







 文章介绍了一种新的零样本提示策略Plan-and-Solve(PS),通过将任务划分为子任务并指导大型语言模型执行,以解决多步骤推理中的计算错误和缺失步骤问题。PS提示在多个数据集上展示了优于零样本CoT和少样本提示的性能。
文章介绍了一种新的零样本提示策略Plan-and-Solve(PS),通过将任务划分为子任务并指导大型语言模型执行,以解决多步骤推理中的计算错误和缺失步骤问题。PS提示在多个数据集上展示了优于零样本CoT和少样本提示的性能。
计划和解决提示:通过大型语言模型改进零样本思维链推理

摘要
最近,大型语言模型 (LLM) 已被证明可以在各种 NLP 任务中提供令人印象深刻的性能。为了解决多步骤推理任务,少镜头思维链(CoT)提示包括一些手动制作的逐步推理演示,使法学硕士能够显式生成推理步骤并提高推理任务的准确性。为了消除手动工作,Zeroshot-CoT 将目标问题陈述与“让我们一步一步思考”连接起来,作为法学硕士的输入提示。尽管 Zero-shot-CoT 取得了成功,但它仍然存在三个缺陷:计算错误、失步错误和语义误解错误。为了解决缺失步骤错误,我们提出了 Planand-Solve (PS) Prompting。它由两个部分组成:首先制定计划,将整个任务划分为更小的子任务,然后根据计划执行子任务。为了解决计算错误并提高生成的推理步骤的质量,我们用更详细的指令扩展了 PS 提示,并派生了 PS+ 提示。我们在三个推理问题的十个数据集上评估了我们提出的提示策略。 GPT-3 上的实验结果表明,我们提出的零样本提示在所有数据集上始终大幅优于零样本 CoT,与零样本思维程序提示相当或超过零样本思维程序提示,并且具有可比的性能对数学推理问题进行 8 次 CoT 提示。代码可以在 https://github.com/AGIEdgerunners/Plan-and-Solve-Prompting 找到。
引言
大型语言模型 (LLM)(Brown 等人,2020;Thoppilan 等人,2022;Chowdhery 等人,2022)最近被证明在各种 NLP 任务中非常有效。与之前的预训练语言模型(PTMs)不同,这些LLM通常作为服务提供,由于商业考虑和潜在的滥用风险,无法访问模型参数(Sun et al., 2022)。因此,针对下游任务微调LLM具有挑战性(He et al., 2021; Houlsby et al., 2019; Devlin et al., 2019)。相反,我们利用LLM通过使用指令(或触发句子)激发其嵌入知识的强大推理能力来解决复杂的推理问题。到目前为止,LLM已经表现出了令人印象深刻的能力,可以通过简单地以一些说明性示例(即少样本学习)为条件或在没有说明性示例的情况下解决新问题的提示(即零样本学习)来解决新的推理问题。
为了使用LLM解决多步骤复杂推理任务,研究者们提出了少样本思维链 (CoT) 提示,使LLM能够在通过一些手动逐步推理演示示例预测最终答案之前显式生成中间推理步骤。零样本 CoT 通过将“让我们一步一步思考”附加到提供给LLM的目标问题中,消除了提示中手动制作示例的需要,例如 GPT-3。这种简单的提示策略令人惊讶地使LLM能够产生类似于小样本 CoT 提示的性能。
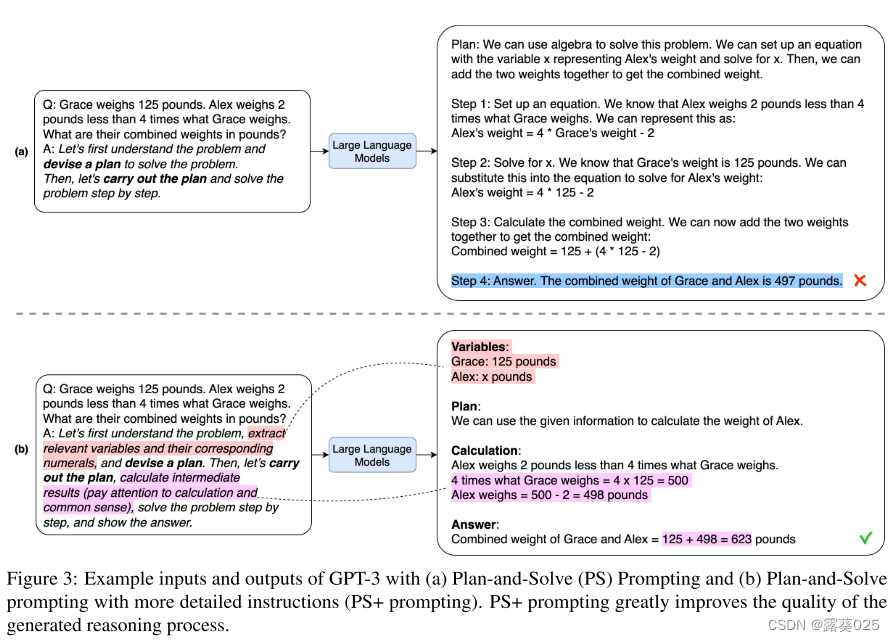
尽管 Zero-shotCoT 在解决多步推理任务方面取得了显着的成功,但其在 100 个算术测试示例样本上的结果仍然存在三个缺陷(如图 1 所示):
(i) 计算错误(测试的 7%)示例):这些是导致错误答案的计算错误;
(ii) 遗漏步骤错误(占测试示例的 12%):当遗漏某些中间推理步骤时,特别是在涉及许多步骤时,就会出现这种情况;
(iii) 语义误解(占测试用例的27%):对问题的语义理解和推理步骤的连贯性还存在其他错误,可能是由于LLM能力不足造成的。

为了解决由于缺少推理步骤而导致的 Zero-shot-CoT 问题,我们提出了 Plan-and-Solve (PS) Prompting。它由两个部分组成:首先制定计划,将整个任务划分为更小的子任务,然后根据计划执行子任务。在我们的实验中,我们简单地将 Zero-shot-CoT 中的“Let’s think step by step”替换为“Let’s first understand the problem
and devise a plan to solve the problem. Then, let’s
carry out the plan and solve the problem step by
step”(让我们首先了解问题并制定解决问题的计划。然后,我们一步步执行计划,解决问题)(见图2(b))。

为了解决 Zero-shot-CoT 的计算错误并提高生成推理步骤的质量,我们在 PS 提示中添加了更详细的指令。具体来说,我们扩展了“提取相关变量及其对应数字(“extract relevant variables and their corresponding numeral)”和“计算中间结果(注意计算和常识)(calculate intermediate results (pay attention to calculation and commonsense))”指令。这种提示变体称为 PS+ 提示策略(见图 3 (b))。尽管 PS+ 策略很简单,但它极大地提高了生成推理过程的质量。此外,这种提示策略可以很容易地定制,以解决数学推理以外的各种问题,例如常识和符号推理问题。
我们在六个数学推理数据集上评估了我们提出的提示,包括 AQuA 、GSM8K 、MultiArith、AddSub、SingleEq 和 SVAMP 、两个常识推理数据集(CommonsenseQA 和 StrategyQA ),以及两个符号推理数据集(Last Letter 和 Coin Flip)。
我们使用 GPT-3 进行的实验结果表明,我们提出的 Zero-shot-PS+ 提示在所有推理问题和数据集上始终大幅优于 Zero-shot-CoT,并且与 Zeroshot-Program-of-Thought 相当或超过(PoT)提示。此外,尽管 PS+ 提示不需要手动演示示例,但它在算术推理中具有类似于 8-shot CoT 提示的性能。
总的来说,我们的结果表明:
(a) 零样本 PS 提示能够比零样本 CoT 提示生成更高质量的推理过程,因为 PS 提示提供了更详细的指令,指导法学硕士执行正确的推理任务;
(b) 在某些数据集上,零样本 PS+ 提示优于少样本手动 CoT 提示,这表明在某些情况下它有可能优于手动少样本 CoT 提示,这有望激发新的 CoT 提示方法的进一步开发在LLM中引发推理。
2 计划与解决提示概述
我们引入了 PS 提示,这是一种新的零样本 CoT 提示方法,它使LLM能够明确地设计解决给定问题的计划,并在预测输入问题的最终答案之前生成中间推理过程。与之前的少样本 CoT 方法在提示中包含逐步的少样本演示示例不同,零样本 PS 提示方法不需要演示示例,其提示涵盖了问题本身和简单的触发器句子。与 Zero-shot-CoT 类似,Zero-shot PS 提示包含两个步骤。在步骤1中,提示首先使用建议的提示模板进行推理,生成推理过程和问题的答案。步骤2,利用答案提取提示,例如“因此,答案(阿拉伯数字)是”,提取评价答案。
2.1 步骤1:提示推理生成
为了解决输入问题,同时避免由于计算错误和推理步骤缺失而导致的错误,此步骤旨在构建满足以下两个条件的模板:
• 模板应该引导LLM确定子任务并完成这些子任务。
• 模板应指导LLM更多地关注计算和中间结果,并尽可能确保它们正确执行。
为了满足第一个标准,我们遵循 Zero-shot-CoT,首先将输入数据示例转换为带有简单模板
“Q: [X].A:[T]”。
具体来说,输入槽 [X] 包含输入问题陈述,并且在输入槽 [T] 中指定手工制作的指令,以触发 LLM 生成推理过程,其中包括计划和完成计划的步骤。
在零样本CoT中,输入槽[T]中的指令包括触发指令“让我们一步一步思考”。我们的零样本 PS 提示方法包括“制定计划”和“执行计划”的指令,如图 2(b)所示。因此,提示将是“Q:[X]. A:我们首先要了解问题并制定解决问题的方案。那么,我们就按照计划一步一步地解决问题吧。”然后,我们将上述提示传递给 LLM,LLM 随后输出推理过程。
根据 Zero-shot-CoT,我们的方法默认使用贪婪解码策略(1 个输出链)来生成输出。为了满足第二个标准,我们用更详细的说明扩展了基于计划的触发语句。具体来说,在触发语句中添加“注意计算”,要求LLM尽可能准确地进行计算。
为了减少因缺少必要的推理步骤而导致的错误,我们添加了“提取相关变量及其相应数字”,以明确指示LLM不要忽略输入问题陈述中的相关信息。我们假设,如果LLM遗漏了相关且重要的变量,则更有可能错过相关的推理步骤。变量生成内容与缺失推理步骤错误的相关分析如图 5 所示,在经验上支持了这一假设(相关值小于 0)。此外,我们在提示中添加了“计算中间结果”,以增强 LLM 生成相关且重要的推理步骤的能力。具体示例如图3(b)所示。在第 1 步结束时,LLM 生成包含答案的推理文本。例如,图 3(b) 中生成的推理文本包括“Grace 和 Alex 的组合重量 = 125 + 498 = 623 磅”。在触发语句中添加具体描述的策略代表了一种提高复杂推理零样本性能的新方法。
2.2 步骤2:提示提取答案
与 Zero-shot-CoT 类似,我们在步骤 2 中设计了另一个提示,让 LLM 从推理文本生成器中提取最终的数字答案在步骤 1 中完成。此提示包括附加到第一个提示的答案提取指令,后跟 LLM 生成的推理文本。这样,LLM 有望以所需的形式返回最终答案。
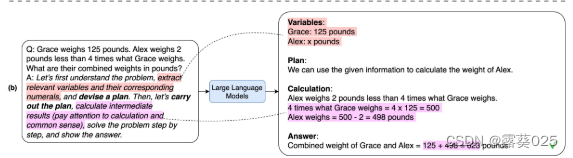
根据图 3(b) 中的示例,步骤 2 中使用的提示将包括“Q:Grace 体重 125 磅····变量:Grace:125 磅····答案:Grace 和 Alex 的总重量 = 125 + 498 = 623 磅。因此,答案(阿拉伯数字)是”。对于这个例子,LLM返回的最终答案是“623”。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









