







一、使用PyTorch复现课上例题
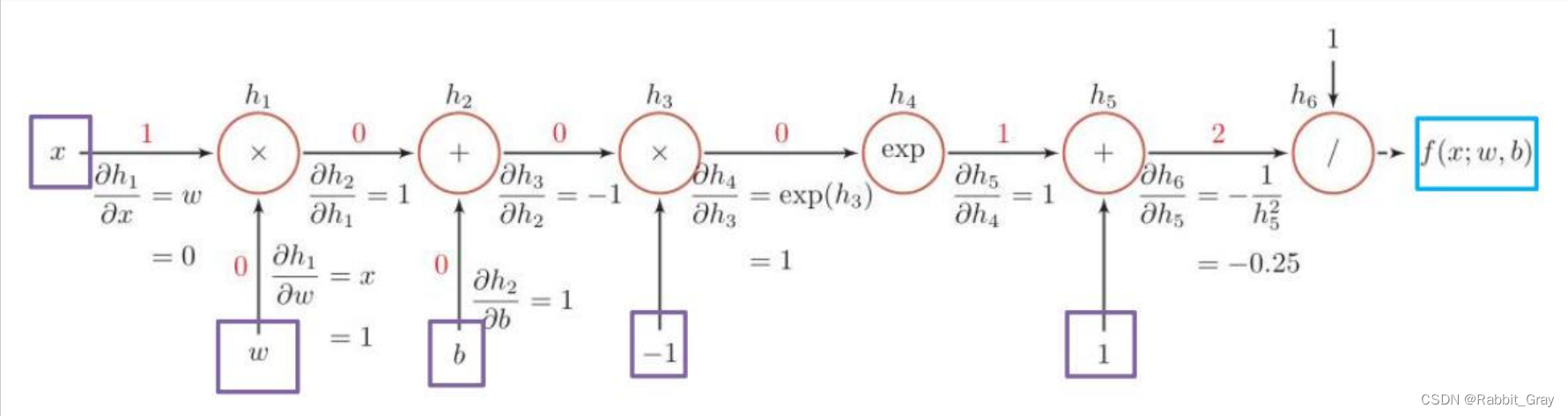
import torch
x = torch.tensor(1.)# , requires_grad=True)
w = torch.tensor(0. , requires_grad=True)
b = torch.tensor(0. , requires_grad=True)
# 开始动态构建计算图(前向传播过程中计算数值、设置grad_fn)
h1 = w * x
h2 = h1 + b
h3 = h2 * (-1)
h4 = torch.exp(h3)
h5 = h4 + 1
h6 = 1 / h5
y = h6
# y = 1/(torch.exp(-(w*x+b))+1)
# 反向传播(计算利用grad_fn计算grad)
y.backward()
print(x.grad)
print(w.grad)
print(b.grad)
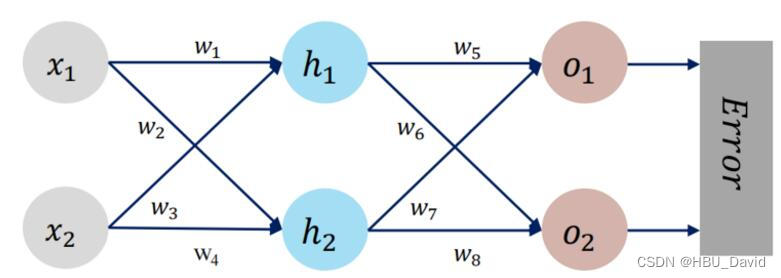
import torch
x1, x2 = torch.Tensor([0.5]), torch.Tensor([0.3])
y1, y2 = torch.Tensor([0.23]), torch.Tensor([-0.07])
print("=====输入值:x1, x2;真实输出值:y1, y2=====")
print(x1, x2, y1, y2)
w1, w2, w3, w4, w5, w6, w7, w8 = torch.Tensor([0.2]), torch.Tensor([-0.4]), torch.Tensor([0.5]), torch.Tensor(
[0.6]), torch.Tensor([0.1]), torch.Tensor([-0.5]), torch.Tensor([-0.3]), torch.Tensor([0.8]) # 权重初始值
w1.requires_grad = True
w2.requires_grad = True
w3.requires_grad = True
w4.requires_grad = True
w5.requires_grad = True
w6.requires_grad = True
w7.requires_grad = True
w8.requires_grad = True
def sigmoid(z):
a = 1 / (1 + torch.exp(-z))
return a
def forward_propagate(x1, x2):
in_h1 = w1 * x1 + w3 * x2
out_h1 = sigmoid(in_h1) # out_h1 = torch.sigmoid(in_h1)
in_h2 = w2 * x1 + w4 * x2
out_h2 = sigmoid(in_h2) # out_h2 = torch.sigmoid(in_h2)
in_o1 = w5 * out_h1 + w7 * out_h2
out_o1 = sigmoid(in_o1) # out_o1 = torch.sigmoid(in_o1)
in_o2 = w6 * out_h1 + w8 * out_h2
out_o2 = sigmoid(in_o2) # out_o2 = torch.sigmoid(in_o2)
print("正向计算:o1 ,o2")
print(out_o1.data, out_o2.data)
return out_o1, out_o2
def loss_fuction(x1, x2, y1, y2): # 损失函数
y1_pred, y2_pred = forward_propagate(x1, x2) # 前向传播
loss = (1 / 2) * (y1_pred - y1) ** 2 + (1 / 2) * (y2_pred - y2) ** 2 # 考虑 : t.nn.MSELoss()
print("损失函数(均方误差):", loss.item())
return loss
def update_w(w1, w2, w3, w4, w5, w6, w7, w8):
# 步长
step = 1
w1.data = w1.data - step * w1.grad.data
w2.data = w2.data - step * w2.grad.data
w3.data = w3.data - step * w3.grad.data
w4.data = w4.data - step * w4.grad.data
w5.data = w5.data - step * w5.grad.data
w6.data = w6.data - step * w6.grad.data
w7.data = w7.data - step * w7.grad.data
w8.data = w8.data - step * w8.grad.data
w1.grad.data.zero_() # 注意:将w中所有梯度清零
w2.grad.data.zero_()
w3.grad.data.zero_()
w4.grad.data.zero_()
w5.grad.data.zero_()
w6.grad.data.zero_()
w7.grad.data.zero_()
w8.grad.data.zero_()
return w1, w2, w3, w4, w5, w6, w7, w8
if __name__ == "__main__":
print("=====更新前的权值=====")
print(w1.data, w2.data, w3.data, w4.data, w5.data, w6.data, w7.data, w8.data)
for i in range(1):
print("=====第" + str(i) + "轮=====")
L = loss_fuction(x1, x2, y1, y2) # 前向传播,求 Loss,构建计算图
L.backward() # 自动求梯度,不需要人工编程实现。反向传播,求出计算图中所有梯度存入w中
print("\tgrad W: ", round(w1.grad.item(), 2), round(w2.grad.item(), 2), round(w3.grad.item(), 2),
round(w4.grad.item(), 2), round(w5.grad.item(), 2), round(w6.grad.item(), 2), round(w7.grad.item(), 2),
round(w8.grad.item(), 2))
w1, w2, w3, w4, w5, w6, w7, w8 = update_w(w1, w2, w3, w4, w5, w6, w7, w8)
print("更新后的权值")
print(w1.data, w2.data, w3.data, w4.data, w5.data, w6.data, w7.data, w8.data)
# print(forward_propagate(x1, x2))二、对比【作业3】和【作业2】的程序,观察两种方法结果是否相同?如果不同,哪个正确?
不相同,PyTorch算出来的正确。
作业二w1-w4梯度计算公式已更正,更正后的代码和pytorch算出来的梯度一致。
初始权值如下,步长step=1
w1, w2, w3, w4, w5, w6, w7, w8 = 0.2, -0.4, 0.5, 0.6, 0.1, -0.5, -0.3, 0.8
作业二的手推法(迭代1次)

作业三的PyTorch法(迭代1次 )

三、【作业2】程序更新(保留【作业2中】的错误答案,留作对比。新程序到作业3。)
已更新:人工智能基础 作业2_Rabbit_Gray的博客-CSDN博客
四、对比【作业2】与【作业3】的反向传播的实现方法。总结并陈述
作业二是手动计算反向传播过程中各参数梯度
作业三是用PyTorch的Tensor这种数据结构,在前向传播中动态构建计算图,使用计算图的最后一个张量节点loss的backward()方法自动计算计算图中所有参数梯度。
五、激活函数Sigmoid用PyTorch自带函数torch.sigmoid(),观察、总结并陈述
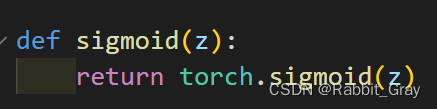
使用自己写的sigmoid(),前向/反向传播迭代10000次用时:92秒
使用torch.sigmoid(),前向/反向传播迭代10000次用时:78秒
torch的sigmoid()函数效率更高一些。
六、激活函数Sigmoid改变为Relu,观察、总结并陈述
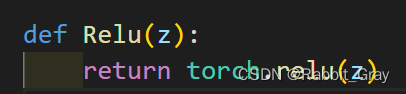
使用torch.relu(),前向/反向传播迭代10000次用时:72秒
ReLU激活函数计算起来更快一些
七、损失函数MSE用PyTorch自带函数 t.nn.MSELoss()替代,观察、总结并陈述
def loss_fuction(x1, x2, y1, y2): # 损失函数
y1_pred, y2_pred = forward_propagate(x1, x2) # 前向传播
# loss = (1 / 2) * (y1_pred - y1) ** 2 + (1 / 2) * (y2_pred - y2) ** 2 # 考虑 : t.nn.MSELoss()
loss_func = torch.nn.MSELoss() # 创建损失函数
y_pred = torch.cat((y1_pred, y2_pred), dim=0) # 将y1_pred, y2_pred合并成一个向量
y = torch.cat((y1, y2), dim=0) # 将y1, y2合并成一个向量
loss = loss_func(y_pred, y) # 计算损失
print("损失函数(均方误差):", loss.item())
return loss首先获得一个损失函数loss_func,然后把预测值y_pred和实际值y传入损失函数计算loss值
八、损失函数MSE改变为交叉熵,观察、总结并陈述
def loss_fuction(x1, x2, y1, y2): # 损失函数
y1_pred, y2_pred = forward_propagate(x1, x2) # 前向传播
loss_func = torch.nn.CrossEntropyLoss() # 创建交叉熵损失函数
y_pred = torch.stack([y1_pred, y2_pred], dim=1) # 将两个预测值放在一个矩阵中
y = torch.stack([y1, y2], dim=1) # 将两个真实值放在一个矩阵中
loss = loss_func(y_pred, y) # 计算损失
print("损失函数(均方误差):", loss.item())
return loss交叉熵损失函数一般适用于分类任务,标签一般为one-hot形式,似乎不太适合本例子?
九、改变步长,训练次数,观察、总结并陈述
使用MSE损失函数,令step为1、2、5、10、1000,分别迭代1000次,loss曲线图如下图所示
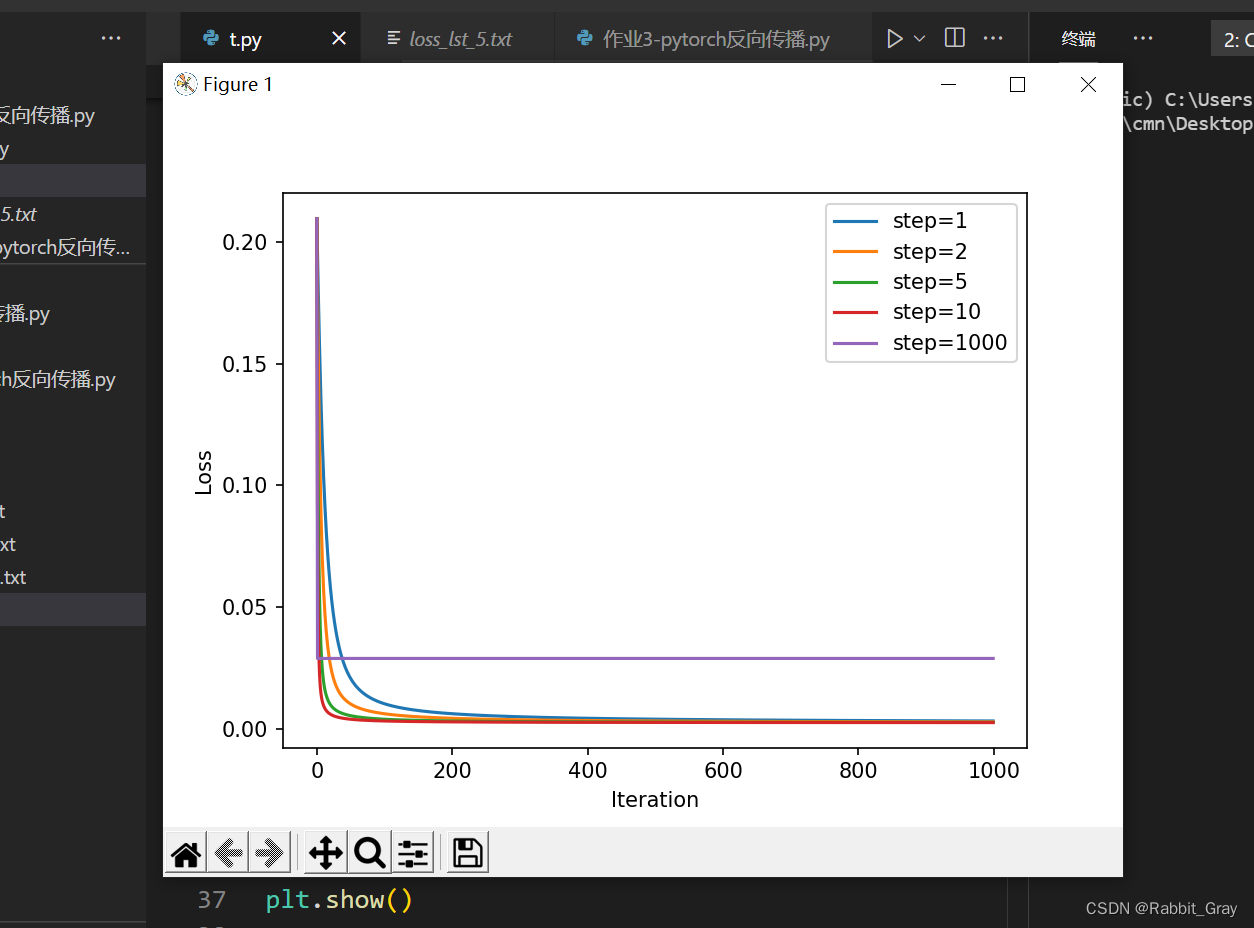
可以发现在一定范围内,步长越大,收敛越快,但是当步长(如图中step=1000)过大的时候,有可能发生不能收敛到最小值附近的情况
十、权值w1-w8初始值换为随机数,对比【作业2】指定权值结果,观察、总结并陈述
# w1, w2, w3, w4, w5, w6, w7, w8 = torch.Tensor([0.2]), torch.Tensor([-0.4]), torch.Tensor([0.5]), torch.Tensor(
# [0.6]), torch.Tensor([0.1]), torch.Tensor([-0.5]), torch.Tensor([-0.3]), torch.Tensor([0.8]) # 权重初始值
# 随机初始化权值
w1, w2, w3, w4, w5, w6, w7, w8 = torch.randn(1, 1), torch.randn(1, 1), torch.randn(1, 1), torch.randn(1, 1), \
torch.randn(1, 1), torch.randn(1, 1), torch.randn(1, 1), torch.randn(1, 1)
随机初始化8个权值为(-1, 1)之间的数,发现权值如何初始化基本不影响最终网络收敛,和作业2对比,发现迭代训练1000步以后权值非常接近。
十一、全面总结反向传播原理和编码实现,认真写心得体会。
反向传播基于链式求导法则,可以避免计算图中最后一个loss节点单独对每个节点重新求导,每个节点只需要计算一次梯度就可以计算出更新该节点所需要的梯度。
实现伪代码:
# 准备数据集
x = [1,2]
target = [3,4]
# 随机初始化权重
w1 = [rand, rand, rand, rand]
w2 = [rand, rand, rand, rand]
# 定义损失函数
loss_func = create_MSE()
# 训练1000轮
for _ in range(1000):
# 前向传播 构建计算图和模型输出
y_pred = forward_propagate(x)
# 根据模型输出和标签计算损失
loss = loss_func(y_pred, target)
# 反向传播 计算各权重梯度
loss.backward()
# 根据各参数梯度更新各参数
update_w_use_grad(w1, w2)
心得体会:搞一遍原理以后觉得还是用框架比较方便😅















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









