







这是本系列的最后一个优化方案,这一篇的优化方案3是所有方案中最优秀的,它解决了优化方案2中产生的[RowNumber] 问题,使整个底层计算过程中全部步骤都没有出现数据量超过万行的情况,使性能获得了极大的提升!
研究《DAX查询计划 白皮书》中的案例(一)初始方案
研究《DAX查询计划 白皮书》中的案例(二)优化方案1
研究《DAX查询计划 白皮书》中的案例(三)优化方案(番外)
研究《DAX查询计划 白皮书》中的案例(四)优化方案2
研究《DAX查询计划 白皮书》中的案例(四)优化方案3
优化方案3
DAX 查询
// 优化方案3(修正)
EVALUATE
ADDCOLUMNS (
VALUES ( 'Calendar'[Date] ),
"Open Orders",
SUMX (
FILTER (
GENERATE (
SUMMARIZE (
Sales,
Sales[OrderDate],
Sales[ShipDate],
"Rows", COUNTROWS ( Sales )
),
DATESBETWEEN (
'Calendar'[Date],
Sales[OrderDate] + 1, // 修正此处,原版是 Sales[OpenDate]
Sales[ShipDate] - 1 )
),
'Calendar'[Date] = EARLIER ( 'Calendar'[Date] )
),
[Rows]
)
)
运行效率
以连续5次冷启动的结果进行统计,将各方案的情况列写在表格里,数字下方括号里记录的是相对前一个方案的性能变化情况。
优化方案3的表现非常亮眼,计算效率超过了之前全部的方案,总耗时已经接近个位数!
| 环境 | 参数 | 初始方案 | 优化方案1 | 优化方案2 | 优化方案(番外) | 优化方案3 |
|---|---|---|---|---|---|---|
| 环境1 | 平均总耗时(毫秒) | 4389.4 | 290.4 (↑ 93.38%) | 79.6 (↑ 72.59%) | 56.8 (↑ 28.64%) | |
| SE耗时 (毫秒) | 14.4 | 4.8 | 13.6 | 4.8 | ||
| SE占比 | 0.328% | 1.653% (↑ 403.83%) | 17.09% (↑ 933.67%) | 8.45% (↓50.54%) | ||
| 环境2 | 平均总耗时(毫秒) | 4017.0 | 300.60 (↑ 92.52%) | 76.4 (↑ 74.58%) | 53.8 (↑ 29.58%) | 12.8 (↑ 83.25%) |
| SE耗时 (毫秒) | 17.2 | 5.8 (↑ 66.28%) | 18.2 | 5 | 3.4 | |
| SE占比 | 0.428% | 1.929% (↑ 350.62%) | 23.82% (↑ 1134.64%) | 9.29% (↓ 60.99%) | 26.56% (↑ 11.50%) |
白皮书中没有对此方案进行任何分析,留给读者实践,下面是我对该方案进行分析的详细记录。
存储引擎部分
依然首先查看存储引擎执行了哪些 xmSQL 查询
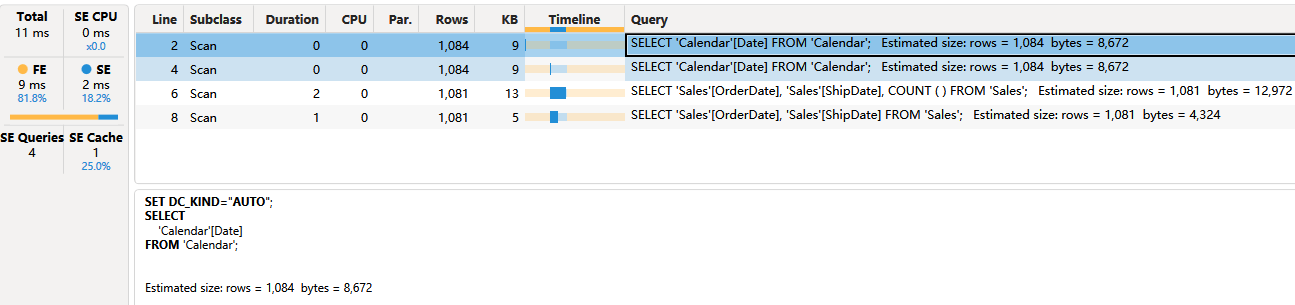
左侧窗口记录 SE Cache 为 1,表明有一个 xmSQL 被复用。右侧窗口记录了 4 行 Scan,其中 Line2 和 Line 4 是完全相同的,Line4 复用了 Line2 。
存储引擎一共执行 3 个 xmSQL:
1、VQ1
Line2 和 Line4,从 Calendar 表中获取 [Date] 的不重复值,包含 1 列,共 1081 行
‘Calendar’[Date]
// xmSQL VQ1
SELECT
'Calendar'[Date]
FROM 'Calendar';
2、VQ2
Line6,对 Sales 表以 Sales[OrderDate]、Sales[ShipDate] 分组并计算行数,包含 2 个数据列和 1 个值列,共 1081 行
Sales[OrderDate], Sales[ShipDate], COUNT
// xmSQL VQ2
SELECT
'Sales'[OrderDate],
'Sales'[ShipDate],
COUNT ( )
FROM 'Sales';
部分结果类似
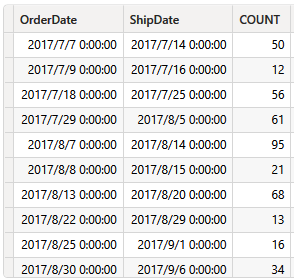
3、VQ3
Line8,对 Sales 表以 Sales[OrderDate]、Sales[ShipDate] 分组,即获取 Sales 表中{Sales[OrderDate], Sales[ShipDate]} 的不重复值对,共 1081 行
Sales[OrderDate], Sales[ShipDate]
// xmSQL VQ3
SELECT
'Sales'[OrderDate],
'Sales'[ShipDate]
FROM 'Sales';
部分结果为:

存储引擎部分 3 个 xmSQL 查询都没有出现 [RowNumber]。
公式引擎部分
逻辑查询计划
AddColumns: RelLogOp DependOnCols()() 0-1 RequiredCols(0, 1)('Calendar'[Date], ''[Open Orders])
├── Scan_Vertipaq: RelLogOp DependOnCols()() 0-0 RequiredCols(0)('Calendar'[Date])
└── SumX: ScaLogOp DependOnCols(0)('Calendar'[Date]) Integer DominantValue=BLANK
├── Filter: RelLogOp DependOnCols(0)('Calendar'[Date]) 1-4 RequiredCols(0, 1, 2, 3, 4)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate], ''[Rows], 'Calendar'[Date])
│ ├── CrossApply: RelLogOp DependOnCols()() 1-4 RequiredCols(1, 2, 3, 4)('Sales'[OrderDate], 'Sales'[ShipDate], ''[Rows], 'Calendar'[Date])
│ │ ├── AddColumns: RelLogOp DependOnCols()() 1-3 RequiredCols(1, 2, 3)('Sales'[OrderDate], 'Sales'[ShipDate], ''[Rows])
│ │ │ ├── GroupBy_Vertipaq: RelLogOp DependOnCols()() 1-15 RequiredCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate])
│ │ │ │ └── Scan_Vertipaq: RelLogOp DependOnCols()() 1-15 RequiredCols(6, 7)('Sales'[OrderDate], 'Sales'[ShipDate])
│ │ │ └── Count_Vertipaq: ScaLogOp DependOnCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) Integer DominantValue=BLANK
│ │ │ └── Scan_Vertipaq: RelLogOp DependOnCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) 16-30 RequiredCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate])
│ │ └── DatesBetween: RelLogOp DependOnCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) 4-4 RequiredCols(1, 2, 4)('Sales'[OrderDate], 'Sales'[ShipDate], 'Calendar'[Date])
│ │ ├── Add: ScaLogOp DependOnCols(1)('Sales'[OrderDate]) DateTime DominantValue=NONE
│ │ │ ├── 'Sales'[OrderDate]: ScaLogOp DependOnCols(1)('Sales'[OrderDate]) DateTime DominantValue=NONE
│ │ │ └── Constant: ScaLogOp DependOnCols()() Integer DominantValue=1
│ │ └── Subtract: ScaLogOp DependOnCols(2)('Sales'[ShipDate]) DateTime DominantValue=NONE
│ │ ├── 'Sales'[ShipDate]: ScaLogOp DependOnCols(2)('Sales'[ShipDate]) DateTime DominantValue=NONE
│ │ └── Constant: ScaLogOp DependOnCols()() Integer DominantValue=1
│ └── EqualTo: ScaLogOp DependOnCols(0, 4)('Calendar'[Date], 'Calendar'[Date]) Boolean DominantValue=false
│ ├── 'Calendar'[Date]: ScaLogOp DependOnCols(4)('Calendar'[Date]) DateTime DominantValue=NONE
│ └── 'Calendar'[Date]: ScaLogOp DependOnCols(0)('Calendar'[Date]) DateTime DominantValue=NONE
└── ''[Rows]: ScaLogOp DependOnCols(3)(''[Rows]) Integer DominantValue=NONE
代码中每一行的 DependOnCols 表示该操作依赖哪些列,RequiredCols 表示生成哪些列,根据这些信息在每个块上添加更多内容。上一篇讲了同一列可以有多个来源,这次直接在各列后面用数字标明。
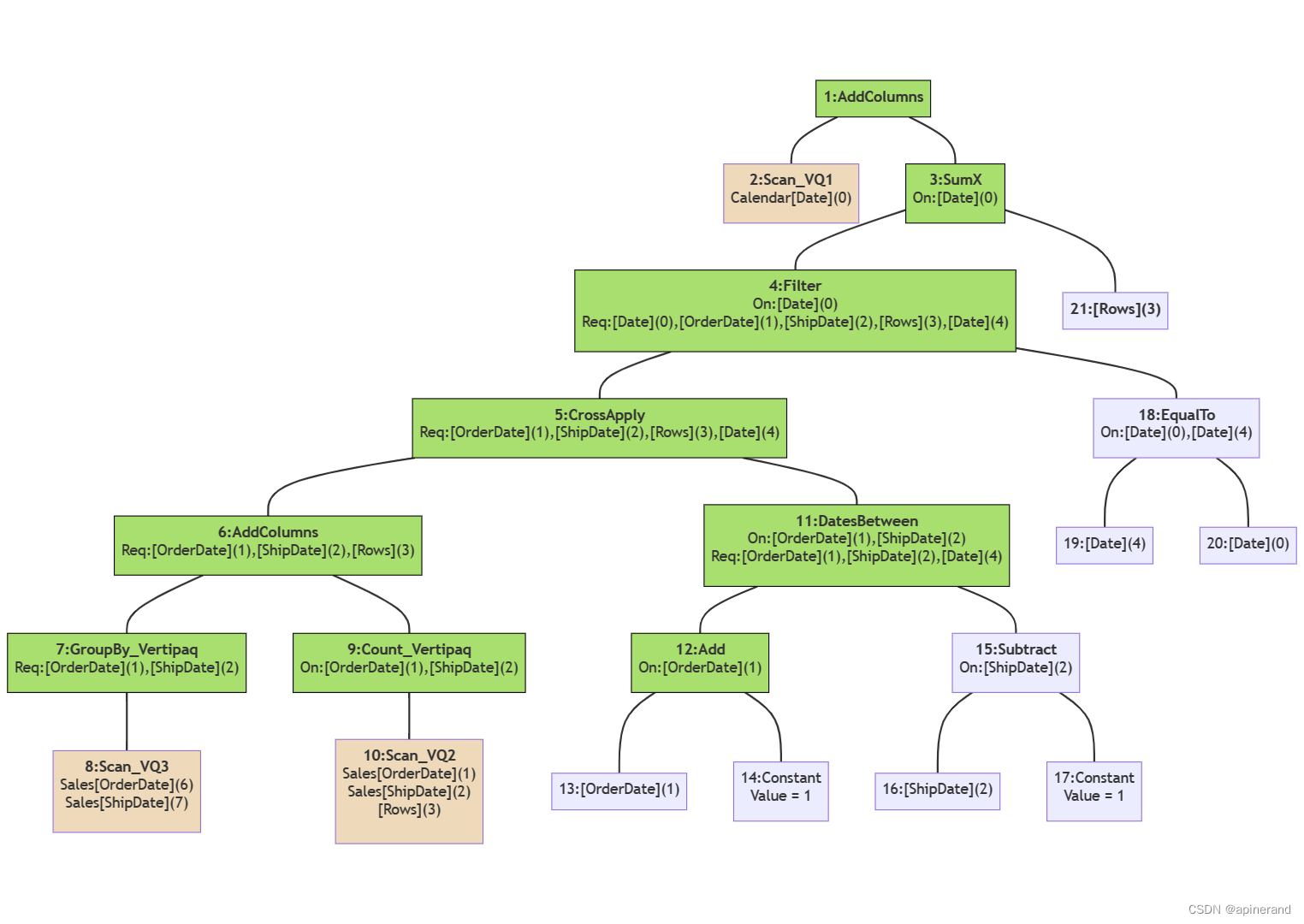
逻辑查询计划基本与 DAX 查询代码保持了相同的结构和计算顺序。
物理查询计划

AddColumns: IterPhyOp LogOp=AddColumns IterCols(0, 1)('Calendar'[Date], ''[Open Orders])
├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=20 #ValueCols=0
│ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
└── SpoolLookup: LookupPhyOp LogOp=SumX LookupCols(0)('Calendar'[Date]) Integer #Records=1079 #KeyCols=1 #ValueCols=1 DominantValue=BLANK
└── AggregationSpool<Sum>: SpoolPhyOp #Records=1079
└── Extend_Lookup: IterPhyOp LogOp=Extend_Lookup''[Rows] IterCols(3)(''[Rows])
├── Filter: IterPhyOp LogOp=Filter IterCols(0, 1, 2, 3, 4)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate], ''[Rows], 'Calendar'[Date])
│ └── CrossApply: IterPhyOp LogOp=EqualTo IterCols(0, 4)('Calendar'[Date], 'Calendar'[Date])
│ ├── ApplyRemap: IterPhyOp LogOp=CrossApply LookupCols(4)('Calendar'[Date]) IterCols(1, 2, 3)('Sales'[OrderDate], 'Sales'[ShipDate], ''[Rows])
│ │ └── Spool_MultiValuedHashLookup: IterPhyOp LogOp=CrossApply LookupCols(4)('Calendar'[Date]) IterCols(1, 2, 3)('Sales'[OrderDate], 'Sales'[ShipDate], ''[Rows]) #Records=6444 #KeyCols=4 #ValueCols=0
│ │ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=6444
│ │ └── CrossApply: IterPhyOp LogOp=CrossApply IterCols(1, 2, 3, 4)('Sales'[OrderDate], 'Sales'[ShipDate], ''[Rows], 'Calendar'[Date])
│ │ ├── AddColumns: IterPhyOp LogOp=AddColumns LookupCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) IterCols(3)(''[Rows])
│ │ │ ├── Spool_UniqueHashLookup: IterPhyOp LogOp=GroupBy_Vertipaq LookupCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) #Records=1081 #KeyCols=20 #ValueCols=0
│ │ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ │ │ └── Cache: IterPhyOp #FieldCols=2 #ValueCols=0
│ │ │ └── SpoolLookup: LookupPhyOp LogOp=Count_Vertipaq LookupCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) Integer #Records=1081 #KeyCols=20 #ValueCols=1 DominantValue=BLANK
│ │ │ └── ProjectionSpool<ProjectFusion<Copy>>: SpoolPhyOp #Records=1081
│ │ │ └── Cache: IterPhyOp #FieldCols=2 #ValueCols=1
│ │ └── DatesBetween: IterPhyOp LogOp=DatesBetween IterCols(1, 2, 4)('Sales'[OrderDate], 'Sales'[ShipDate], 'Calendar'[Date])
│ │ ├── Extend_Lookup: IterPhyOp LogOp=Add IterCols(1)('Sales'[OrderDate])
│ │ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=AddColumns IterCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) #Records=1081 #KeyCols=2 #ValueCols=0
│ │ │ │ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=1081
│ │ │ │ └── AddColumns: IterPhyOp LogOp=AddColumns IterCols(1, 2, 3)('Sales'[OrderDate], 'Sales'[ShipDate], ''[Rows])
│ │ │ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=GroupBy_Vertipaq IterCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) #Records=1081 #KeyCols=20 #ValueCols=0
│ │ │ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ │ │ │ └── Cache: IterPhyOp #FieldCols=2 #ValueCols=0
│ │ │ │ └── SpoolLookup: LookupPhyOp LogOp=Count_Vertipaq LookupCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) Integer #Records=1081 #KeyCols=20 #ValueCols=1 DominantValue=BLANK
│ │ │ │ └── ProjectionSpool<ProjectFusion<Copy>>: SpoolPhyOp #Records=1081
│ │ │ │ └── Cache: IterPhyOp #FieldCols=2 #ValueCols=1
│ │ │ └── Add: LookupPhyOp LogOp=Add LookupCols(1)('Sales'[OrderDate]) DateTime
│ │ │ ├── ColValue<'Sales'[OrderDate]>: LookupPhyOp LogOp=ColValue<'Sales'[OrderDate]>'Sales'[OrderDate] LookupCols(1)('Sales'[OrderDate]) DateTime
│ │ │ └── Constant: LookupPhyOp LogOp=Constant Integer 1
│ │ └── Subtract: LookupPhyOp LogOp=Subtract LookupCols(2)('Sales'[ShipDate]) DateTime
│ │ ├── ColValue<'Sales'[ShipDate]>: LookupPhyOp LogOp=ColValue<'Sales'[ShipDate]>'Sales'[ShipDate] LookupCols(2)('Sales'[ShipDate]) DateTime
│ │ └── Constant: LookupPhyOp LogOp=Constant Integer 1
│ └── InnerHashJoin: IterPhyOp LogOp=EqualTo IterCols(0, 4)('Calendar'[Date], 'Calendar'[Date])
│ ├── Extend_Lookup: IterPhyOp LogOp=Extend_Lookup'Calendar'[Date] IterCols(0)('Calendar'[Date])
│ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=20 #ValueCols=0
│ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ │ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ │ └── ColValue<'Calendar'[Date]>: LookupPhyOp LogOp=ColValue<'Calendar'[Date]>'Calendar'[Date] LookupCols(0)('Calendar'[Date]) DateTime
│ └── HashLookup: IterPhyOp LogOp=HashLookup'Calendar'[Date] IterCols(4)('Calendar'[Date]) #Recs=1079
│ └── HashByValue: SpoolPhyOp #Records=1079
│ └── Extend_Lookup: IterPhyOp LogOp=Extend_Lookup'Calendar'[Date] IterCols(4)('Calendar'[Date])
│ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=CrossApply IterCols(4)('Calendar'[Date]) #Records=1079 #KeyCols=1 #ValueCols=0
│ │ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=1079
│ │ └── ApplyRemap: IterPhyOp LogOp=CrossApply IterCols(1, 2, 3, 4)('Sales'[OrderDate], 'Sales'[ShipDate], ''[Rows], 'Calendar'[Date])
│ │ └── CrossApply: IterPhyOp LogOp=CrossApply IterCols(1, 2, 3, 4)('Sales'[OrderDate], 'Sales'[ShipDate], ''[Rows], 'Calendar'[Date])
│ │ ├── AddColumns: IterPhyOp LogOp=AddColumns LookupCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) IterCols(3)(''[Rows])
│ │ │ ├── Spool_UniqueHashLookup: IterPhyOp LogOp=GroupBy_Vertipaq LookupCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) #Records=1081 #KeyCols=20 #ValueCols=0
│ │ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ │ │ └── Cache: IterPhyOp #FieldCols=2 #ValueCols=0
│ │ │ └── SpoolLookup: LookupPhyOp LogOp=Count_Vertipaq LookupCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) Integer #Records=1081 #KeyCols=20 #ValueCols=1 DominantValue=BLANK
│ │ │ └── ProjectionSpool<ProjectFusion<Copy>>: SpoolPhyOp #Records=1081
│ │ │ └── Cache: IterPhyOp #FieldCols=2 #ValueCols=1
│ │ └── DatesBetween: IterPhyOp LogOp=DatesBetween IterCols(1, 2, 4)('Sales'[OrderDate], 'Sales'[ShipDate], 'Calendar'[Date])
│ │ ├── Extend_Lookup: IterPhyOp LogOp=Add IterCols(1)('Sales'[OrderDate])
│ │ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=AddColumns IterCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) #Records=1081 #KeyCols=2 #ValueCols=0
│ │ │ │ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=1081
│ │ │ │ └── AddColumns: IterPhyOp LogOp=AddColumns IterCols(1, 2, 3)('Sales'[OrderDate], 'Sales'[ShipDate], ''[Rows])
│ │ │ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=GroupBy_Vertipaq IterCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) #Records=1081 #KeyCols=20 #ValueCols=0
│ │ │ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ │ │ │ └── Cache: IterPhyOp #FieldCols=2 #ValueCols=0
│ │ │ │ └── SpoolLookup: LookupPhyOp LogOp=Count_Vertipaq LookupCols(1, 2)('Sales'[OrderDate], 'Sales'[ShipDate]) Integer #Records=1081 #KeyCols=20 #ValueCols=1 DominantValue=BLANK
│ │ │ │ └── ProjectionSpool<ProjectFusion<Copy>>: SpoolPhyOp #Records=1081
│ │ │ │ └── Cache: IterPhyOp #FieldCols=2 #ValueCols=1
│ │ │ └── Add: LookupPhyOp LogOp=Add LookupCols(1)('Sales'[OrderDate]) DateTime
│ │ │ ├── ColValue<'Sales'[OrderDate]>: LookupPhyOp LogOp=ColValue<'Sales'[OrderDate]>'Sales'[OrderDate] LookupCols(1)('Sales'[OrderDate]) DateTime
│ │ │ └── Constant: LookupPhyOp LogOp=Constant Integer 1
│ │ └── Subtract: LookupPhyOp LogOp=Subtract LookupCols(2)('Sales'[ShipDate]) DateTime
│ │ ├── ColValue<'Sales'[ShipDate]>: LookupPhyOp LogOp=ColValue<'Sales'[ShipDate]>'Sales'[ShipDate] LookupCols(2)('Sales'[ShipDate]) DateTime
│ │ └── Constant: LookupPhyOp LogOp=Constant Integer 1
│ └── ColValue<'Calendar'[Date]>: LookupPhyOp LogOp=ColValue<'Calendar'[Date]>'Calendar'[Date] LookupCols(4)('Calendar'[Date]) DateTime
└── ColValue<''[Rows]>: LookupPhyOp LogOp=ColValue<''[Rows]>''[Rows] LookupCols(3)(''[Rows]) Integer
这次的物理查询计划流程结构图如下:
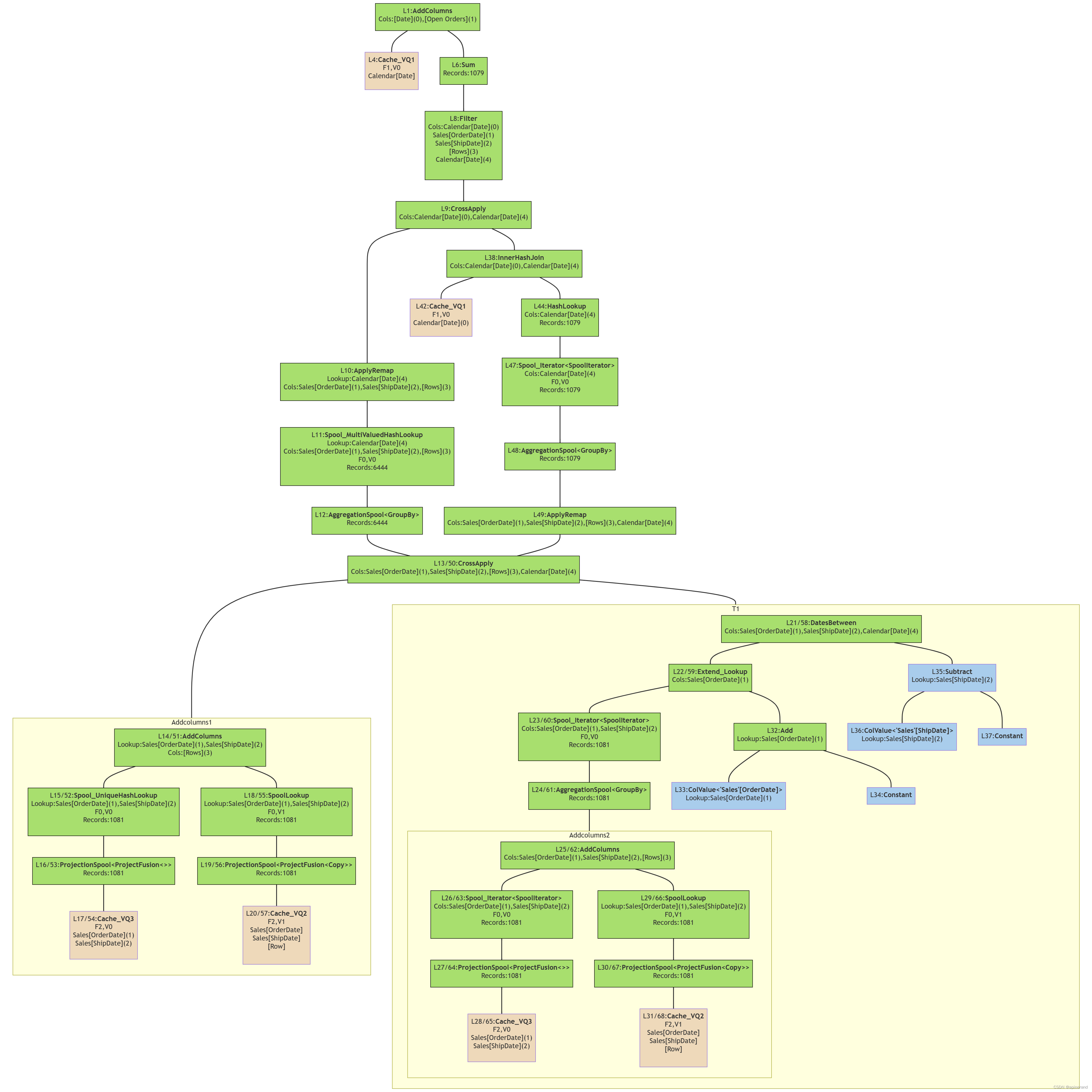
底层计算过程
本系列的重点在于 “理解DAX 在底层是怎么算的”,而不是“怎么通过阅读物理查询计划了解 DAX 底层计算过程”,在上一篇尝试了用模拟小数据表来演示每一步的计算过程,比干巴巴解释物理查询计划的代码更形象,这一篇就不逐一去解释代码了。
根据对物理查询计划的理解梳理底层计算过程,用一个小数据表做模拟。
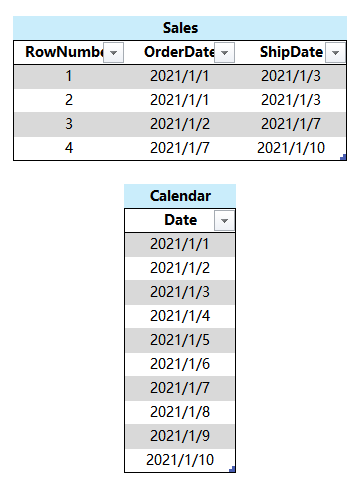
1、
将 Sales 表按 Sales[OrderDate]、Sales[ShipDate] 分组,并计算出每个{[OrderDate], [ShipDate]}组合包含的数据行数量
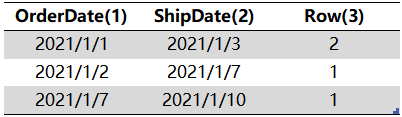
2、
将 Sales 表中按 Sales[OrderDate]、Sales[ShipDate] 分组,按照每一个 {[OrderDate], [ShipDate]} 值对,从 Calendar[Date] 筛选出 [OrderDate] +1 < [Date] < [ShipDate] -1 的数据,与对应的 {[OrderDate], [ShipDate]} 交叉成表
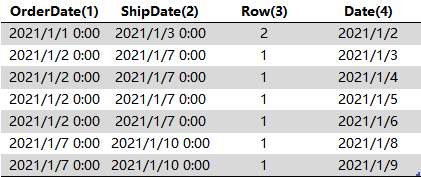
3、
将 2# 的结果表与Calendar[Date](0)以 [Date] 进行匹配查询合并,得到
这一步的目的是在切换 [Date](4)到 [Date](0),上一篇已经详细讲过这种情况
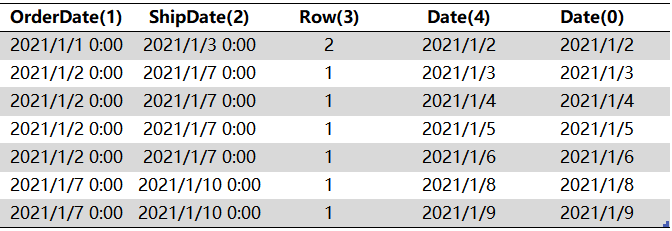
4、
3# 以 [Date](0)分组,将每组内的 [Row] 累加
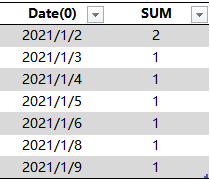
5、
以 Calendar[Date](0)为基准,从 4# 中查询对应的 [SUM] 作为 [Open Orders] 列,得到最终结果
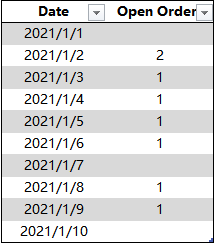
各步骤与物理查询结构流程图的对应关系可下载文件查看
性能分析
优化方案3取得如此明显的性能优化,它与优化方案2一样,没有出现优化方案1中由 FILTER 产生的任何交叉表,而比优化方案2更优秀的是,这一次甚至没有出现 [RowNumber],全程所有步骤都没有生成超过万级的数据表,全在处理千级数据。

优化方案3的思路,来自优化方案2的物理查询计划,实际就是把优化方案2的底层计算过程用 DAX 写了一遍。在上一篇中特意做了每个步骤的模拟计算,就是为了这里做铺垫,如果仔细阅读并理解了优化方案2的底层计算过程,应该还记得它主要用了这样几个步骤:
1、对于 Sales 表的每一行,从 Calendar 表中找出 [OrderDate]、[ShipDate] 之间的 [Date] 并与 Sales 表合并
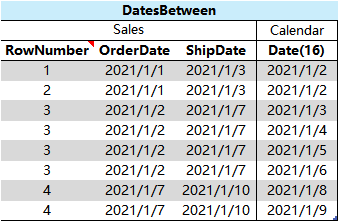
2、从 1# 的结果中,按 [OrderDate]、[ShipDate] 分组,并更换 Date(16)到 Date(0)
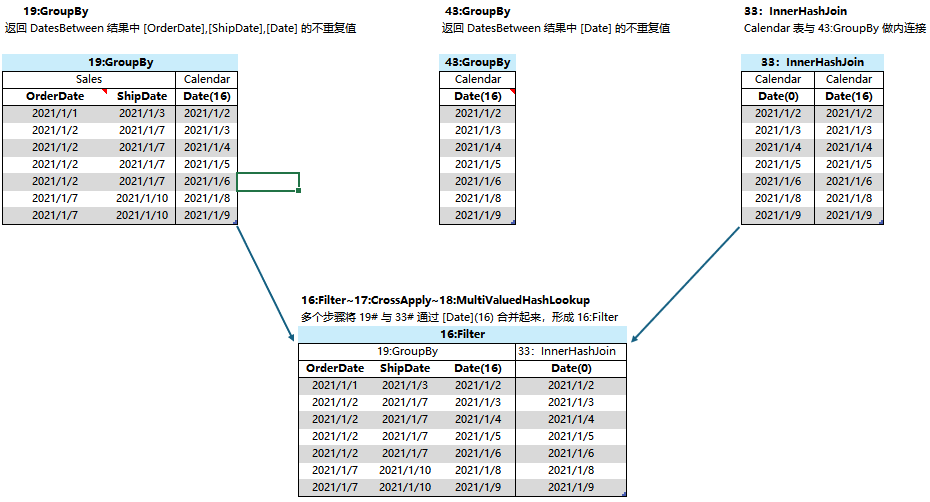
3、将 2# 与 Sales表以 [OrderDate]、[ShipDate] 进行匹配查询,目的是获取各个{[OrderDate],[ShipDate]}值对包含的全部 [RowNumber],因为最后的 COUNTROWS需要使用 [RowNumber] 来对行进行计数。
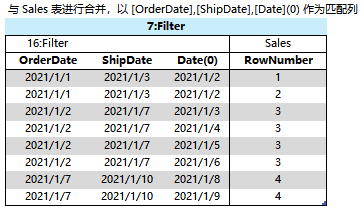
这一个结果看着与 1# 很相似,区别在 1# 的结果表中是 Date(16),现在是 Date[0],在上一篇已经讲过 DAX 底需要这样做的原因了。
4、最后从以 Calendar[Date](0)为基准,从 3# 中根据 Date(0)分组并对 [RowNumber] 进行记数,得到每个 Calendar[Date] 有多少行 [RowNumber]
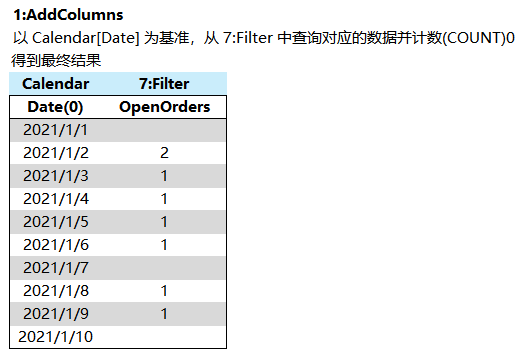
在 DAX 代码层面,优化方案3采取了以下改进:
- 不使用 Sales 整表,而用
SUMMARIZE(Sales,Sales[OrderDate],Sales[ShipDate])取得分组数据,减少数据量 - 按照优化方案2底层创建 Sales 与 Calendar 合并表的情况,主动以 Sales 的分组表与 Calendar 创建合并表
- 在给 Sales 分组时便计算出各个分组的数据量,最后该用 SUM 替代 优化方案2中的 COUNTROWS(Sales) ,避免出现 [RowNumber]

最后的总结
本系列参照《白皮书》的结构,分析了若干个 DAX 查询代码的物理查询计划,梳理其底层计算过程,逐个分析性能瓶颈,熟悉了 DAX 性能优化的一般步骤和一些优化思路,了解了可能影响计算性能的因素,比如中间步骤产生的大数据量,交叉表的存在,[RowNumber] 的影响等。DAX 性能优化并不是一件简单的事,阅读物理查询计划、绘制流程结构图、进行精简、梳理底层计算步骤确实需要耗费许多精力,而且官方对这一块的支持力度不是很大,并没有提供很多关于查询计划操作符的详细解释,笔者也是连蒙带猜地结合实验进行了一些探索,难免会出现错误的理解,希望对 DAX 性能优化感兴趣、愿意了解物理查询计划或者正在研究这个领域的朋友,能够一起交流探讨。















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









