










Abstract & Introduction & Related Work
- 研究任务
lifelong learning - 已有方法和相关工作
- 面临挑战
- 现有方法大多基于图片或者游戏,而不是语言
- 创新思路
- 提出了一种基于语言模型的lifelong learning方法
- 重现以前任务的伪样本,同时不需要额外的内存或模型容量
- 实验结论
- 结果显示,LAMOL可以防止灾难性遗忘,而没有任何不妥协的迹象,并且只用一个模型就可以连续完成五种非常不同的语言任务
- sota
- 此外,我们建议在伪样本生成过程中增加特定任务的标记,以便在所有先前的任务中均匀地分配生成的样本。这一扩展稳定了LLL,在大量任务的训练中特别有用
- 我们分析了不同数量的伪样本如何影响LAMOL的最终性能,考虑了有和没有特定任务标记的结果
训练一个语言模型,同时具备生成伪样本的能力,而不需要额外的空间

LAMOL
DATA FORMATTING
受decaNLP(Bryan McCann & Socher,2018)使用的协议启发,我们使用的数据集的样本被框定在一个类似SQuAD的方案中,其中包括上下文、问题和答案。虽然LM同时是一个QA模型,但数据格式取决于训练目标。当作为QA模型进行训练时,LM在阅读上下文和问题后学习解码答案。另一方面,当作为LM训练时,LM学习解码给定的三个部分的token。
除了上下文、问题和答案之外,我们还增加了三个特殊的token:
- ANS :插在问题和答案之间。由于在推理过程中,上下文和问题是已知的,所以在输入ANS后开始解码
- EOS :每个样本的最后一个token,遇到EOS时停止解码
- GEN :伪样本生成期间的第一个token,解码在输入GEN后开始

TRAINING
用一个系数 γ \gamma γ 来平衡伪样本的数量,并且置信度不够高的时候,生成的样本会被丢弃
同时优化两个损失
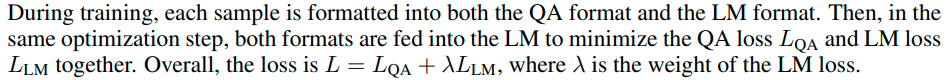
TASK-SPECIFIC TOKENS
在训练许多任务时,对所有任务使用相同的GEN token是有问题的,因为旧任务的部分在理论上是呈指数级下降的。例如,如果 γ = 0.01 γ=0.01 γ=0.01,那么在训练第二个任务时,第一个任务的部分约为 1%,但在训练第三个任务时,只有约 0.01 0.01% 0.01。这个问题对LLL绝对是有害的。为了缓解这个问题,我们可以选择用每个任务的特定任务token来取代GEN token,以通知模型生成属于特定任务的伪样本
在这个设定下,所有的之前的任务都有相同的伪样本数量 γ ∣ T i ∣ \gamma|T_i| γ∣Ti∣
请注意,由于每个任务都使用特定的token,随着更多任务的训练,LM的词汇量和嵌入权重会略有增加
EXPERIMENTAL RESULTS



CONCLUSION
我们提出了LAMOL,一种基于语言建模的简单而有效的LLL方法。一个单一的LM就能实现LLL,无需额外的模型组件,也无需保留旧的样本。此外,任何预训练的LM都可以用来利用大量的未标记文本来改善LLL。最后,只要有需要,就可以增加更多的任务
Remark
方法出奇的简单,大概可以作为一个base method?ICLR出品确实顶















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









