







一、学前准备
所需软件及插件如下
- ES:https://www.elastic.co/cn/downloads/elasticsearch
- Kibana:https://www.elastic.co/cn/downloads/kibana
- 可视化chrome插件:https://github.com/TravisTX/elasticsearch-head-chrome
- 分词器插件:https://github.com/medcl/elasticsearch-analysis-ik
注意:ES、Kibana、ik开箱即用;版本必须相同,路径不能有中文或者空格否则会无法启动,ik插件需要放到ES路径下的plugins文件夹下新建ik中
二、 简介
ES是一款REST风格基于Lucene的搜索引擎
三、学习使用
1. 安装完软件后,先来了解IK分词器
- 因为ES是一个搜索引擎,它要做的就是搜索,例如京东,搜索一样商品,它会把相关的一些商品也列出来,方便用户挑选下单,但是中国文化博大精深,同一段话甚至同一个词不同的断句分词都可能有不同的意思,对应不同的商品,因此中文分词器就很有必要了,这里咱们学习ik分词器
维基百科:https://baike.baidu.com/item/IKAnalyzer
简单教学:https://zq99299.github.io/note-book/elasticsearch-senior/ik/30-ik-introduce.html
- 最简单小demo(kibana的开发工具中编写运行)
# 查询 分词 --请求头
GET _analyze
# --请求体
{
# 分词方法 最细粒度
"analyzer": "ik_max_word",
# 被分词的文本
"text": "爱上对方过后就哭了"
}
- 效果
{
"tokens" : [
{
"token" : "爱上",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "对方",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "过后",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "就",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "哭了",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 4
}
]
}
除了Ik官方给我们提供的词典之外,我们也可自己添加自己专属的词典 词汇
在ik文件路径下找到conf,里面以.dic结尾的就是官方提供的词典,我们可以自己新建类似的文件 在xml文件中支持引用即可
保存后重启 就会发现 自定义的词汇也会被识别
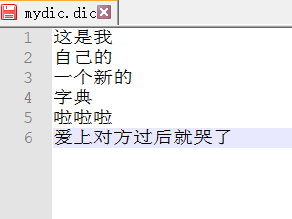


- 小彩蛋:
下雨天留客,天留我不留。
下雨天,留客天。天留我不?留!
(同样的文字,分词断句不同,意思就不同,是不是很奇妙呢?这也体现出了分词器的重要性。 看到这里的各位,趁青春正好,拼尽全力去学习吧,还有更多高深奥妙的事物期待我们发现与创造,加油!)
2. 开始正式的学习ES
- 我们要知道ES是Rest风格的,下面是REST风格的书写规则

测试
- 简易的新增
#增加 索引名 `类型名` 文档id 随着ES的版本更新,类型最终会被舍弃
#如果没有声明数据类型 字符串默认keyword
PUT /test01/sunnyside/1
{
"name": "maenguang",
"age": 18
}


- 指定数据类型的新增
#新增 索引名
PUT /test02
{
#映射规则
"mappings": {
#属性
"properties": {
"name": {
#类型
"type": "text"
},
"age": {
"type": "long"
}
}
}
}

- 查询
#查询 索引
GET /test02

- 修改
# 方法一: 直接override (版本号会增加)
PUT /test01/sunnyside/2
{
"name": "马恩光123",
"age": 18
}
# 方法二: (版本号会增加)
POST /test01/sunnyside/2/_update
{
"doc": {
"name": "法外狂徒张三"
}
}
- 删除
#删除 索引 文档 id
DELETE /test01/sunnyside/2
补充说明:关于ES中的数据类型
关于ES和MYSQL的对应关系


3. SpringBoot整合
推荐使用文档学习,开发文档是最好的老师
文档地址:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html
- Spring整合的ES依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
- 官方提供的ES操作对象RestHighLevelClient 以及一个简单的配置类
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http")));
client.close();
- 测试类
(添加文档时需要准备一个实体类)
package com.ma.esapi.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.stereotype.Component;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
public class User {
private String name;
private Integer age;
}
package com.ma.esapi;
import com.alibaba.fastjson.JSON;
import com.ma.esapi.pojo.User;
import org.apache.lucene.util.QueryBuilder;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
@SpringBootTest
class EsApiApplicationTests {
// 指定注入RestHighLevelClient对象
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
// 一、索引测试
// 测试索引的创建 ES中所有的操作都是请求
@Test
void testCreateIndex() throws IOException {
// 1. 创建索引请求
CreateIndexRequest request = new CreateIndexRequest("maenguang_index");
// 2. 执行创建请求,请求后获得响应
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
// 3. 测试
System.out.println(createIndexResponse);
}
// 测试索引是否存在 ES中所有的操作都是请求
@Test
void testExistIndex() throws IOException {
// 1. 创建一个获取索引的对象
GetIndexRequest request = new GetIndexRequest("maenguang_index");
// 2. 执行校验
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
// 3. 测试
System.out.println(exists);
}
// 测试删除索引 ES中所有的操作都是请求
@Test
void testDeleteIndex() throws IOException {
// 1. 创建一个删除索引的对象
DeleteIndexRequest request = new DeleteIndexRequest("maenguang_index");
// 2. 执行删除
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
// 3. 测试
System.out.println(delete.isAcknowledged());
}
// 二、文档测试
// 添加文档
@Test
void testAddDocument() throws IOException {
// 1. 选择要将文档添加到哪个索引中
IndexRequest request = new IndexRequest("maenguang_index");
// 2. 创建规则 PUT /maenguang_index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
// 3. 创建对象
User user = new User("miaomiaomiao", 18);
// 4. 将自己的对象值填入 json 需要引入fastjson依赖
request.source(JSON.toJSONString(user), XContentType.JSON);
// 5. 客户端发送请求,获取响应结果
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
// 6. 查看
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status());
}
// 获取文档 判断文档是否存在
@Test
void testIsExists() throws IOException {
// 1. 指定查询的文档数据所在的索引 GET/maenguang_index/_doc/1
GetRequest getRequest = new GetRequest("maenguang_index", "1");
// 下面是两条可有可无的代码 作用是规定是否获取_sources的上下文
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
// 2. 客户端发送判断请求
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
// 3. 测试
System.out.println(exists);
}
// 获取文档的信息
@Test
void testGetDocument() throws IOException {
// 1. 指定查询的文档数据所在的索引 GET/maenguang_index/_doc/1
GetRequest getRequest = new GetRequest("maenguang_index", "1");
// 2. 客户端发送判断请求
GetResponse documentFields = client.get(getRequest, RequestOptions.DEFAULT);
// 3. 测试
// 打印文档的内容
System.out.println(documentFields.getSourceAsString());
System.out.println(documentFields);
}
// 更新文档的信息
@Test
void testUpdateDocument() throws IOException {
// 1. 指定要更新的文档数据所在的索引
UpdateRequest request = new UpdateRequest("maenguang_index", "1");
request.timeout("1s");
// 2. 创建对象
User user = new User("maenguang", 18);
// 3. 将自己的对象值填入 json 需要引入fastjson依赖
request.doc(JSON.toJSONString(user),XContentType.JSON);
// 4. 客户端发送请求
UpdateResponse update = client.update(request, RequestOptions.DEFAULT);
// 5. 测试
System.out.println(update);
System.out.println(update.status());
}
// 删除文档信息
@Test
void testDeleteDocument() throws IOException {
// 1. 指定删除的数据
DeleteRequest request = new DeleteRequest("maenguang_index", "1");
// 2. 客户端发送请求
DeleteResponse delete = client.delete(request, RequestOptions.DEFAULT);
// 3. 测试
System.out.println(delete.status());
}
// 真实的项目,一般都会批量的插入数据
@Test
void testAddBulkDocument() throws IOException {
// 1. 新建一个对象
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
// 2. 模拟一个多数据集合
List<User> userList = new ArrayList<>();
userList.add(new User("user001",1));
userList.add(new User("user002",2));
userList.add(new User("user003",3));
userList.add(new User("user004",4));
userList.add(new User("user005",5));
// 3. 遍历 批处理请求
for (int i = 0; i < userList.size(); i++) {
// 指定插入到的位置
bulkRequest.add(new IndexRequest("maenguang_index")
.id(""+(i+1))
.source(JSON.toJSONString( userList.get(i)),XContentType.JSON)
);
}
// 4. 执行请求
BulkResponse bulkItemResponses = client.bulk(bulkRequest, RequestOptions.DEFAULT);
// 5. 测试 返回false 代表没有失败
System.out.println(bulkItemResponses.hasFailures());
}
// 查询
@Test
void testSearch() throws IOException {
// 1. 创建要搜索的索引库对象
SearchRequest searchRequest = new SearchRequest("maenguang_index");
// 2. 构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 查询条件,我们可以使用QueryBuilders快速匹配
// QueryBuilders.termQuery() 精确匹配
// QueryBuilders.matchAllQuery() 匹配所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "user001");
sourceBuilder.query(termQueryBuilder);
// 设置响应时间
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
System.out.println("===========================================");
for (SearchHit documentFields : searchResponse.getHits().getHits()){
System.out.println(documentFields.getSourceAsMap());
}
}
}















 3547
3547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









