






一、引言
机器学习是人工智能的一个子领域,它专注于使计算机系统能够从数据中学习并做出预测或决策,而无需进行明确的编程。本教程旨在帮助您入门机器学习,从基础知识到实际应用,我们将一起探索这个激动人心的领域。
二、机器学习基础
1. 机器学习类型
机器学习可以分为三种主要类型:监督学习、无监督学习和强化学习。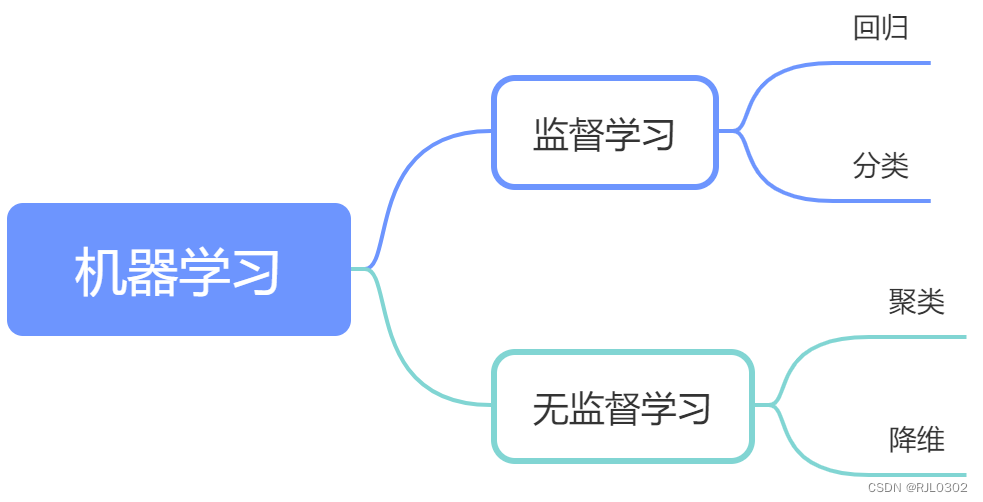
监督学习:在这种类型的学习中,我们使用标记好的数据来训练模型。例如,使用带有标签的图像来训练图像分类模型。
无监督学习:在无监督学习中,我们处理未标记的数据,并尝试发现数据中的结构或模式。例如,聚类算法就是一种无监督学习方法。
强化学习:强化学习涉及智能体(agent)在环境中通过试错来学习如何做出最佳决策。
2. 数据预处理
在进行机器学习之前,通常需要对数据进行预处理,包括数据清洗、特征选择、特征缩放等。
2.1预处理
预处理是机器学习数据准备的初步阶段,它涵盖了从数据导入到模型训练前的一系列操作。预处理的主要目标是提高数据质量,确保数据的一致性和准确性,从而为后续的特征工程、模型训练等步骤奠定坚实的基础。预处理通常包括以下几个步骤:
数据导入:使用适当的库(如pandas)导入数据集。数据集的格式可能多种多样,如csv、json、txt等。
缺失值处理:识别数据中的缺失值,并采取适当的措施,如删除包含缺失值的样本、使用插补方法填补缺失值,或使用特定的占位符表示缺失值。
异常值处理:检测和处理数据中的异常值,这些异常值可能是由测量误差、录入错误或其他原因引起的。可以使用统计方法、可视化方法或基于模型的方法来识别和处理异常值。
标签值处理:对于分类问题,需要将类别标签转化成数字,以便作为模型的目标值。
2.2数据清洗
数据清洗是预处理的一个重要环节,旨在处理数据中的噪声、不一致性和其他潜在问题。其目标是提高数据的质量和准确性,从而确保机器学习模型的有效性和可靠性。数据清洗可能涉及以下操作:
重复值处理:识别并删除数据中的重复样本,以避免对模型和分析结果产生不良影响。
数据转换:对数据进行转换和规范化,使其符合机器学习算法的要求。这可能包括对数变换、标准化或归一化等操作,以调整数据的分布和尺度。
数据采样:对于大型数据集,可以采用抽样方法来减少数据量,以便更高效地进行分析和模型训练。
2.3特征选择
特征选择是机器学习预处理中的另一个关键步骤,旨在从原始特征集中选择出最相关、最有效的特征,以提高模型的性能。特征选择的过程通常包括:
特征评估:基于一定的准则(如相关性、一致性等)评估每个特征的重要性或有效性。
特征筛选:根据评估结果,剔除无效或低效的特征,保留对模型训练起关键作用的特征。
特征选择的好处包括简化模型、提高拟合性能、节省计算资源和存储资源,以及规避维数灾难风险等。然而,它也可能增加模型的方差。
2.4特征缩放
特征缩放是预处理中的另一个重要步骤,主要用于平衡不同特征之间的贡献。当数据集中的特征具有不同的量纲或数量级差距较大时,特征缩放变得尤为重要。它可以帮助提高模型的精度和收敛速度,尤其是在使用线性模型或与距离有关的计算时。
常用的特征缩放方法包括标准化和归一化。标准化通常是将特征值缩放到均值为0、方差为1的状态,而归一化则是将特征值缩放到一个特定的范围(如0到1之间)。
综上所述,预处理、数据清洗、特征选择和特征缩放是机器学习前期准备的关键步骤,它们共同为构建高效、准确的机器学习模型奠定了基础。
三、常用机器学习算法
1. K近邻算法(KNN)
K近邻算法(K-Nearest Neighbors,简称KNN)是一种非常常用的分类和回归方法。其核心思想是通过比较一个数据点与其最近的K个邻居(样本点)来进行预测或分类。具体来说,KNN算法将新的样本点与训练数据集中的样本进行距离度量,并选择与该样本距离最近的K个训练样本作为参考。待标记的样本所属类别就由这K个距离最近的样本投票产生。
KNN算法的优点包括简单有效、重新训练的代价低、适合类域交叉样本以及适合大样本自动分类。然而,它也有一些缺点,比如它是一种惰性学习方法,即基本上不学习,相较于一些积极学习的算法,KNN可能较慢。此外,KNN算法的类别评分不是规格化的,输出可解释性不强,对于不均衡的样本可能不擅长处理。
KNN算法的应用场景非常广泛,包括但不限于:
分类问题:如垃圾邮件识别、图像分类、文本分类等。
回归问题:例如预测房价、股票价格等。
异常检测:如检测信用卡欺诈、医疗诊断中的异常病例等。
聚类分析:如市场细分、社交网络分析等。
推荐系统:如电影推荐、商品推荐等。
在使用KNN算法时,需要注意选择合适的距离度量标准,通常使用欧氏距离或曼哈顿距离来度量数据点之间的距离。同时,K值的选择也非常重要,不同的K值可能会影响算法的性能。
2. 决策树与随机森林
决策树和随机森林都是机器学习中的常用算法,它们各自具有独特的特点和应用场景。
决策树是一种树形结构,其中每个内部节点表示一个测试属性,每个分支表示这个属性的一个可能的值,每个叶子节点表示一个类或类分布。决策树算法的原理主要是通过对数据集的递归划分来构建树形结构,每个划分基于一个特征,并且使划分后的数据集更加有序。决策树可以处理各种数据类型,包括离散型和连续型,并且具有易于理解和解释的优点。它广泛应用于监督学习场景下的分类和回归问题,如银行可以使用决策树算法将客户分为高风险和低风险,以更好地进行信贷授信;金融业可以使用决策树算法预测股票的价格波动情况。
随机森林则是一种集成学习方法,它构建了多棵决策树,并通过这些树的投票或平均结果来做出最终的预测。随机森林的“随机”主要体现在两个方面:一是每棵树的训练集是通过随机抽样得到的,并且是有放回的抽样;二是在树的每个节点分裂时,随机选择一部分特征进行考虑。这种随机性使得随机森林能够避免过拟合,并且具有较好的泛化能力。此外,随机森林还能处理高维数据,训练速度相对较快,并且具有一定的可解释性。随机森林在分类、回归、异常检测和数据降维等场景都有广泛的应用。
总的来说,决策树和随机森林都是强大的机器学习工具,它们各自的特点使得它们在不同的问题和场景中都能发挥出色的性能。选择使用哪种算法,需要根据具体的数据集、问题类型和需求来进行考虑。
3. 支持向量机(SVM)
支持向量机(SVM)是一种强大的监督学习模型,广泛应用于分类和回归分析。它的核心工作原理在于通过寻找一个最优的超平面来分隔不同类别的数据点。
在二维空间中,这个超平面表现为一条直线;而在多维空间中,它则是一个高维平面。SVM的目标是找到这样一个超平面,使得不同类别的样本点被有效地分开,并且距离这个超平面最近的样本点的间隔最大。这些距离超平面最近的样本点被称为支持向量,因为它们对确定超平面的位置起到了关键作用。
SVM算法通过最小化模型误差和最大化间隔来实现这一目标。在处理非线性问题时,SVM通过使用内核函数将原始特征空间转换到新的高维特征空间,从而在新空间中寻找线性可分的超平面。这使得SVM能够处理高维数据和非线性数据。
此外,SVM还具有一些其他优点。例如,它对于特征选择很有效,可以选择最相关的特征以更好地分类数据。同时,SVM的决策边界与线性回归的最小二乘法所得到的决策边界原理不同,因此其损失函数也有所不同,这使得SVM在某些情况下能够取得更好的分类效果。
总的来说,SVM通过寻找最优超平面来实现数据的分类和回归,其强大的性能和广泛的应用领域使其成为机器学习领域的一种重要工具。
四、实践应用
为了帮助您更好地理解机器学习,我们将使用一个简单的示例进行演示:使用scikit-learn库实现KNN分类器。
步骤1:导入必要的库
python复制代码
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
步骤2:加载数据
python复制代码
iris = datasets.load_iris()
X = iris.data
y = iris.target
步骤3:划分数据集
python复制代码
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
步骤4:数据预处理
python复制代码
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
步骤5:创建和训练模型
python复制代码
classifier = KNeighborsClassifier(n_neighbors=5)
classifier.fit(X_train, y_train)
步骤6:评估模型
python复制代码
print("Accuracy:", classifier.score(X_test, y_test))
五、总结
本教程为您提供了机器学习的基本概念和入门知识。通过实践应用部分,您已经了解了如何使用scikit-learn库实现一个简单的KNN分类器。当然,机器学习领域还有很多深入的知识等待您去探索。希望这个教程能帮助您迈出机器学习的第一步!
六、附图
由于文本格式的限制,我无法直接在这里插入图片。但您可以搜索“机器学习类型”、“KNN算法工作原理”等关键词,找到相关的图解或流程图,以帮助您更直观地理解这些概念。
七、进一步学习
如果您对机器学习感兴趣并希望深入学习,我推荐您阅读以下书籍和资源:
《Python机器学习》(作者:Sebastian Raschka 和 Vahid Mirjalili)
《机器学习实战》(作者:Peter Harrington)
scikit-learn官方文档和教程
Coursera、Udemy等在线平台上的机器学习课程
祝您在机器学习的旅程上越走越远!















 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









