







植被覆盖度(Fractional Vegetation Cover, FVC)遥感反演方法及GLASS、GEOV等FVC产品
如有需求,博主可提供全球任意地区FVC,FVC相关实验设计,欢迎私信我。qq:1850436915
植被覆盖度定义:一般是指植被(包括叶、茎、枝)在地面的垂直投影面积占统计区总面积的百分比。
遥感反演方法常用的包括:像元二分法、回归模型法、机器学习算法等
本博文介绍以上几种方法的具体实验步骤。
1.1 像元二分法:本文介绍以单一遥感影像生成多尺度FVC数据(MODIS:250m,Landsat 30m,Sentinel-2:10m)(影像选点法,或置信区间法计算),依靠Google Earth Engine 平台快速生成长时序FVC数据(置信区间法)。
1.2 回归模型法实际用得不多,本文以一元线性回归进行实验。
1.3 机器学习算法需要有实测FVC数据。
2. FVC产品数据处理及应用
3. FVC相关模拟研究,例如FVC动态变化趋势、FVC变化影响因子
1.1 像元二分法:
1.1.1 影像选点
公式: FVC = (VI - VIsoil) / ( VIveg - VIsoil)
式中:VI为植被指数,通常选用归一化差分植被指数,VIsoil选定的裸土端元VI值,VIveg为植被端元VI。
什么意思呢?我们先来举一个简单的例子:
我们在沙漠地区选中一点(地区没有或只有很少植被),(图为MOD13Q1,NDVI值由小到大依次为:橙-黄-绿渐变),该点NDVI值为0.059,那么该值可以作为VIsoil的值,即选定的裸土端元VI值。


同样,在植被茂盛的地区
 我们可以选取0.911,该值作为VIveg的值,即选定的植被端元VI值。
我们可以选取0.911,该值作为VIveg的值,即选定的植被端元VI值。
现在,我们来看在专业软件(ENVI或者ArcGIS)像元二分法的操作步骤:
(1)数据源获取,所需数据:NDVI、EVI等植被指数,本文以归一化差分植被指数NDVI为例。
本文使用的数据为MODIS的MOD13Q1植被产品,产品具体介绍省略。该产品提供250m的NDVI数据,可以从LPDAAC网址中下载,也可以在GEE平台中调用(当然,后续也会介绍如何直接用GEE生成FVC数据)。
为了方便,我在GEE平台上下载,需要2000~2024年逐月或逐年MODIS NDVI最大值结果可以私信我。下图为部分亚洲地区年NDVI最大值影像。
时序数据:

现在,以QTP为研究区,使用NDVI反演FVC(ENVI软件)
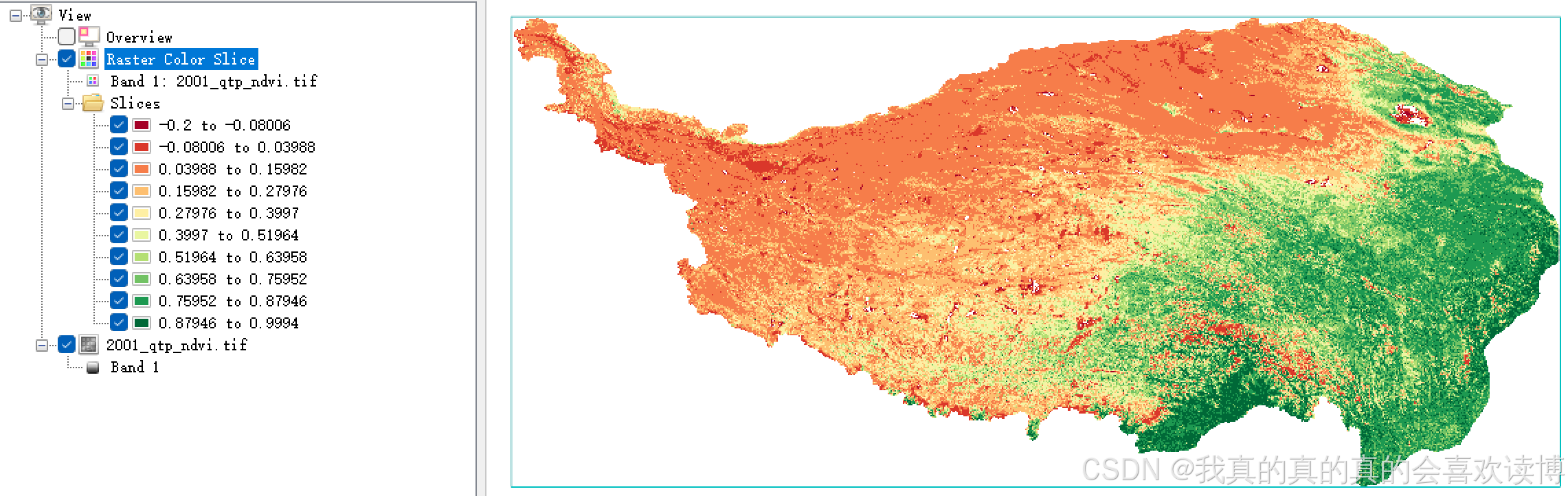
NDVI正常的值范围在0~1之间,但不免会有一些负值(云雪雨水等,少部分土壤也有可能为负值),但这些数量非常少,可以忽略不计。下图为正常NDVI值。

但是,如果你并非用GEE制作NDVI,在NASA官网下载并使用MRT软件处理,很有可能出现异常值:
MRT转投影,重采样后还需要进行以下操作:
1)MOD13Q1 NDVI需要进行拼接、裁剪等预处理后,原始数据像元值为整型,需要乘比例系数0.0001,即NDVI值范围处于[-1,1]之间。
2)在某些软件中,加载MODIS NDVI影像后,会出现一片白/黑的现象,原因可能是存在背景值,或者是MOD13Q1数据统计值异常(存在着一个很大或很小的值)。
需要去除异常值的情况:下图可以看到,影像的统计信息又99%的像元DN<0,部分像元DN值非常大。


此时需要通过波段计算去除异常值:b1 为植被指数的波段,
lt ( less than)-1 指的是小于-1的值;*0表示赋值为0;
(b1 ge(greather equal )-1 and b1 le(less equal)1)指 b1 大于等于-1且小于等于1的值; *b1指赋值为b1

现在,大家的影像应当是正常的影像,我们可以开始用像元二分法进行FVC反演。
通过波段计算即可获得区域FVC影像
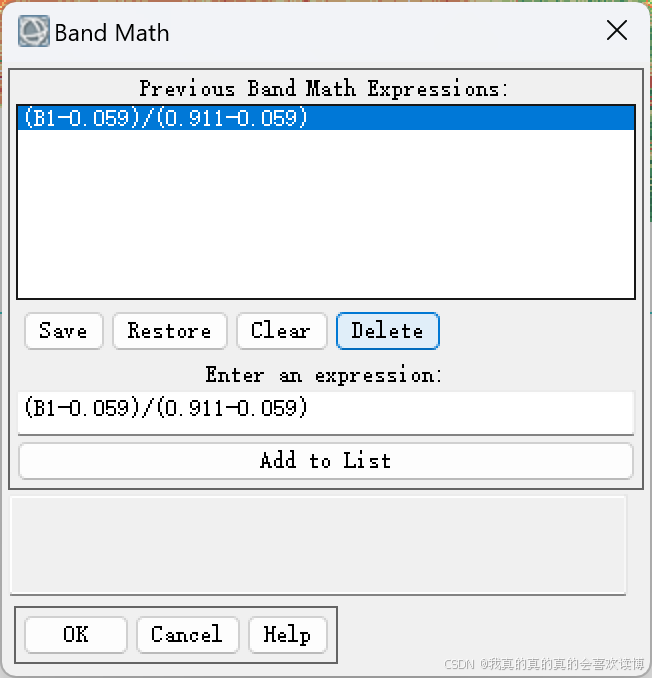
0.059和0.911为本文最开始,在遥感影像上选的两点的值。这实际上是一种 目视解译遥感影像选取纯植被/裸土端元值选取的方法,可以直接使用这两个值计算出研究区的FVC值。
1.1.2 置信区间法
此外,还有另一种方法,即置信区间法选取 纯植被/裸土端元端元值 。我们通过ENVI软件,右击影像,点击“快速统计”。该操作能让你快速了解影像像元值分布(最大值,最小值,均值等)。
置信区间法,是将影像像元值先由大到小或由小到大排列。理论上,纯裸土的NDVI值为0,但由于多种因素(大气、传感器等)影响,纯裸土的NDVI值不可能0。那么5%的置信区间,表示将前5%的像元认为是纯裸土,即在“快速统计”中为第五列,将纯裸土端元像元值设置为:0.044624(置信区间5%),也可以选2%,此时纯裸土端元像元值设置为-0.002419,当然,也有其他的置信区间,需根据你的研究区进行选择。(通常,纯裸土端元值范围在-0.1 ~ 0.2之间)
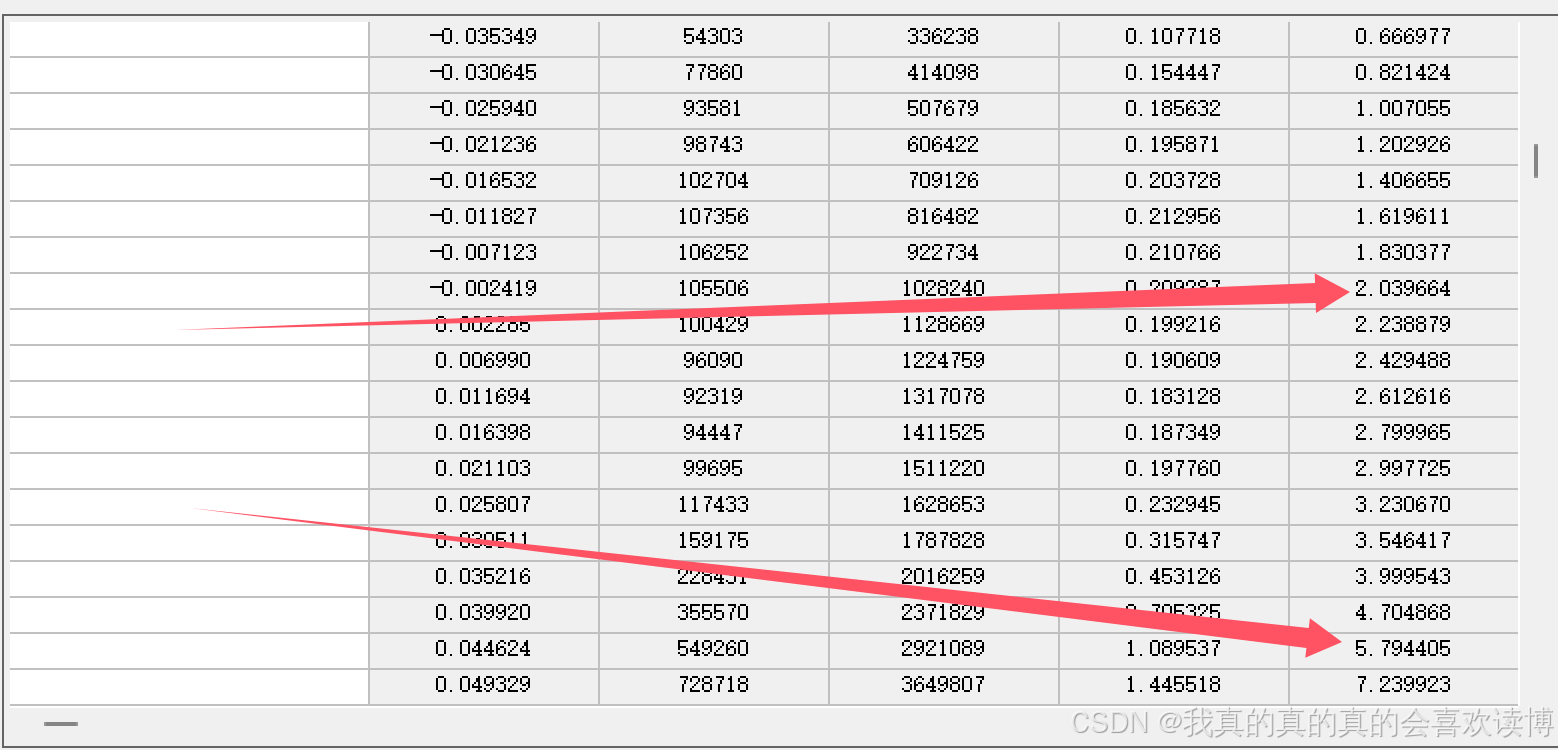
设置好纯裸土端元值,我们再看看纯植被端元值。
置信区间5%:纯植被端元像元值为:0.863
置信区间2%:纯植被端元像元值为:0.905
最后,使用Band math计算FVC
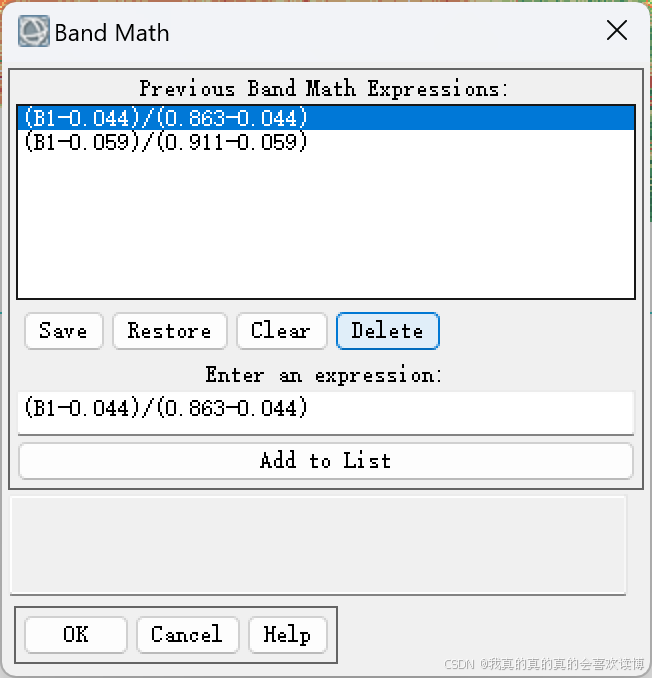
选取B1波段对应2001NDVI,设置输出路径,即可计算出区域尺度的植被覆盖度:
计算出的FVC:
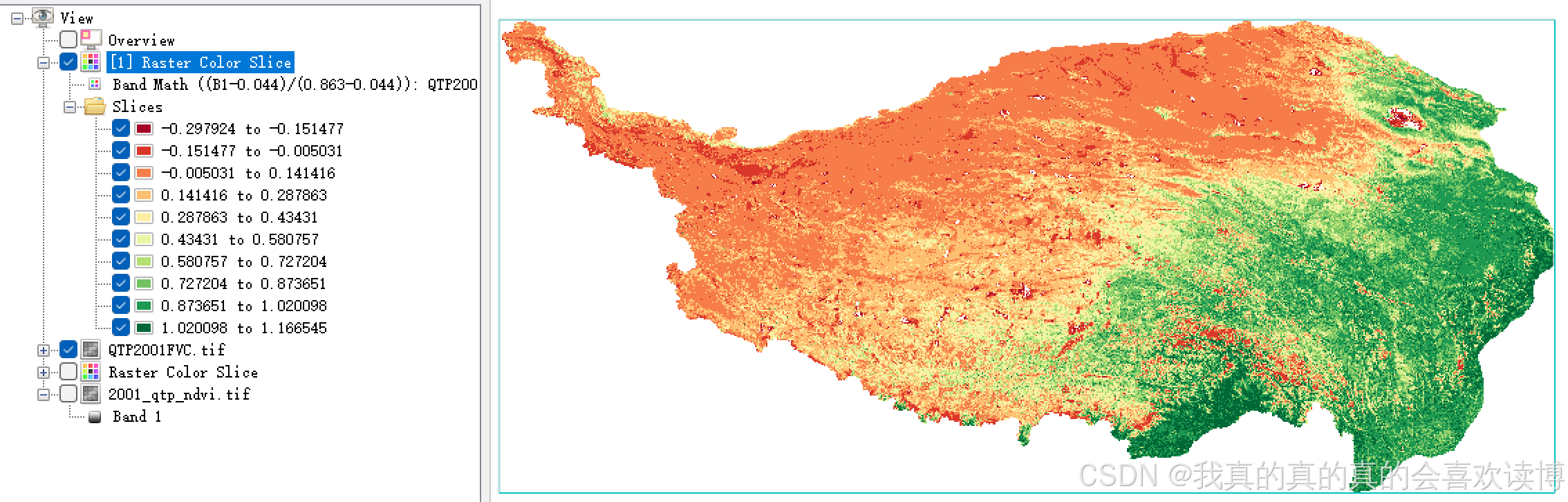
最后,根据FVC的定义,应当把计算出的FVC值归为0到1之间(再次利用Band Math)
小结:不同选取纯植被/裸土端元值的方法,有各自的优缺点
基于遥感影像选取:需要目视解译高空间分辨率遥感影像,手动选择土壤或植被像元,并记录其端元值,比较麻烦,且需要对当地有较好的认知(需要找到纯裸土区域),即使是Landsat影像分辨率也有不足,因为30m×30m的裸土范围应该较少,因此,需要10m/2m/1m的高空间分辨率遥感影像。
基于置信区间法:基于置信区间法选取端元值简单易操作,但是如果一个区域有茂密的植被,而你的影像空间分辨率为中等,那么纯裸土端元很难选择(例如:广西、云南、贵州夏季),裸土端元的低估会造成FVC的高估[1],因此,应该结合地域、季节,慎重选择端元值。
[1] Montandon L M, Small E E. The impact of soil reflectance on the quantification of the green vegetation fraction from NDVI - ScienceDirect[J]. Remote Sensing of Environment, 2008, 112( 4):1835-1845.
剩下两种方法(经验回归模型和机器学习)均需要实测FVC数据。
1.2 经验回归模型法:植被指数、光谱波段线性回归 。
经验回归模型法指的是FVC和某一遥感影像的波段或植被指数之间呈现一定的关系。
FVC反演值=a×NDVI+b(最简单的一次线性函数,也可以为指数、二次函数等等)

在最小二乘条件下,能得到散点唯一的条拟合直线。此时,我们可以对一张遥感影像使用Band Math:

B1为植被指数数据或者反射率数据,而0.1和0.9实际上是拟合直线的斜率以及截距。通过计算我们可以得到区域尺度的植被覆盖度数据。
1.3 机器学习方法:随机森林、支持向量机、多元自适应回归样条、高斯过程回归、神经网络、卷积神经网络等等
机器学习方法也很简单,我们需要收集实测FVC数据(表中为GLASS),以及辅助数据(列2:列7)。
在MATLAB中把实测FVC数据作为目标数据,把辅助数据作为驱动数据,使用70%(不唯一)的随机样本来训练模型,余下30%的数据用来测试模型。

最后,我们训练得到模型,并测试模型的准确性(通常为决定系数,以及均方根误差)。
在编程软件中,将遥感影像叠加,顺序需要和训练模型时的顺序一致,例如(BLUE、RED、NIR、NDVI、SAVI、EVI)。叠加后实际上是7个波段的影像集合,一个像元拥有七个波段的信息。在编程软件中,遥感影像可以看成是一个矩阵,X,Y:(行和列,也可以为坐标),"Z"信息为像元携带的值(x1~x7)。模型f(x1~x7)即可计算出区域尺度的FVC。(写的匆忙,后期再改)
1.3 机器学习方法(2024 03 11)MATLAB
思路:
(1)构建数据集(包括测试集和训练集)
例如:M~O列为驱动数据;P列为目标数据

(2)构建反演模型(以一个简单的随机森林回归模型为例)
反演模型在MATLAB里面有很多,很多CSDN博主也有很多模型的代码,只需运行出来
clear % 清空变量
clc % 清空命令行
TRAIN = xlsread('G:\\TR.xlsx');%%训练集目录
TEST= xlsread('G:\\TR.xlsx'); %%测试集目录
P_train = TRAIN(:, 2: 4)'; %%训练集读取xlsx全部的行,2~4列 (驱动数据)
T_train = TRAIN(:,1)'; %%训练集读取xlsx全部的行,1列 (目标数据)
M = size(P_train, 2);
P_test = TEST(: ,2: 4)';
T_test = TEST(: , 2)';
N = size(P_test, 2);
%% 转置以适应模型
p_train = P_train'; p_test = P_test';
t_train = T_train'; t_test = T_test';
%% 训练模型
trees = 500; % 决策树数目
leaf = 50; % 最小叶子数
OOBPrediction = 'on'; % 打开误差图
OOBPredictorImportance = 'on'; % 计算特征重要性
Method = 'regression'; % 分类还是回归
net = TreeBagger(trees, p_train, t_train, 'OOBPredictorImportance', OOBPredictorImportance,...
'Method', Method, 'OOBPrediction', OOBPrediction, 'minleaf', leaf);
importance = net.OOBPermutedPredictorDeltaError; % 重要性
%% 模拟
t_sim1 = predict(net, p_train);
t_sim2 = predict(net, p_test );
%% 均方根误差
error1 = sqrt(sum((t_sim1' - t_train).^2) ./ M);
error2 = sqrt(sum((t_sim2' - t_test ).^2) ./ N);
%% 绘图
figure
plot(1: M, t_train, 'r-*', 1: M, t_sim1, 'b-o', 'LineWidth', 1)
legend('真实值','预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'训练集预测结果对比'; ['RMSE=' num2str(error1)]};
title(string)
xlim([1, M])
grid
figure
plot(1: N, t_test, 'r-*', 1: N, t_sim2, 'b-o', 'LineWidth', 1)
legend('真实值','预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'测试集预测结果对比';['RMSE=' num2str(error2)]};
title(string)
xlim([1, N])
grid
%% 绘制误差曲线
figure
plot(1 : trees, oobError(net), 'b-', 'LineWidth', 1)
legend('误差曲线')
xlabel('决策树数目')
ylabel('误差')
xlim([1, trees])
grid
%% 绘制特征重要性
figure
bar(importance)
legend('重要性')
xlabel('特征')
ylabel('重要性')
%% 相关指标计算
% R2
R1 = 1 - norm(t_train - t_sim1')^2 / norm(T_train - mean(t_train))^2;
R2 = 1 - norm(t_test - t_sim2')^2 / norm(T_test - mean(t_test ))^2;
disp(['训练集数据的R2为:', num2str(R1)])
disp(['测试集数据的R2为:', num2str(R2)])
% MAE
mae1 = sum(abs(t_sim1' - t_train)) ./ M;
mae2 = sum(abs(t_sim2' - t_test )) ./ N;
disp(['训练集数据的MAE为:', num2str(mae1)])
disp(['测试集数据的MAE为:', num2str(mae2)])
% MBE
mbe1 = sum(t_sim1' - t_train) ./ M ;
mbe2 = sum(t_sim2' - t_test ) ./ N ;
disp(['训练集数据的MBE为:', num2str(mbe1)])
disp(['测试集数据的MBE为:', num2str(mbe2)])完毕后,用save model保存模型即可。
![]()
(3)制作空间分布图。
先加载模型
![]()
放入波段数据,在这里为了便于分析,我将一幅影像的波段重命名为:Blue(2001.tif)、Green(2002.tif)、Red(2003.tif)、NIR(2004.tif),将其依次读取并做成一个有空间位置信息的大矩阵。


Blue(2001.tif)、Green(2002.tif)、Red(2003.tif)、NIR(2004.tif)为4个驱动数据,对应一个目标数据(反演结果,也是FVC)。
我感觉可以这么想:4张影像(例如Blue、Green、Red、NIR)叠加。影像大小200*200
那么现在是200行*200列*4
将其平铺为40000(行)*4(列),
取出第1行(data1)放入随机森林回归模型predict(net,data)

随机森林回归模型(Blue、Green、Red、NIR)——>预测FVC值,这个值就是第一行第一列预测的像元值。逐个预测,依次填回影像。最后可以得到FVC机器学习反演结果,带经纬度信息。

2. 植被覆盖度产品数据
GLASS、GEOV1、GEOV2、GEOV3、MuSyQ FVC使用及处理教程
GEOV3全球数据很大,但可以定制区域,详细过程目前还没时间写。
2.1 GLASS FVC/ LAI /GPP 产品(2000~2021):时间分辨率:8天,一年46期
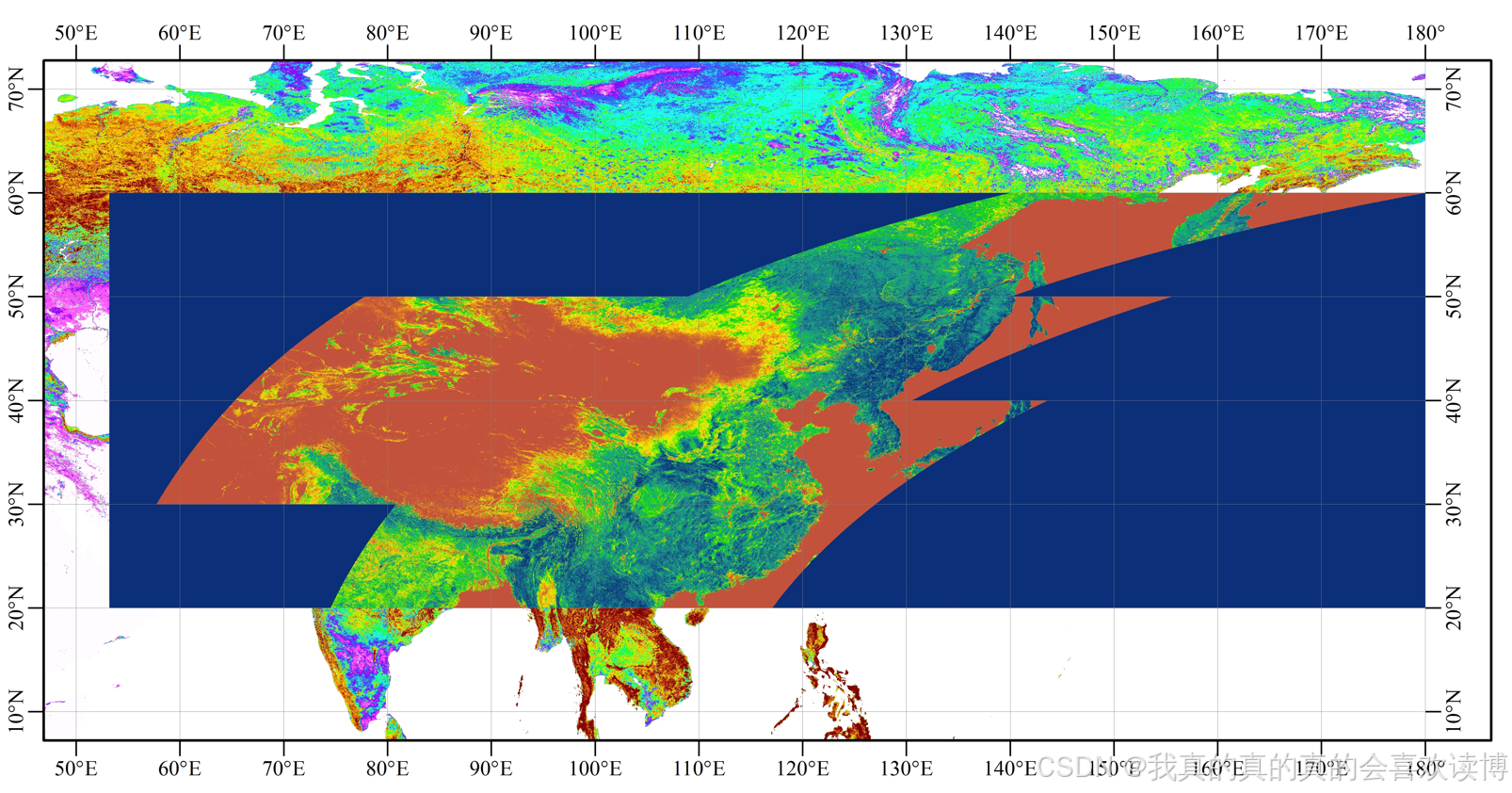
2.2 GEOV1 、 GEOV2 (2000~2019)/ GEOV3 (2014~至今)产品,合成周期10天,一个月3期,一年36期
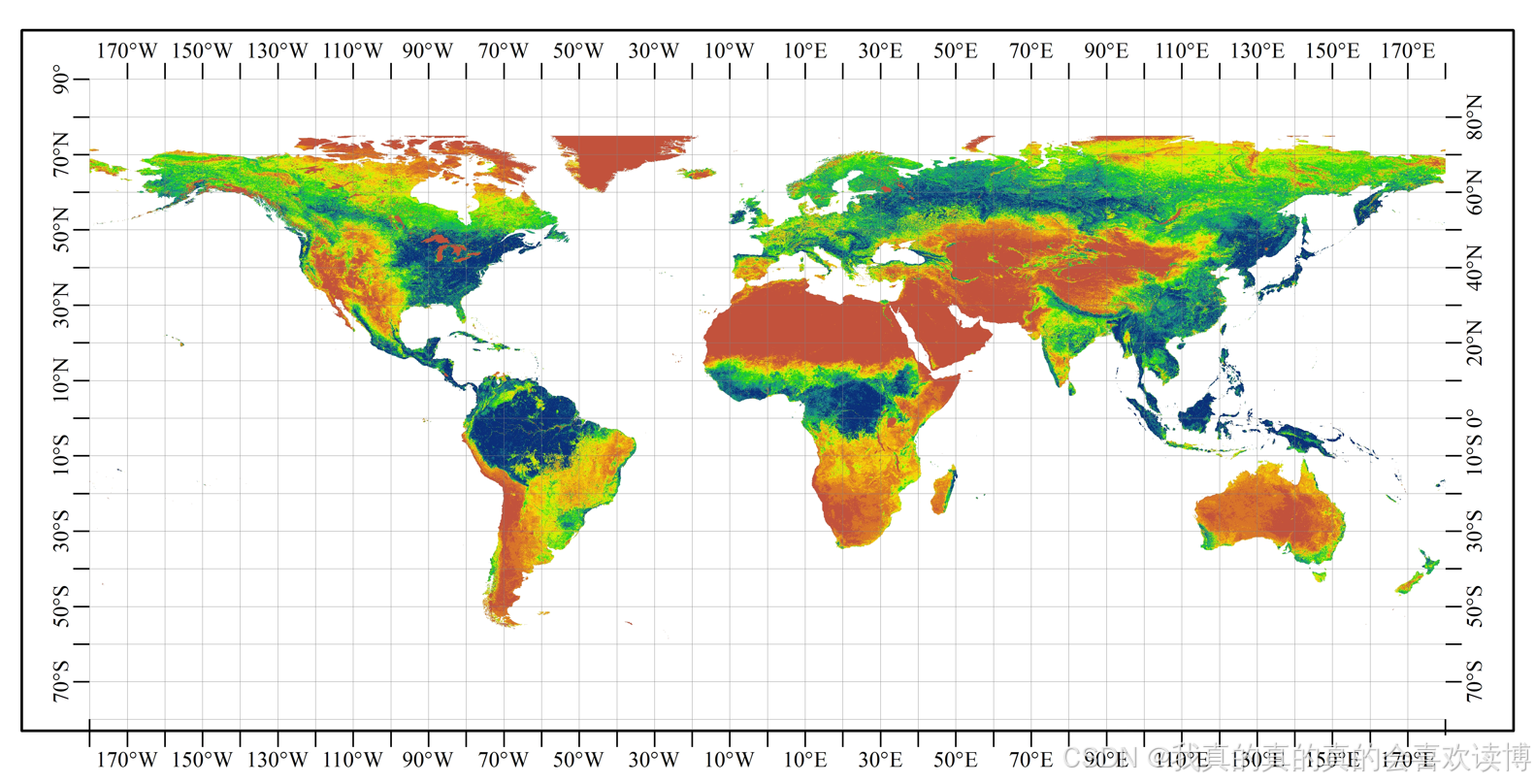
来源:哥白尼全球土地服务中心(https://land.copernicus.eu/global/products/fcover)
参考文献:
Fuster, B.; Sánchez-Zapero, J.; Camacho, F.; García-Santos, V.; Verger, A.; Lacaze, R.; Weiss, M.; Baret, F.; Smets, B. Quality Assessment of PROBA-V LAI, FAPAR and FCOVER Collection 300 m Products of Copernicus Global Land Service. Remote Sens. 2020, 12, doi:10.3390/rs12061017.
Baret, F.; Weiss, M.; Lacaze, R.; Camacho, F.; Makhmara, H.; Pacholcyzk, P.; Smets, B. GEOV1: LAI and FAPAR Essential Climate Variables and FCOVER Global Time Series Capitalizing over Existing Products. Part1: Principles of Development and Production. Remote Sens. Environ. 2013, 137, 299–309, doi:10.1016/j.rse.2012.12.027.
Verger, A.; Baret, F.; Weiss, M. Biophysical Variables from VEGETATION-P Data. MultiTemp 2013 7th Int. Work. Anal. Multi-temporal Remote Sens. Images. IEEE, 2013, 10–13.
2.3 MuSyQ FVC产品数据
来源:国家地球系统科学数据中心首页 申请后通过邮箱FTP获取
参考文献:
Zhao J , Li J , Liu Q , et al., 2020. Estimating fractional vegetation cover from leaf area index and clumping index based on the gap probability theory. International Journal of Applied Earth Observation and Geoinformation 90:102112.
数据时空分辨率为4d/500m,时间范围:2001~2021,空间范围:全球
HDF5(H5) 可以通过MATLAB、Python打开,并转化为tif
3. 植被覆盖度动态变化分析
3.1 趋势分析
所需数据:研究区时间序列影像,下面补充一些常用的影像处理知识。
打开建模工具

插入循环工具,循环栅格(Rasters)


将工具拖入模型内

放入栅格:选择的一定是循环文件
掩膜文件:可以是矢量,也可以是栅格(研究区/感兴趣区域)
%name%表示输出文件的名字与放入文件的名字一模一样。

点击开始运行即可

得到了23张研究区的时间序列影像。

3.1.1 一元线性回归
3.1.2 Sen+MK
需要的数据:研究区的时间序列影像,所有影像行列必须一致,坐标系统,空间分辨率等基本信息完全一致。
放入MATLAB里,注意修改参数信息,(代码C站里有很多)。

Sen趋势计算结果:

最后再重分类:
先看到MODIS_Sen.tif的像元值分布

栅格值小于0的(斜率小于0)的栅格赋值为1;栅格值大于0的(斜率大于0)的栅格赋值为2.
重分类结果:1表示该区域FVC有减小趋势,2表示该区域FVC有增加趋势。

3.2 相关分析,偏相关分析以及复相关分析
例如:探究A区域植被覆盖度变化与温度、降水之间的关系。
相关分析:放入2000~2023年FVC时间序列影像及2000~2023年平均气温等数据,计算出的结果为相关系数。
详细可以参考:(2024.3.14)
3.3 基于地理探测器,探究影影响FVC动态变化的因子
3.3.1 创建渔网
(1)选择栅格
DEM数据完整度高,栅格像元基本无缺失值,故选取DEM数据创建渔网。
DEM数据采用的是Copernicus DEM。
在该网站有其详细介绍:https://developers.google.com/earth-engine/datasets/catalog/COPERNICUS_DEM_GLO30
The Copernicus DEM is a Digital Surface Model (DSM) which represents the surface of the Earth including buildings, infrastructure and vegetation. This DEM is derived from an edited DSM named WorldDEM&trade, i.e. flattening of water bodies and consistent flow of rivers has been included. Editing of shore- and coastlines, special features such as airports and implausible terrain structures has also been applied.
The WorldDEM product is based on the radar satellite data acquired during the TanDEM-X Mission, which is funded by a Public Private Partnership between the German State, represented by the German Aerospace Centre (DLR) and Airbus Defence and Space. More details are available in the dataset documentation.
Earth Engine asset has been ingested from the DGED files.
DEM数据一般需要分块下载,GEE平台可以完成对这些块块的拼接与裁剪。这里给出GIS中如何拼接(镶嵌)。
例如:当前有两块区域。





镶嵌方式中,选择最大值方法为:这组栅格数据重叠的区域最大值(不重叠则直接镶嵌)。
选择First方法为:这组栅格数据重叠的区域的值为第一张影像的值(本例中为85E27N(如果这两幅影像重叠))。
(2)基于栅格创建渔网及点
数据管理——采样——创建渔网
![]()




一片黑,将其放大之后表明:设置为1000m显然间隔太近。一共生成4.5万个点(注意:渔网生产的总点数最好别超过3万个点,EXCEL版地理探测器限制)
(3)提取栅格值至点
地理探测器首先要有一组变化的数据,例如2000~2020年MODIS NDVI、FVC等等
现在用一组MODIS_LST演示,
 空间分析——提取——提取多值到点
空间分析——提取——提取多值到点

提取名字一定要认真对待!打开渔网点属性表,现在已经完成了变化数据的提取

现在是影响因子数据,可以是时序数据,也可以为年平均值数据(例如道路,GDP,人口密度等数据)
在重分类中,利用自然间断点法(也可以手动设置),将影响因子数据重分类(多少类看你自己的选择)。


这里演示的是将一副影响因子(假设为GDP数据)影像的值分为5类:

再次提取栅格值至点并将其输出:

(4)地理探测器的使用
打开地理探测器(excel),复制数据,读取数据,Y因子选择主数据(温度变化,植被覆盖变化等等),X因子为重分类后的影响因子数据(坡度、高程、坡向等等)

点击运行即可。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









