






 本文介绍了KNN算法的基本原理,强调了k值选择对预测结果的影响,以及如何处理分类与回归中标签性质的不同。通过实例演示了如何使用KNN算法并探讨了过拟合与欠拟合的问题。
本文介绍了KNN算法的基本原理,强调了k值选择对预测结果的影响,以及如何处理分类与回归中标签性质的不同。通过实例演示了如何使用KNN算法并探讨了过拟合与欠拟合的问题。
1.KNN算法
knn算法是机器学习最简单,最基础的算法之一。可用于分类与回归。KNN通过测量不同特征值之间的距离来进行分类。
要使KNN算法能够运行必须首先确定两个因素:(1)算法超参数k;(2)模型向量空间的距离量度。
2.k值的确定
k值的确定对KNN算法的预测结果有着至关重要的影响:
(1)当k值过小预测结果对紧邻点十分敏感,易受噪声点干扰容易导致KNN算法的过拟合。
(2)当k值较大,距离较远的训练样本也能够对实例预测结果产生影响,模型相不会因为个别噪声点对最终预测结果产生影响。但是缺点也十分明显:算法的近邻误差会偏大,距离较远的点(与预测实例不相似)会对预测结果产生影响,使得预测结果产生较大偏差,此时模型容易发生欠拟合。
(k大欠拟合,k小过拟合)
3,距离量度
样本空间内的两个点之间的距离量度表示两个样本点之间的相似程度:距离越短,表示相似程度越高;反之,相似程度越低。
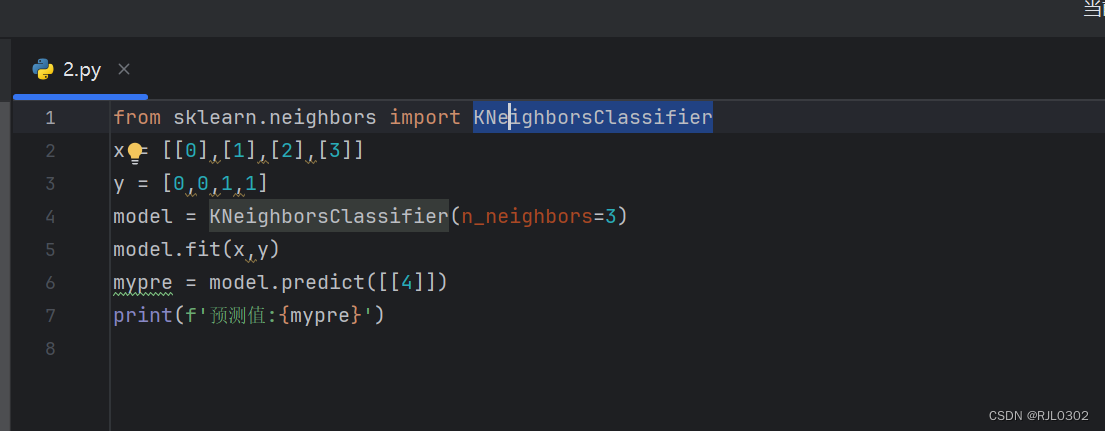
from sklearn.neighbors import KNeighborsClassifier #导入所需要用到的包
#创建模型
x = [[0],[1],[2],[3]]
y = [0,0,1,1]
model = KNeighborsClassifier(n_neighbors=3)
model.fit(x,y)
mypre = model.predict([[4]])
#输出预测值
print(f'预测值:{mypre}')
如下:

课堂反思:
回归和分类,标签值性质不同:
(分类问题输出的值是离散的,回归问题输出的值是连续的)
注:这个离散和连续不是纯数学意义上的离散和连续。
我们可以这么理解:离散就是规定好有有限个类别,这些类别是离散的。连续就是理论上可以取某一范围内的任意值,比如现在28°,当然这是我们测出来的,但是实际温度可能是无限趋于28。也就是说,回归并没有要求你的值必须是那个类别,你只要能回归出一个值,在可控范围内即可。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









