






目录
一、K均值聚类算法(K-Means)算法简介
(一)聚类算法
聚类算法作为一种无监督学习方法其主要目的是将未标注的数据集中的样本划分为若干个不相干的子集,这些子集被称为簇(cluster)。聚类算法通过计算各个样本之间的相似性来将具有类似特征的的数据点划分到同一个簇中。其主要被应用于用户画像、广告推荐、图像分割以及降维等方向。
(二)K-Means聚类算法
K-means聚类算法是一种最简单的无监督学习算法,属于基于划分的聚类算法,是数据挖掘的十大经典算法之一。算法的主要思想是利用距离作为两个数据点相似性的评价指标,把得到紧凑且独立的簇作为最终目标。
K近邻算法(K nearest neighbor KNN)算法与K-Means算法相近,都是以距离为评价指标的算法,不同的是KNN算法是监督学习,其训练集有明确标注,对测试点的预测是根据距其最近的K个已标注点进行的(多数表决原则),而K-means算法中的K是指预先设定K个簇。
二、K均值聚类算法流程
①选定簇数量K的值;
②在样本数据集中选取K个点作为初始质心,即
③计算训练集D中每个样本到每个质心
的欧式距离
;
④若的距离最小,则将样本
标记为簇
中的样本;
⑤利用欧氏距离最小的原则将所有的样本数据点分配到不同的簇后,计算新的质心;
⑥如果质心更新了,则跳转到③,否则算法结束,输出结果。(样本数过多时可以设置最大迭代次数)
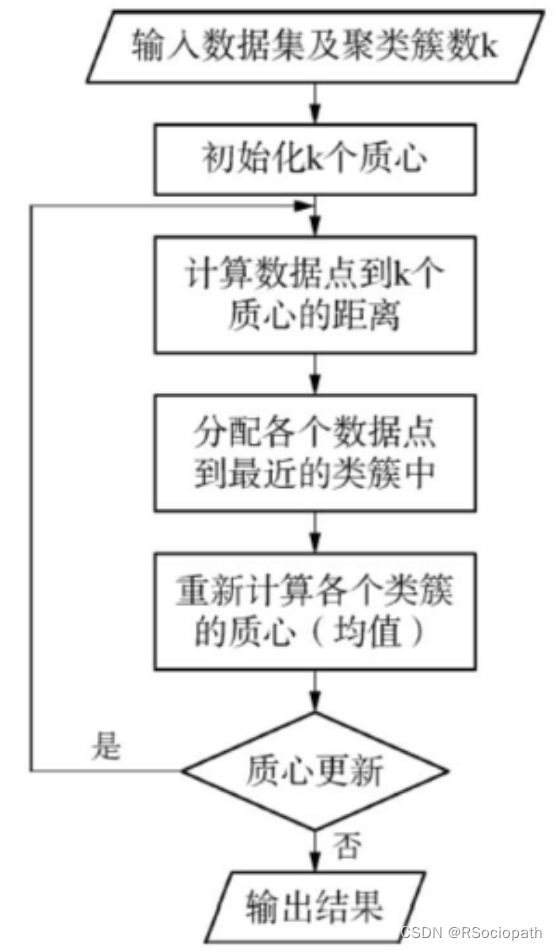
图2-1:K-Means算法流程
三、代码实现
(一)所用库
from sklearn.datasets._samples_generator import make_blobs #生成样本数据
from matplotlib import pyplot as plt #可视化
from sklearn.cluster import KMeans #聚类(二)绘制散点图
X,Y=make_blobs(n_samples=100,centers=5)
plt.figure(figsize=(8,5),dpi=144)
plt.scatter(X[:,0],X[:,1],s=50,edgecolors='k')
plt.show()(三)K-Means算法拟合
kmean=KMeans(3)#设置K值为3
kmean.fit(X)(四)聚类结果
labels=kmean.labels_
centers=kmean.cluster_centers_
fig=plt.figure(figsize=(8,5),dpi=144)
plt.scatter(X[:,0],X[:,1],c=labels.astype(int),s=50,edgecolors='k')
plt.scatter(centers[:,0],centers[:,1],c='r',s=100,marker='*')
plt.show()四、结果
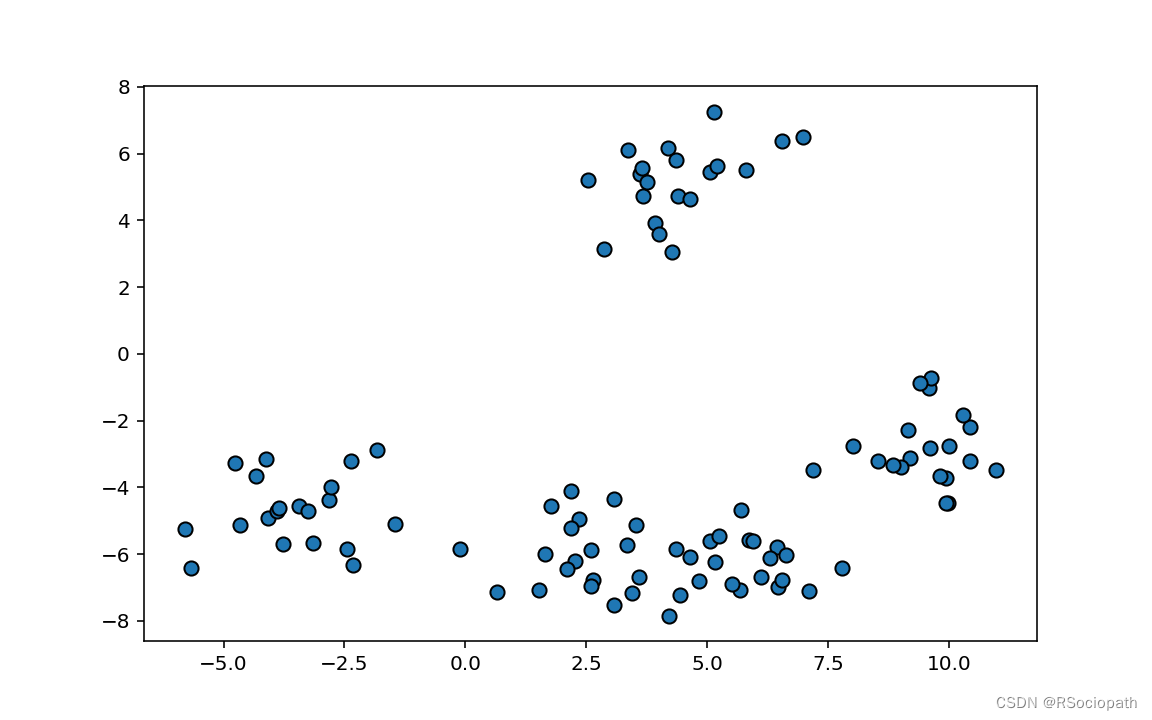
图4-1 :未标注散点图
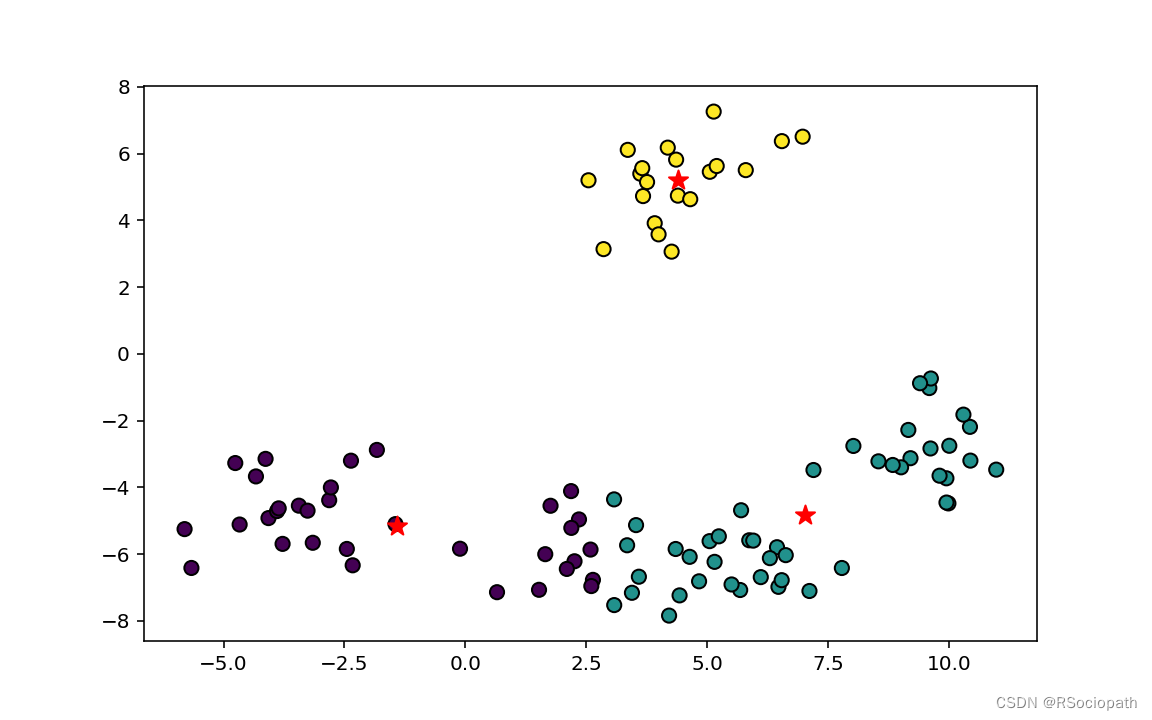 图4-2: 聚类结果散点图
图4-2: 聚类结果散点图















 1248
1248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









