




使用LLM在KG上进行复杂的逻辑推理

摘要
在知识图谱上进行推理是一项具有挑战性的任务,这需要深度理解实体之间复杂的关系和它们关系的逻辑。而当前的方法通常依赖于学习 几何形状 以将实体嵌入到向量空间中进行逻辑查询操作,但在复杂查询和特定数据集表示方面表现不佳。
几何形状通常指的是将实体或关系映射到向量空间时所使用的几何结构或形状。几何形状嵌入方法通过学习实体和关系之间的几何关系,将它们映射到向量空间中的几何形状。这些几何形状可以是点、线、曲线等,它们在向量空间中的位置和距离可以反映实体和关系在知识图谱中的语义关系。
本文提出了一种新的 解耦(decoupled) 方法,即LARK,将复杂的KG推理定义为上下文KG搜索和逻辑查询推理的组合,以利用 图抽取算法(Graph extraction algorithms) 和大型语言模型(LLM)的优势。
“解耦方法”(Decoupling Method)通常指的是将复杂系统或问题分解为更简单、相互独立的组件或子问题的方法。
"Graph extraction algorithms"图抽取算法
用于从非结构化的文本数据中提取出图结构信息。这些算法将文本中的实体、关系和属性识别出来,并将它们表示为图的形式,其中实体作为节点,关系作为边连接节点。
Graph extraction算法的目标是将文本数据转化为结构化的图数据,以便进行图分析、图挖掘和知识图谱构建等任务。
实验证明,所提出的方法在多个逻辑查询构造上优于现有的KG推理方法,并在更复杂的查询中取得了显著的性能提升。此外,该方法的性能与底层LLM的规模增加成正比,从而使得最新的LLM在逻辑推理上能够得到整合。该方法为解决复杂KG推理的挑战提供了新的方向,并为未来在这一领域的研究铺平了道路。
介绍
知识图谱(KG)使用灵活的三元组模式来编码知识,其中两个实体节点通过关系边连接。然而,一些现实世界中的知识图谱,如Freebase、Yago和NELL等,通常是大规模的、噪声干扰和不完整的。因此,在这样的知识图谱上进行推理是人工智能研究中的一个基本且具有挑战性的问题。
逻辑推理的总体目标是利用存在量词(∃)、合取(∧)、析取(∨)和否定(¬)等一阶逻辑(FOL)查询的运算符,为知识图谱上的FOL查询开发回答机制。为了有效地捕捉知识图谱实体的语义位置和逻辑覆盖范围,当前研究主要集中在创建多样的潜在空间几何结构上,例如向量、盒子、双曲面和概率分布等。
尽管这些方法取得了成功,但它们在性能上存在以下限制:
- 复杂查询: 它们依赖于对 FOL查询 的限制形式,这导致丢失需要链式推理和涉及知识图谱中多个实体之间多个关系的复杂查询的信息;
- 泛化能力: 针对特定知识图谱的优化可能无法推广到其他知识图谱,这限制了这些方法在真实场景中的适用性,因为知识图谱在结构和内容上可以有很大的变化;
- 可扩展性: 繁重的训练时间限制了这些方法在更大的知识图谱上的可扩展性和将新数据纳入现有知识图谱的能力。
FOL查询是指一阶逻辑(First-Order Logic)中的查询操作。一阶逻辑是一种形式化的逻辑系统,用于描述和推理关于对象、关系和性质的命题。
在一阶逻辑中,FOL查询是对知识库或知识图谱中的事实和关系进行询问的方式。FOL查询使用一阶逻辑的语法和语义规则,结合存在量词 (∃)、合取 (∧)、析取 (∨) 和否定 (¬) 等逻辑运算符,以及变量和常量,来构造查询语句。查询语句由一个或多个谓词(表示关系)和变量组成,用于询问知识库中是否存在满足某些条件的事实或关系。
例如,假设有一个知识库包含关于人员的信息,其中包括实体 “John” 和 “Mary”,以及关系 “父亲” 和 “母亲”。我们可以构建一个FOL查询,如 “∃x 父亲(x, John)”,它询问是否存在一个实体 x,使得 x 是 John 的父亲。查询的回答可能是 “是” 或 “否”,表示是否存在满足查询条件的事实。
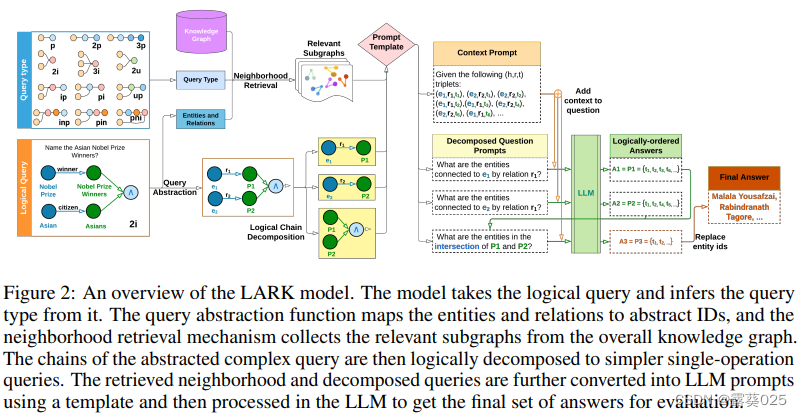
为了解决这些限制,本文旨在利用大型语言模型(LLM)的推理能力,在一种名为Language-guided Abstract Reasoning over Knowledge graphs(LARK)的新框架中进行推理,如图1所示。

在LARK中,利用逻辑查询在知识图谱上搜索相关的子图上下文,并使用逻辑分解的LLM提示进行链式推理。
为了实现这一目标,首先从输入查询和知识图谱中抽象出逻辑信息。由于逻辑的不变性,这使得我们的方法可以专注于逻辑形式化,避免模型的产生幻觉,并在不同的知识图谱上进行泛化。从这个抽象的知识图谱中,使用逻辑查询中存在的实体和关系提取相关的子图。这些子图作为上下文提示输入到LLMs中。在下一个阶段,需要有效处理复杂的推理查询。根据之前的研究,发现与一系列简单提示相比,LLMs在处理复杂提示时效果显著较差。因此,为了简化查询,利用它们的逻辑性质,将多操作查询确定性地分解为逻辑顺序的基本查询(从图1b到图1c的转换中所示)。然后,将这些分解的逻辑查询转换为提示,并通过LLM进行处理,生成最终的答案集(图1d所示)。逻辑查询按顺序处理,如果查询y依赖于查询x,则x在y之前调度。操作按逻辑顺序进行调度,以便将不同的逻辑查询进行批处理,并将答案存储在缓存中以便于访问。
逻辑分解是将复杂的多操作查询分解为一系列逻辑顺序的基本查询的过程。每个基本查询只包含一个操作,例如投影、交集、并集或否定。
本文提出的方法有效地将逻辑推理与知识图谱的能力与LLM的能力相结合,这是首次尝试。与先前依赖受限的一阶逻辑(FOL)查询形式的方法不同,该方法利用逻辑分解的LLM提示,实现了对从知识图谱中检索到的子图的链式推理,从而能够高效地利用LLM的推理能力。知识图谱搜索模型受到 检索增强技术 的启发,但实现了知识图谱的确定性特性,以简化相关子图的检索。此外,与其他提示方法相比,链式分解技术通过利用复杂查询中的逻辑操作链和以逻辑顺序利用后续查询中的先前答案,增强了知识图谱中的推理能力。
检索增强技术是一类用于改进信息检索系统性能的方法和技术。传统的信息检索系统通常基于关键词匹配或统计模型来检索和排名文档,但这些方法可能存在一些局限性,例如无法准确理解查询意图、无法处理复杂的查询或无法提供个性化的结果。
检索增强技术旨在克服这些限制,提高信息检索系统的效果和用户体验。
总结一下,本文的主要贡献如下:
- 提出了一种名为Language-guided Abstract Reasoning over Knowledge graphs(LARK)的新模型,利用大型语言模型的推理能力,高效地回答知识图谱上的FOL查询。
- 该模型利用查询中的实体和关系在抽象的知识图谱中找到相关的子图上下文,然后使用逻辑分解的查询的LLM提示在这些上下文中进行链式推理。
- 在标准知识图谱数据集上进行的逻辑推理实验表明,相对于基于投影(p)、交集(∧)、并集(∨)和否定(¬)等操作的14种FOL查询类型,LARK的MRR性能提升了33%至64%。
- 通过比较复杂查询和分解的逻辑查询,证明了链式分解的优势,LARK在逻辑推理任务上的性能比复杂查询提升了9%至24%。此外,对LLMs的分析显示了增加规模和更好设计的底层LLMs对LARK性能的重要贡献。
相关工作
本文涉及两个主题的交叉,即知识图谱上的逻辑推理和LLM中的推理提示技术。
知识图谱上的逻辑推理:这个领域的一开始的方法主要关注捕捉实体的语义信息以及它们之间的投影所涉及的关系操作。然而,该领域的进一步研究揭示了对编码知识图谱中存在的空间和层次信息的新几何形式的需求。为了解决这个问题,模型如Query2Box 、HypE 、PERM和BetaE将实体和关系编码为盒子、双曲面、高斯分布和贝塔分布。此外,CQD等方法专注于通过简单中间查询的答案组合来改进复杂推理任务的性能。在另一条研究线路中,HamQA 和QA-GNN 开发了利用知识图谱邻域增强整体性能的问答技术。先前的方法主要关注增强逻辑推理的知识图谱表示。与这些现有方法相反,本文提供了一个系统的框架,利用LLM的推理能力,并将其定制为解决知识图谱上的逻辑推理问题。
LLM中的推理提示:最近的研究表明,LLM可以通过上下文提示学习各种NLP任务。此外,LLM通过提供中间推理步骤(也称为思维链)成功应用于多步推理任务,这些步骤是到达答案所需的。另外,某些研究组合了多个LLM或带有符号函数的LLM来执行多步推理,并具有预定义的分解结构。最近的研究如least-to-most、successive 和decomposed 的提示策略将复杂提示分解为子提示,并按顺序回答它们以实现有效性能。虽然这些研究与本文的方法接近,但它们没有利用先前的答案来指导后续查询。
LARK是独特的,因为它能够利用链式分解机制中的逻辑结构,增强检索到的知识图谱邻域,并在连续查询中将前面的LLM答案纳入其中的多阶段回答结构。
方法
在这一节描述了在知识图谱上进行逻辑推理的问题设置,还描述了该模型的各个组件。
问题格式化
在这项工作职能,解决了在KG上进行逻辑推理的问题。知识图谱 G: E × R,存储实体(E)和关系(R)。不失一般性,KG也可以组织为一组三元组 ⟨e1,r,e2⟩ ⊆ G,其中每个关系 r ∈ R 是一个布尔函数 r: E×E → {True,False},表示关系 r 是否存在于实体对(e1,e2)∈ E 之间。
考虑四个基本的一阶逻辑(FOL)操作:投影(p),交集(∧),并集(∨)和否定(¬)来查询 KG。这些操作的定义如下:
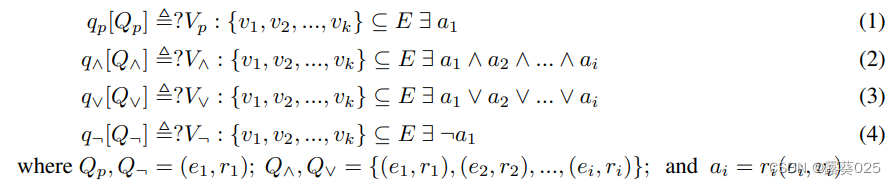
“≜” 是一个符号,表示 “qp[Qp]” 定义为后面的表达式。
“?Vp : {v1, v2, …, vk} ⊆ E” 是一个条件,表示变量 “Vp” 取值于集合 {v1, v2, …, vk},且这些取值都属于实体集合 E。
“存在一个变量 a1,使得在变量 Vp 取值于集合 {v1, v2, …, vk} 且这些取值都属于实体集合 E 的情况下,命题 qp[Qp] 成立。”
其中,qp、q∧、q∨和q¬分别代表投影、交集、并集和否定查询;Vp、V∧、V∨和V¬分别代表这些查询的相应结果。ai是一个布尔指示器,如果ei通过关系ri与vi相连,则ai为1,否则为0。逻辑推理的目标是制定这些操作,以便对于给定的查询qτ和输入Qτ,我们能够有效地从实体集合E中检索到Vτ,例如对于一个投影查询qp[(Nobel Prize, winners)],我们希望检索到Vp = {Nobel Prize winners} ⊆ E。
在传统的逻辑推理方法中,查询操作通常通过几何函数来表示。例如,在Query2Box中,查询的交集被表示为盒子表示的交集。然而,在LARK中,利用语言模型(LLM)的先进推理能力,并优先考虑在查询中对逻辑链进行高效的分解,以提高性能。这种新颖的策略旨在通过利用LLM在知识图谱上的推理能力来克服传统方法的局限性。
邻域检索和逻辑链分解
LARK的推理能力基于大型语言模型构建。然而,语言模型的输入长度有限,限制了其处理整个知识图谱的能力。此外,尽管知识图谱中的实体和关系集合是唯一的,但逻辑操作的推理是普适的。因此,特别针对知识图谱上的逻辑推理的上述特点调整了语言模型的提示。为了满足这个需求,我们采用了一个两步的过程:
- 查询抽象化: 为了使知识图谱上的逻辑推理过程更具普适性,建议 将知识图谱和查询中的所有实体和关系替换为唯一的ID。这种方法有三个显著的优点。
(1)首先,它减少了查询中的标记(token)数量,提高了语言模型的效率。
(2)其次,它允许仅利用语言模型的推理能力,而不依赖于任何外部的常识知识。通过避免使用常识知识,LARK减少了模型幻觉的可能性(可能导致生成不受知识图谱支持的答案)。
(3)最后,它去除了任何特定于知识图谱的信息,从而确保该过程对不同的数据集具有普适性。虽然这可能直观地导致信息的丢失,但在第4.4节中呈现的实证结果表明,对整体性能的影响是可忽略的。
将知识图谱和查询中的所有实体和关系替换为唯一的ID
旨在简化和抽象化知识图谱中的实体和关系表示。通常,在知识图谱中,实体和关系使用它们的文本标识或符号来表示。然而,这些文本标识可能是多样的,存在不统一性和多义性的问题。
为了解决这个问题,并使得知识图谱的处理更加一致和高效,可以使用唯一的ID来代替实体和关系的文本标识。每个实体和关系都被分配一个独特的ID,这个ID可以是数字、字符串或其他形式的标识符。
假设我们有一个知识图谱,其中包含以下实体和关系的文本标识:
实体:
实体1: “苹果”
实体2: “香蕉”
实体3: “橙子”
关系:
关系1: “属于”
关系2: “是颜色”
现在,我们将这些实体和关系替换为唯一的ID:
实体ID:
实体1: E1
实体2: E2
实体3: E3
关系ID:
关系1: R1
关系2: R2
这样,我们可以使用唯一的ID来表示知识图谱中的实体和关系。例如,一个关系三元组可以表示为 (E1, R1, E2),表示 “苹果 属于 香蕉”。
在查询中,如果有一个查询 “橙子 是颜色 什么”,我们也可以将其中的实体和关系替换为唯一的ID,例如 “E3 R2 ?”,表示 “实体3 关系2 ?”。
- 邻域检索: 为了有效回答逻辑查询,不需要语言模型访问整个知识图谱。相反,可以识别包含答案的相关邻域。之前的方法主要关注语义检索的网络文档。然而,逻辑查询具有确定性的特点,因此对查询中存在的实体和关系进行 k层的深度优先遍历 。设E1τ和R1τ分别表示查询Qτ的查询类型τ中的实体和关系集合,则查询qτ的k级邻域由Nk(qτ[Qτ])定义为:
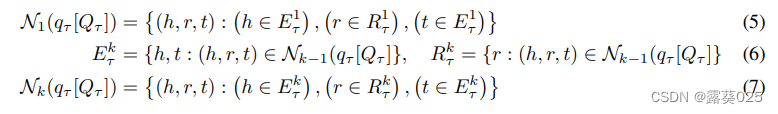
k层的深度优先遍历意味着我们探索和扩展与查询相关的实体和关系的范围,直到遍历的深度达到k级为止。这样可以限制遍历的范围,避免无限遍历整个知识图谱,同时在有限的深度内获取与查询相关的信息。
已经采取了一些措施,通过抽象查询并限制LLM的输入上下文,使LARK方法更具通用性和效率。然而,查询的复杂性仍然是一个问题。查询类型τ的复杂性,用O(qτ)表示,取决于它涉及的实体和关系的数量,即O(qτ) ∝ |Eτ| + |Rτ|。换句话说,查询的大小(以其组成元素为单位)是确定其计算复杂性的关键因素。这一观察结果尤其在LLM的上下文中具有相关性,因为先前的研究表明,它们处理的查询复杂性增加时,性能往往会降低。为了解决这个问题,LARK中提出了逻辑查询链分解机制,将复杂的多操作查询转化为多个单操作查询。由于操作集合是穷尽的,我们采用以下策略来分解不同的查询类型:
- 将k层 投影查询 简化为k个一层投影查询,例如,一个包含一个实体和三个关系的3p查询
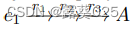 被分解为
被分解为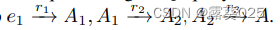 。
。 - 将k交集查询简化为k个投影查询和一个交集查询,例如,一个由两个投影查询
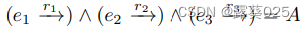
的3i查询组成的交集查询被分解为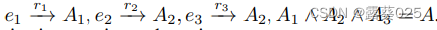 。类似地,将k并集查询简化为k个投影查询和一个并集查询。
。类似地,将k并集查询简化为k个投影查询和一个并集查询。
投影查询用于选择特定的实体和关系,并返回与它们相关联的信息。
在先前的工作和实证研究中使用的查询类型的详尽分解可以在附录中找到。
链状推理提示
在前一节中概述了限制邻域并将复杂查询分解为简单查询链的方法。利用这些方法,现在可以利用LLM的推理能力来获得查询的最终答案,如图2所示。为了实现这一点,采用了一个提示模板,将邻域转换为上下文提示,将分解的查询转换为问题提示。值得注意的是,分解中的某些查询依赖于先前查询的响应,例如交集查询依赖于前面的投影查询。此外,与之前的提示方法(如思维链和分解提示)不同,答案需要在提示中的特定位置进行集成。为了解决这个问题,在相关查询中保留一个占位符,并在实时中使用一个临时缓存存储前面的答案,以替换占位符。这还具有保持查询的并行性的额外好处,因为可以分阶段运行批量的分解查询,而不是顺序运行每个分解查询。关于不同查询类型的复杂和分解逻辑查询的具体提示模板,请参见附录B。
实施细节
在八个Nvidia A100 GPU上使用PyTorch 实现了LARK,每个GPU具有40 GB VRAM。对于LLM(Large Language Model),选择了FLAN-T5模型 ,因为它在Huggingface库中公开可用。为了对大规模模型进行高效的推理,我们依赖于LLM的混合精度版本和Deepspeed库的零阶段三优化。模型算法见附录D,所有实验的实现代码、精确配置文件和数据集均可公开获取。
在实验中,查询的最高复杂性要求在实体和关系周围有3个跳点的邻域。因此,将深度限制设置为3(即k = 3)。此外,为了使过程完全适用于不同的数据集,对输入设置了n个标记的限制,这取决于LLM模型(对于Flan-T5,n=2048)。在实践中,这意味着当上下文长度超过n时,停止深度优先遍历。
实验结果
本部分描述了实验,旨在回答以下研究问题(RQs):
RQ1:LARK在标准知识图谱基准上的逻辑推理任务中是否优于最先进的基准模型?
RQ2:本文的链式分解查询和逻辑排序答案机制与标准提示技术相比如何表现?
RQ3:LARK底层LLM模型的规模和设计如何影响其性能?
RQ4:如果增加令牌大小的支持,本模型会如何表现?
RQ5:查询抽象是否会影响本模型的推理性能?
数据集和基准模型
选择了以下标准基准数据集,以研究模型在知识图谱上的逻辑推理任务中与最先进模型的性能对比:
- FB15k 基于Google创建的大型协作知识图谱项目Freebase。FB15k包含大约15,000个实体,1,345个关系和592,213个三元组(关于实体的事实陈述)。
- FB15k-237 是FB15k的子集,包含14,541个实体,237个关系和310,116个三元组。FB15k-237中的关系是FB15k中关系的子集,旨在解决FB15k的一些限制,例如存在许多无关或模糊的关系,并为知识图谱补全模型提供更具挑战性的基准。
- NELL995 是使用Never-Ending Language Learning(NELL)系统创建的,NELL是一个机器学习系统,通过阅读文本并推断新事实,自动从网络中提取知识。NELL995包含9,959个实体,200个关系和114,934个三元组。NELL995中的关系涵盖了广泛的领域,包括地理、体育和政治。
选择上述数据集的标准是它们在先前的研究中普遍存在。有关它们的令牌大小的详细信息,请参见附录E。对于基准模型,选择了以下方法:
- GQE 将查询编码为单个向量,并在低维空间中表示实体和关系。它使用平移和深度集合运算符,分别建模为投影和交集运算符。
- Query2Box (Q2B) 使用盒子嵌入模型,这是传统向量嵌入模型的一种推广,可以捕捉更丰富的语义。
- BetaE 使用新颖的贝塔分布来建模实体和关系表示中的不确定性。BetaE可以捕捉嵌入的点估计和不确定性,从而在知识图谱补全任务中实现更准确的预测。
- HQE 使用双曲线查询嵌入机制来建模知识图谱补全任务中的复杂查询。
- HypE 使用双曲线模型来表示知识图谱中的实体和关系,同时捕捉它们的语义、空间和层次特征。
- CQD 将复杂查询分解为更简单的子查询,并对子查询应用特定于查询的注意机制。
RQ1. 逻辑推理的有效性
为了研究模型在逻辑推理任务中的有效性,将其与先前的基准模型在以下标准逻辑查询结构上进行比较:
- 多跳投影(Multi-hop Projection) 从知识图谱中的头实体遍历多个关系,通过将查询投影到目标实体来回答复杂查询。在我们的实验中,我们考虑从头实体开始的1p、2p和3p查询,分别表示从头实体开始的1个关系跳、2个关系跳和3个关系跳。
- 几何运算(Geometric Operations) 应用交集(∧)和并集(∨)的操作来回答查询。实验使用2i和3i查询,分别表示对2个和3个实体的交集。此外,还研究了2u查询,它对2个实体执行并集操作。
- 复合运算(Compound Operations) 将多个操作(如交集、并集和投影)整合在一起,处理知识图谱上的复杂查询。
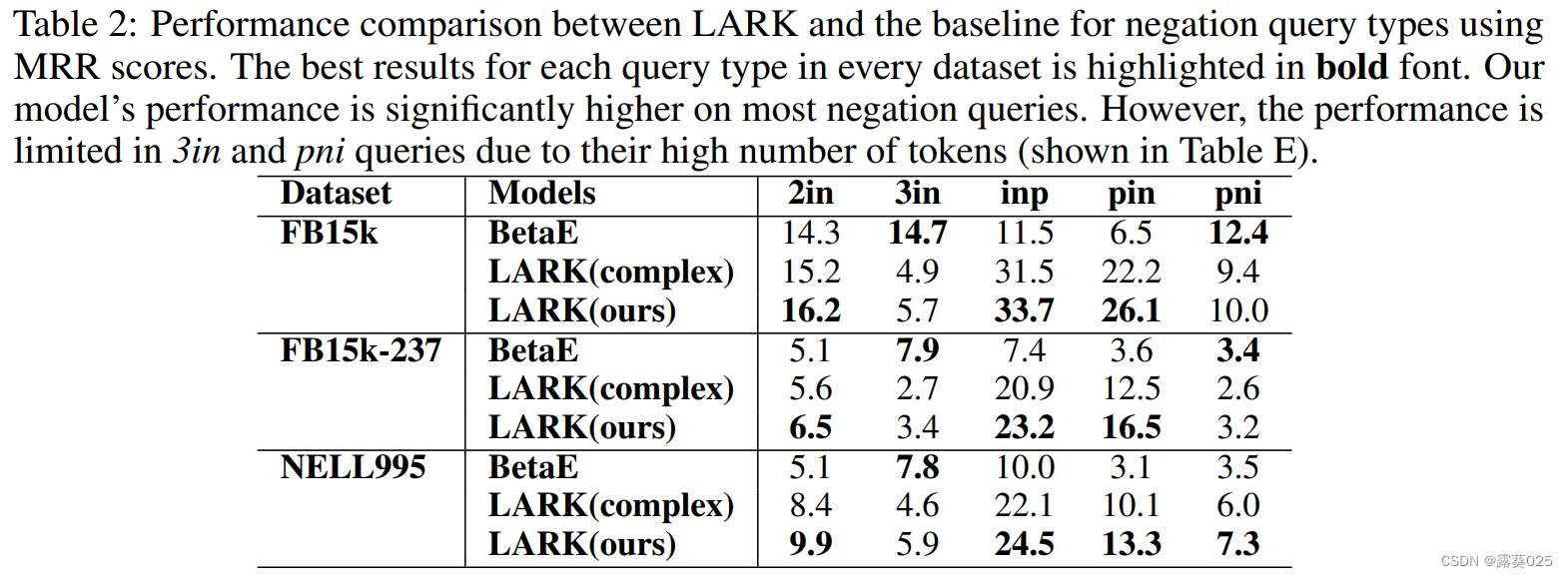
- 否定运算(Negation Operations) 通过找到不满足给定逻辑的实体来否定查询。在实验中,研究了2in、3in、inp和pin查询,它们分别否定2i、3i、ip和pi查询。还分析了pni查询(pi查询的另一种变体),其中否定作用于交集中的两个实体。需要注意的是,BetaE是现有文献中唯一支持否定的方法,因此在实验中只与其进行比较。
展示了实验研究的结果,比较了使用不同查询结构检索到的候选实体的平均倒数排名(Mean Reciprocal Rank,MRR)得分。MRR是候选实体的倒数排名的平均值。为了确保公平比较,选择了这些查询结构,这些结构在该领域的大多数先前工作中都被使用过。附录A提供了这些查询类型的示例,以便更好地理解。实验结果显示,LARK在不同查询类型上平均优于先前的最先进基准模型33%至64%,如表1所示。
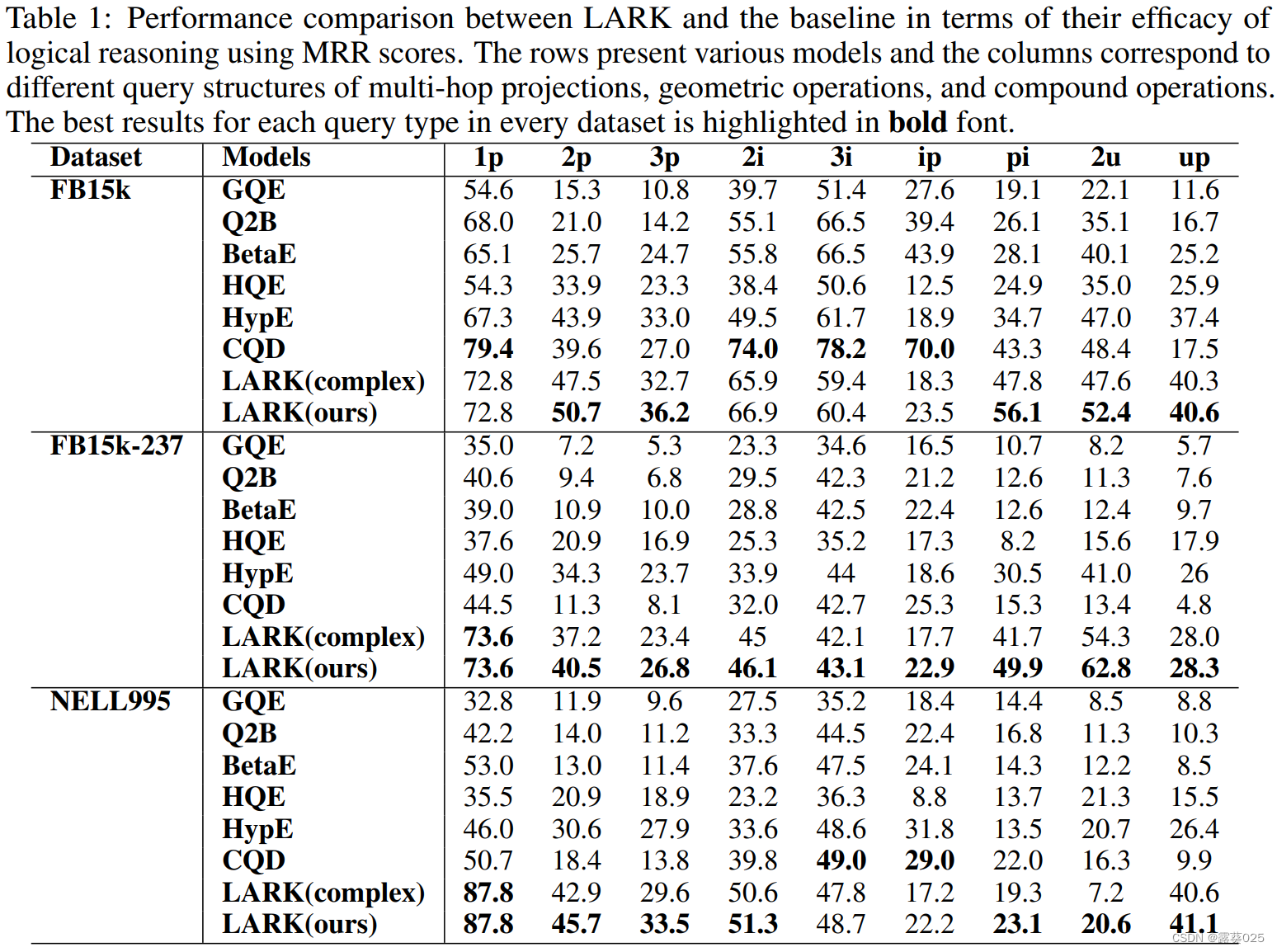
观察到,对于更简单的查询,LARK的性能改进更大,其中1p > 2p > 3p和2i > 3i。这表明,LLM在跨关系方面更擅长捕捉广度,但在多个关系之间的深度方面可能不太有效。此外,评估还包括针对具有挑战性的否定查询的测试,其中BetaE仍然是唯一的现有方法。即使在这种复杂的情景下,发现(如表2所示)LARK的性能明显优于基准模型,提高了110%。这证实了模型在处理复杂查询场景中的卓越推理能力。值得注意的另一点是,某些基准模型(如CQD)在FB15k数据集的某些查询类型(如1p、3i和ip)上能够胜过LARK。原因是FB15k在训练集到验证集和测试集之间存在数据泄漏,这对训练为基础的基准模型不公平地有利。而推理模型LARK则不受此影响。
RQ2. 链分解的优势
这个实验旨在研究使用链分解查询相对于标准复杂查询的优势。采用了上一节中描述的相同实验设置。结果在表1和表2中显示,利用链分解查询可以显著提高模型的性能,提高了9%至26%。这种改进明确表明了LLM捕捉广泛关系的能力,并有效利用这种能力来提升复杂查询的性能。这项研究突显了使用链分解来克服复杂查询的局限性并提高逻辑推理任务的效率的潜力。这一发现对自然语言处理领域具有重要贡献,并对其他各种应用,如问答系统和知识图谱补全,产生了影响。总体而言,结果表明,链分解查询可能是改善LLM在复杂逻辑推理任务上性能的一种有前途的方法。
RQ3. LLM规模的分析
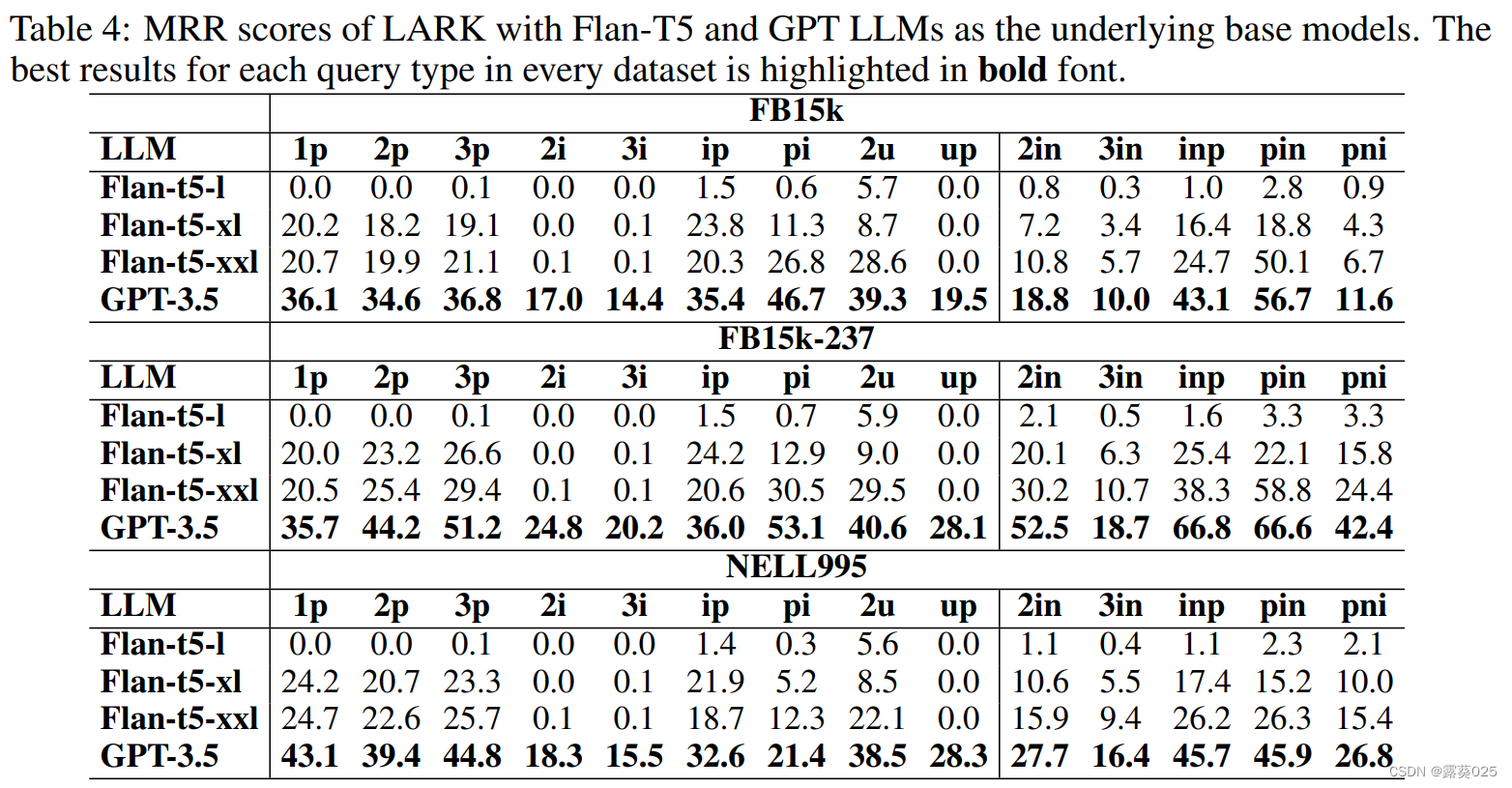
这个实验分析了底层LLMs的规模和查询抽象对LARK模型整体性能的影响。为了研究LLM规模的影响,比较了Flan-T5模型的三个变体,分别是flan-t5-l、flan-t5-xl和flan-t5-xxl,它们分别有7.8亿、30亿和110亿个参数。表3中呈现的评估结果显示,当从flan-t5-l过渡到flan-t5-xl,以及从flan-t5-xl过渡到flan-t5-xxl时,LARK模型的性能分别提高了72%和118%。这表明增加LLM参数的数量可以提升LARK模型的性能。

RQ4. 增加LLMs的标记限制的研究
从附录E提供的数据集详细信息中,观察到不同查询类型的标记大小在58到超过100,000之间有相当大的波动。不幸的是,实验中基准的Flan-T5的标记限制是2048。这个限制不足以展示LARK在我们的任务上的全部潜力性能。为了解决这个限制,我们考虑到具有更高标记限制的模型的可用性,例如GPT-3.5。然而,这些模型的运行成本很高,因此无法对整个数据集进行彻底的分析。尽管如此,为了了解LARK在增加标记大小的情况下的潜力,从每个标记长度超过2048且小于4096的数据集中随机抽取了每个查询类型的1000个查询,并将模型与GPT-3.5和Flan-T5作为基准进行了比较。在表4中显示的评估结果表明,从flan-t5-xxl过渡到GPT-3.5可以使LARK模型的性能显著提高29%-40%,这表明增加LLMs的标记限制可能具有进一步提升性能的重要潜力。
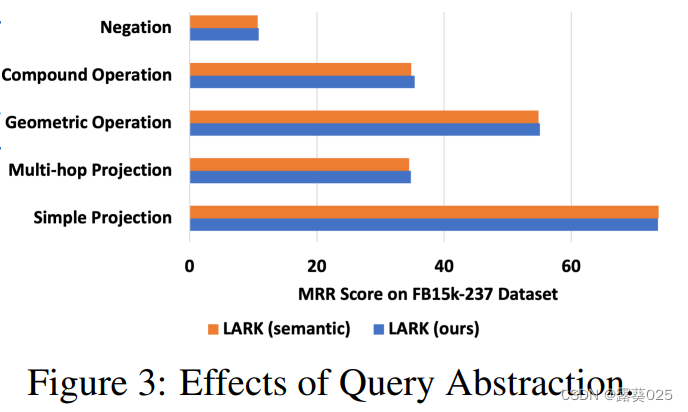
RQ5. 查询抽象的影响
关于查询抽象的分析,考虑了LARK的一个变体,称为LARK(语义),它保留了知识图谱实体和关系的语义信息。如图3所示,语义信息对简单投影查询提供了0.01%的轻微性能提升。然而,在更复杂的查询中,它导致了0.7%至1.4%的性能下降。这种性能下降的主要原因是语义信息的包含超过了LLMs的标记限制,导致了邻域信息的丢失。因此,断言查询抽象不仅是一种有价值的技术,可以减轻模型的幻觉,并在不同的知识图谱数据集上实现泛化,还可以通过减小标记大小来提高性能。
广泛影响
使用大型语言模型(LLMs)进行复杂逻辑推理的方法预计将为对大规模、嘈杂和不完整的现实世界知识图谱进行改进的推理铺平道路。这可能对自然语言理解、问答系统和智能信息检索系统等各种应用产生重大影响。例如,在医疗保健领域,知识图谱可以用于表示患者数据、医学知识和临床研究,对这些知识图谱进行逻辑推理可以实现更好的诊断、治疗和药物发现。然而,还需要考虑伦理问题。与大多数基于人工智能的技术一样,存在将偏见引入模型的潜在风险,这可能导致不公平的决策和行动。偏见可能在知识图谱本身中引入,因为它们通常是从带有偏见的来源中半自动创建的,并且可以通过逻辑推理过程放大。此外,用于训练LLMs的大量数据也可能引入偏见,因为它可能反映社会偏见和刻板印象。因此,有必要仔细监控和评估在这种方法中使用的知识图谱和LLMs,以确保公平性并避免歧视。该方法的性能还取决于所使用的知识图谱的质量和完整性,以及当前LLMs的有限标记大小。但是,我们还观察到,当前增加LLMs标记限制的趋势将很快解决这些限制之一。
结论
在本文中,介绍了LARK,这是第一个将知识图谱上的逻辑推理与LLMs的能力集成的方法。
本文的方法利用逻辑分解的LLM提示,使得可以在从知识图谱中检索到的子图上进行链式推理,从而有效地利用LLMs的推理能力。
通过在标准知识图谱数据集上进行的逻辑推理实验,证明了LARK在14种不同的FOL查询类型上显著优于先前的最新方法。
最后,还表明,LARK的性能随着规模的增加和底层LLMs的更好设计而改善。证明了可以处理更长输入标记长度的LLMs可以带来显著的性能提升。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









