







前言
在部署之前,需要明确集群的规划,即有多少台机子,每台机子上应该存放哪些进程。

一、部署python环境
在每台机子上都执行安装anaconda的步骤,确保所有的机器都安装了python环境,才能正常使用spark集群。
安装步骤参考我先前的文章:1、linux安装Anaconda
二、配置环境变量
主要是/etc/profile 和 /root/.bashrc 这两个文件, 我们可以直接将node1上的同步过去。
scp /etc/profile root@node2:/etc/
scp /etc/profile root@node2:/etc/
scp /root/.bashrc root@node2:/root/
scp /root/.bashrc root@node3:/root/
三、配置spark配置文件
cd /export/servers/spark-3.2.0/conf
1、workers
mv workers.template workers
vi workers
#追加以下内容
node1
node2
node3
2、spark-env.sh
mv spark-env.sh.template spark-env.sh
#追加以下内容,注意你的安装路径、节点名 有没有和我的不同
## 设置JAVA安装目录
JAVA_HOME=/export/servers/jdk1.8.0_241
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/servers/hadoop-3.3.0/etc/hadoop
YARN_CONF_DIR=/export/servers/hadoop-3.3.0/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=node1
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的 web ui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的 webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
3、创建历史记录存放目录
刚才配置信息里的hdfs://node1:8020/sparklog/,指定了用hdfs系统里的sparklog来存放spark程序运行日志信息,但这个目录还不存在,需要创建。
#启动hdfs和yarn
start-all.sh
hadoop fs -mkdir /sparklog
hadoop fs -chmod 777 /sparklog
#查看生成结果
hadoop fs -ls /
4、spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf
#追加如下内容
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://node1:8020/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true
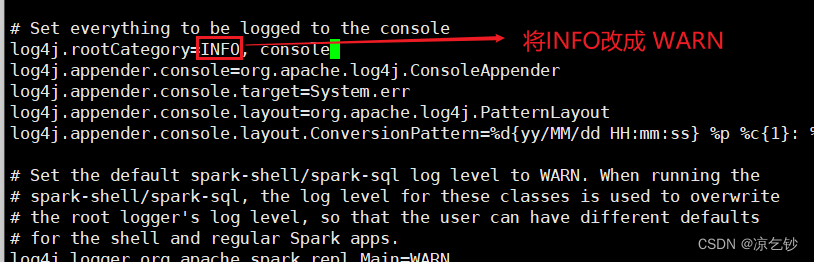
5、log4j.properties
这一步是可选操作,但还是建议修改。因为Spark会疯狂输出日志, 设置级别为WARN时,就只输出警告和错误日志, 而不是一堆信息。
mv log4j.properties.template log4j.properties
vi log4j.properties
按照下图去修改内容
四、同步spark
cd /export/servers/
scp -r spark-3.2.0 root@node2:$PWD
scp -r spark-3.2.0 root@node3:$PWD
五、启动历史服务
在node1上进行操作
cd spark-3.2.0
sbin/start-history-server.sh
六、启停spark集群
# 整体启停
sbin/start-all.sh
sbin/stop-all.sh
# 单个启停
sbin/start-master.sh
sbin/stop-master.sh
sbin/start-worker.sh
sbin/stop-worker.sh
其它文章:
Spark环境搭建部署全流程,看这一篇就够了















 4517
4517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









