






特征工程的内容
• 特征提取 :从原始数据中提取与任务相关的特征
• 特征预处理 :特征对模型产生影响;因量纲问题,有些特征对模型影响大、有些影响小
• 特征降维:将原始数据的维度降低,叫做特征降维
• 特征选择 :把多个的特征合并成一个特征。一般利用乘法或加法来完成
特征预处理
要做到归一化和标准化:
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响 (支配)目标结果,使得一些模型(算法)无法学习到其它的特征。
归一化:通过对原始数据进行变换把数据映射到【mi,mx】(默认为[0,1])之间
例子: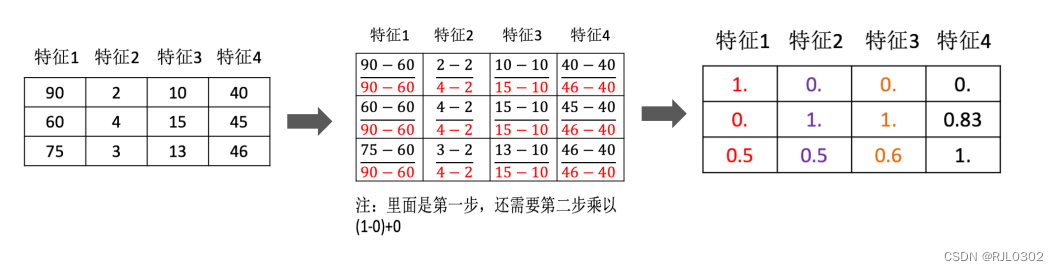
/\ /\
|| ||
【min和max都是在一列之中做比较】 mi和mx也是
公式:{[(x-min)*(mx-mi)]/(max-min)}+mi
课堂例子实现:
import numpy as np
from sklearn.preprocessing import MinMaxScaler
def dm01_MinMaxScaler():
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 2. 初始化归一化对象
transformer = MinMaxScaler()
# 3. 对原始特征进行变换
data = transformer.fit_transform(data)
# 4. 打印归一化后的结果
print(data)
#调用函数
dm01_MinMaxScaler()
结果为
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.5 0.5 0.6 1. ]]
还有一个鸢尾花分类之后会补充
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









