







Requests库简介
Requests库是python的第三方库,目前公认的爬取网页最好的第三方库。
Requests库的安装
以管理员身份运行cmd
输入 pip install requests
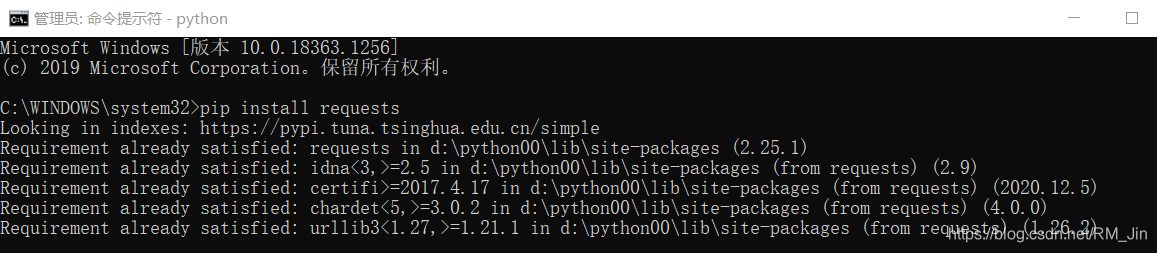
我这里之前已经装好了
来看看requests库有没有安装成功
打开python(可直接在命令行输入python)
import requests# 导库
r = requests.get("https://so.gushiwen.org/shiwenv_2d0368e3fb76.aspx") #获取古诗文网url
r.status_code #查看状态码,200表示网页已经获取成功,其他都不成功
r.encoding = 'utf-8' #编码方式,根据http的header中猜测的响应内容的编码方式
r.text #输出文本
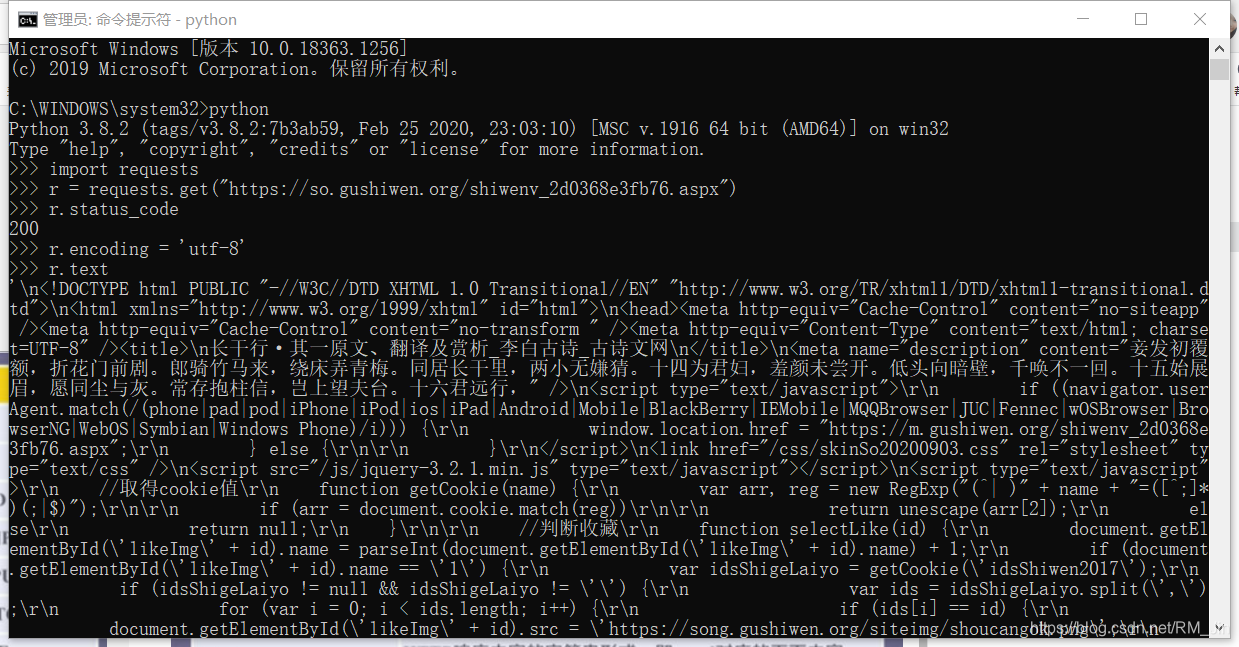
如图,requests库安装成功。
Requests库的常用方法

通过 r=requests.get(url) 方法可构造一个向服务器请求资源的Request对象,并且返回一个包含服务器资源的Response对象(包含从服务器返回的所有的资源,爬虫返回的全部内容)
requests.get(url,params=None,**kwargs)
url:获取页面的URL链接
params:URL中的额外参数,字典或字节流格式,可选
**kwargs:12个控制访问参数,可选
Response对象的属性:

爬取网页的通用代码框架
def getHTMLText(url):#封装成了一个函数
try:
r = requests.get(url,timeout=30)
r.raise_for_status() #如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding #因为apparent更准确
return r.text
except:
return "产生异常"
可以使用户爬取网页更稳定、更可靠

















 460
460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









