






 BEIT-3是一个通用的多模态基础模型,通过统一的框架进行模型、训练目标和规模的标准化,实现图像、文本和图像-文本对的统一掩码语言建模。实验结果显示,BEIT-3在各类视觉和视觉语言任务上表现出色,预训练和微调仅使用公开数据,显示出强大的跨模态迁移性能。
BEIT-3是一个通用的多模态基础模型,通过统一的框架进行模型、训练目标和规模的标准化,实现图像、文本和图像-文本对的统一掩码语言建模。实验结果显示,BEIT-3在各类视觉和视觉语言任务上表现出色,预训练和微调仅使用公开数据,显示出强大的跨模态迁移性能。
文章汇总
作者的意图非常明确,就是想做一个更大一统的框架,不仅是在模型上的统一,而且从训练的目标函数上要统一,还有模型大小,数据集大小,如何scale也要统一,作者称之为Big Convergence。
BEiTv3就是把图像也看成了是一种语言(原文: Image can be modeled as a foreign language),文章把Image叫做Imagelish,文本叫做English,然后把图像文本对叫做Parallel Sentence。这样的话,不论是图像还是文本都可以用Mask Modeling去做,即把部分patch进行mask掉,之后要求这个模型把这个被mask掉的patch给它恢复出来,所以我们就不需要ITC,ITM(BLIP中提及过) ,Language Modeling或者Word Patch Alignment等各种Loss,而是只有一个Loss。模型层面用的是他们之前VLMO提出的MOME,即Multi-Way Transformers。
摘要
语言、视觉和多模态预训练的大融合正在出现。在这项工作中,我们介绍了一个通用的多模态基础模型BEIT-3,它在视觉和视觉语言任务上实现了最先进的迁移性能。具体来说,我们从主干架构、预训练任务和模型扩展三个方面推进了大收敛。我们介绍了用于通用建模的多路Transformers,其中模块化体系结构支持深度融合和特定于模态的编码。基于共享主干,我们以统一的方式对图像(英语)、文本(英语)和图像-文本对(“平行句”)执行掩码“语言”建模。实验结果表明,BEIT-3在目标检测(COCO)、语义分割(ADE20K)、图像分类(ImageNet)、视觉推理(NLVR2)、视觉问答(VQAv2)、图像字幕(COCO)和跨模态检索(Flickr30K, COCO)方面取得了最先进的性能。
1.引言:大融合
近年来,语言[RNSS18, DCLT19, DYW+19]、视觉[BDPW22, PDB+22]和多模态[WBDW21, RKH+21, YWV+22]预训练呈现大融合的趋势。通过对海量数据进行大规模预训练,我们可以很容易地将模型转移到各种下游任务中。我们可以预训练一个处理多种模态的通用基础模型,这很有吸引力。在这项工作中,我们从以下三个方面提出了视觉语言预训练的收敛趋势。
首先,Transformers[VSP+17]的成功在于从语言翻译到视觉[DBK+20]和多模态[KSK21, WBDW21]的问题。网络架构的统一使我们能够无缝地处理多种模式。对于视觉语言建模,由于下游任务的不同性质,有各种各样的方法来应用transformer。例如,双编码器架构用于高效检索[RKH+21],编码器-解码器网络用于生成任务[WYY+21],融合编码器架构用于图像-文本编码[KSK21]。然而,大多数基础模型必须根据特定的体系结构手动转换最终任务格式。此外,这些参数通常不能有效地跨模态共享。在这项工作中,我们采用多路变压器[WBDW21]进行通用建模,即为各种下游任务共享一个统一的体系结构。模块化网络还综合考虑了模态特定编码和跨模态融合。
其次,基于掩模数据建模的预训练任务已成功应用于多种模式,如文本[DCLT19]、图像[BDPW22、PDB+22]和图像-文本对[BWDW22]。
当前的视觉语言基础模型通常多任务处理其他预训练目标(如图像-文本匹配),使得扩展不友好且效率低下。相比之下,我们只使用一个预训练任务,即mask-then-predict,来训练通用的多模态基础模型。通过将图像视为一门外语(即英语),我们以相同的方式处理文本和图像,没有根本的建模差异。因此,图像-文本对被用作“平行句”,以学习模态之间的对齐。我们还表明,简单而有效的方法学习强可转移表征,在视觉和视觉语言任务上都取得了最先进的性能。显著的成功证明了生成式预训练的优越性[DCLT19, BDPW22]。
第三,模型规模和数据规模的普遍扩大提高了基础模型的泛化质量,使我们可以将其转移到各种下游任务中。我们遵循这一理念,将模型规模扩大到数十亿个参数。此外,我们在实验中扩大了预训练数据的大小,而只使用公开可访问的学术资源。虽然没有使用任何私人数据,但我们的方法比依赖内部数据的最先进的基础模型要好得多。此外,将图像作为一门外语来处理,可以直接重用为大规模语言模型预训练而开发的管道。
在这项工作中,我们利用上述思想预训练了一个通用的多模态基础模型BEIT-3。我们通过对图像、文本和图像-文本对执行屏蔽数据建模来预训练多路变压器。在预训练过程中,我们随机屏蔽一定比例的文本标记或图像补丁。自监督学习的目标是恢复给定损坏输入的原始令牌(即文本令牌或视觉令牌)。该模型是通用的,因为它可以重新用于各种任务,而不管输入方式或输出格式如何。
如图1和表1所示,BEIT-3在广泛的视觉和视觉语言任务中实现了最先进的迁移性能。我们在广泛的下游任务和数据集上评估了BEIT-3,即对象检测(COCO)、实例分割(COCO)、语义分割(ADE20K)、图像分类(ImageNet)、视觉推理(NLVR2)、视觉问答(VQAv2)、图像字幕(COCO)和跨模态检索(Flickr30K, COCO)。具体来说,尽管我们只使用公共资源进行预训练和微调,但我们的模型优于之前的强基础模型[YWV+22, ADL+22, YCC+21]。该模型也获得了比专门模型更好的结果。此外,BEIT-3不仅在视觉语言任务上表现良好,而且在视觉任务(如目标检测、语义分割)上也表现良好。
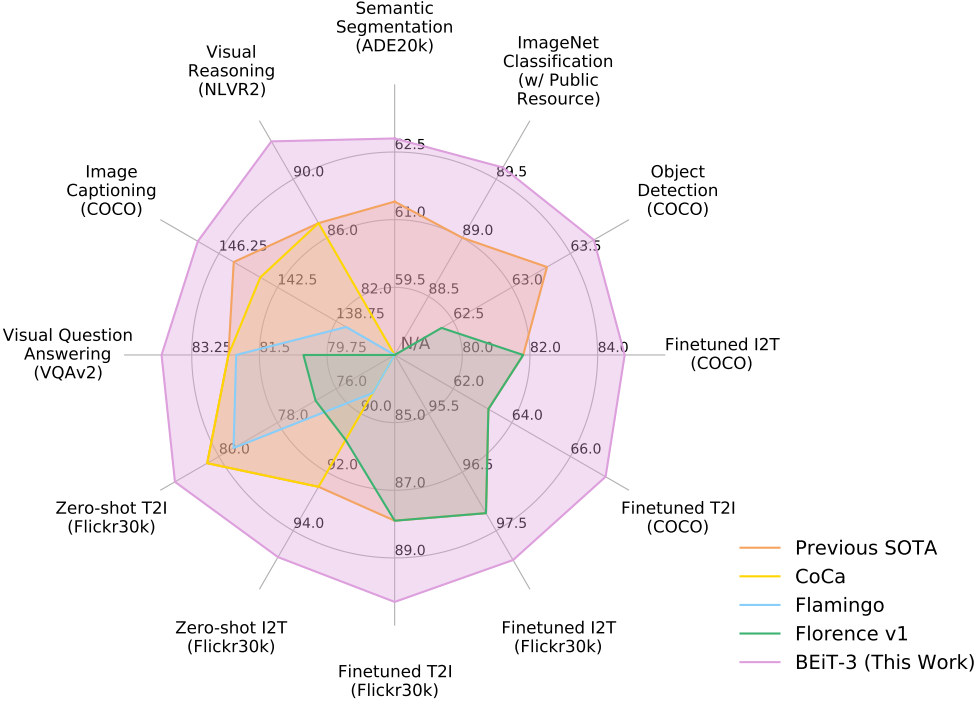
图1:与其他定制或基础模型相比,BEIT-3在广泛的任务范围内实现了最先进的性能。I2T/T2I是图像到文本/文本到图像检索的缩写。
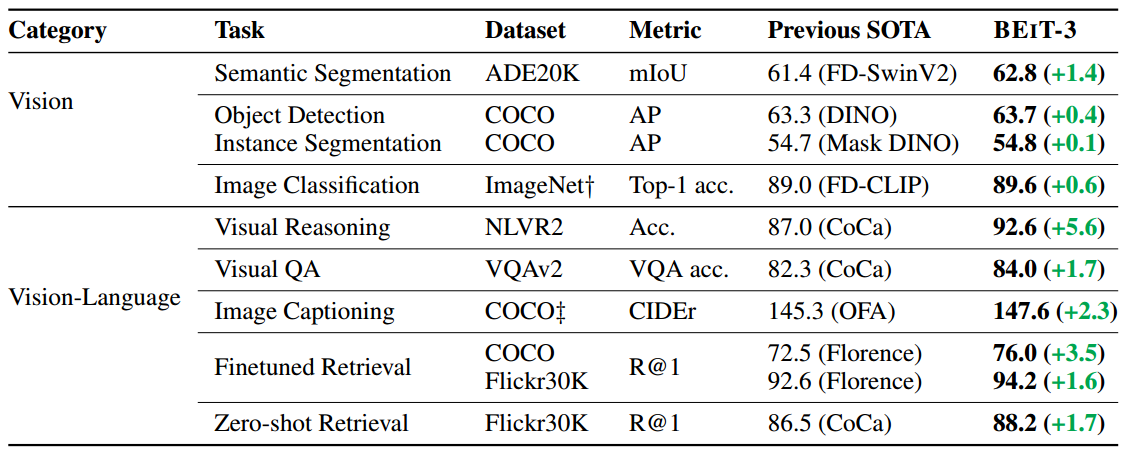
表1:各种视觉和视觉语言基准测试的BEIT-3结果概述。我们比较了以前最先进的型号,包括FD-SwinV2 [WHX+22], DINO [ZLL+22], Mask DINO [ZLL+22], FD-CLIP [WHX+22], CoCa [YWV+22], OFA [WYM+22], Florence [YCC+21]。我们报告了检索任务的前1名图像到文本和文本到图像结果的平均值。“y”表示ImageNet结果仅使用可公开访问的资源。“z”表示未经CIDEr优化的图像字幕结果。
2.BEIT-3:一个通用的多模态基础模型
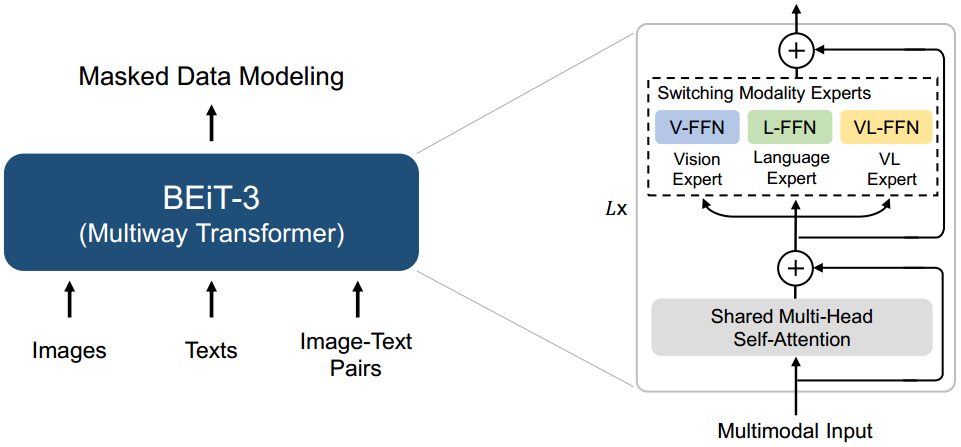
图2:BEIT-3预训练概述。我们使用共享的Multiway Transformer作为骨干网络,对单模态(即图像和文本)和多模态(即图像-文本对)数据执行屏蔽数据建模。
如图2所示,BEIT-3使用共享的Multiway Transformer网络,通过对单模态和多模态数据进行屏蔽数据建模进行预训练。该模型可以转移到各种视觉和视觉语言下游任务中。
2.1骨干网:Multiway Transformer
我们使用多路变压器[WBDW21]作为主干模型来编码不同的模态。如图2所示,每个Multiway Transformer模块由一个共享的自关注模块和一个用于不同模态的前馈网络池(即模态专家)组成。我们根据每个输入令牌的模式将其路由给专家。在我们的实现中,每一层包含一个视觉专家和一个语言专家。此外,最上面的三层有专为融合编码器设计的视觉语言专家。更详细的建模布局请参见图3 (a)(b)(c)。使用一组情态专家可以鼓励模型捕获更多特定于情态的信息。共享自关注模块学习不同模态之间的对齐,并为多模态(如视觉语言)任务提供深度融合。
如图3所示,统一的体系结构使BEIT-3能够支持范围广泛的下游任务。例如,BEIT-3可以作为各种视觉任务的图像主干,包括图像分类、对象检测、实例分割和语义分割。它还可以作为有效的图像-文本检索的双编码器和多模态理解和生成任务的融合模型进行微调。
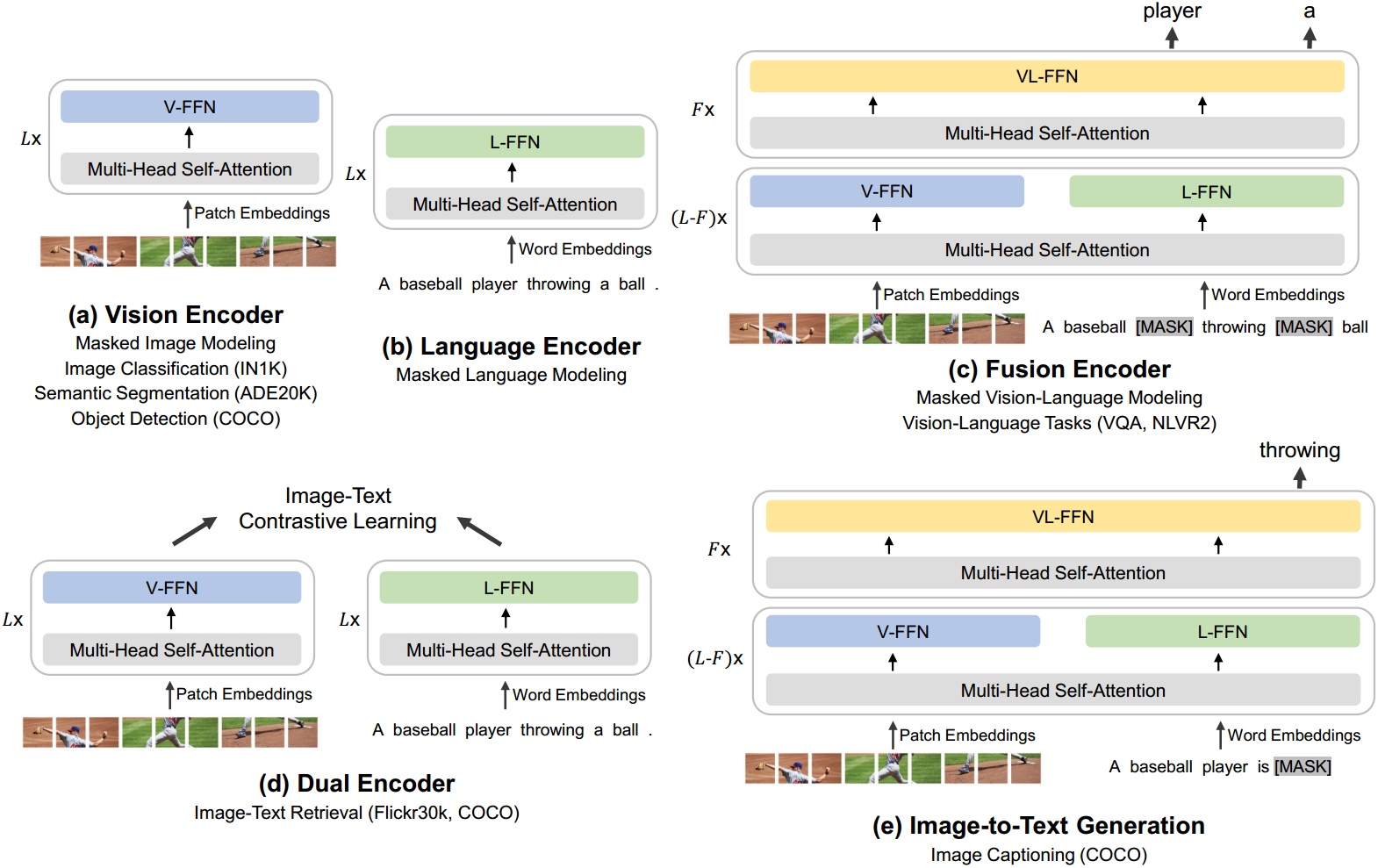
图3:BEIT-3可以转移到各种视觉和视觉语言下游任务。使用共享的Multiway Transformer,我们可以将模型重用为(a)(b)视觉或语言编码器;(c)融合编码器,对图像-文本对进行联合编码,实现深度交互;(d)为有效检索分别对模式进行编码的双编码器;(e)用于图像-文本生成的序列到序列学习。
2.2预训练任务:屏蔽数据建模
我们通过对单模(即图像和文本)和多模数据(即图像-文本对)的统一掩模数据建模[BWDW22]目标预训练BEIT-3。在预训练过程中,我们随机屏蔽一定比例的文本标记或图像补丁,并训练模型恢复被屏蔽的标记。统一的“先掩后预测”任务不仅学习表征,而且学习不同模态的对齐。具体来说,文本数据由sentencepece标记器[KR18]进行标记。使用BEIT v2 [PDB+22]的标记器对图像数据进行标记,得到离散的视觉标记作为重构目标。我们随机屏蔽15%的单模文本标记和50%的图像-文本对文本标记。对于图像,我们使用BEIT [BDPW22, PDB+22]中的块掩码策略掩码40%的图像补丁。
我们只使用一个预训练任务,这使得训练过程变得友好。相比之下,以前的视觉语言模型[LYL+20, ZLH+21, KSK21, LSG+21, WBDW21, LLXH22, YWV+22]通常采用多个预训练任务,如图像-文本对比,图像-文本匹配,单词-patch/区域对齐。我们证明了一个更小的预训练批大小可以用于mask-then-predict任务。相比之下,基于对比的模型[RKH+21, JYX+21, YCC+21, YWV+22]通常需要非常大的批大小进行预训练,这带来了更多的工程挑战,例如GPU内存成本。
2.3放大:BEIT-3预训练
骨干网络

表2:BEIT-3的模型配置。建筑布局遵循VIT -giant [ZKHB21]。
BEIT-3是ViTgiant [ZKHB21]建立的巨型基础模型。如表2所示,该模型由40层Multiway Transformer组成,其中隐藏尺寸为1408,中间尺寸为6144,注意头为16。所有层都包含视觉专家和语言专家。在Multiway Transformer的前三个层中也雇佣了视觉语言专家。自我关注模块在不同的模态中共享。BEIT-3共有1.9B的参数,其中视觉专家参数为692M,语言专家参数为692M,视觉语言专家参数为52M,共享自关注模块参数为317M。请注意,只有与视觉相关的参数(即,VIT -giant相当的尺寸;当该模型用作视觉编码器时,约1B)被激活。
预训练数据

表3:BEIT-3预训练数据。所有的数据都是学术上可访问的。
BEIT-3对表3所示的单模态和多模态数据进行预训练。对于多模态数据,从五个公共数据集中收集了大约15M张图像和21M对图像-文本:概念12M (CC12M) [CSDS21],概念字幕(CC3M) [SDGS18], SBU字幕(SBU) [OKB11], COCO [LMB+14]和视觉基因组(VG) [KZG+17]。对于单模数据,我们使用了来自ImageNet-21K的14M图像和来自英文维基百科、BookCorpus、OpenWebText3、CC-News和Stories的160GB文本语料库[BDW+20],以及[ZKZ+15]。
预训练设置
我们对BEIT-3进行1M步的预训练。每批共6144个样本,其中图像2048个,文本2048个,图像-文本对2048个。与对照模型[RKH+21, JYX+21, YWV+22]相比,批量大小要小得多。BEIT-3使用14 × 14的补丁大小,并以224 × 224的分辨率进行预训练。我们使用与BEIT [BDPW22]相同的图像增强,包括随机调整大小裁剪,水平翻转和颜色抖动[WXYL18]。使用一个具有64k词汇大小的sentencepece标记器[KR18]对文本数据进行标记。我们使用β1 = 0:9, β2 = 0:98, 学习率 =1e-6的AdamW [LH19]优化器进行优化。我们使用余弦学习率衰减调度器,其峰值学习率为1e-3,线性预热为10k步。权重衰减为0:05。采用随机深度[HSL+16],比率为0:1。使用BEiT初始化算法[BDPW22]来稳定Transformer的训练。
3.视觉与视觉语言任务实验
我们在视觉语言和视觉任务的主要公共基准上广泛评估了BEIT-3。表1给出了结果概述。BEIT-3在广泛的视觉和视觉语言任务上获得了最先进的性能。
表1:各种视觉和视觉语言基准测试的BEIT-3结果概述。我们比较了以前最先进的型号,包括FD-SwinV2 [WHX+22], DINO [ZLL+22], Mask DINO [ZLL+22], FD-CLIP [WHX+22], CoCa [YWV+22], OFA [WYM+22], Florence [YCC+21]。我们报告了检索任务的前1名图像到文本和文本到图像结果的平均值。“y”表示ImageNet结果仅使用可公开访问的资源。“z”表示未经CIDEr优化的图像字幕结果。
3.1视觉语言下游任务
我们在广泛使用的视觉语言理解和生成基准上评估了BEIT-3的能力,包括视觉问答[GKS+17]、视觉推理[SZZ+19]、图像文本检索[PWC+15, LMB+14]和图像字幕[LMB+14]。
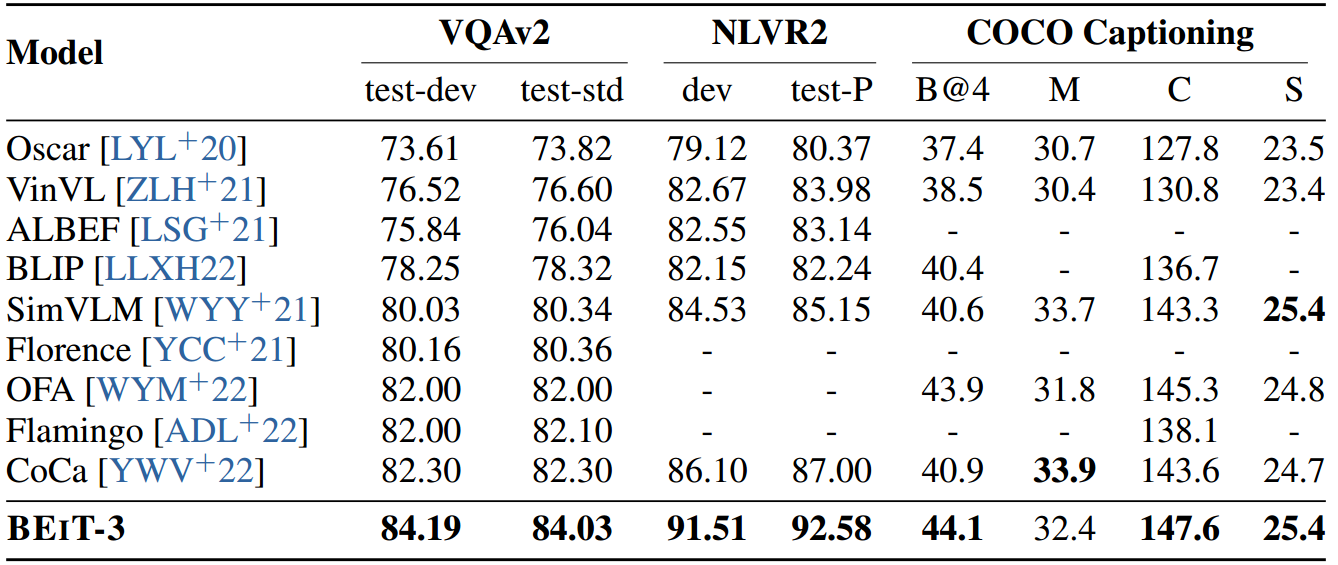
表4:视觉问答、视觉推理和图像字幕任务的结果。我们报告了VQAv2测试开发和测试标准分割上的vqa得分,NLVR2开发集和公共测试集(test- p)的准确性。对于COCO图像字幕,我们报告BLEU@4 (B@4), METEOR (M), CIDEr (C)和SPICE (S)在Karpathy测试分裂上。为简单起见,我们在不使用CIDEr优化的情况下报告标题结果。
3.2视觉下游任务
除了视觉语言下游任务外,BEIT-3还可以应用于广泛的视觉下游任务,包括目标检测、实例分割、语义分割和图像分类。当使用BEIT-3作为视觉编码器时,有效参数的数量与viti -giant [ZKHB21]相当,约为1B。
目标检测和实例分割
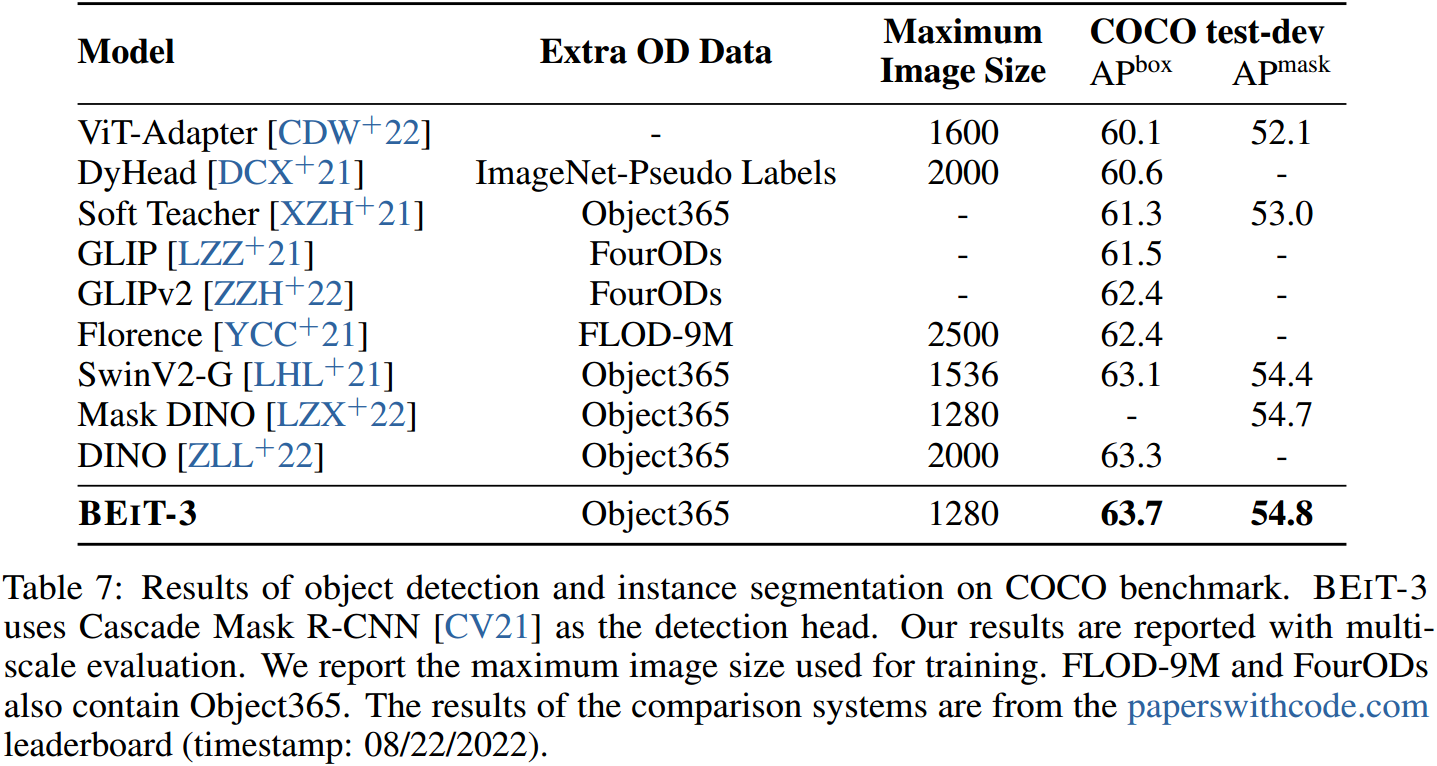
我们在COCO 2017基准[LMB+14]上进行了微调实验,该基准由118k训练图像、5k验证图像和20k测试开发图像组成。我们使用BEIT-3作为骨干,并遵循ViTDet [LMGH22],包括简单的特征金字塔和窗口关注,用于目标检测和实例分割任务。按照常用的做法[LHL+21, ZLL+22],我们首先对Objects365 [SLZ+19]数据集进行中间调优。然后在COCO数据集上对模型进行微调。在推理时使用Soft-NMS [BSCD17]。表7将BEIT-3与以前最先进的模型在COCO对象检测和实例分割方面进行了比较。BEIT-3在COCO测试开发集上实现了最佳效果,用于微调的图像尺寸较小,达到63:7盒AP和54:8掩模AP。
图像分类
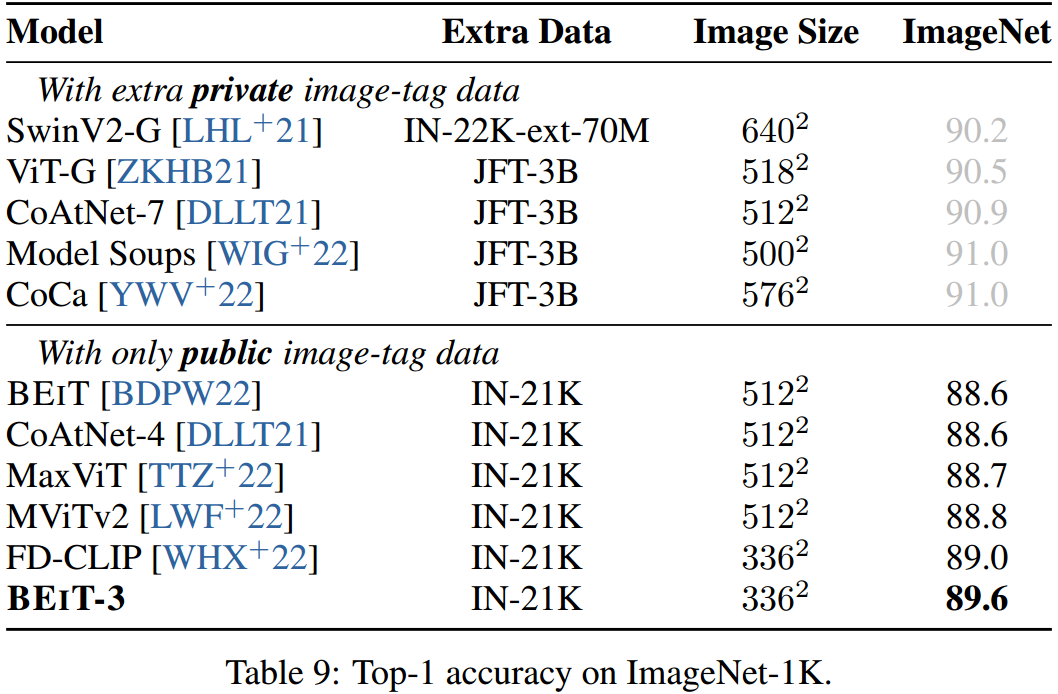
我们在ImageNet-1K [RDS+15]上对模型进行评估,该模型包含1k个类别中的1:28M训练图像和50k验证图像。我们没有在视觉编码器上附加任务层[DBK+20, BDPW22],而是将任务制定为图像到文本检索任务。我们使用类别名称作为文本来构造图像-文本对。BEIT-3被训练成一个双编码器来为图像找到最相关的标签。在推理过程中,我们首先计算特征嵌入可能的类名和图像的特征嵌入。然后计算它们的余弦相似度分数来预测每个图像最可能的标签。表9报告了在ImageNet-1K上的结果。首先在ImageNet-21K上进行中间调优,然后在ImageNet-1K上训练模型。为了公平比较,我们只使用公共图像标签数据与之前的模型进行比较。BEIT-3优于先前的模型,在仅使用公共图像标记数据时创建了新的最先进的结果。
4.结论
在本文中,我们提出了BEIT-3,这是一个通用的多模态基础模型,它在广泛的视觉和视觉语言基准上实现了最先进的性能。BEIT-3的核心思想是将图像建模为一种外语,这样我们就可以统一地对图像、文本和图像-文本对进行蒙面“语言”建模。我们还证明了Multiway transformer可以有效地对不同的视觉和视觉语言任务进行建模,使其成为通用建模的有趣选择。BEIT-3简单有效,是多模态基础模型放大的一个有希望的方向。对于未来的工作,我们将致力于对多语言BEIT-3进行预训练,并在BEIT-3中加入更多的模式(例如音频),以促进跨语言和跨模式的迁移,并推进跨任务、语言和模式的大规模预训练的大收敛。我们还对通过结合BEIT-3和MetaLM [HSD+22]的优势来实现多模态基础模型的上下文学习能力感兴趣。
参考资料
文章下载(2022年)
https://arxiv.org/abs/2208.10442
代码地址
https://github.com/microsoft/unilm/tree/master/beit3


















 1683
1683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











