







上一篇给出的优化方案中使用了两个 FILTER 函数,如果将两个 FILTER 函数合并成一个,可以使计算性能进一步提升,但是白皮书中并没有记录该方案。为了查明原因,比较优劣,本篇先将白皮书的其他优化方案抛开,先研究一下这个番外优化方案的秘诀。
研究《DAX查询计划 白皮书》中的案例(一)初始方案
研究《DAX查询计划 白皮书》中的案例(二)优化方案1
研究《DAX查询计划 白皮书》中的案例(三)优化方案(番外)
研究《DAX查询计划 白皮书》中的案例(四)优化方案2
研究《DAX查询计划 白皮书》中的案例(四)优化方案3
优化方案(番外)
DAX 查询
相对上一篇的优化方案1,本篇只做了一点小小的改变,将两个 FILTER 的条件合并到一条 FILTER 里
// 优化方案(番外)
EVALUATE
ADDCOLUMNS (
VALUES ( 'Calendar'[Date] ),
"OpenOrders",
CALCULATE (
COUNTROWS ( Sales ),
FILTER (
sales,
sales[OrderDate] < 'Calendar'[Date]
&& sales[ShipDate] > 'Calendar'[Date]
)
)
)
运行效率
以连续5次冷启动的结果进行统计
- 环境1
平均总耗时 56.8 毫秒,标准差 3.27 毫秒
其中 SE(存储引擎)平均耗时 4.80 毫秒,标准差 0.84 毫秒
SE/总耗时 = 8.451%
- 环境2
平均总耗时 53.8 毫秒,标准差 3.56 毫秒
其中 SE(存储引擎)平均耗时 5.0 毫秒,标准差 1.0 毫秒
SE/总耗时 = %
把目前所有方案的运行效率依次做比较,记录如下,数字下方的括号是相对前一个方案的性能变化情况。
| 环境 | 参数 | 初始方案 | 优化方案1 | 优化方案(番外) |
|---|---|---|---|---|
| 环境1 | 平均总耗时(毫秒) | 4389.4 | 290.4 (↑ 93.38%) | 56.8 (↑ 80.44%) |
| SE耗时 (毫秒) | 14.4 | 4.8 (↑ 66.67%) | 4.8 (-) | |
| SE占比 | 0.328% | 1.653% (↑ 403.83%) | 8.45% (↑ 411.27%) | |
| 环境2 | 平均总耗时(毫秒) | 4017.0 | 300.60 (↑ 92.52%) | 53.8 (↑ 82.10%) |
| SE耗时 (毫秒) | 17.2 | 5.8 (↑ 66.28%) | 5.0 (↑ 13.79%) | |
| SE占比 | 0.428% | 1.929% (↑ 350.62%) | 9.29% (↑ 381.67%) |
优化方案(番外)的总耗时 56.8 毫秒,相对优化方案1的总耗时 290.4 毫秒,运行效率提升了 80.44%。
仅仅是将两个 FILTER 函数合并成了一个,就使得性能提升八成,这背后的原因是什么,下面进行分析。
存储引擎部分
存储引擎这次执行了 3 个 xmSQL 查询:
1、VQ1:将 Sales 表以 [OrderDate] 和 [ShipDate] 分组,返回 {[OrderDate], [ShipDate]} 值对,共 1081 个值对。后文以VQ1:[OrderDate], [ShipDate] 表示该结果
// xmSQL VQ1
SELECT
'Sales'[OrderDate],
'Sales'[ShipDate]
FROM 'Sales';
2、VQ2:与上一篇优化方案1 中的 VQ2 完全一致,将 Calendar 表中以 [Date] 分组,返回 Calendar[Date] 列的不重复值,共 1081 行数据。后文以 VQ2:Calendar[Date]表示该结果
// VQ2
SELECT
'Calendar'[Date]
FROM 'Calendar';
3、VQ3:与上一篇优化方案1 中的 VQ3 类似,也是从 Sales 中筛选符合条件的行,以 Sales[OrderDate]、Sales[ShipDate] 分组,并计算每一组的行数。结果包含 3 列 Sales[OrderDate]、Sales[ShipDate]、[COUNT],共 1074 行数据。后文以 VQ3:Sales[OrderDate],Sales[ShipDate],[COUNT]表示该结果
SELECT
'Sales'[OrderDate],
'Sales'[ShipDate],
COUNT ( )
FROM 'Sales'
WHERE
( 'Sales'[OrderDate], 'Sales'[ShipDate] ) IN { ( 43341.000000, 43348.000000 ) , ( 43494.000000, 43501.000000 ) , ( 43416.000000, 43423.000000 ) , ( 43646.000000, 43653.000000 ) , ( 43721.000000, 43728.000000 ) , ( 43570.000000, 43577.000000 ) , ( 43007.000000, 43014.000000 ) , ( 43150.000000, 43157.000000 ) , ( 43656.000000, 43663.000000 ) , ( 43264.000000, 43271.000000 ) ..[1,074 total tuples, not all displayed]};
WHERE 子句有变化,这次限定的是 (Sales[OrderDate], Sales[ShipDate]) 值对的取值范围,注意是值对。
( ‘Sales’[OrderDate], ‘Sales’[ShipDate] ) IN { ( 43341.000000, 43348.000000 ) , ( 43494.000000, 43501.000000 ) , ( 43416.000000, 43423.000000 ) , ( 43646.000000, 43653.000000 ) , ( 43721.000000, 43728.000000 ) , ( 43570.000000, 43577.000000 ) , ( 43007.000000, 43014.000000 ) , ( 43150.000000, 43157.000000 ) , ( 43656.000000, 43663.000000 ) , ( 43264.000000, 43271.000000 ) …[1,074 total tuples, not all displayed]}
WHERE 子句现在是 (Sales[Order], Sales[ShipDate]) IN {( ), ( ),...}的结构,最后中括号中用的词是 tuples(元组)。 tuples 指的是由多个数据构成的一个集合,比如 (1, 2, 3) 可以算作一个 tuple。
该 xmSQL 查询的结果可以借用这段 DAX 查询来理解:
// DAX
DEFINE
VAR tuples = TREATAS(
{(),()...},
Sales[OrderDate], Sales[ShipDate]
)
EVALUATE
CALCULATETABLE (
ADDCOLUMNS (
SUMMARIZE ( Sales, Sales[OrderDate], sales[ShipDate] ),
"COUNT", CALCULATE ( COUNTROWS ( Sales ) )
),
tuples
)
而上一篇中此部分的内容是 Sales[Order] IN {...} VAND Sales[ShipDate] IN {...},最后中括号中用的词是 values
‘Sales’[OrderDate] IN ( 43768.000000, 43809.000000, 43850.000000, 43893.000000, 43934.000000, 43975.000000, 43014.000000, 43426.000000, 43468.000000, 43513.000000…[1,080 total values, not all displayed] ) VAND
‘Sales’[ShipDate] IN ( 43775.000000, 43816.000000, 43857.000000, 43900.000000, 43941.000000, 43982.000000, 43028.000000, 43433.000000, 43475.000000, 43520.000000…[1,074 total values, not all displayed] )
上一篇已经分析过这种 WHERE 子句的值列表由公式引擎提供,稍后会再次通过物理查询计划得到印证。
公式引擎部分
逻辑查询计划
已经第三篇了,这里就不再说重复的话了
AddColumns: RelLogOp DependOnCols()() 0-1 RequiredCols(0, 1)('Calendar'[Date], ''[OpenOrders])
├── Scan_Vertipaq: RelLogOp DependOnCols()() 0-0 RequiredCols(0)('Calendar'[Date])
└── Calculate: ScaLogOp DependOnCols(0)('Calendar'[Date]) Integer DominantValue=BLANK
├── Count_Vertipaq: ScaLogOp DependOnCols(0)('Calendar'[Date]) Integer DominantValue=BLANK
│ └── Scan_Vertipaq: RelLogOp DependOnCols(0)('Calendar'[Date]) 16-30 RequiredCols(0)('Calendar'[Date])
└── Filter: RelLogOp DependOnCols(0)('Calendar'[Date]) 1-15 RequiredCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate])
├── Filter: RelLogOp DependOnCols(0)('Calendar'[Date]) 1-15 RequiredCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate])
│ ├── Scan_Vertipaq: RelLogOp DependOnCols()() 1-15 RequiredCols(6, 7)('Sales'[OrderDate], 'Sales'[ShipDate])
│ └── LessThan: ScaLogOp DependOnCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate]) Boolean DominantValue=NONE
│ ├── 'Sales'[OrderDate]: ScaLogOp DependOnCols(6)('Sales'[OrderDate]) DateTime DominantValue=NONE
│ └── 'Calendar'[Date]: ScaLogOp DependOnCols(0)('Calendar'[Date]) DateTime DominantValue=NONE
└── GreaterThan: ScaLogOp DependOnCols(0, 7)('Calendar'[Date], 'Sales'[ShipDate]) Boolean DominantValue=NONE
├── 'Sales'[ShipDate]: ScaLogOp DependOnCols(7)('Sales'[ShipDate]) DateTime DominantValue=NONE
└── 'Calendar'[Date]: ScaLogOp DependOnCols(0)('Calendar'[Date]) DateTime DominantValue=NONE
说一下与上一篇的区别,这次逻辑查询计划里两个 FILTER 嵌套了,上一篇是并列的,不过具体的区别还得看物理查询计划。
物理查询计划
先截图

去掉 Line 和 Records ,画上层次结构线
AddColumns: IterPhyOp LogOp=AddColumns IterCols(0, 1)('Calendar'[Date], ''[OpenOrders])
├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=26 #ValueCols=0
│ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
└── SpoolLookup: LookupPhyOp LogOp=Count_Vertipaq LookupCols(0)('Calendar'[Date]) Integer #Records=1079 #KeyCols=1 #ValueCols=1 DominantValue=BLANK
└── AggregationSpool<AggFusion<Sum>>: SpoolPhyOp #Records=1079
└── CrossApply: IterPhyOp LogOp=Count_Vertipaq IterCols(0)('Calendar'[Date])
├── Spool_MultiValuedHashLookup: IterPhyOp LogOp=Filter LookupCols(6, 7)('Sales'[OrderDate], 'Sales'[ShipDate]) IterCols(0)('Calendar'[Date]) #Records=6444 #KeyCols=3 #ValueCols=0
│ └── AggregationSpool<GroupBy>: SpoolPhyOp #Records=6444
│ └── Filter: IterPhyOp LogOp=Filter IterCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate])
│ └── Extend_Lookup: IterPhyOp LogOp=GreaterThan IterCols(0, 7)('Calendar'[Date], 'Sales'[ShipDate])
│ ├── Filter: IterPhyOp LogOp=Filter IterCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate])
│ │ └── Extend_Lookup: IterPhyOp LogOp=LessThan IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ │ ├── CrossApply: IterPhyOp LogOp=LessThan IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ │ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=26 #ValueCols=0
│ │ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ │ │ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ │ │ └── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(6, 7)('Sales'[OrderDate], 'Sales'[ShipDate]) #Records=1081 #KeyCols=26 #ValueCols=0
│ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ │ └── Cache: IterPhyOp #FieldCols=2 #ValueCols=0
│ │ └── LessThan: LookupPhyOp LogOp=LessThan LookupCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate]) Boolean
│ │ ├── ColValue<'Sales'[OrderDate]>: LookupPhyOp LogOp=ColValue<'Sales'[OrderDate]>'Sales'[OrderDate] LookupCols(6)('Sales'[OrderDate]) DateTime
│ │ └── ColValue<'Calendar'[Date]>: LookupPhyOp LogOp=ColValue<'Calendar'[Date]>'Calendar'[Date] LookupCols(0)('Calendar'[Date]) DateTime
│ └── GreaterThan: LookupPhyOp LogOp=GreaterThan LookupCols(0, 7)('Calendar'[Date], 'Sales'[ShipDate]) Boolean
│ ├── ColValue<'Sales'[ShipDate]>: LookupPhyOp LogOp=ColValue<'Sales'[ShipDate]>'Sales'[ShipDate] LookupCols(7)('Sales'[ShipDate]) DateTime
│ └── ColValue<'Calendar'[Date]>: LookupPhyOp LogOp=ColValue<'Calendar'[Date]>'Calendar'[Date] LookupCols(0)('Calendar'[Date]) DateTime
└── Cache: IterPhyOp #FieldCols=2 #ValueCols=1
└── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Filter IterCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate]) #Records=6444 #KeyCols=3 #ValueCols=0
└── AggregationSpool<GroupBy>: SpoolPhyOp #Records=6444
└── Filter: IterPhyOp LogOp=Filter IterCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate])
└── Extend_Lookup: IterPhyOp LogOp=GreaterThan IterCols(0, 7)('Calendar'[Date], 'Sales'[ShipDate])
├── Filter: IterPhyOp LogOp=Filter IterCols(0, 6, 7)('Calendar'[Date], 'Sales'[OrderDate], 'Sales'[ShipDate])
│ └── Extend_Lookup: IterPhyOp LogOp=LessThan IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ ├── CrossApply: IterPhyOp LogOp=LessThan IterCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate])
│ │ ├── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(0)('Calendar'[Date]) #Records=1081 #KeyCols=26 #ValueCols=0
│ │ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ │ └── Cache: IterPhyOp #FieldCols=1 #ValueCols=0
│ │ └── Spool_Iterator<SpoolIterator>: IterPhyOp LogOp=Scan_Vertipaq IterCols(6, 7)('Sales'[OrderDate], 'Sales'[ShipDate]) #Records=1081 #KeyCols=26 #ValueCols=0
│ │ └── ProjectionSpool<ProjectFusion<>>: SpoolPhyOp #Records=1081
│ │ └── Cache: IterPhyOp #FieldCols=2 #ValueCols=0
│ └── LessThan: LookupPhyOp LogOp=LessThan LookupCols(0, 6)('Calendar'[Date], 'Sales'[OrderDate]) Boolean
│ ├── ColValue<'Sales'[OrderDate]>: LookupPhyOp LogOp=ColValue<'Sales'[OrderDate]>'Sales'[OrderDate] LookupCols(6)('Sales'[OrderDate]) DateTime
│ └── ColValue<'Calendar'[Date]>: LookupPhyOp LogOp=ColValue<'Calendar'[Date]>'Calendar'[Date] LookupCols(0)('Calendar'[Date]) DateTime
└── GreaterThan: LookupPhyOp LogOp=GreaterThan LookupCols(0, 7)('Calendar'[Date], 'Sales'[ShipDate]) Boolean
├── ColValue<'Sales'[ShipDate]>: LookupPhyOp LogOp=ColValue<'Sales'[ShipDate]>'Sales'[ShipDate] LookupCols(7)('Sales'[ShipDate]) DateTime
└── ColValue<'Calendar'[Date]>: LookupPhyOp LogOp=ColValue<'Calendar'[Date]>'Calendar'[Date] LookupCols(0)('Calendar'[Date]) DateTime
前两篇也是去掉了 Line 和 Records,其实 Records 还挺重要的,Records 记录的是该步骤物化了多少数据量,大概可以理解为这一步产生了多少数据量,不过有些步骤产生的数据量没有标记出来,需要使用者自行分析计算。
下面是结构流程图,我也学《白皮书》的作者故意省略了大量操作符,这样图画出来会小一点。
我特意省略了部分操作符,使两个 10:Filter 和 30:Filter 往下的操作符正好并列摆布,这样就能很明显地看出来,10:Filter 和 30:Filter 往下的操作符是完全相同的,所以,我要把这张图再精简一下。
在上一篇我们也这样干过,这么做主要是想说明物理查询计划里有些步骤是重复的,可以合并起来看,不用把每个分支都去分析一遍。
底层计算过程
一
从下往上,先看重复出现的那几个步骤是在做什么,把这部分命名为 T
1、14/34:CrossApply 对 17/37:Cache(VQ2)与 20/40:Cache(VQ1)求交叉表
将 VQ1:[OrderDate], [ShipDate] 与 VQ2:Calendar[Date] 求交叉表,得到的结果有 3 列 [OrderDate], [ShipDate], Calendar[Date],包含 Sales 表中全部 1081 个 {[OrderDate], [ShipDate]} 值对与 Calendar[Date] 全部 1081 个值的笛卡尔积,共 1081×1081 = 1168561 行
2、12/32:Filter 从 1# 的结果中筛选出Sales[OrderDate] < Calendar[Date]的数据,583740 行
3、10/30:Fitler 从 2# 的结果中筛选出 Sales[ShipDate] > Calendar[Date]的数据,6444 行
这部分执行的操作,是从 {[OrderDate], [ShipDate]} 值对与 Calendar[Date] 的交叉表中筛选出满足Sales[OrderDate] < 'Calendar'[Date] && Sales[ShipDate] > 'Calendar'[Date]的全部数据,其结果包含 Sales[OrderDate], Sales[ShipDate], Calendar[Date] 3列,后文用 T:[OrderDate], [ShipDate], Calendar[Date] 表示 T 的结果表
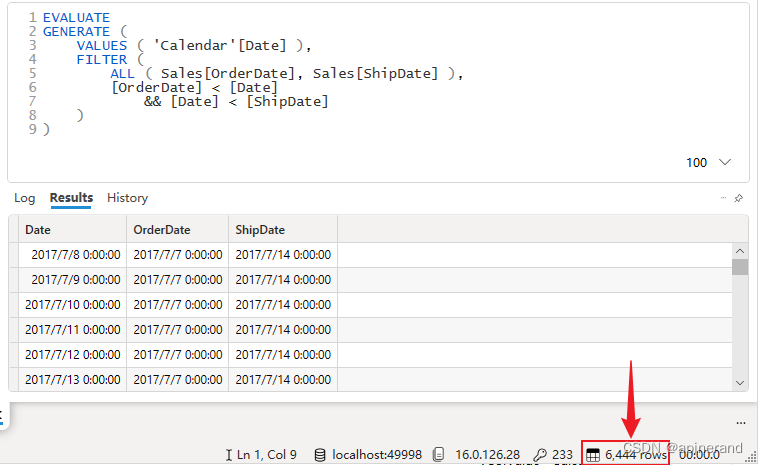
可以用以下 DAX 查询的结果来帮助理解(注意用这段查询的运行结果去理解T的结果,并不是说T执行了下面这段 DAX 查询代码)
//DAX
EVALUATE
GENERATE (
VALUES ( 'Calendar'[Date] ),
FILTER (
ALL ( sales[OrderDate], sales[ShipDate] ),
[orderdate] < [Date]
&& [Date] < [ShipDate]
)
)
其结果如下,右下角记录了该结果有 6444 行。
二
从 T 往上看
1、27:Cache(VQ3) 从 T 的结果中取出 {Sales[OrderDate], Sales[ShipDate]} 值对,正好 1074 个,这 1074 行数据构成了 VQ3 的 WHERE 子句中的 1074 个 tuples(组元),27:Cache(VQ3)从存储引擎读取 VQ3 的结果
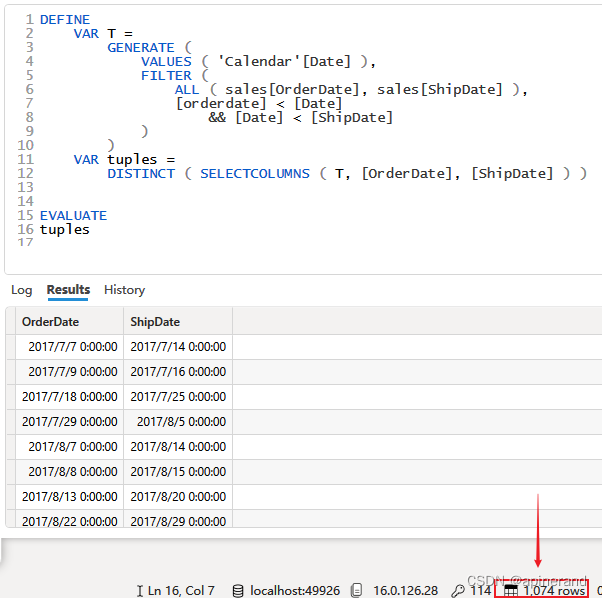
在存储引擎一节已经讲过 VQ3 的作用:
从 Sales 中筛选符合条件的行,以 Sales[OrderDate]、Sales[ShipDate] 分组,并计算每一组的行数
当时没有讲符合什么样的筛选条件,现在知道 WHERE 子句中的组元来自 T ,可以把 VQ3 的作用补全了:
从 Sales 中筛选出对于 Calendar 表中任意 [Date],都能满足 [OrderDate] < Calendar[Date] < [ShipDate] 的数据行,以 Sales[OrderDate]、Sales[ShipDate] 分组,并计算每一组的行数
2、7:CrossApply 以 8:Spool_MultiValuedHashLookup 作为参数,将 T:[OrderDate], [ShipDate], Calendar[Date] 与 VQ3:Sales[OrderDate],Sales[ShipDate],[COUNT] 以 Sales[OrderDate]、Sales[ShipDate] 为匹配列进行连接,类似 PowerQuery 中的合并查询,得到的新结果包含 [OrderDate], [ShipDate], Calendar[Date], [COUNT] 4 列。
这一步的作用,可以通过一段 PowerQuery 代码的结果来理解:
// Power Query
let
MultiValuedHashLookup =
Table.NestedJoin(
VQ3, {"OrderDate", "ShipDate"},
T, {"OrderDate", "ShipDate"},
"查询Date", JoinKind.LeftOuter
), // 查询合并
CrossApply =
Table.ExpandTableColumn(MultiValuedHashLookup, "查询Date", {"Date"}, {"Date"}) // 展开
in
CrossApply
三
接着往上
1、6:Sum 从 7:CrossApply的结果表中,以 Calendar[Date] 为分组,对 [Count] 进行累加,得到 Calendar[Date], [SUM]
2、4:Cache(VQ2) 从存储引擎获取 VQ2:Calendar[Date],
3、1:AddColumns 以此为基准,从 6:Sum 中查询对应 Calendar[Date] 的 [SUM] 值作为新加列 [OpenOrders] 的内容,得到最终的查询计算结果
性能提升原因分析
物理查询计划已经分析完了,相对于上一篇,优化方案(番外)性能更好的原因是什么?
先看底层原因,将两个方案的物理查询计划按相同的原则进行精简,然后放一起做比较,并在图上标出每个步骤产生的数据量。
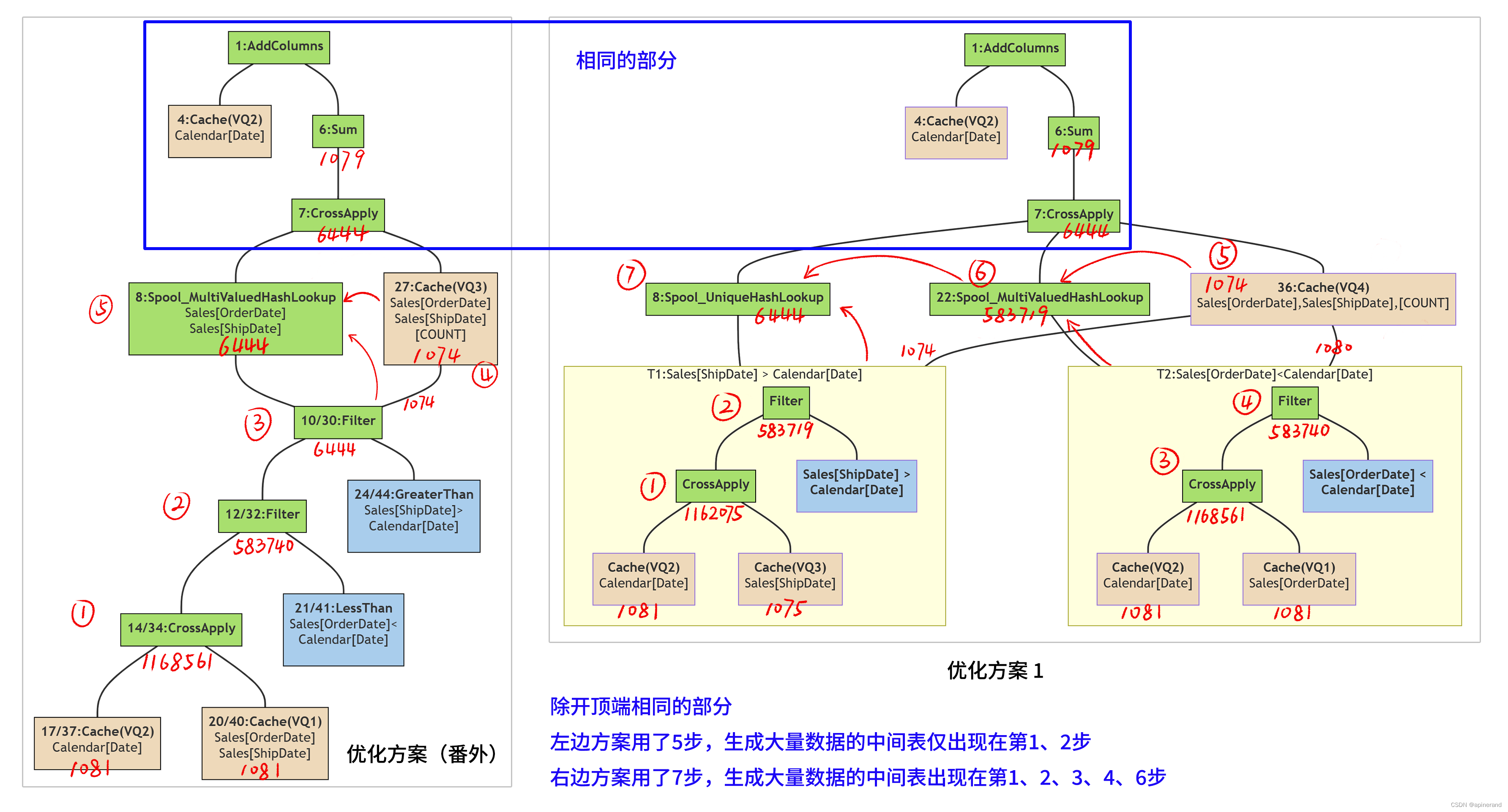
两个方案最顶端的步骤是一样的(用蓝框标记),不同的步骤体现在蓝框部分下方
左边的优化方案(番外)用了5步,产生大量中间数据的步骤只出现在第1、2步;
右边的优化方案1则用了7步,而且产生大量中间数据的步骤出现在了第1、2、3、4、6步。
优化方案(番外)使用了更少的步骤并很快地缩小了数据规模,因此计算效率更高。
这一优势来自于优化方案(番外)的 VQ1 使用了 Sales[OrderDate],Sales[ShipDate],将两个条件列合并在同一个 FILTER 操作中
// xmSQL VQ1
SELECT
'Sales'[OrderDate],
'Sales'[ShipDate]
FROM 'Sales';
再看代码层面,将之前两个分开的 FILTER 函数合并成一个是关键原因
// 运行较慢的方案
CALCULATE (
COUNTROWS ( Sales ),
FILTER ( sales, sales[OrderDate] < 'Calendar'[Date] ),
FILTER ( sales, sales[ShipDate] > 'Calendar'[Date] )
)
// 运行较快的方案
CALCULATE (
COUNTROWS ( Sales ),
FILTER (
sales,
sales[OrderDate] < 'Calendar'[Date]
&& sales[ShipDate] > 'Calendar'[Date]
)
)
总结
通过最近这三篇案例分析可以得出如下经验:
1、在迭代器中使用 FILTER 函数与行上下文中的值进行比较时,在底层会生成 交叉表+判断 操作
ADDCOLUMNS(
日期表,
"COUNT",
COUNTROWS(
FILTER(数据表, 数据表[OrderDate] < 日期表[Date])
)
)
相关数据列,通常只包含参与判断的列,不会出现数据表中其他无关的列;但某些情况下会出现 [RowNumber] 列。
2、在 1# 条件下,FILTER 的条件包含多个列时,在底层执行生成上下嵌套的 FILTER 操作
ADDCOLUMNS(
日期表,
"COUNT",
COUNTROWS(
FILTER(
数据表,
数据表[OrderDate] < 日期表[Date] &&
数据表[ShipDate] > 日期表[Date]
)
)
)
3、在 1# 条件下,如果使用类似 COUNTROWS(FILTER(...))的写法作为迭代计算,会在 xmSQL 查询中带入 [RowNumber] ,可能造成数据庞大的交叉表,如
ADDCOLUMNS(
日期表,
"COUNT",
COUNTROWS(
FILTER(数据表, 数据表[OrderDate] < 日期表[Date])
)
)
生成的 xmSQL 可能是这样的,其结果的基数等于数据表的基数
// xmSQL
SELECT
数据表[RowNumber], 数据表[OrderDate]
FORM
数据表
【相关数据列】将包括 [RowNumber] 和 数据表[OrderDate]
4、在 1# 条件下,使用 CALCULATE + FILTER 的写法,可以避免出现 3# 中说的 [RowNumber],不过也会出现需要公式引擎提供 WHERE 子句值列表的 xmSQL 查询
ADDCOLUMNS(
日期表,
"COUNT",
CALCULATE(
COUNTROWS(数据表),
FILTER(数据表, 数据表[OrderDate] < 日期表[Date])
)
)
// xmSQL
SELECT
'Sales'[OrderDate]
COUNT ( )
FROM 'Sales'
WHERE
'Sales'[OrderDate] IN ( 43768.000000, 43809.000000......)
5、在 4# 条件下,当在 CALCULATE 的参数中使用n个独立的 FILTER 语句,会在底层生成n个独立的 交叉表+判断 操作,增加交叉表的数量
ADDCOLUMNS(
日期表,
"COUNT",
CALCULATE(
COUNTROWS(数据表),
FILTER(数据表, 数据表[OrderDate] < 日期表[Date]),
FILTER(数据表, 数据表[ShipDate] > 日期表[Date])
)
)
6、在 5# 条件下,如果将多个 FILTER 合并成一个,可以恢复到 2# 的情况,并且不会出现 3# 的 [RowNumber]
ADDCOLUMNS(
日期表,
"COUNT",
CALCULATE(
COUNTROWS(数据表),
FILTER(
数据表,
数据表[OrderDate] < 日期表[Date] &&
数据表[ShipDate] > 日期表[Date])
)
)















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









