



 该项目是编译原理课程设计的一部分,使用Python和PyCharm开发了一个词法分析器,该分析器基于DFA识别3º语法的文法。程序接收文法和源代码作为输入,输出token表。开发环境为Windows10和Python。项目包括NFA和DFA的创建,词法分析以及测试。当遇到不符合文法的词时,程序会给出错误提示。
该项目是编译原理课程设计的一部分,使用Python和PyCharm开发了一个词法分析器,该分析器基于DFA识别3º语法的文法。程序接收文法和源代码作为输入,输出token表。开发环境为Windows10和Python。项目包括NFA和DFA的创建,词法分析以及测试。当遇到不符合文法的词时,程序会给出错误提示。
对于上不去github的小伙伴已经配套上传到CSDN,编译原理课程设计:词法分析器-Python文档类资源-CSDN下载所使用的开发环境:Windows10、python(PyCharm)环境课题功能:创建一更多下载资源、学习资料请访问CSDN下载频道.![]() https://download.csdn.net/download/RLIRiong/85379958
https://download.csdn.net/download/RLIRiong/85379958
要求:
创建一个词法分析程序,该程序支持分析常规语法。使用DFA(确定性有限自动机)来实现此程序。 程序有两个输入:1)一个文本文档,包括一组3º语法(正规文法)的产生式;2)一个源代码文本文档,包含一组需要识别的字符串。 程序的输出是一个token(令牌)表,该表由5种token组成:关键词,标识符,常量,限定符和运算符。
开发平台:
所使用的开发环境:Windows10、python(PyCharm)环境
项目简介:
词法分析器读入三型文法,将三型文法构建成一个起点和一个终点的NFA,然后将NFA用子集法构造成DFA,创建DFA的索引表,后续读取要扫描的代码,将代码中的每个词依次带入DFA的索引表进行状态转换,如果到达终态说明词符合文法要求,输出token列表(三元组:所在行号,类别,token 内容)如果出错会输出另一种三元组(行号, 对错判定, token内容),并将token列表写入txt文件供任务二LR(1)语法分析器来使用,同时也会将结果输出到result.txt文件来观测,默认注释掉DFA可视化过程,如果想观测状态变化需要把show函数注释取消。
main函数流程图:

相关数据结构
DFA的状态用state类来表示,由state里的notepsilon和epsilon来连接各个状态。
class state:
| 数据结构名 | 类型 | 介绍 |
| _end | 布尔 | 表示是否为终结状态,是则为True,反之False。 |
| notepsilon | 字典 | 表示路径非空的状态链接,键为路径,键值为路径所到达的状态。 |
| epsilon | 列表 | 表示路径为ε的状态链接,里面保存ε可以到达的状态。 |
| statenum | int | 表示该状态的状态编号,用于后续的状态可视化。 |
| is_right | 布尔 | 表示是否应该记录产生式右部,如果该状态是由起点状态经过非空路径到达的,会为True,让下面的right来记录产生式右部非终结符。 |
| right | str | 表示产生式的右部,如果通过了is_right,会记录产生式右部,用于构造NFA。 |
| left | str | 表示产生式左部,如果没通过is_right,说明这是这个产生式的起点状态,记录产生式左部,用于构造NFA 。 |
其他数据结构:
| 数据结构名 | 类型 | 介绍 |
| keywords | 列表 | 保存预设的关键词。 |
| delimiter | 列表 | 保存预设的限定符。 |
| constant | 列表 | 保存预设的允许是常量的终结符。 |
| operator | 列表 | 保存预设的运算符。 |
| identifier | 列表 | 保存预设的允许是标识符的终结符。 |
| token | 字典 | 保存预设的token。 |
| Alphabet | 列表 | 保存所有终结符。 |
详细设计
函数
创建NFA:
| 函数名 | 返回值 | 方法介绍 |
| go_nfa(list_source) | 一个只有一个起点和一个终点的NFA元组(起点状态,终点状态)。 | 参数为所有产生式的列表,创建NFA。 |
| one_road(list_source) | 返回元组(起点状态,终点状态)。 | 参数为单个产生式,创建一个起点和终点,将两个状态从起点用终结符连到终点。 |
| more_road(list_source) | 返回元组(起点状态,终点状态)。 | 参数为单个产生式,创建一个起点和终点,从起点用终结符连接到终点,再从终点用ε连接到起点。 |
| add_road(begin, end, a) | 返回元组(起点状态,终点状态)。 | 用a从begin连接到end。 |
| add_epsilon_road(begin, end) | 返回元组(起点状态,终点状态)。 | 用ε从begin连接到end。 |
| union(tuple1, tuple2) | 返回元组(起点状态,终点状态)。 | 创建两个新状态begin,end,将两个起点和终点分别用begin和end连接,形成一个更大的NFA。 |
创建DFA:
| 函数名 | 返回值 | 方法介绍 |
| go_dfa(nfa, alphabet) | 一个索引表格和DFA的起点状态。 | 参数为nfa元组和a终结符表,将nfa进行合并,得到一个dfa的表用于扫描。 |
| go_circle(same_state, visit_state) | 遍历完则返回False,反之True继续循环。 | 判断是否完成遍历等价状态集。 |
| get_same_state(begin, ahead_state) | 没有返回值。 | 深度搜索策略寻找可以直达的状态。 |
| get_next_state(gura, alp, next_state) | 非空状态集 | 用于等价状态通过某一个非终结符到的下一个非空状态集 。 |
词法分析:
| 函数名 | 返回值 | 方法介绍 |
| scan(dfa, nfa, token) | token列表 | 带入DFA扫描单词。 |
| get_all_code() | 一维列表,里面保存所有要扫描的词。 | 读取代码文件的所有词,用于在界面进行显示。 |
| get_code() | 二维列表,里面保存所有要扫描的词以及行信息。 | 读取代码文件的所有词,形成二维列表,可以显示行数,用于扫描处理。 |
| go_first(dfa, nfa) | 成功则返回首状态,反之返回int类型。 | 寻找dfa中的首状态,进行遍历。 |
| go_next(sta, alp, dfa) | 成功则返回首状态,反之返回int类型。 | 通过终结符寻找下一个状态。 |
| in_end(sta) | 是返回True,反之False。 | 判断该状态是否已经到达终点。 |
| whoami(token, word) | 词所属的类型。 | 扫描通过的单词进入该函数进行token的分类判定。 |
| show(dfa) | 没有返回值。 | 进行dfa的可视化工作,可以看到dfa的状态转换。 |
| get_states(states) | 状态集合。 | 得到状态集合。 |
| get_nexts(i['next']) | 需要的状态。 | 得到下一个状态。 |
测试与运行
以编译原理书上的例题为例:

带入词法分析器:

并设计词:
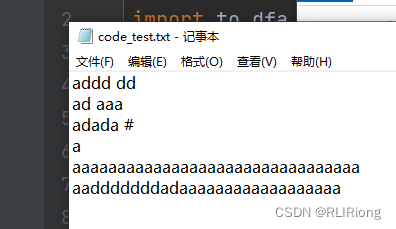
运行程序结果:
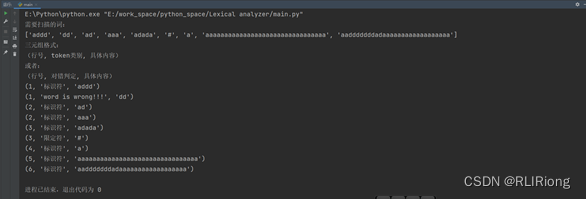
我们来查看词法分析器的DFA运行可视化情况:
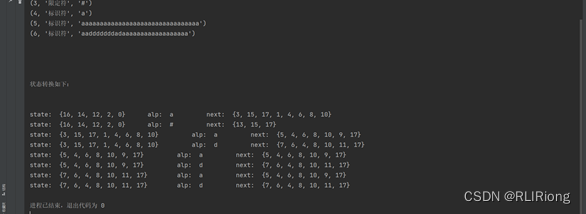
进行手写计算,画出的DFA符合程序可视化的结果。
现在我们对code_test.txt进行一定的修改,添加一点错误的词语:dd(包含在三型文法之内的终结符), dio(额外添加的终结符i,o)

运行结果:
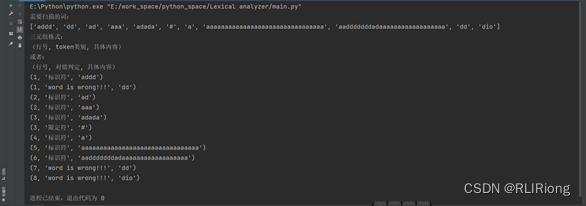

















 7117
7117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









