







优化方案1将原始方案的计算效率提高了 90% 以上,而白皮书认为这还不是最好的方案,原作者给出了另外两个更好的方案,这两个算法都不再基于对计算要求的直接理解,更换了 DAX 写法。本篇分析白皮书提供的优化方案2,并与优化方案1和优化方案(番外)进行比较,进一步认识性能优劣的底层原因。
研究《DAX查询计划 白皮书》中的案例(一)初始方案
研究《DAX查询计划 白皮书》中的案例(二)优化方案1
研究《DAX查询计划 白皮书》中的案例(三)优化方案(番外)
研究《DAX查询计划 白皮书》中的案例(四)优化方案2
研究《DAX查询计划 白皮书》中的案例(四)优化方案3
优化方案2
DAX 查询
// 优化方案2(原版)
EVALUATE
ADDCOLUMNS (
VALUES ( 'Date'[Date] ),
"OpenOrders",
COUNTROWS (
FILTER(
'Internet Sales',
CONTAINS (
DATESBETWEEN (
'Date'[Date],
'Internet Sales'[Order Date], // 白皮书提供的代码在这里没有+1
'Internet Sales'[Ship Date] - 1
),
'Date'[Date],
'Date'[Date]
)
)
)
)
这段代码与第一篇原始方案的结构类似,都是 COUNTROWS + FILTER 的写法,不过 FILTER 条件参数不再是简单的 Sales[OrderDate] < Calendar[Date] && Sales[ShipDate] > Calendar[Date] ,改成了 CONTAINS + DATESBETWEEN的判断。
白皮书发布于 2013 年,当时 DAX 还不支持 IN 这个符号(IN发布于 2016年12月),放在今天,这段代码可以修改成下面这样,后文的分析基于修改后的代码。
另外,白皮书给的算法有误,DATESBETWEEN('Calendar'[Date],Sales[OrderDate], Sales[ShipDate] - 1 ) 应该改成DATESBETWEEN('Calendar'[Date],Sales[OrderDate] +1 , Sales[ShipDate] - 1 ),起点不应该包括在内。
// 优化方案2(修正)
EVALUATE
ADDCOLUMNS (
VALUES ( 'Calendar'[Date] ),
"OpenOrders",
COUNTROWS (
FILTER (
Sales,
'Calendar'[Date] IN // 修改了这里l
DATESBETWEEN (
'Calendar'[Date],
Sales[OrderDate] + 1 // 修改了这里
Sales[ShipDate] - 1
)
)
)
)
运行效率
以连续5次冷启动的结果进行统计,将各方案的情况列写在表格里,数字下方括号里记录的是相对前一个方案的性能变化情况。相对优化方案1,优化方案2的总耗时又减少了1个数量级,从约 百级 降低到 十级,但是比优化方案(番外)耗稍长一些。
| 环境 | 参数 | 初始方案 | 优化方案1 | 优化方案2 | 优化方案(番外) |
|---|---|---|---|---|---|
| 环境1 | 平均总耗时(毫秒) | 4389.4 | 290.4 (↑ 93.38%) | 79.6 (↑ 72.59%) | 56.8 (↑ 28.64%) |
| SE耗时 (毫秒) | 14.4 | 4.8 | 13.6 | 4.8 | |
| SE占比 | 0.328% | 1.653% (↑ 403.83%) | 17.09% (↑ 933.67%) | 8.45% (↓50.54%) | |
| 环境2 | 平均总耗时(毫秒) | 4017.0 | 300.60 (↑ 92.52%) | 76.4 (↑ 74.58%) | 53.8 (↑ 29.58%) |
| SE耗时 (毫秒) | 17.2 | 5.8 (↑ 66.28%) | 18.2 | 5 | |
| SE占比 | 0.428% | 1.929% (↑ 350.62%) | 23.82% (↑ 1134.64%) | 9.29% (↓ 60.99%) |
白皮书原本的行文结构是逐步优化至最优,但是上一篇由于我的好奇整出个白皮书之外的优化方案(番外),比本篇的优化方案2运行更快,最快的放在表格最后一列上。
存储引擎部分
有必要把存储引擎相关界面截图,因为这里出现了新情况
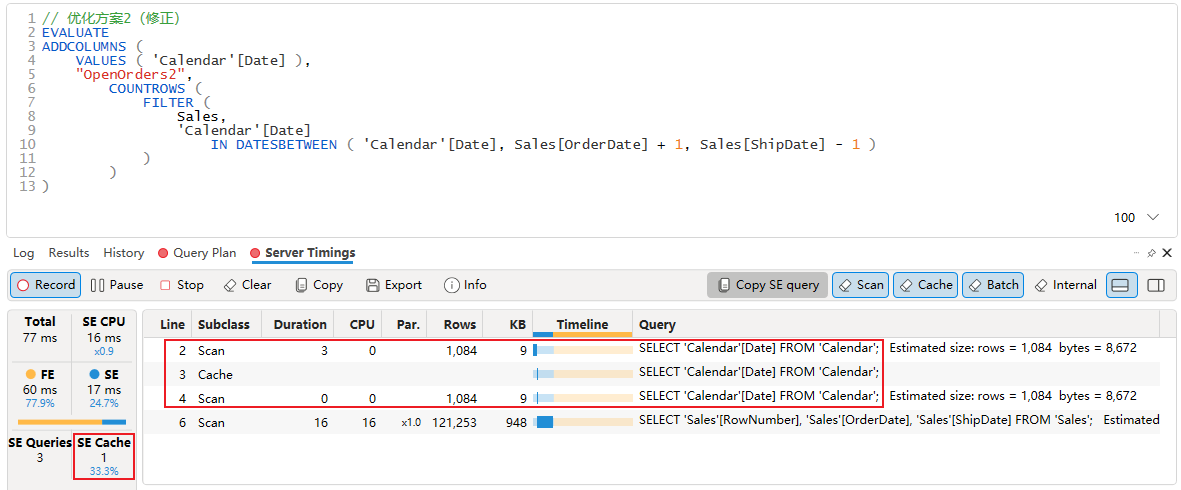
从 xmSQL 列表看,一共有 3 个 Scan 即 3 个 xmSQL 查询,左下角显示 SE Cache 命中1次。这 3 个 Scan 中有 2 个 xmSQL 查询是完全相同的,出现在 Line 2 和 Line 4,命中的 Cache 在 Line 3。
实际上只有 2 个 xmSQL,其中 1 个被重复使用。
1、VQ1:将 Calendar 表中按 Calendar[Date] 分组,返回由 [Date] 的不重复值,结果包含1列,共 1081 行数据
// xmSQL VQ1
SELECT
'Calendar'[Date]
FROM 'Calendar';
2、VQ2:将 Sales 表按 Sales[RowNumber]、Sales[OrderDate]、Sales[ShipDate] 分组,并返回这3列上的值。
SELECT
'Sales'[RowNumber],
'Sales'[OrderDate],
'Sales'[ShipDate]
FROM 'Sales';
读过前几篇文章的朋友知道,[RowNumber] 的出现,会使得查询结果包含 Sales 表的每一行,所以该查询返回 121253 行数据,共 3 列 Sales[RowNumber]、Sales[OrderDate]、Sales[ShipDate]
第一篇文章分析初始方案的性能瓶颈说过 [RowNumber] 的出现可能会导致后续出现超大规模的交叉表,而这次 [RowNumber] 也出现了,为什么性能没有低下反倒还提高了?之前也强调过了,并没有什么通用的优化写法,自然也就没有绝对禁用的禁忌写法,关键还得看各种写法生成的物理查询计划。
公式引擎部分
逻辑查询计划
终于,这次逻辑查询计划出现值得注意的信息了
AddColumns: RelLogOp DependOnCols()() 0-1 RequiredCols(0, 1)('Calendar'[Date], ''[OpenOrders])
├── Scan_Vertipaq: RelLogOp DependOnCols()() 0-0 RequiredCols(0)('Calendar'[Date])
└── CountRows: ScaLogOp DependOnCols(0)('Calendar'[Date]) Integer DominantValue=BLANK
└── Filter: RelLogOp DependOnCols(0)('Calendar'[Date]) 1-15 RequiredCols(0, 1, 6, 7)('Calendar'[Date], 'Sales'[RowNumber-2662979B-1795-4F74-8F37-6A1BA8059B61], 'Sales'[OrderDate], 'Sales'[ShipDate])
├── Scan_Vertipaq: RelLogOp DependOnCols()() 1-15 RequiredCols(1, 6, 7)('Sales'[RowNumber-2662979B-1795-4F74-8F37-6A1BA8059B61], 'Sales'[OrderDate], 'Sales'[ShipDate])
└── Not: ScaLogOp DependOnCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate]) Boolean DominantValue=false
└── IsEmpty: ScaLogOp DependOnCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate]) Boolean DominantValue=true
└── Filter: RelLogOp DependOnCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate]) 16-16 RequiredCols(0, 6, 7, 16)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate], 'Calendar'[Date])
├── DatesBetween: RelLogOp DependOnCols(6, 7)('Sales'[OrderDate], 'Sales'[ShipDate]) 16-16 RequiredCols(6, 7, 16)('Sales'[OrderDate], 'Sales'[ShipDate], 'Calendar'[Date])
│ ├── 'Sales'[OrderDate]: ScaLogOp DependOnCols(6)('Sales'[OrderDate]) DateTime DominantValue=NONE
│ └── Subtract: ScaLogOp DependOnCols(7)('Sales'[ShipDate]) DateTime DominantValue=NONE
│ ├── 'Sales'[ShipDate]: ScaLogOp DependOnCols(7)('Sales'[ShipDate]) DateTime DominantValue=NONE
│ └── Constant: ScaLogOp DependOnCols()() Integer DominantValue=1
└── Is: ScaLogOp DependOnCols(0, 16)('Calendar'[Date], 'Calendar'[Date]) Boolean DominantValue=false
├── 'Calendar'[Date]: ScaLogOp DependOnCols(16)('Calendar'[Date]) DateTime DominantValue=NONE
└── 'Calendar'[Date]: ScaLogOp DependOnCols(0)('Calendar'[Date]) DateTime DominantValue=NONE
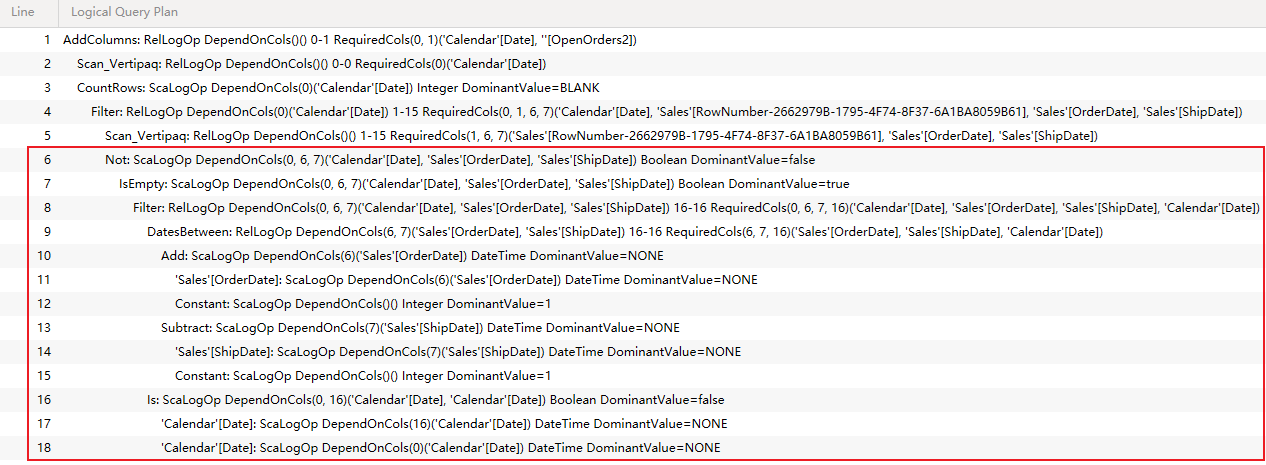
注意红框中的这部分,这部分对应的是 DAX 代码中的 IN,在结构流程图中也用方框标记一下
红框里的代码,按从上往下的结构将操作符写出来
NOT( ISEMPTY ( FILTER ( Table, Condition ) ) )
其代表的便是
IN DATESBETWEEN ( 'Calendar'[Date], Sales[OrderDate] + 1, Sales[ShipDate] - 1 )
为什么这么说?因为白皮书里就这么说的。白皮书发布于 2013年,当时的逻辑查询计划与今天不太一样,当年这部分逻辑查询计划是这样的:
NOT ( ISBLANK ( MINX ( FILTER ( Table, Condition ), 1 ) ) )
即便没有人告诉我们这部分代表的是 IN,通过对比逻辑查询计划与 DAX 代码的结构、结合 DAX 理论思考 IN 的判断过程,也能得出相同的结论:
1、4:Filter 读取 5:Scan_Vertipaq的行,提供行上下文 [Sales[Number],Sales[OrderDate],Sales[ShipDate]
2、根据 1# 行上下文中的 Sales[OrderDate]和 Sales[ShipDate] 分别计算 Sales[OrderDate]+1、 Sales[ShipDate]-1 两个日期区间端点,9:DatesBetween从 Calendar[Date] 中筛选出该区间内的全部 [Date]
3、1:AddColumns 读取2:Scan_Vertipaq,提供行上下文 Calendar[Date]
4、8:Filter 从 9:DatesBetween 生成的 [Date] 中,筛选出与 # 3 行上下文中的 [Date] 相同的数据。
5、4:Filter 以 NOT(IsEmpty(8:Filter)为条件筛选 5:Scan_Vertipaq
5-1、对于 2:Scan_Vertipaq 中某个具体的 Calendar[Date](记为 A) 以及5:Scan_Vertipaq 中某个具体的 [Sales[Number],Sales[OrderDate],Sales[ShipDate](记为 B),如果 4# 的结果不为空,说明 9:DatesBetween生成的 [Date] 区间中包含 A,7:IsEmpty 为假,6:Not为真,于是4:Filter判断 B 符合条件。
5-2、对于 2:Scan_Vertipaq 中某个具体的 Calendar[Date](记为 A) 以及5:Scan_Vertipaq 中某个具体的 [Sales[Number],Sales[OrderDate],Sales[ShipDate](记为 B),如果 4# 的结果为空,说明 9:DatesBetween生成的 [Date] 区间中不包含 A,7:IsEmpty 为真,6:Not为加,于是4:Filter判断 B 不符合条件。
对应的是这一段代码
FILTER(
Sales,
NOT(ISEMPTY(
FILTER(
DATESBETWEEN (
'Calendar'[Date],
Sales[OrderDate] + 1
Sales[ShipDate] - 1
),
'Calednar'[Date] = EARLIER('Calendar'[Date])
//EARLIER('Calendar'[Date]) 从最外层 ADDCOLUMNS 提供的行上下文中获取
)
))
)
也就是 DAX 查询代码中的 IN 这一部分
FILTER (
Sales,
'Calendar'[Date] IN // 由最外层 ADDCOLUMNS 提供
DATESBETWEEN (
'Calendar'[Date],
Sales[OrderDate] + 1
Sales[ShipDate] - 1
)
)
逻辑查询计划中并不一定完全按照 DAX 查询代码使用的符号,比如这一段逻辑查询计划中就不存在 IN 这样的符号,IN 的实现通过一系列可能不太直观的操作来完成。
在逻辑查询计划中识别到该部分可以帮助后面在物理查询计划中找出哪部分再执行 IN这个计算。
这便是逻辑查询计划中值得注意的信息。
物理查询计划
这次物理查询计划较长
AddColumns: IterPhyOp LogOp=AddColumns IterCols(0, 1)('Calendar'[Date], ''[OpenOrders2])
├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=20 #ValueCols=0
│ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
└── SpoolLookup: LookupPhyOp LogOp=CountRows LookupCols(0)('Calendar'[Date]) Integer #Records=1079 #KeyCols=1 #ValueCols=1 DominantValue=BLANK
└── AggregationSpool<Count>: SpoolPhyOp #Records=1079
└── Filter: IterPhyOp LogOp=Filter IterCols(0, 1, 6, 7)('Calendar'[Date], 'Sales'[RowNumber], 'Sales'[OrderDate], 'Sales'[ShipDate])
└── CrossApply: IterPhyOp LogOp=Not IterCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate])
├── Spool_MultiValuedHashLookup: IterPhyOp LogOp=Scan_Vertipaq LookupCols(6, 7)('Sales'[OrderDate], 'Sales'[ShipDate]) IterCols(1)('Sales'[RowNumber]) #Records=121253 #KeyCols=20 #ValueCols=0
│ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=121253
│ └── Cache: IterPhyOp #FieldCols=3 #ValueCols=0
└── Not: IterPhyOp LogOp=Not IterCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate])
└── Extend_Const: IterPhyOp LogOp=IsEmpty IterCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate])
└── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Filter IterCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate]) #Records=6444 #KeyCols=3 #ValueCols=0
└── AggregationSpool<GroupBy>: SpoolPhyOp #Records=6444
└── Filter: IterPhyOp LogOp=Filter IterCols(0, 6, 7, 16)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate], 'Calendar'[Date])
└── CrossApply: IterPhyOp LogOp=Is IterCols(0, 16)('Calendar'[Date], 'Calendar'[Date])
├── Spool_MultiValuedHashLookup: IterPhyOp LogOp=DatesBetween LookupCols(16)('Calendar'[Date]) IterCols(6, 7)('Sales'[OrderDate], 'Sales'[ShipDate]) #Records=6444 #KeyCols=3 #ValueCols=0
│ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=6444
│ └── DatesBetween: IterPhyOp LogOp=DatesBetween IterCols(6, 7, 16)('Sales'[OrderDate], 'Sales'[ShipDate], 'Calendar'[Date])
│ ├── Extend_Lookup: IterPhyOp LogOp=Add IterCols(6)('Sales'[OrderDate])
│ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(6, 7)('Sales'[OrderDate], 'Sales'[ShipDate]) #Records=1081 #KeyCols=2 #ValueCols=0
│ │ │ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=1081
│ │ │ └── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(1, 6, 7)('Sales'[RowNumber], 'Sales'[OrderDate], 'Sales'[ShipDate]) #Records=121253 #KeyCols=20 #ValueCols=0
│ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=121253
│ │ │ └── Cache: IterPhyOp #FieldCols=3 #ValueCols=0
│ │ └── Add: LookupPhyOp LogOp=Add LookupCols(6)('Sales'[OrderDate]) DateTime
│ │ ├── ColValue<'Sales'[OrderDate]>: LookupPhyOp LogOp=ColValue<'Sales'[OrderDate]>'Sales'[OrderDate] LookupCols(6)('Sales'[OrderDate]) DateTime
│ │ └── Constant: LookupPhyOp LogOp=Constant Integer 1
│ └── Subtract: LookupPhyOp LogOp=Subtract LookupCols(7)('Sales'[ShipDate]) DateTime
│ ├── ColValue<'Sales'[ShipDate]>: LookupPhyOp LogOp=ColValue<'Sales'[ShipDate]>'Sales'[ShipDate] LookupCols(7)('Sales'[ShipDate]) DateTime
│ └── Constant: LookupPhyOp LogOp=Constant Integer 1
└── InnerHashJoin: IterPhyOp LogOp=Is IterCols(0, 16)('Calendar'[Date], 'Calendar'[Date])
├── Extend_Lookup: IterPhyOp LogOp=Extend_Lookup'Calendar'[Date] IterCols(0)('Calendar'[Date])
│ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=20 #ValueCols=0
│ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ └── ColValue<'Calendar'[Date]>: LookupPhyOp LogOp=ColValue<'Calendar'[Date]>'Calendar'[Date] LookupCols(0)('Calendar'[Date]) DateTime
└── HashLookup: IterPhyOp LogOp=HashLookup'Calendar'[Date] IterCols(16)('Calendar'[Date]) #Recs=1079
└── HashByValue: SpoolPhyOp #Records=1079
└── Extend_Lookup: IterPhyOp LogOp=Extend_Lookup'Calendar'[Date] IterCols(16)('Calendar'[Date])
├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=DatesBetween IterCols(16)('Calendar'[Date]) #Records=1079 #KeyCols=1 #ValueCols=0
│ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=1079
│ └── DatesBetween: IterPhyOp LogOp=DatesBetween IterCols(6, 7, 16)('Sales'[OrderDate], 'Sales'[ShipDate], 'Calendar'[Date])
│ ├── Extend_Lookup: IterPhyOp LogOp=Add IterCols(6)('Sales'[OrderDate])
│ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(6, 7)('Sales'[OrderDate], 'Sales'[ShipDate]) #Records=1081 #KeyCols=2 #ValueCols=0
│ │ │ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=1081
│ │ │ └── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(1, 6, 7)('Sales'[RowNumber], 'Sales'[OrderDate], 'Sales'[ShipDate]) #Records=121253 #KeyCols=20 #ValueCols=0
│ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=121253
│ │ │ └── Cache: IterPhyOp #FieldCols=3 #ValueCols=0
│ │ └── Add: LookupPhyOp LogOp=Add LookupCols(6)('Sales'[OrderDate]) DateTime
│ │ ├── ColValue<'Sales'[OrderDate]>: LookupPhyOp LogOp=ColValue<'Sales'[OrderDate]>'Sales'[OrderDate] LookupCols(6)('Sales'[OrderDate]) DateTime
│ │ └── Constant: LookupPhyOp LogOp=Constant Integer 1
│ └── Subtract: LookupPhyOp LogOp=Subtract LookupCols(7)('Sales'[ShipDate]) DateTime
│ ├── ColValue<'Sales'[ShipDate]>: LookupPhyOp LogOp=ColValue<'Sales'[ShipDate]>'Sales'[ShipDate] LookupCols(7)('Sales'[ShipDate]) DateTime
│ └── Constant: LookupPhyOp LogOp=Constant Integer 1
└── ColValue<'Calendar'[Date]>: LookupPhyOp LogOp=ColValue<'Calendar'[Date]>'Calendar'[Date] LookupCols(16)('Calendar'[Date]) DateTime

如果直接画结构流程图太长了,我将一些中间步骤精简一下,留下我觉得需要关注的操作符。找一下刚才在逻辑查询计划的NOT( ISEMPTY ( FILTER ( Table, Condition ) ) )部分标记出来。
底层计算过程
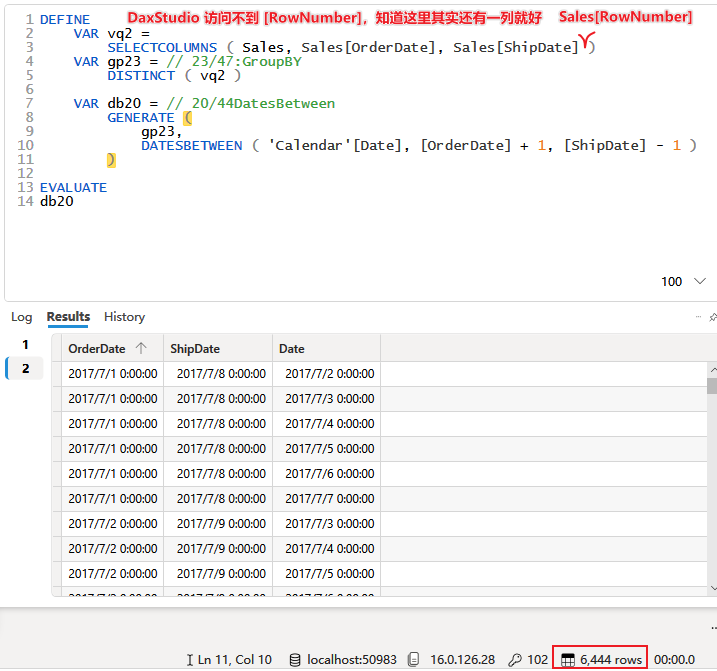
从下往上,按大块来分析,首先分析 [DatesBetween] 这一块
一
DatesBetween 块
(1) 26/50:VQ2 包含 Sales 表中每一行的 [RowNumber]、[OrderDate]、[ShipDate],共 121253 行
(2) 23/47:GroupBy 将 (1)# 的结果表按照 Sales[OrderDate]、Sales[ShipDate] 分组,共 1081 行
(3) 21/45:Extend_Lookup 与 27/51:Add、 30/54:Subtract ,从(2)# 的结果中逐行计算 Sales[OrderDate]+1 和 Sales[ShipDate] -1,仍是 1081 行
(4) 20/44:DatesBetween 以(3)# 中每一行的 Sales[OrderDate]+1 和 Sales[ShipDate] -1 作为条件,从 Calendar[Date] 筛选出符合 Sales[OrderDate] < Calendar[Date] < Sales[ShipDate] 的数据并与对应的 Sales[OrderDate]、Sales[ShipDate]合并,共 6444 行
可以用下面这段 DAX 查询代码的结果来理解
二
DatesBetween 往上
43:GroupBY把 DatesBetween块产生的 6444 行数据(包含 Calendar[Date], Sales[OrderDate],Sales[Shipdate] 3 列) 按 [Date] 分组,等价于对 [Date] 列去重返回不重复值,共 1079 行
41:Extend_Lookup和57:Calendar[Date]是从43:GroupBy中取出行上下文中的 [Date] 值
37:VQ1从存储引擎获取 VQ1,得到 Calendar[Date] 列中共 1081 个值
33:InnerHashJoin从37:VQ1中逐一取出 [Date] 值,并通过 41:Extend_Lookup和57:Calendar[Date]从43:GroupBy中取出 DatesBetween 生成的 [Date] 值逐一比对,保留相同值。也可以简单描述为:37:VQ1 与 43:GroupBy 做内连接,得到 两列 [Date],[Date]。共 1079 行
两列都是 [Date] 吗?是的。
为了进一步说明这里在做什么,下面要讲一些让人头晕的东西,我将用 [Date](16) 表示 DatesBetween 中的 [Date],用 [Date](0)表示 Calendar 表中的 [Date]:
这个过程有点绕,
43:GroupBy 从 DatesBetween 中取出 [Date](16)(的不重复值),37:VQ1 从 Calendar 表中取出[Date](0),33:InnerHashJoin将[Date](16)和 [Date](0)内连接,得到两者的交集,含有两列,[Date](16), [Date](0)。
19:GroupBy 从 DatesBetween 中取出[Date](16), [OrderDate],[ShipDate],17:CrossApply 通过 18:MultiValuedHashLookup,将 19:GroupBy 的[Date](16), [OrderDate],[ShipDate] 与 33:InnerHashJoin 的 [Date](16), [Date](0) 通过该表中的 [Date](16)匹配并合并,最终得到是一张有 4 列的表,这4列分别是:
[Date](0),[Date](16),Sales[OrderDate],Sales[ShipDate]
共 6444 行。
为什么会出现[Date](0), [Date](16)这两个东西,不都是 Calendar[Date] 列吗?
数字 0 和数字 16 可不是我乱编的,而是真实记录在物理查询计划代码中的,比如第一行

AddColumns: IterPhyOp LogOp=AddColumns IterCols(0, 1)('Calendar'[Date], ''[OpenOrders2])
IterCols(0,1)('Calendar'[Date], ''[OpenOrders2]),IterCols后面第一个括号里的0,对应了第二个括号中的第一个参数'Calendar'[Date]。
在后面的物理查询计划中,凡是出现IterCols(..0..)(..'Calendar'[Date]..)字样,都是 0 表示这个[Date]列跟第一行的[Date]列来自同一处。
再比如第33行,也就是上文的33:InnerHashJoin

InnerHashJoin: IterPhyOp LogOp=Is IterCols(0, 16)('Calendar'[Date], 'Calendar'[Date])
IterCols(0, 16)('Calendar'[Date], 'Calendar'[Date]),这里提供的信息告诉我们,两个 Calendar[Date] 一个是 [Date](0),另一个是[Data](16),这其中的[Date](0)与前面一段话中说的第一行中的 [Data](0) 是同一个。
那[Date](16)是从哪来的?
在第44行:

DatesBetween: IterPhyOp LogOp=DatesBetween IterCols(6, 7, 16)('Sales'[OrderDate], 'Sales'[ShipDate], 'Calendar'[Date])
这就是DatesBetween块中的 20/44:DatesBetween,(20/44是表示在第20行和第44行都是相同的代码)

DatesBetween 生成的数据中包含的 Calendar[Date] 是 [Date](16),与[Date](0)是不同的。
为什么要区分不同的 [Date]?回想一下 DAX 理论,哪个部分讲过需要对同一列进行区分?
是嵌套行上下文,DAX 理论告诉我们当行上下文存在嵌套时,同一列在不同层次的行上下文中,可以有不同的值,可以使用函数 EARLIER 取得某层的行上下文。
在底层的物理查询计划中,虽然名称一样,但来自不同内容的列,用不同的数字标号标记,比如[Date](16) 来自 DatesBetween迭代器,而[Date](0)来自 AddColumns迭代器,
也许这样标记一下会更好理解
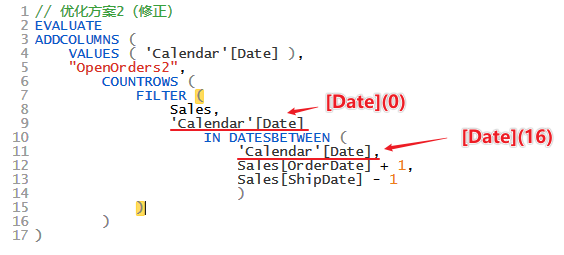
总之,本小节描述的这一部分物理查询计划,生成了这样一个结果:
[Date](0), Sales[OrderDate](6), Sales[ShipDate](7), [Date](16)
物理查询计划的第16行也对此有提示

Filter: IterPhyOp LogOp=Filter IterCols(0, 6, 7, 16)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate], 'Calendar'[Date])
6和7分别对应了Sales[OrderDate], Sales[ShipDate],不过这里不重要,因为全篇没有其他 Sales[OrderDate], Sales[ShipDate] 需要区分。
非要弄出两个[Date]来有什么意义吗?有,往后看。
三
继续往上,7:Filter 将通过 IN 的判断从 Sales 表中筛选出符合条件的数据。
7:Filter 、 8.CrossApply 、9:MultiValuedHashLookup 操作符用 11:VQ2中每一行的 Sales[OrderDate] 和 Sales[ShipDate] 作为匹配列,将 11:VQ2 与 14:Spool_Iterator 以Sales[OrderDate], Sales[ShipDate]为匹配列进行查询合并,得到另一张包含4列的结果表,共 714840 行,实际这就是将 Sales 表里每一行的 [OrderDate]、[ShipDate] 期间的 Calendar[Date] 合并了进来。
[Date](0),Sales[RowNumber],Sales[OrderDate],Sales[ShipDate]
Date[16]不见了,只剩下 [Date](0)。为什么需要 [Date](0)而不需要[Date](16),继续往下看。
四
最后一步
1:AddColumns 以 4:VQ1为基准,通过 6:Aggregate对7:Filter生成的数据表,以 [Date](0)进行分组并进行计数,得到最终的结果。
注意我在 4:VQ1块特意标记了 (0),因为这个 [Date]来自AddColumns。上一节7:Filter的结果中留下 [Date](0)丢掉[Date](16)的原因就在这里,既然最后一步要用到 [Date](0)来匹配,就需数据表里也包含有 [DATE](0),如果7:Filter里留下的是 [DATE](16),那就不能匹配了。
在 DAX 底层,很多操作的作用是为了匹配列,比如本例中DatesBetween 中的 [Date](16)经过步骤三最后生成了匹配的[Date](0)。
性能分析
优化方案2的性能介于优化方案1和优化方案(番外)之间,这几篇文章一直在介绍中间步骤产生的数据量的大小对性能的影响,那么就把这3个方案放一起再横向比较一下。
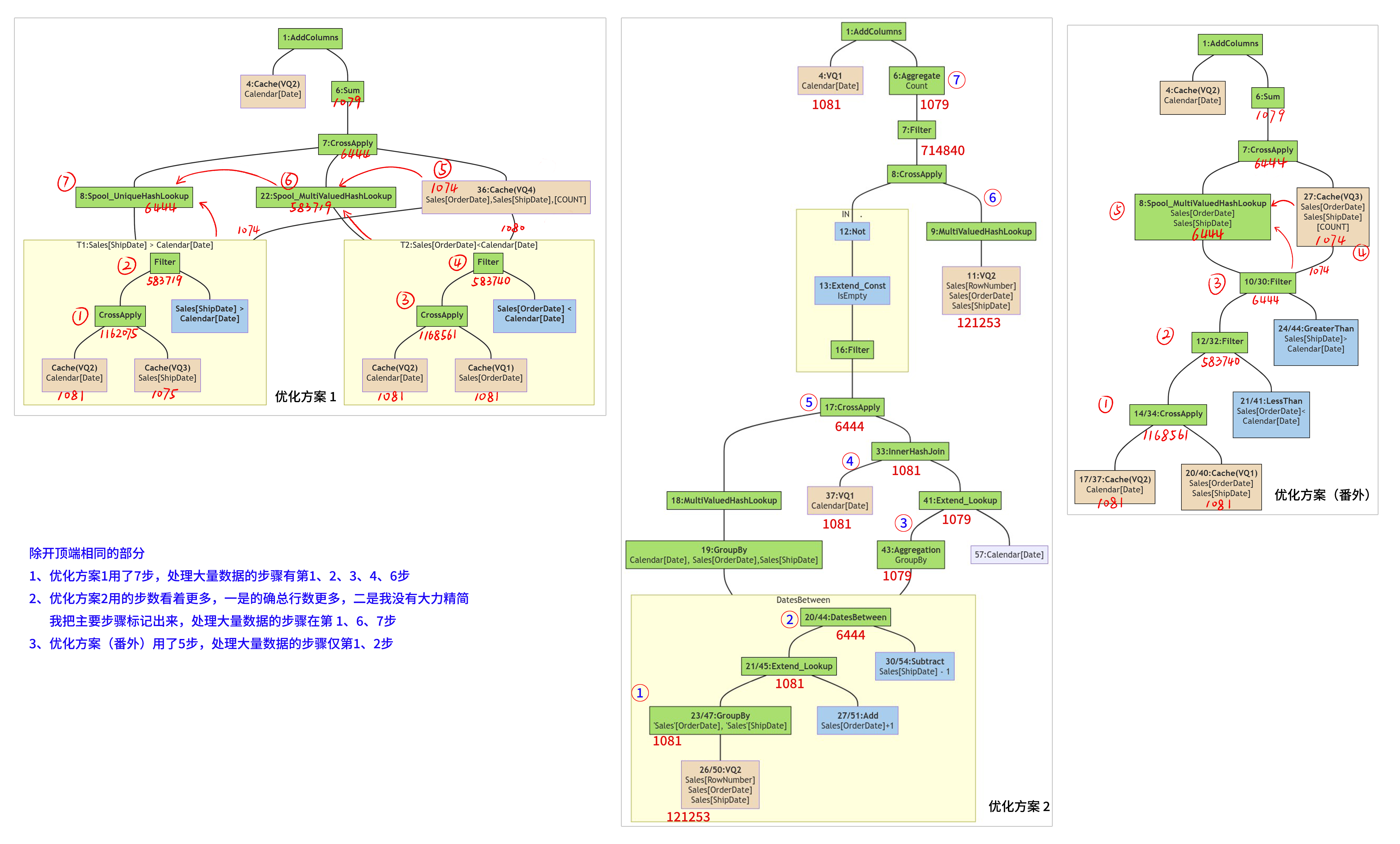
从物理查询计划的行数来看,优化方案2的物理查询计划的确是最长的,由于 DatesBetween的存在,它的步骤看上去也确实很多,但大多数步骤处理的数据量相对较小,只有图中标记的第1(2次)、6、7步处理了十万级的数据,共4次。
优化方案1中两个独立的 FILTER 产生了两个 交叉表+筛选,1(2次)、2(2次)、3(2次)、4(2次)、6、7 步需要处理十万级的数据,共10次。
优化方案(番外) 只在 1(2次)、2(2次)两步需要处理十万级的数据,共4次。
| 优化方案1 | 优化方案2 | 优化方案(番外) | |
|---|---|---|---|
| 处理10万级数据的步骤次数 | 10 | 4 | 4 |
| 测试总耗时(毫秒)【环境1】 | 290.4 | 79.6 | 56.8 |
| 测试总耗时(毫秒)【环境2】 | 300.6 | 76.4 | 53.8 |
处理10万级以上数据的步骤数量差异、各步骤处理的具体数据数量差异,再加上剩下的其他步骤,导致了3个方案的性能差异。优化方案(番外)耗时更少的原因,应该是它的步骤更少。
瓶颈分析
一、 RowNumber
很显然,RowNumber 的出现增加需要处理的数据量,使 121253 行 Sales 表都需要物化,尽管在整个底层计算过程中只出现了 3 次,分别在第1(2次)、6步,如果能想法将 [RowNumber] 去掉也许会更好。
二、DateBetween 的潜在问题
第一步使用了 DatesBetween 从 Calendar[Date] 中获取 [OrderDate]+1、[ShipDate]-1 区间的日期,其生成数据量取决于 [OrderDate] 与 [ShipDate] 之间的天数,例如用一个简化的数据表作演示,第一步计算过程和结果如下:
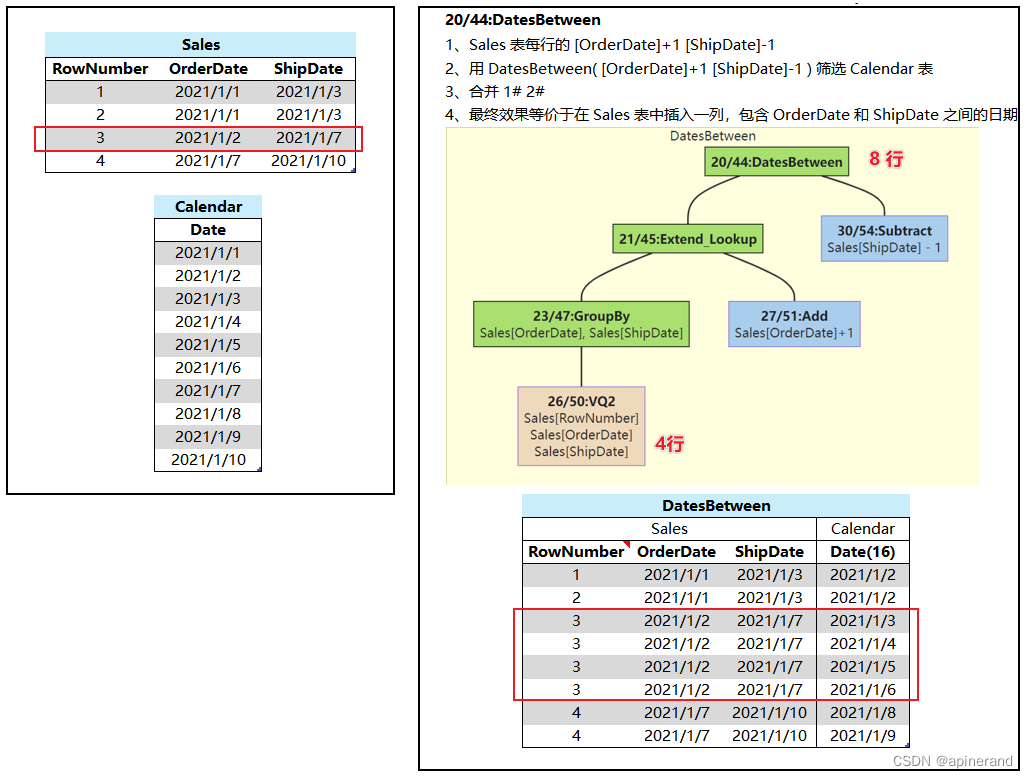
图中用红框标记了 Sales 表里 RowNumber = 3 这行及其对应的结果,这一行的 OrderDate 和 ShipDate 分别是 2021/1/2 和 2021/1/7,生成的结果表便包含了之间的日期 2021/1/3, 2021/1/4, 2021/1/5, 2021/1/6 ,共4行。
如果 OrderDate 与 ShipDate 两个日期相差很大,比如 2021-1-1 到 2022-1-1,那么生成的结果表中将包含近一整年的日期,数据量增加。
DatesBetween块产生的数据量,取决于 Sales 表中各行 OrderDate 与 ShipDate 之间包含的天数。
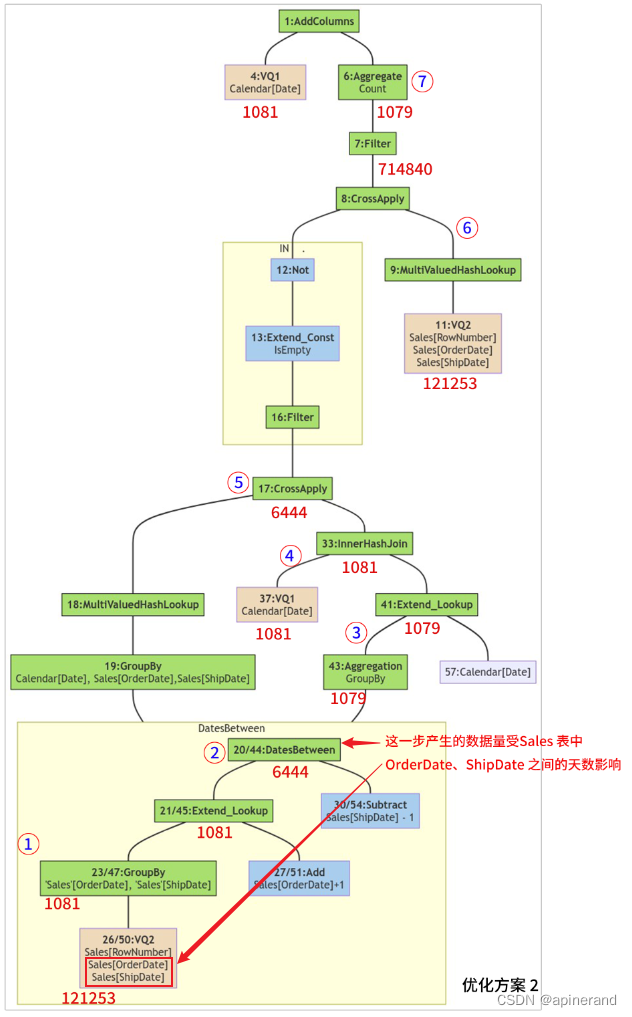
在本案例中,Sales 表中除了部分行的 [ShipDate] 记录是空白,有记录的每一行 [OrderDate] 与 [ShipDate] 都是间隔 6 天。1074 个不重复值对 { [OrderDate] , [ShipDate] },每个都间隔6天,于是在这一步产生的数据量是 1074 × 6 = 6444 行。
当更换另一张 Sales 表,如果存在大量数据行中 [OrderDate] 与 [ShipDate] 相差间隔日期很大,那么这一步生成的数据量就不是 6444 ,而可能是上万行甚至更多,计算速度就会变慢。
优化方案2并不具备通用性,它的计算效率受 Sales 表中 [OrderDate] 和 [ShipDate] 两列数据的分布影响。
因此,优化 DAX 计算性能,并不是只需要关心 DAX 代码怎么写,还要关注数据模型的情况。
总结
一
物理查询计划会通过给列加序号来区分,同一个列可以重复出现但序号不同,可以与 DAX 理论中行上下文嵌套的概念参照对应。
二
DAX 底层很多重复的操作块,很多时候是在更换列,比如本例中 DatesBetween 生成的 [Date](16),需要在最后一步之前与 AddColumns 生成的 [Date](0)匹配对应。
三
DAX 底层处理大量数据的步骤越多,执行需要的时间越长,因此优化的方向是:减少步骤 + 尽快减少数据量。比如案例中的最终结果只有 1081 行,比较3个方案,优化方案(番外) 从 1081×1081=1168561 行开始,快速几步就将需要处理的数据从百万级降到千级,所以目前它计算得最快。
四
优化方案可能只对当前数据模型有效,换一个数据模型,同样的写法可能并不能取得优化效果。
模拟每个步骤计算过程
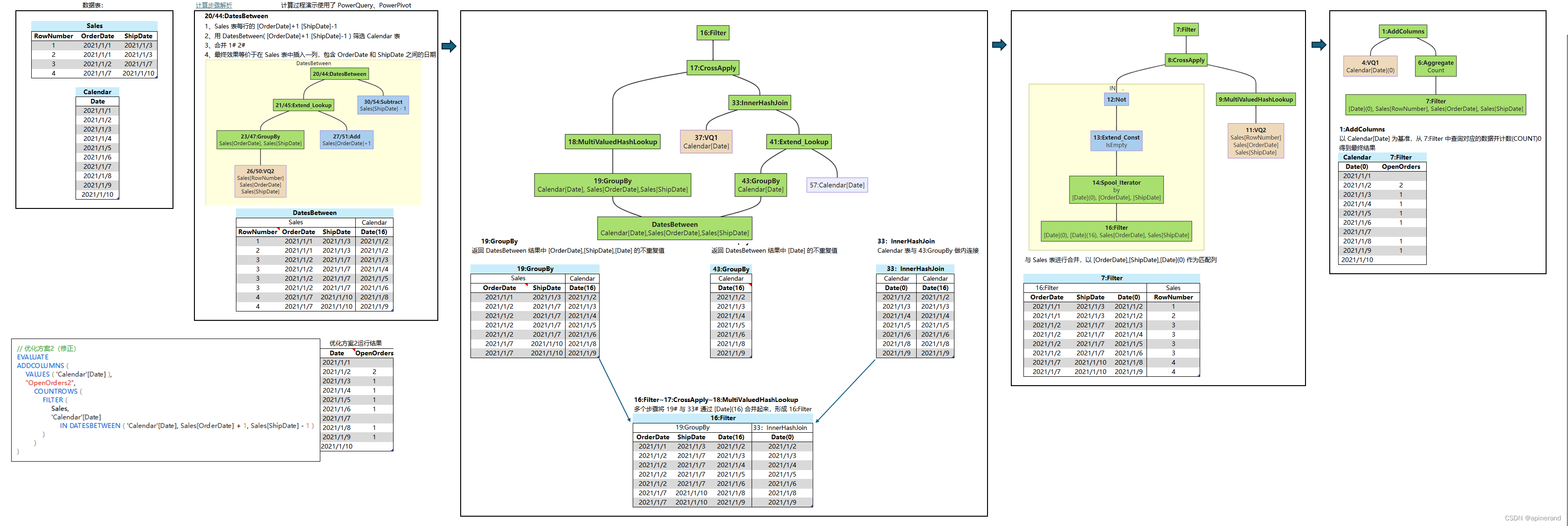
鉴于本篇所讲的案例过程相对复杂,我在 Excel 中用 DAX、PowerQuery、公式 模拟了动态计算过程,用户可以自行更改数据源(需要手动更改日期表),刷新后可自动重算。
希望可以帮助理解本文。
下载资源文件















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









