






不惜一切代价
正如我们多次提到的,LLM 最看重的是规模。这是因为随着参数数量的增加,这些模型会开发出新功能。
因此,这些模型的每一代新模型通常都比之前的模型大得多,其中 GPT-4 的大小是 GPT-3 的十倍,而据传 GPT-5 比 GPT-4 大 30 倍(如果我们使用微软首席技术官 Kevin Scott 对训练集群规模的提及)。
然而,您可能也听说过,这些模型的运行成本很高,而且模型越大,成本就越高,特别是在推理过程中(运行时)。
但为什么?
前沿人工智能的经济学
Frontier AI 模型受内存限制,这意味着它们在实际饱和 GPU 的处理能力之前就已经饱和了 GPU 的内存。
这是因为用于训练和提供这些模型的硬件 GPU 比内存具有更强大的计算能力,而内存芯片实在是太贵了。因此,即使 GPU 可能具有足够的计算能力来处理模型,但该模型可能必须通过不同的并行技术(如数据、管道、张量、序列或专家并行(或多种类型的组合))同时分布在多个 GPU 上。
因此,LLM 推理集群以极大的处理折扣运行,很少超过全局处理能力的 40–50%(在数据中心术语中,该指标称为 MFU 或模型 FLOPs 利用率,对于 NVIDIA H100s,该值进一步下降到 30–40% 范围)。
此外,还需要考虑 GPU-GPU 通信成本(GPU 必须共享信息),这会增加模型的整体延迟。
尽管几乎不可避免地会产生一些通信开销,但某些 GPU 拓扑或外形尺寸(如Ring Attention)允许 AI 工程师以一种将通信成本与处理工作负载重叠的方式在 GPU 之间分配 LLM,从而最大限度地减少加速器空转并减少总体延迟。
毫不奇怪,多年来,研究人员一直试图在处理不断增加的模型尺寸的同时使这一过程更加高效。
现在,虽然解决内存问题不是很容易,除非你只是让模型更小,执行量化(降低参数精度,即减少小数),或者优化推理缓存,但有一个很好的方法可以通过减少所需的计算来提高吞吐量而不影响性能。
现在,谷歌将这种方法提升到了一个新的水平。但我们谈论的是什么方法呢?
专家混合问题
无需赘述,混合专家模型 (MoE) 本质上是将模型分解为多个较小的网络(称为专家),以对输入空间进行区域化。
通俗地说,每个专家都精通不同的输入主题,而其他专家则精通其他主题。因此,在推理过程中,我们将输入路由到模型中每个输入的前 k 名专家,丢弃其余输入。
当今最流行的模型是 MoE,例如前面提到的 GPT-4。
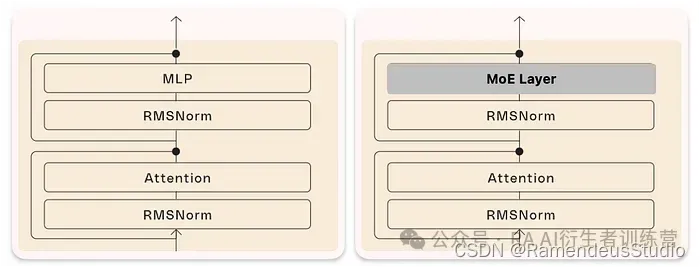
从技术角度上讲,我们知道 LLM 只是 Transformer 块的串联(下图左),我们引入了一种新类型的层,即 MoE 层,来替代标准 MLP 层,它们本质上是相同的,但分为专家。
但为什么要这么做呢?根据 Meta 的数据, MLP 占模型总参数数量的三分之二以上,更重要的是,它们占所需计算量的很大一部分,在某些情况下甚至达到 98% 。因此,对它们进行碎片化会显著减少计算量。
例如,Mixtral-8×22 B 是一个 1760 亿参数的模型,分为 8 个专家。因此,如果我们每个预测只激活一个专家而不是运行整个模型,则只有 220 亿个参数会激活。
这使模型的计算需求减少了大约八分之一,尽管计算并不精确,因为模型仅在前馈层上划分,而注意力机制保持不变。
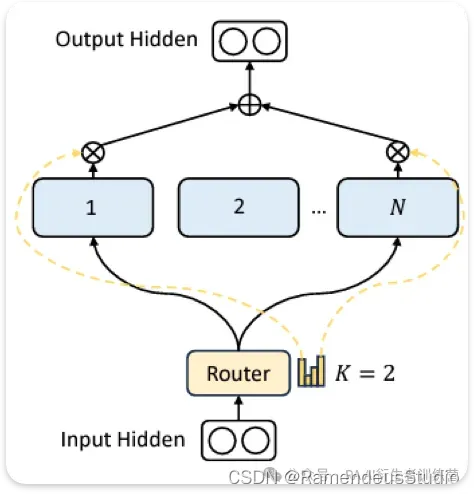
MoE 层
那么延迟又如何呢?这很难估计,因为我们必须考虑我们前面提到的 GPU 拓扑和分布方法,这会极大地改变整体情况。但是,作为参考,在 Mixtral-8×7B 中,Mistral 声称计算量下降了 4 倍(每个预测有 2 个活跃专家,延迟减少了 6 倍)。
令人兴奋的是,正如谷歌在 2022 年证明的那样,将网络划分为专家似乎也可以提高性能,这导致了过去几年 MoE 模型的绝对狂热。
然而,尽管更高的粒度(更多的专家)是极其可取的,但这是一个棘手的问题。
到目前为止。
百万专家网络
Google 创建了参数高效专家检索 (PEER),一种将 LLM 划分为百万名专家的新方法。
具体来说,该模型平衡了输入和专家的注意力。但这意味着什么呢?
在 LLM 的核心中,我们有注意力机制,它允许输入序列中的单词相互交流、共享信息并根据周围环境更新其含义。
换句话说,注意力机制的作用是,从序列的其他部分检索语义相关的上下文,并更新与该上下文相关的单词含义。
对于序列“我爱我的棒球棒”,我们利用注意力将“棒”的含义更新为“棒球”,这样现在“棒”指的是棒球棒而不是动物。
然而,在这里,我们以一种完全不同的方式使用注意力:针对任何给定的输入检索最熟练的专家。思考这个问题的最直观的方法是模型使用输入作为查询并询问“网络中的哪些专家最适合此输入?”
然后查询检索到的专家,并将其信息嵌入到输入中。
例如,如果输入是“迈克尔乔丹”,我们可能会检索篮球和耐克专家,并将“篮球”和“耐克运动员”的概念嵌入到输入中,以区分运动员和好莱坞演员。
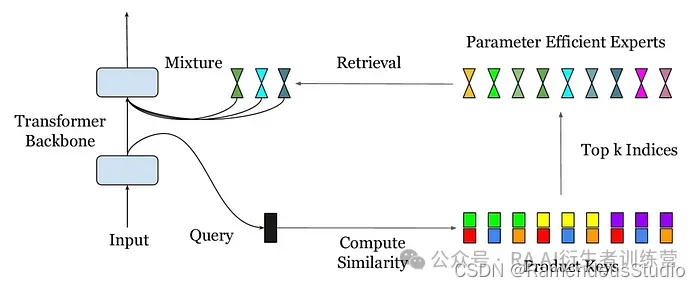
与其他更传统的方法相比,该解决方案不仅计算效率更高,而且还降低了困惑度(我们评估模型质量的指标),在人工智能领域达到了极为罕见的水平:
这些模型不仅提供更好的计算性能,而且它们实际上是更好的模型。
美好时光的标志
正如我们今天所报道的,谷歌已经找到了一种方法,PEER,将专家的粒度提高到百万,从而大大降低了这些模型的推理成本。
值得注意的是,这一发展与其他旨在优化内存使用的效率提升实现是相互关联的。然而,考虑到这种方法没有明显的缺点,至少在个位数的十亿级模型中,大多数方法都没有像 PEER 那样受到欢迎。
尽管如此,根据论文的签名,Gemini 1.5 Flash(速度极快但性能极高的 Gemini 模型)很可能已经在运行 PEER 架构。
谈到业务,谷歌的未来与人工智能密不可分,这已不是什么秘密。谷歌在技术开发方面不再落后于 OpenAI,但很少有人提及的是,在计算方面,谷歌遥遥领先于其他公司。
他们还拥有数量最多的可用数据,尤其是视频数据,每天上传到 YouTube 的视频数据相当于 2 千万亿个单词,足以训练 143 个 LLaMa 3 模型,并且有足够的自由现金流来引领下一个 AI 模型前沿(刚刚获得了有史以来的第一笔股息以及 700 亿美元的股票回购,也就是说,他们非常富有)。
资金充足尤为重要,因为下一个 AI 模型前沿将需要更多数量的计算和更大的模型。在这种情况下,考虑到该公司在上个季度大幅增加运营费用后已经面临降低运营费用的压力,像 PEER 这样的研究对他们来说很有意义。

![]() 欢迎前往我们的公众号,阅读更多时事资讯
欢迎前往我们的公众号,阅读更多时事资讯![]()
![]()
创作不易,觉得不错的话,点个赞吧!!!















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









