







 本文通过Scrapy爬取了酷安网6000余款App信息,分析了评分、下载量、体积等指标,揭示了各分类下的优秀App。发现大部分App下载量低于10万,而高评分App数量占比较大。通过数据筛选,找出了系统工具、社交聊天、资讯阅读等多个类别下的优质软件,推荐了如RE管理器、静读天下等App。
本文通过Scrapy爬取了酷安网6000余款App信息,分析了评分、下载量、体积等指标,揭示了各分类下的优秀App。发现大部分App下载量低于10万,而高评分App数量占比较大。通过数据筛选,找出了系统工具、社交聊天、资讯阅读等多个类别下的优质软件,推荐了如RE管理器、静读天下等App。
欢迎关注天善智能,我们是专注于商业智能BI,人工智能AI,大数据分析与挖掘领域的垂直社区,学习,问答、求职一站式搞定!
对商业智能BI、大数据分析挖掘、机器学习,python,R等数据领域感兴趣的同学加微信:tstoutiao,并注明消息来源,邀请你进入数据爱好者交流群,数据爱好者们都在这儿。
作者: 苏克1900
公众号:第2大脑

摘要:如今移动互联网越来越发达,各式各样的 App 层出不穷,也就产生了优劣之分,相比于普通 App,我们肯定愿意去使用那些良心佳软,但去发现这些 App 并不太容易,本文使用 Scrapy 框架爬取了著名应用下载市场「酷安网」上的 6000 余款 App,通过分析,发现了各个类别领域下的佼佼者,这些 App 堪称真正的良心之作,使用它们将会给你带来全新的手机使用体验。
1. 分析背景
1.1. 为什么选择酷安
如果说 GitHub 是程序员的天堂,那么酷安则是手机 App 爱好者们(别称「搞机」爱好者)的天堂,相比于那些传统的手机应用下载市场,酷安有三点特别之处:
第一、可以搜索下载到各种神器、佳软,其他应用下载市场几乎很难找得到。比如之前的文章中说过的终端桌面「Aris」、安卓最强阅读器「静读天下」、RSS 阅读器 「Feedme」 等。
第二、可以找到很多 App 的破解版。我们提倡「为好东西付费」,但是有些 App 很蛋疼,比如「百度网盘」,在这里面就可以找到很多 App 的破解版。
第三、可以找到 App 的历史版本。很多人喜欢用最新版本的 App,一有更新就马上升级,但是现在很多 App 越来越功利、越更新越臃肿、广告满天飞,倒不如回归本源,使用体积小巧、功能精简、无广告的早期版本。
作为一名 App 爱好者,我在酷安上发现了很多不错的 App,越用越感觉自己知道的仅仅是冰山一角,便想扒一扒这个网站上到底有多少好东西,手动一个个去找肯定是不现实了,自然想到最好的方法——用爬虫来解决,为了实现此目的,最近就学习了一下 Scrapy 爬虫框架,爬取了该网 6000 款左右的 App,通过分析,找到了不同领域下的精品 App,下面我们就来一探究竟。
1.2. 分析内容
总体分析 6000 款 App 的评分、下载量、体积等指标。
根据日常使用功能场景,将 App 划分为:系统工具、资讯阅读、社交娱乐等 10 大类别,筛选出每个类别下的精品 App。
1.3. 分析工具
Python
Scrapy
MongoDB
Pyecharts
Matplotlib
2. 数据抓取
由于酷安手机端 App 设置了反扒措施,使用 Charles 尝试后发现无法抓包, 暂退而求其次,使用 Scrapy 抓取网页端的 App 信息。抓取时期截止到 2018 年 11 月 23日,共计 6086 款 App,共抓取 了 8 个字段信息:App 名称、下载量、评分、评分人数、评论数、关注人数、体积、App 分类标签。
2.1. 目标网站分析
这是我们要抓取的 目标网页,点击翻页可以发现两点有用的信息:
每页显示了 10 条 App 信息,一共有610页,也就是 6100 个左右的 App 。
网页请求是 GET 形式,URL 只有一个页数递增参数,构造翻页非常简单。
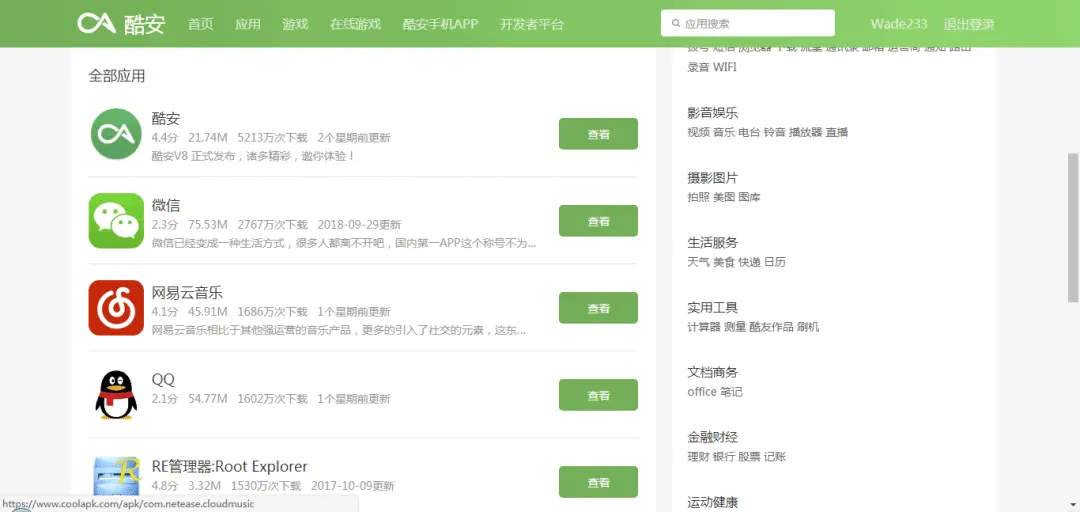
接下来,我们来看看选择抓取哪些信息,可以看到,主页面内显示了 App 名称、下载量、评分等信息,我们再点击 App 图标进入详情页,可以看到提供了更齐全的信息,包括:分类标签、评分人数、关注人数等。由于,我们后续需要对 App 进行分类筛选,故分类标签很有用,所以这里我们选择进入每个 App 主页抓取所需信息指标。
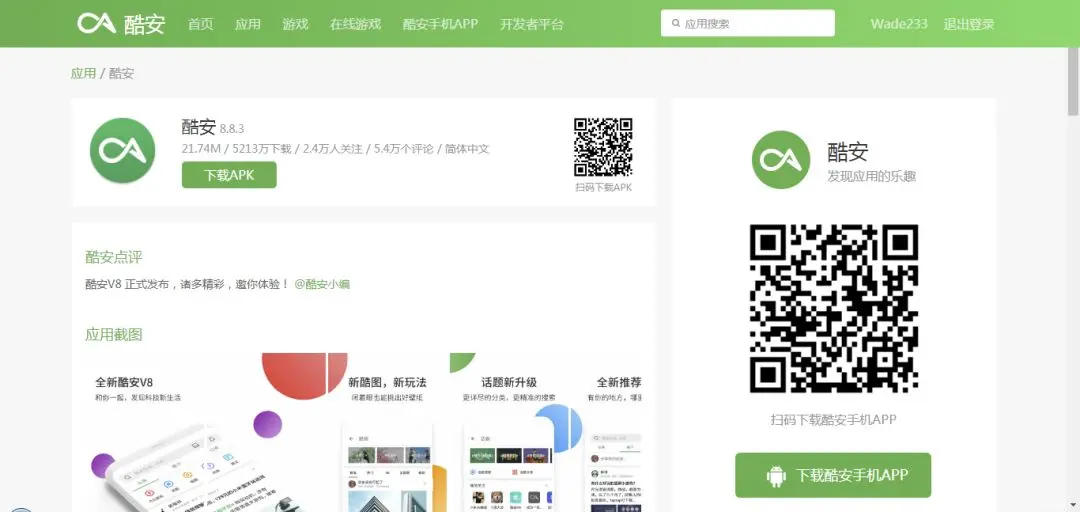
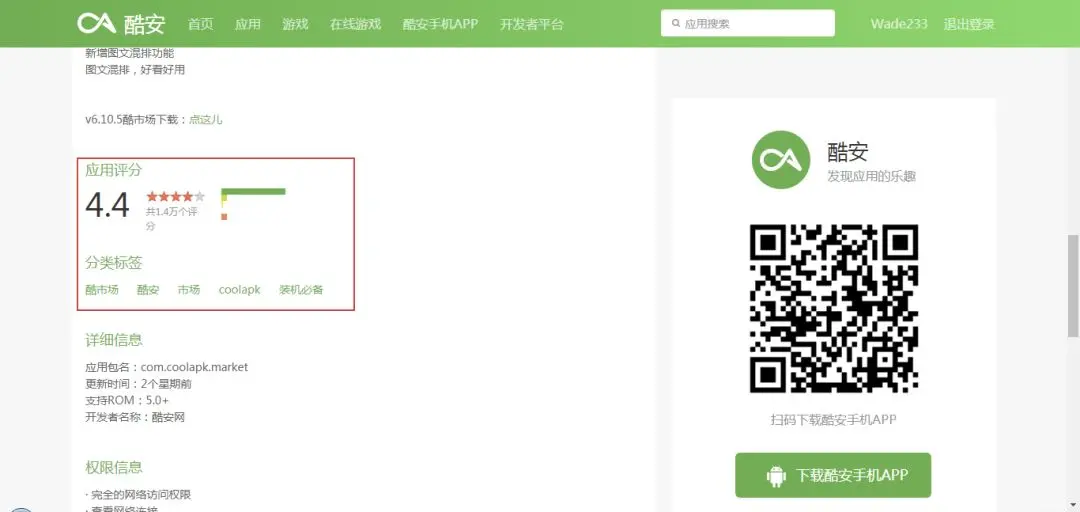
通过上述分析,我们就可以确定抓取流程了,首先遍历主页面 ,抓取 10 个 App 的详情页 URL,然后详情页再抓取每个 App 的指标,如此遍历下来,我们需要抓取 6000 个左右网页内容,抓取工作量不算小,所以,我们接下来尝试使用 Scrapy 框架进行抓取。
2.2. Scrapy 框架介绍
介绍 Scrapy 框架之前,我们先回忆一下 Pyspider 框架,我们之前使用它爬取了虎嗅网 5 万篇文章,它是由国内大神编写的一个爬虫利器, Github Star 超过 10K,但是它的整体功能还是相对单薄一些,还有比它更强大的框架么?有的,就是这里要说的 Scrapy 框架,Github Star 超过 30K,是Python 爬虫界使用最广泛的爬虫框架,玩爬虫这个框架必须得会。
网上关于 Scrapy 的官方文档和教程很多,这里罗列几个。
Scrapy 中文文档
崔庆才的 Scrapy 专栏
Scrapy 爬拉勾
Scrapy 爬豆瓣电影
Scrapy 框架相对于 Pyspider 相对要复杂一些,有不同的处理模块,项目文件也由好几个程序组成,不同的爬虫模块需要放在不同的程序中去,所以刚开始入门会觉得程序七零八散,容易把人搞晕,建议采取以下思路快速入门 Scrapy:
首先,快速过一下上面的参考教程,了解 Scrapy 的爬虫逻辑和各程序的用途与配合。
接着,看上面两个实操案例,熟悉在 Scrapy 中怎么写爬虫。
最后,找个自己感兴趣的网站作为爬虫项目,遇到不懂的就看教程或者 Google。
这样的学习路径是比较快速而有效的,比一直抠教程不动手要好很多。下面,我们就以酷安网为例,用 Scrapy 来爬取一下。
2.3. 抓取数据
首先要安装好 Scrapy 框架,如果是 Windwos 系统,且已经安装了 Anaconda,那么安装 Scrapy 框架就非常简单,只需打开 Anaconda Prompt 命令窗口,输入下面一句命令即可,会自动帮我们安装好 Scrapy 所有需要安装和依赖的库。
1conda pip scrapy
2.3.1. 创建项目
接着,我们需要创建一个爬虫项目,所以我们先从根目录切换到需要放置项目的工作路径,比如我这里设置的存放路径为:E:\my_Python\training\kuan,接着继续输入下面一行代码即可创建 kuan 爬虫项目:
1# 切换工作路径
2e:
3cd E:\my_Python\training\kuan
4# 生成项目
5scrapy startproject kuspider
执行上面的命令后,就会生成一个名为 kuan 的 scrapy 爬虫项目,包含以下几个文件:
1scrapy. cfg# Scrapy 部署时的配置文件
2kuan# 项目的模块,需要从这里引入
3_init__.py
4items.py# 定义爬取的数据结构
5middlewares.py# Middlewares 中间件
6pipelines.py# 数据管道文件,可用于后续存储
7settings.py# 配置文件
8spiders# 爬取主程序文件夹
9_init_.py
下面,我们需要再 spiders 文件夹中创建一个爬取主程序:kuan.py,接着运行下面两行命令即可:
1cd kuan# 进入刚才生成的 kuan 项目文件夹
2scrapy genspider kuan www.coolapk.com# 生成爬虫主程序文件 kuan.py
2.3.2. 声明 item
项目文件创建好以后,我们就可以开始写爬虫程序了。
首先,需要在 items.py 文件中,预先定义好要爬取的字段信息名称,如下所示:
1classKuanItem(scrapy.Item):
2# define the fields for your item here like:
3name = scrapy.Field()
4volume = scrapy.Field()
5download = scrapy.Field()
6follow = scrapy.Field()
7comment = scrapy.Field()
8tags = scrapy.Field()
9score = scrapy.Field()
10num_score = scrapy.Field()
这里的字段信息就是我们前面在网页中定位的 8 个字段信息,包括:name 表示 App 名称、volume 表示体积、download 表示下载数量。在这里定义好之后,我们在后续的爬取主程序中会利用到这些字段信息。
2.3.3. 爬取主程序
创建好 kuan 项目后,Scrapy 框架会自动生成爬取的部分代码,我们接下来就需要在 parse 方法中增加网页抓取的字段解析内容。
1classKuanspiderSpider(scrapy.Spider):
2name ='kuan'
3allowed_domains = ['www.coolapk.com']
4start_urls = ['http://www.coolapk.com/']
5
6defparse(self, response):</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1552
1552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









