









Abstract&Introduction&Related Work
- 研究任务
- 语言+视觉模态预训练任务
- 已有方法和相关工作
- masked data已经成为一种主流
- 面临挑战
- 现有的多模态大模型不同模态之间的参数的共享不够高效
- 创新思路
- 使用Multiway Transformers来通用建模,使用一个统一个结构共享不同下游任务
- 模块化的网络同时充分考虑到了模态独特的编码和跨模态融合
- 别的大模型往往使用了很多训练任务,而本文中仅仅使用mask-then-predict来训练通用的多模态模型
- 将图片视为外语,把图片和文本做相同的处理,因此图片-文本对被视为平行语料来学习模态的对齐
- 仅仅使用了公开数据集
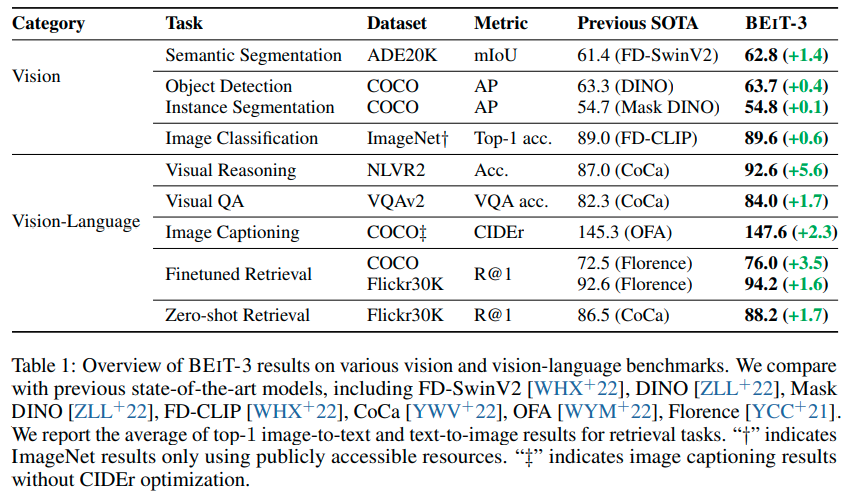
- 实验结论
- 在目标检测,语义分割,图像分类,视觉推理,视觉问答,图像字幕,多模态抽取上都达到了sota(什么CV杀神?)

在视觉任务上全方位乱杀,可惜没看到NLP那边杀起来
BEIT-3: A General-Purpose Multimodal Foundation Model
通过使用共享的多路变压器网络对单模态和多模态数据进行masked data建模来进行预训练。该模型可以转移到各种视觉和视觉语言下游任务
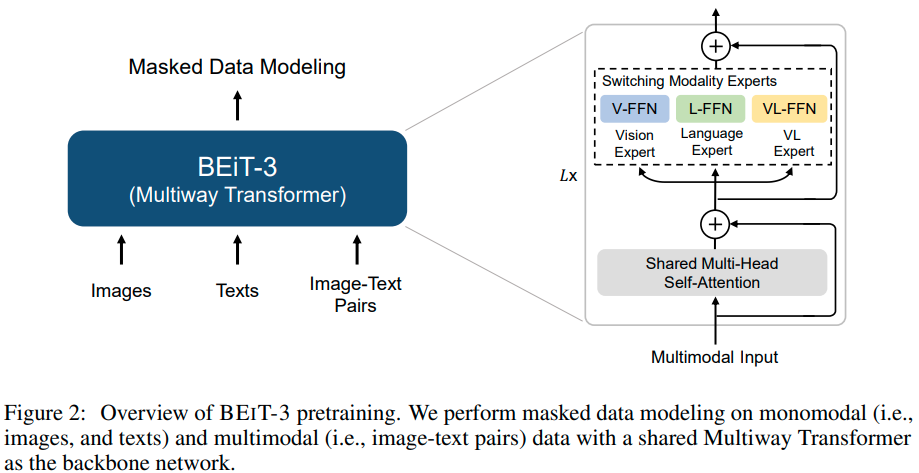
Backbone Network: Multiway Transformers
将输入根据不同模态输入给不同的专家模块,在实现中,每一层都有一个视觉专家和语言专家,最上面三层有视觉-语言专家为融合模态而设计
Using a pool of modality experts encourages the model to capture more modality-specific information.
使用a pool of 模态专家能促进模型捕捉到更多模态特定的信息
The shared self-attention module learns the alignment between different modalities and enables deep fusion for multimodal (such as vision-language) tasks.
共享的自注意力模块学习不同模态之间的对齐,使多模态任务深度融合
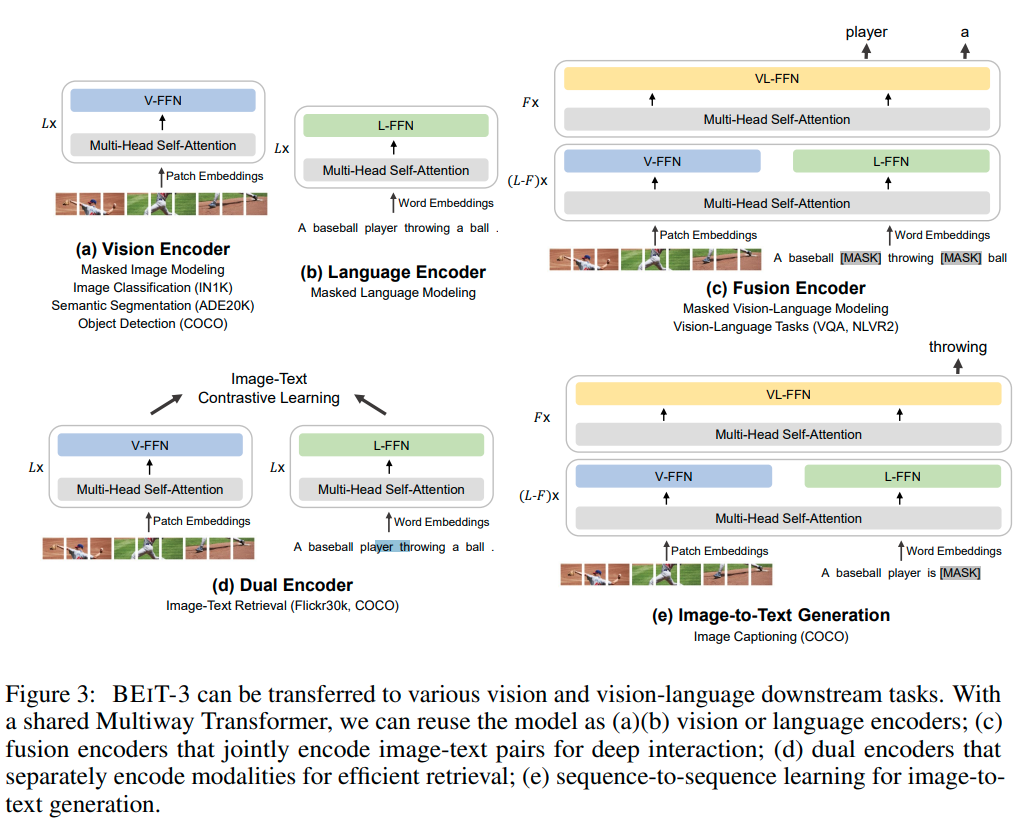
如图3所示,统一架构使BEIT-3能够支持广泛的下游任务
BEIT-3可以用作各种视觉任务的图像主干,包括图像分类、对象检测、实例分割和语义分割。它还可以作为双编码器进行微调,以实现高效的图像文本检索,并作为多模式理解和生成任务的融合模型
Pretraining Task: Masked Data Modeling
文本用SentencePiece Tokenizer,图像用BEiT v2的Tokenizer进行token化
- 文本随机mask 15%
- 图像-文本对随机mask 50%
- 图片随机mask 40%
Scaling Up: BEIT-3 Pretraining
Backbone Network
使用ViT-giant作为骨干网络,40层MultiWay Transformer,总参数量19亿

Pretraining Data
使用的预训练数据

Pretraining Settings
好像越来越接近非超级实验室能做的训练资源了

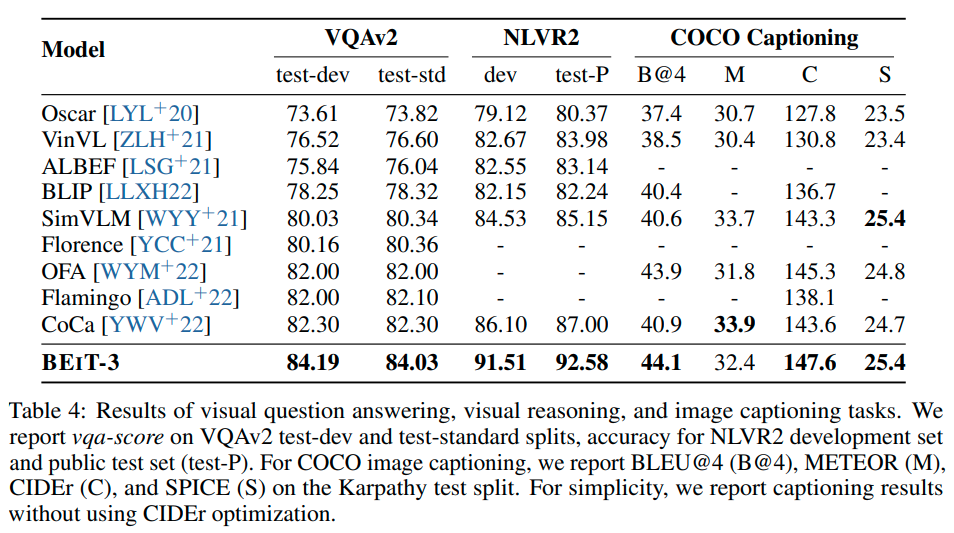
Experiments
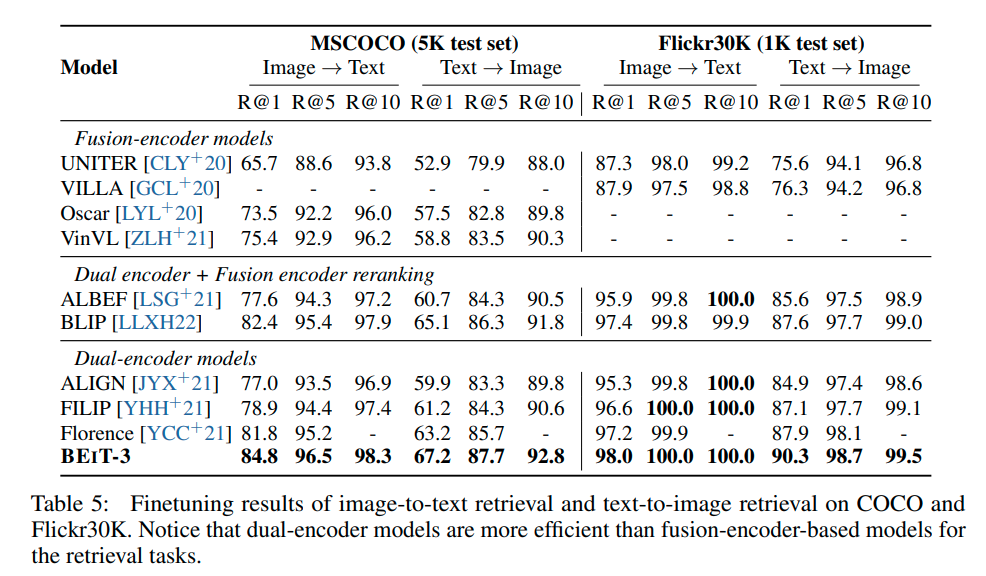
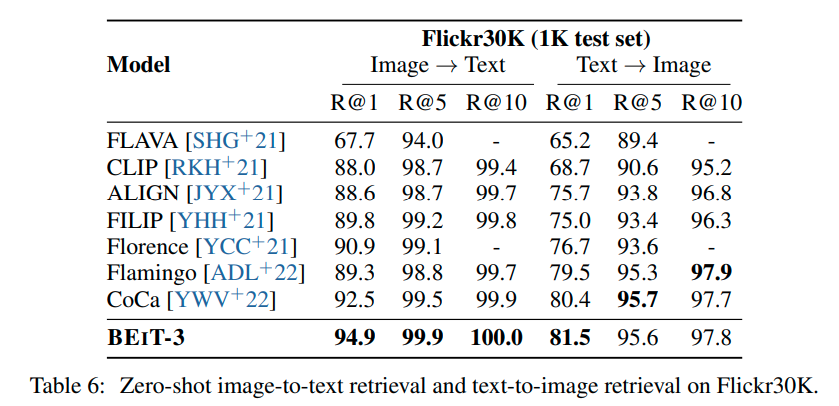
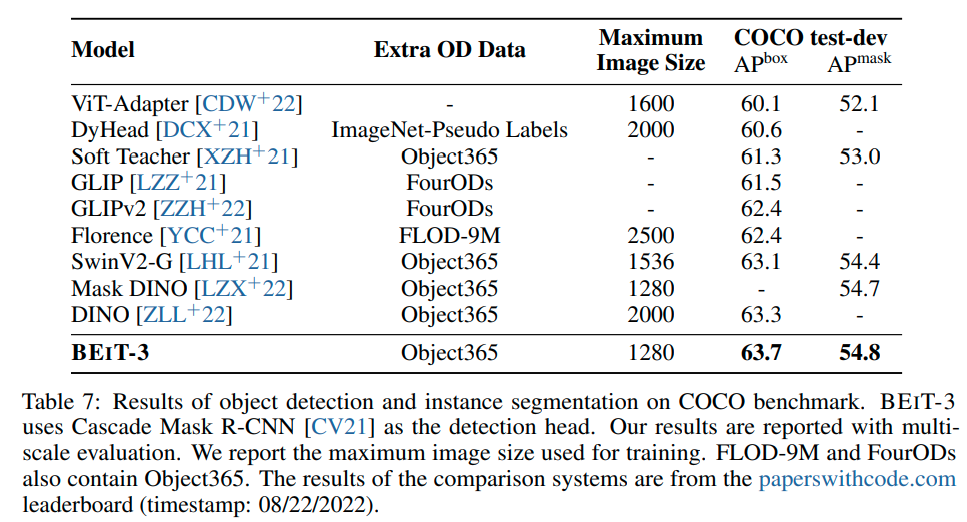
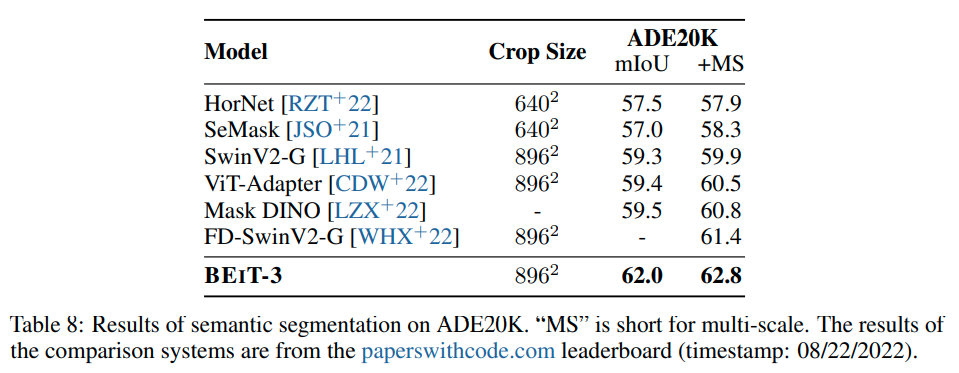
实验是真正的大杀四方,刷了一堆sota
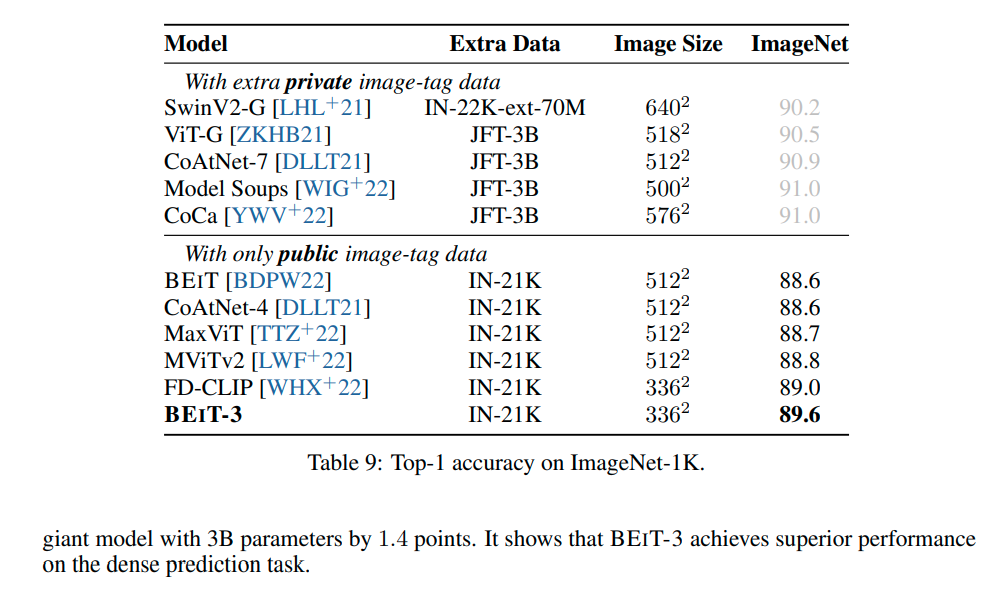
Conclusions
在本文中,我们介绍了BEIT-3,这是一个通用的多模式基础模型,它在广泛的视觉和视觉语言基准上实现了最先进的性能。BEIT-3的关键思想是图像可以被建模为外语,因此我们可以以统一的方式对图像、文本和图像-文本对进行mask“语言”建模。我们还演示了多路transformer可以有效地建模不同的视觉和视觉语言任务,使其成为通用建模的有趣选项(?)
BEIT-3简单而且work,是扩展多模态基础模型的一个有前景的方向。对于未来的工作,我们正在进行多语种BEIT-3的预训练,并在BEIT-2中包括更多的模式(如音频),以促进跨语言和跨模式的迁移,并促进跨任务、语言和模式的大规模预训练的大融合。我们也有兴趣通过结合BEIT-3和MetaLM的优势,为多模式基础模型提供上下文学习能力
Remark
微软的超级大作,一举把视觉的sota狠狠的提高了,并且让大家再次见识到了基于masked data的超强潜力,现在就差多模态模型在语言上的威力展现了~相信很快就会有,然后下一阶段再把语音也加入进来















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









