly = len( df[ (Fly_s == 0) & (Table_s == 2) ])/len(df[Table_s == 2])
Game = len( df[ (Game_s == 1) & (Table_s == 2) ])/len(df[Table_s == 2])
# P(A) == Table
Table = Table_s[Table_s==2].count()/index_all
# P(B) = FG
FG = len( df[ (Fly_s == 0) & (Game_s == 1) ])/index_all
# 因此 Fly == 0 Game == 1 情况下 属于标签 2(largeDose)的概率为:
print(Fly*Game*Table/FG)
# P(X|Y) = (Nc + MP)/(N + M) 这样不会出现概率为0 的情况
# Nc表示总体中出现N的次数
# M表示等效样本容量的常数,这里用出现的两种情况(yes|no) 赋值 2
# P表示先验概率,即在没有其它前提下的概率 为 0.5 (yes|no)
# N表示样本总容量















 5390
5390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









