







前言
本篇将介绍如何快速搭建 Spark StandAlone HA环境,请确保你的Zookeeper和HDFS均已启动,以及搭建好了基本的Spark StandAlone环境。
参考文章:
Spark StandAlone环境部署
ZooKeeper安装部署
如果是一直跟着我的文章来到这的,就直接看下面内容即可。
一、Spark StandAlone HA 原理
Zookeeper负责状态维护,集群开启多个master进程,一个作为活跃,其余作为备份,当活跃的master宕机后,由备份的master进行接管。
二、修改配置文件
1、修改spark-env.sh
cd /export/servers/spark-3.2.0/conf
vi spark-env.sh
#删除或者注释掉 SPARK_MASTER_HOST=node1 ,/
因为使用HA模式后,master就不应该固定在某一个节点上了。
在spark-env.sh中, 增加:
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
# spark.deploy.recoveryMode 指定HA模式 基于Zookeeper实现
# 指定Zookeeper的连接地址
# 指定在Zookeeper中注册临时节点的路径
2、同步spark-env.sh文件
scp spark-env.sh node2:/export/servers/spark-3.2.0/conf
scp spark-env.sh node3:/export/servers/spark-3.2.0/conf
3、停止StandAlone集群
cd /export/servers/spark-3.2.0
sbin/stop-all.sh
如果你本身就没有开启standalone集群,这一步忽略即可。
4、启动StandAlone集群
# 在node1上 启动一个master 和全部worker
sbin/start-all.sh
# 注意, 下面命令在node2上执行
sbin/start-master.sh
# 在node2上启动一个备用的master进程
此时,我们的spark集群上就有了两个master和三个worker。
三、查看master监控页面
netstat -anp|grep 进程编号
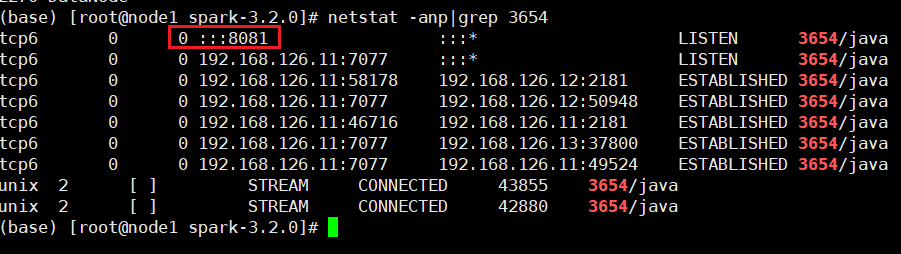
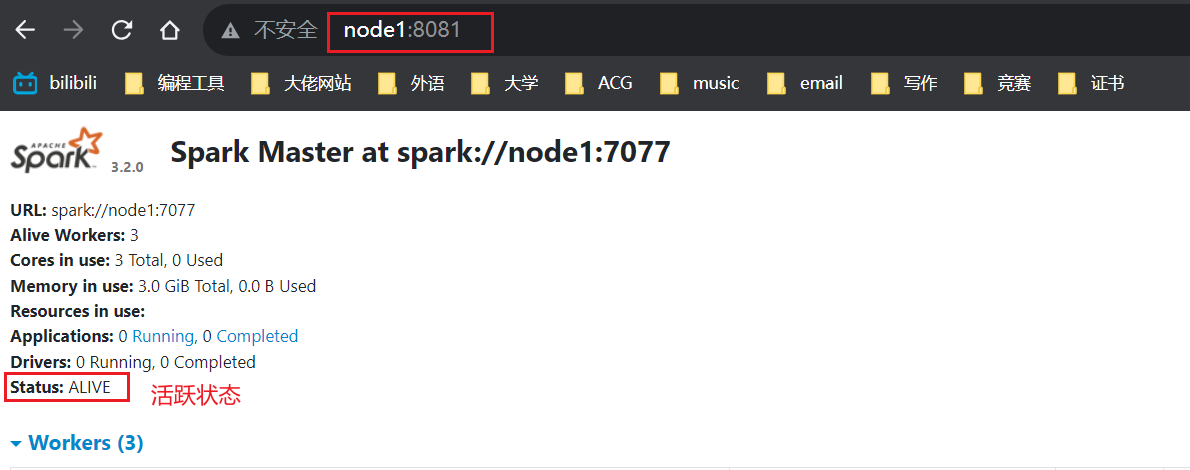
可以看到,我node1上的master进程的页面端口被绑定为8081,因此我输入node1:8080是肯定没有结果响应的。
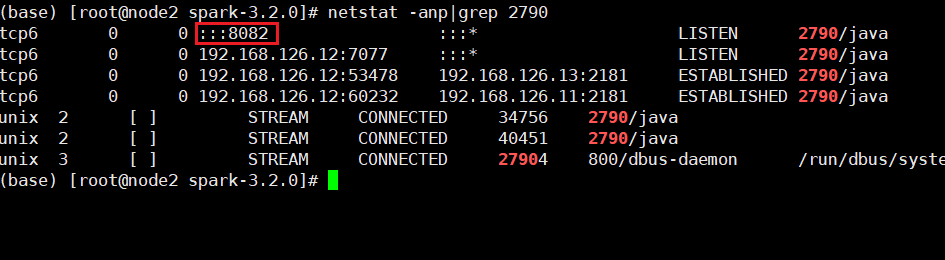
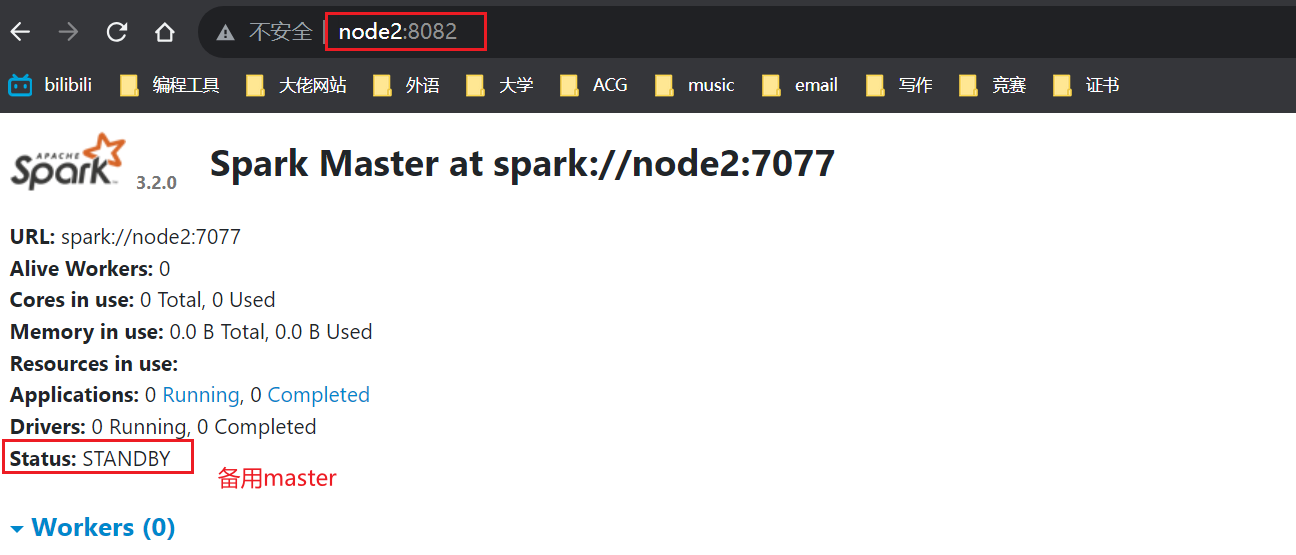
我node2上的master进程的页面端口被绑定为8082
四、测试master主备切换
这一步是用于测试master主备切换的效果,我们在node2上提交一个程序进行,在任务还没结束时,我们在node1上杀死master进程,然后回到node2上,看看集群是否能正常使用备用的master作为新的活跃的master,去管理程序。
1、提交一个任务程序
cd /export/servers/spark-3.2.0
#提交任务
bin/spark-submit --master spark://node1:7077 /export/servers/spark-3.2.0/examples/src/main/python/pi.py 1000
2、杀死活跃master
kill -9 master进程号
3、查看是否报错
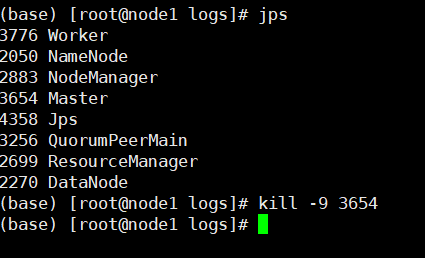
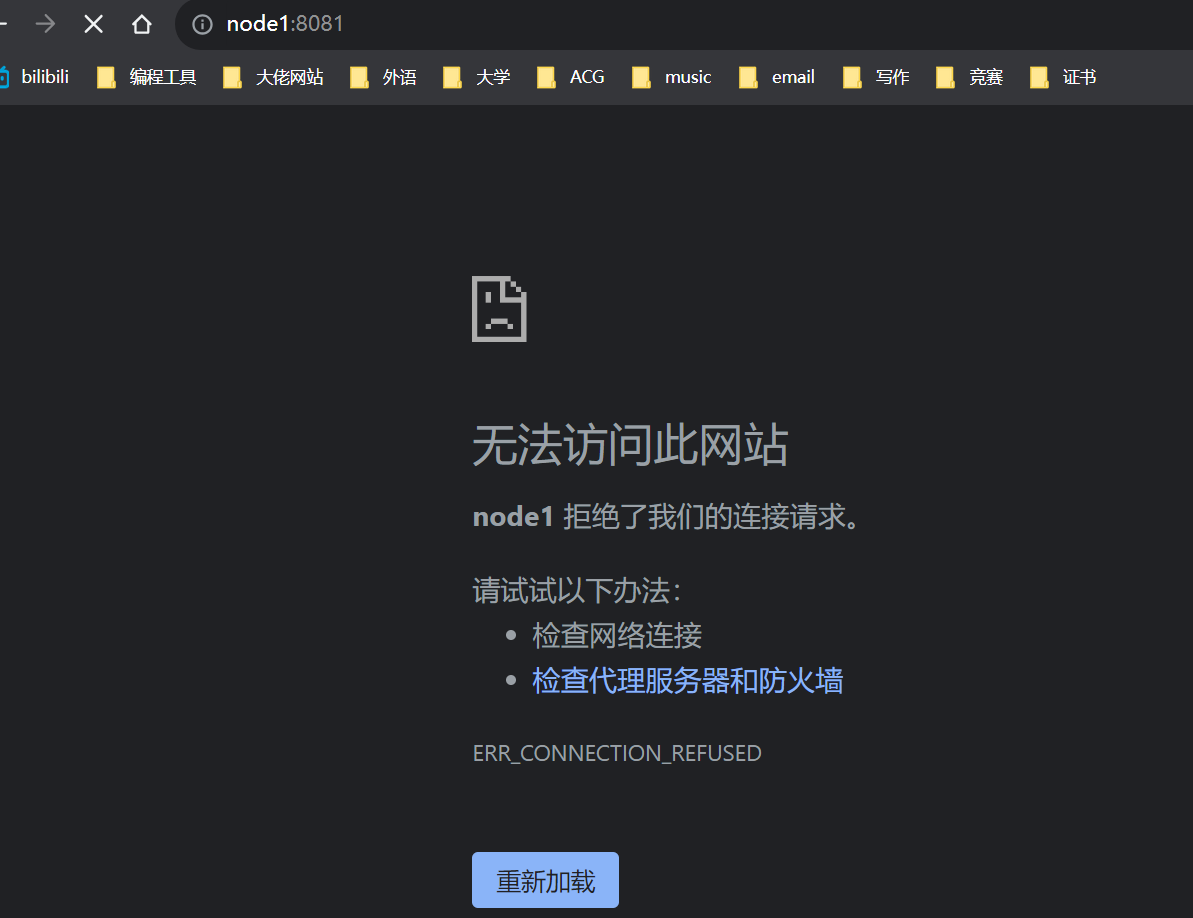
可以看到,当我杀死掉进程之后,node1:8081无法打开
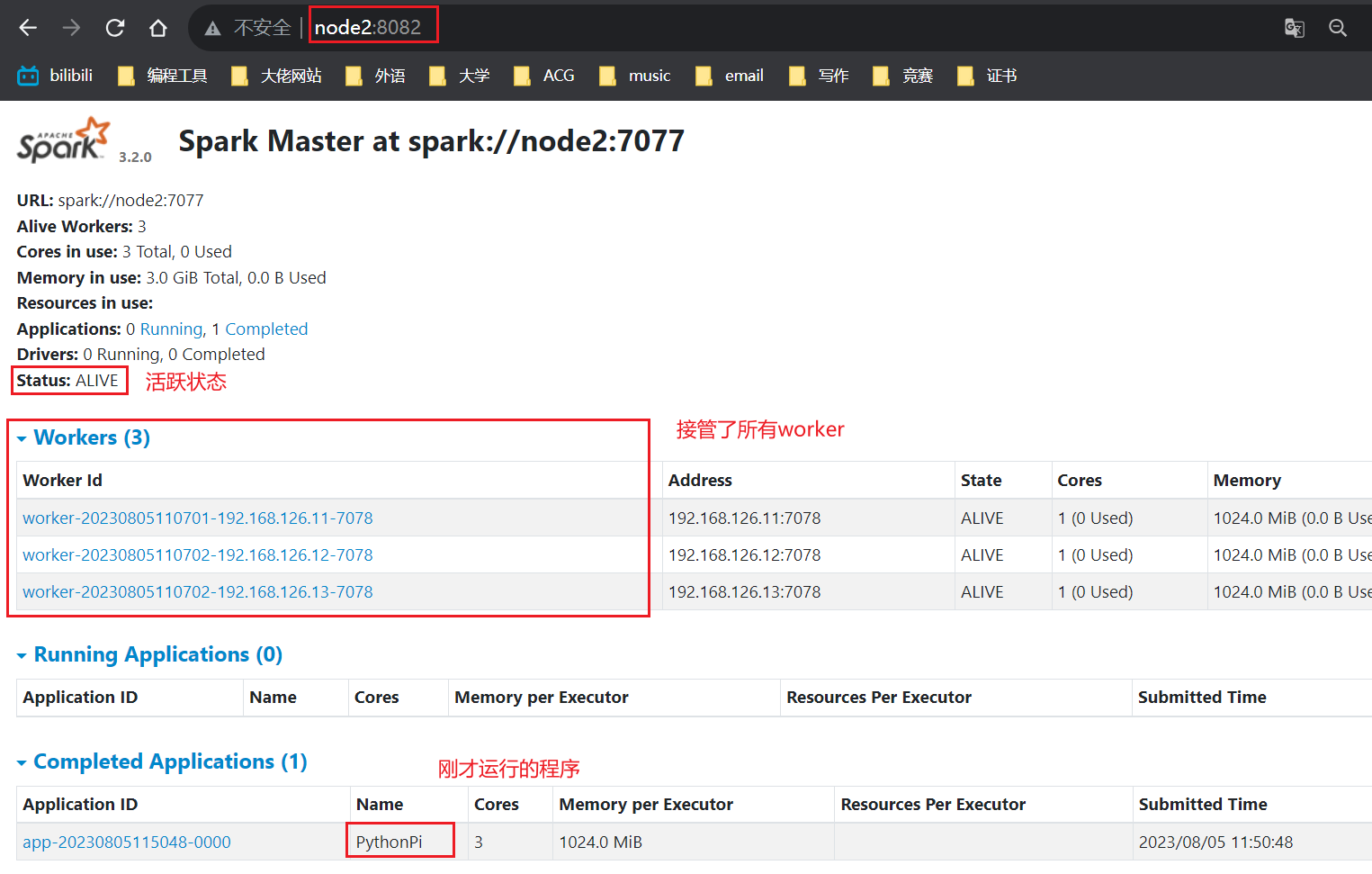
node2上的master已经变成活跃状态了

总结:master的主备切换,不会影响正在运行的程序,但会有一个中断期,整体时间会被延长。
五、恢复集群
因为刚才挂掉了一个master,如果不恢复集群,则又回到了单点故障的问题上了。
#在node1上执行
sbin/start-master.sh
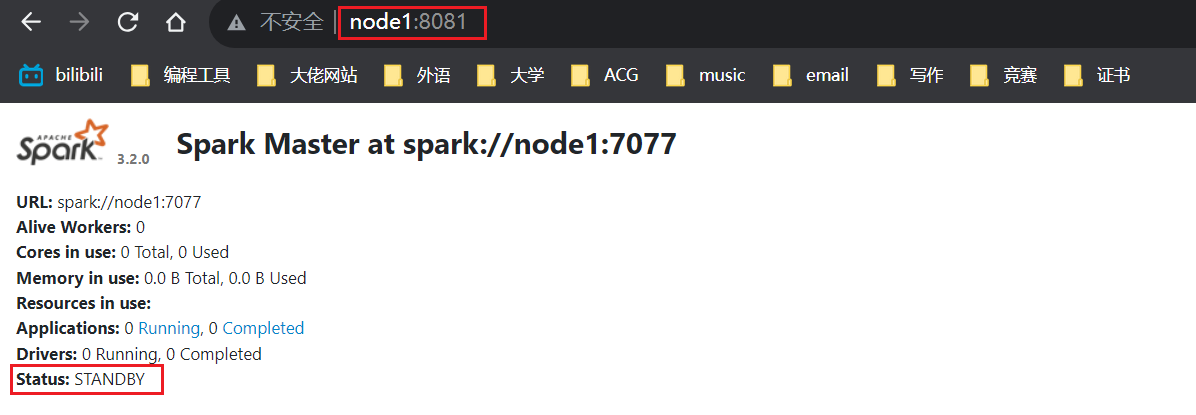
此时node1上的master就成了备用了,“糟了,我成替身了!!!”。其实谁是备用没有关系,有备用就行,你若想要node上的为活跃状态,只需要把node2的给干掉,然后再重新启动即可。
其它文章:
Spark环境搭建部署全流程,看这一篇就够了














 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









