









第一章
1+1+1
并行程序的概念、FLOPs,单位转化
概念
高性能计算:
(High performance computing,缩写HPC) ,指通常使用很多处理器(作为单个机器的一部分)或者某一集群中组织的几台计算机(作为单个计算资源操作)的计算系统和环境,执行一般个人电脑无法处理的大量资料与高速运算,其基本组成组件与个人电脑的概念无太大差异,但规格与性能则强大许多。
计算机发展(必考):
- 电子管(1943) - 晶体管 - 集成电路 - 大规模集成电路 - 异构(1985)
- 从器件到体系结构变革
性能度量
HPL
-
HPL:是现代高性能计算机通用的基准测试程序,使用BLAS数学库和MPI通信来测试高性能计算机性能。
-
Linpack是用于测试高性能计算机系统浮点性能的基准测试程序。
- 通过对高性能计算机采用高斯消元法求解一元N次稠密线性
代数方程组的测试( A x = b Ax=b Ax=b),评价高性能计算的浮点性能。
- 通过对高性能计算机采用高斯消元法求解一元N次稠密线性
FLOPS(必考)
- 衡量性能:每秒浮点运算次数,Floating-point operations per
second (FLOPS或者Flop/s)- FLOPS 是floating point operations per second的缩写,意指每秒浮点运算次数,用来衡量硬件的性能(注意全部大写 )
- FLOPs 是floating point of operations的缩写,是浮点运算次数,
用来衡量算法/模型复杂度。(深度学习)
浮点运算包括所有涉及小数的运算,比整数运算更费时间。现今大部分处理器中都有浮点运算器。
因此每秒浮点运算次数所测量的实际上就是浮点运算器的执行速度。
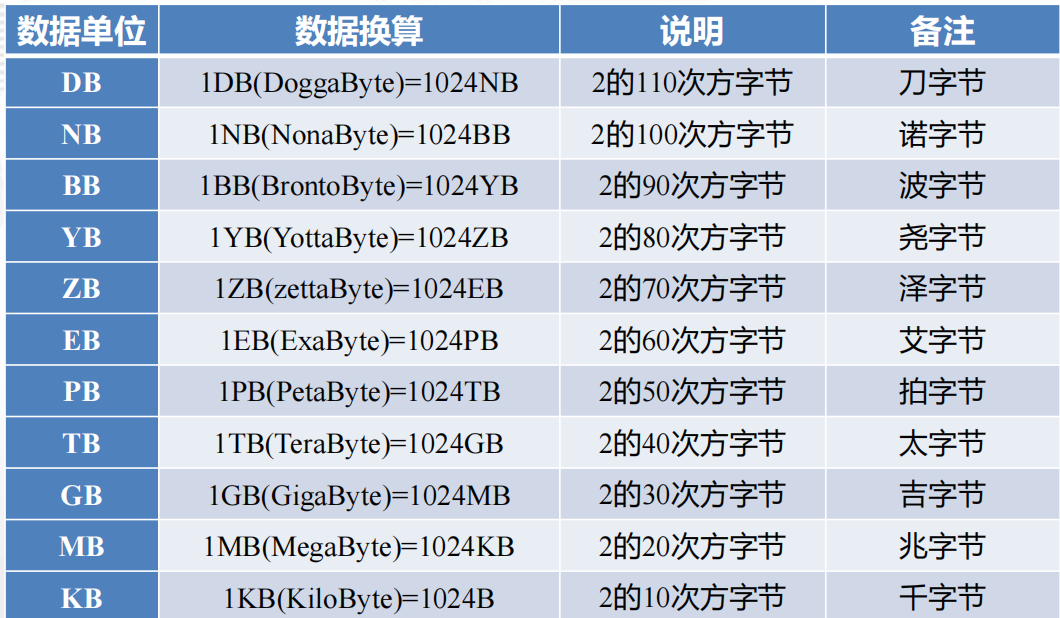
单位换算(必考)

HPCC
HPCC(High Performance Computing Challenge):
是面向高性能计算机的综合测试程序包,能够测试高性能计算机系统多个方面的性能,包括处理器速度、存储访问速度和网络通信速度,对各种应用都有一定的代表性和参考价值。(2015)
评价:HPL简单易操作,结果直接明了,但不够精细,HPL评测标准显得过于粗略。HPCC充分弥补了HPL的一些缺点,对性能跨度非常大的各个方面都进行了充分的测试,但也存在一些问题,那就是没有一个统一的结果评价标准,评价体系的构建不方便。
HPCG
HPCG(High Performance Conjugate Gradients)高性能共轭梯度基准测试,是现在主要测试超算性能程序之一,也是TOP500的一项重要指标。
- 一般来讲HPCG的测试结果会比HPL低很多,常常只有百分几。
评价指标:
- 计算峰值是指计算机每秒完成的浮点计算最大次数,它包
括理论浮点峰值和实测浮点峰值。 - 运算性能(实测浮点峰值,Rmax)是Linpack值,也就是一台机器上运行Linpack测试程序,通过各种优化方法得到的最优测试结果。
- 峰值性能(理论浮点峰值, Rpeak)是计算机在理论上能达到的每秒完成的浮点计算最大次数,它主要是由CPU的主频决定的。
应用
天河2A是由中国国防科技大学(NUDT)开发并部署在中国广州国家超级计算机中心,由Intel Xeon CPU和Matrix-2000加速器提供动力。
2016年6月,中国研发出了当世界上最快的超级计算机“神威太湖
之光”
,坐落在无锡的中国国家超级计算机中心。该超级计算机的浮
点运算速度是当时世界第二快超级计算机“天河二号” 的2倍,达9.3
亿亿次每秒。( 截止2017年11月排名第一)
并行程序
- 单处理器性能大幅度提升的主要原因之一,是日益增加的集成电路晶体管密度。
解决方案:
- 将多个核放在一个集成电路上,来取代设计更快的单核微处理器。
- 从单核系统转移到多核处理器。
- 多核处理器=中央处理单元(中央处理器,CPU)
历程:个人电脑 - 工作站 - 大型电脑 - 向量型超级计算机
集群:分布式集群的计算环境
- 并行程序:使用多个核(处理器)一起工作来解决单一问题
- 并发计算:一个程序的多个任务在同一个时间段内可以同时执行
- 并行计算:一个程序通过多个任务紧密协作来解决某一个问题
- 分布式计算:一个程序需要不其它程序协作来解决某个问题
- 通信:一个或多个核需要将自己的部分和发送给其他核
- 负载平衡:将任务量平均分配给各个核
- 同步:每个核都以自己的速度工作,核之间不会自己同步
- 在master核初始化完全部数据才能使数组能够被其他核访问之前,
其他核不能开始工作,否则容易造成错误。 - 因此,需要在初始化x数组和计算部分和之间加入一个同步
点:Synchronize_cores();
- 在master核初始化完全部数据才能使数组能够被其他核访问之前,
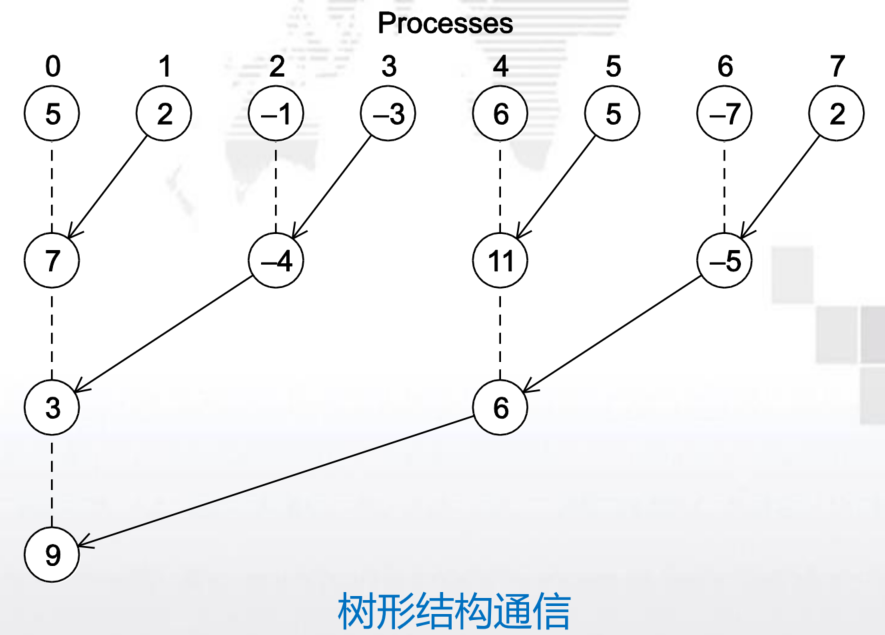
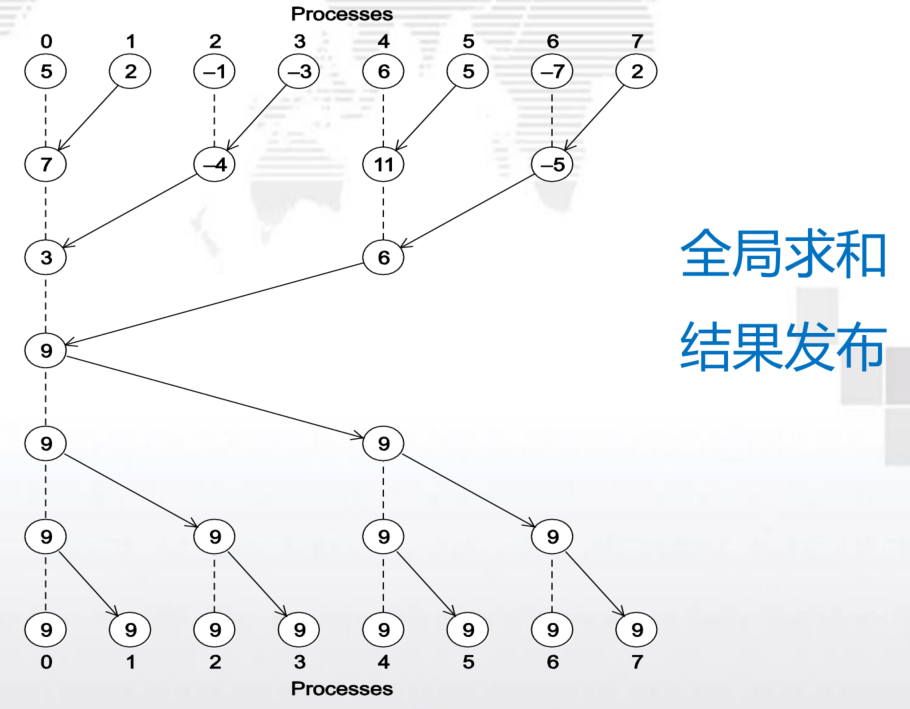
求和实例
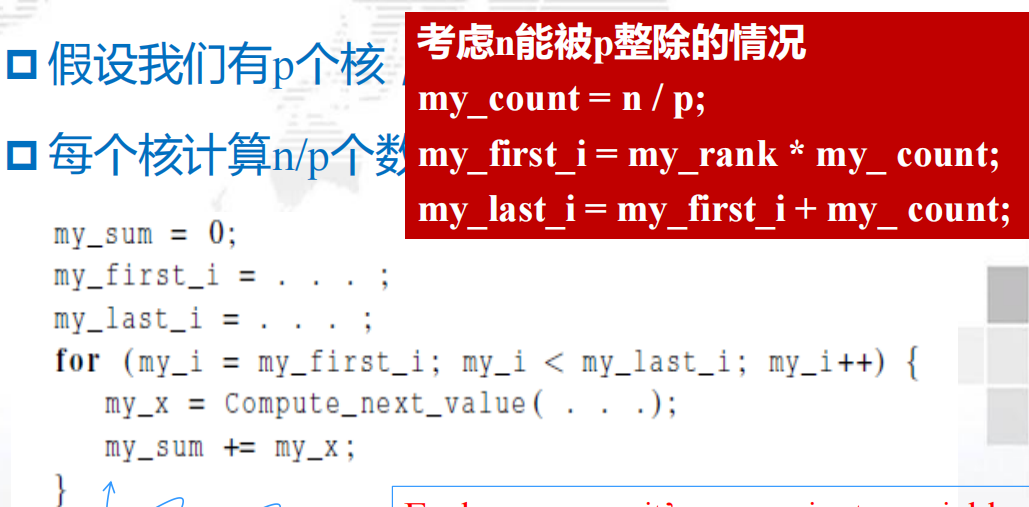
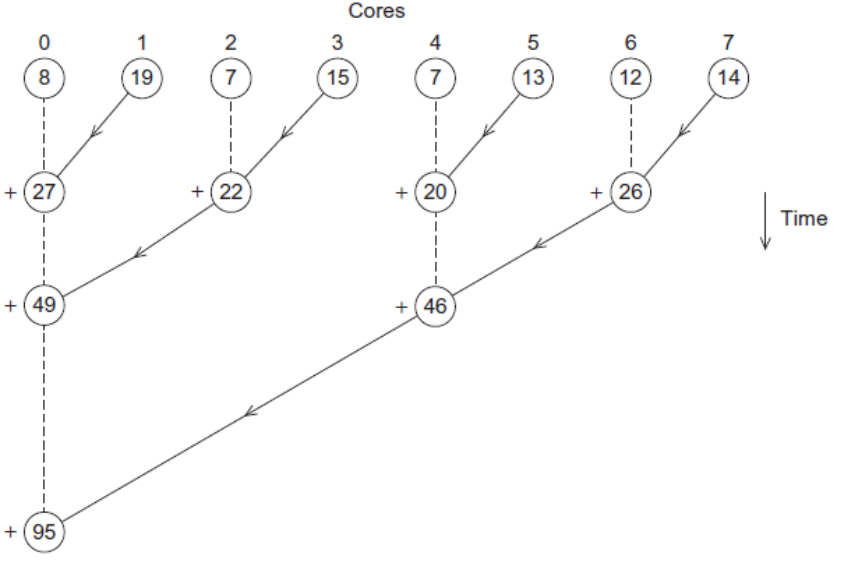
有p个核,每个核独立于其他核并累加求和,以得到部分和 ,每个核的计算数为n/p
- 全局总和:每个单独的核计算完结果后,将结果发送给master的核,master的核将每个核的结果加起来。
- 部分总和:每个核计算完之后,先两两相加,再两两求和
显然第二种方法更好,性能更高!
-
并行程序的方法:任务并行和数据并行
- 任务并行:将待解决的任务所需要执行的各个任务分配到各个核上去执行
- 数据并行:将待处理的数据分配给各个核,每个核在分配的数据集上执行大致相似的操作
习题
图像渲染:
一部2小时的电影渲染需要:
2小时*3600秒 * 24帧 *(1~2小时)/ 24小时=20 ~ 40年!
特殊场景每帧甚至可能需要60个小时!
- 高性能计算机的基准测试程序包括HPL、[
HPCC] 和 [HPCG] 。 - 高性能计算机的浮点性能是通过HPL (High performance Linpack) 基准程序包测定的,其单位是 [
FLOPS] .


-
请分别解释幵行计算和分布式计算的共同点和区别。
- 并行计算:一个程序通过多个任务紧密协作来解决某一个问题;
目的:是用多个处理器去幵行解决同一个问题,使得性能和规模增大。
(1)faster加速求解问题的速度;
(2)bigger提高求解问题的规模
应用场合:常用于科学计算,预测天气
实现方式:结构比较紧密,各节点之间通过高速网络连接;如超级计算机
实时性:并行计算每个节点的每一个任务块都是必要的,计算的结果相互影响,要求每个节点的计算结果要绝对正确,并且在时间上做到同步。- 分布式计算:一个程序不需要其它程序协作来解决某个问题;通常是一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多计算机迚行处理,最后把这些计算结果综合起来得到最终的结果。
目的:在做资源的分享和共用,然后直接在系统上互相沟通传递资料。
应用场合:商业应用,如云计算、穷举暴力类的计算等
实现方式:结构比较松散,各节点可能会跨越局域网,戒者直接部署在互联网上,节点之间几乎不互相通信。
实时性:分布式的计算被分解后的小任务互相之间有独立性,节点之间的结果几乎不互相影响,实时性要求不高。(并发) -
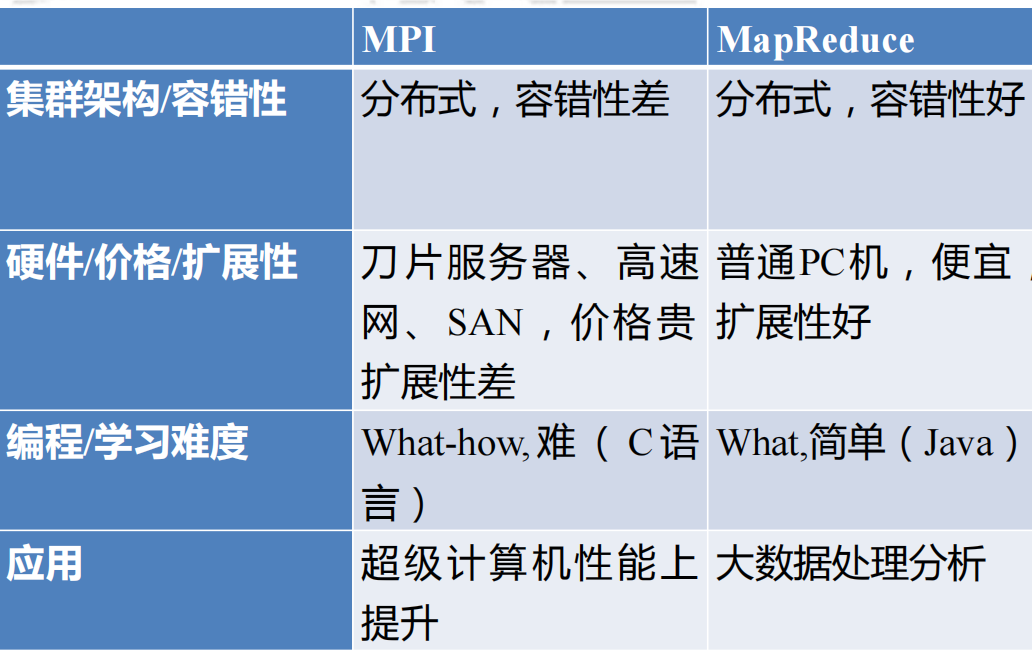
请解释传统幵行计算框架MPI不大数据幵行计算模型MapReduce的共同点和区别


第二章
计算机发展演化、语言模型、并行硬件、并行软件

Foster方法:
- 划分问题并识别任务
- 在任务中识别要执行的通信
- 凝聚或聚合使之变成较大的组任务
- 将聚合任务分配给进程/线程
计算机体系结构(必考)
并行硬件
主存(Main Memory) - 高速缓存Cache - CPU
-
进程:正在运行的程序的实例
- 可执行的机器语言程序
- 一块内存空间
- 操作系统分配给进程的资源描述符
- 安全信息
- 进程状态信息
-
线程:
- 允许程序员将进程划分为多个大致独立的任务.
- 当某个任务阻塞时能够执行其他任务
单指令单数据流(SISD):是一个串行的计算机系统 (冯诺依曼系统)
- 单指令: 在一个时钟周期内只有一个指令流被CPU进行处理。
- 单数据: 在一个时钟周期内只有一个数据流作为输入而使用
单指令多数据流(SIMD):是并行系统
- 单指令: 在一个时钟周期内,所有的处理器单元执行相同的指令
- 多数据流: 每个处理器单元能够作用在不同的数据单元上
- SIMD系统通过对多个数据执行相同的指令从而实现在多个数据流上的操作
输入和输出:
-
在分布式内存程序中,只有进程0能够访问stdin。
-
在共享内存程序中,只有主线程或线程0能够访问stdin.
-
在分布式内存和共享内存系统中,所有进程/线程都能够访问stdout 和stderr.
-
向量处理器
-
GPU
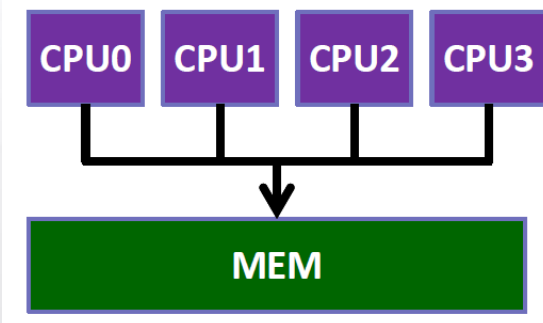
共享内存计算机系统(UMA、NUMA、HPC服务器)
✓ 一组自治的处理器通过互连网络与内存系统连接.
✓ 各个核可以共享访问计算机的内存系统,每个处理器能够访问每个内存区域.
✓ 可以通过检测和更新内存系统来协调各个核,处理器通过访问共享的数据结构来隐式的通信。
特点:
✓一致内存访问(UMA)系统容易编程。
✓ 非一致内存访问(NUMA)系统拥有更大容量的内存。
分布式内存
✓ 每个核都有自己独立的私有的内存.
✓ 核之间的通信需要通过网络发送消息,进行显式的通信.
✓ 将多台计算机连接起来形成一个计算平台,而没有共享内存
集群(最广泛)
✓ 一组商品化系统组成(如PC).
✓ 通过商品化网络连接(如以太网).
集群的节点:指的是通过通信网络相互连接的独立计算单元
混合系统:节点通常都是有一个或多个多核处理器的共享内存系统.
互连网络
共享内存 = 多核处理器共享内存系统
分布式内存 = 多个多核处理器的共享内存系统
分布式内存:
直接互联、间接互联
Cache一致性:
- 一致性访问:每个核访问内存中任何一个区域的时间都相同
- 非一致性访问:访问与核直接连接的那块内存区域比访问其他核要快
并行软件
- SPMD: SPMD程序仅包含一段可执行代码,通过使用条件转移语句,可以让这一段代码在执行时表现得像在不同处理器上执行不同的程序。
写并行程序的步骤:
- 将任务在进程/线程间分配
✓ 每个进程/线程获得大致相等的工作量
✓ 通信量最小化. - 安排进程/线程之间的同步.
- 安排进程/线程之间的通信.
共享内存
动态线程:主线程,在任意时刻都有一组工作线程。当主线程接收到请求后,就会派生出一个工作线程去执行该请求,工作线程完成任务后,就会终止执行然后合并到主线程中。
静态线程:主线程派生出执行线程后,所有的线程都在执行,直到工作结束后主线程进行清理才终止
竞争条件:多个线程/进程同时访问一个资源时,形成互相竞争状态,而程序的输出取决于获胜的线程/进程。
- 引发不确定性
- 四种解决方法:
- 临界区 critical/atomic
- 忙等待(bool flag)
- 互斥量(锁)
- 信号量(unsign int)
消息传递
消息传递的API要提供一个发送和接收的函数,进程之间通
过标号相互识别
char message[100] ;
. . .
my_rank = Get_rank ( ) ;
if ( my_rank == 1) {
sprintf ( message , "Greetings from process 1" ) ;
Send ( message , MSG_CHAR , 100 , 0 ) ;
}
else if ( my_rank == 0) {
Receive ( message , MSG_CHAR , 100 , 1 ) ;
printf ( "Process 0 > Received: %s\n" , message ) ;
}
- PGAS(Partitioned Global Address Space Languages)语言提供
了一种共享内存程序的机制
shared int n = . . . ;
shared double x [ n ] , y [ n ] ;
private int i , my_first_element , my_last_element ;
my_first_element = . . . ;
my_last_element = . . . ;
/ * Initialize x and y */
. . .
for ( i = my_first_element ; i <= my_last_element ; i++)
x [ i ] += y [ i ] ;
第二章总结(选择填空必考):
-
并行编程模型作为一个抽象存在于硬件和内存架构之上
-
在一般情况下,编程模型的设计与计算机体系结构相匹配。
✓ 共享内存程序模型为共享内存机器
✓ 消息传递程序模型为分布式内存机器 -
但是编程模型不受机器或内存体系结构的限制:
✓ 消息传递模型可以在共享内存机器上支持:例如,MPI
可以在单个服务器上。
✓ 共享内存模型也可以在分布式内存机器上:例如,划分全局地址空间的语言可以在分布式系统上。
并行计算机和程序设计模型的分类
◆ Flynn经典分类法——SISD/SIMD/MISD/MIMD
◆ 内存结构上分类——共享内存系统、分布式内存系统
◆ 程序设计模型分类——共享内存编程模式、分布式内存编程
模式
第二章习题


- 经典Flynn分类按照指令和数据将计算机体系结构分为SISD、SIMD、 [
MISD] 和 [MIMD] 。 - 并行程序设计模型分为 [
共享内存程序模型] 和 [消息传递程序模型] 。





- 请给出共享内存系统和分布式内存系统的定义,并举出对应
的计算机有哪些?
共享内存系统
定义:
- 一组自治的处理器通过互连网络与内存系统连接.
- 各个核可以共享访问计算机的内存系统,每个处理器
能够访问每个内存区域.- 可以通过检测和更新内存系统来协调各个核,处理器
通过访问共享的数据结构来隐式的通信
例子:台式机、笔记本、移动手机、HPC服务器分布式内存系统
定义:
- 每个核都有自己独立的私有的内存;
- 核之间的通信需要通过网络发送消息,进行显式的通信 ;
- 将多台计算机连接起来形成一个计算平台,而没有共享内存
例子:(集群、超级计算机、数据中心)
- 经典Flynn分类按照指令和数据将计算机体系结构分为SISD、SIMD、 [
MISD] 和 [MIMD] 。 - 并行程序设计模型分为 [
共享内存系统模型] 和 [分布式程序系统模型] 。
第3章 MPI
、编译运行
点对点通信(HellowWorld)、集群通信(描述各种情况、分块函数的功能)
SPMD
单程序多数据流
- 只编译一个程序,但不是给不同的进程编译不同的程序
- 0号进程做的事情与其他进程不同,其他的进程生成和发送消息时,他负责接收消息并输出
- 主要依靠if-else实现SPMD
MPI常用命令
MPI进程的创建、启动和管理需借助进程管理(PM: Process Manager)来完成。
PM就是MPI环境与操作系统的接口
MPICH提供多种进程管理器,如MPD
MPD是由Python实现的一组工具构成。
Mpdboot在多个主机上启动MPD进程,形成MPI运行时的环
境,目标主机列表由$HOME/mpd.hosts文件制定
mpiexec提供MPI环境与外界交互的强大接口,并在此基础上构
造MPI进程管理环境。
//同时启动mpd.hosts中所列节点的mpd
$mpdboot -n 3 -f mpd.hosts
$mpdtrace -l //查看节点列表
$mpdcleanup//关闭
$mpdexit //杀死指定节点mpd守护进程。
常用参数:-mpdid
$mpdallexit //杀死所有的mpd守护进程。
$mpdlistjobs //列出作业的进程信息。
$mpdkilljob //停止某个作业的所有进程
$mpiexec -n <number of processes> <executable>
#其中-n是表示用几个进程来执行这个程序。
$mpiexec –n 1 –host loginnode master: -n 32 –host slave
#其作用范围为由冒号隔开的选项组
$mpiexec –gdb –n 10 ./cpi
#在启动之前需要使用-g选项来编译程序
#启动程序后,各进程均分别在各自环境和GDB控制下执行。
$mpdlistjobs:查看各节点上运行的进程信息
$totalview是一个商业版本的图形化调试工具。
点对点通信
-
MPI_ANY_SOURCE,MPI_ANY_TAG
1、MPI_ANY_SOURCE:
任何进程发送的消息都可以接收,但其它要求必须满足;
2、MPI_ANY_TAG:
任何标签的消息都可以接收,但其它要求必须满足;
3、两者可同时使用,也可单独使用;
4、不能给通信子comm指定任意值;
5、发送操作与接收操作不对称。 -
发送 : 阻塞和缓冲
-
接收 总是阻塞的
六个MPI基本函数
通信子
通信子是所有可以进行相互通信的进程的集合。
- MPI_COMM_WORLD是MPI预定义的常量,是一个包含所有用户启动进程的通信子。(MPI_Init)
进程标识号(进程id): - 进程在某个通信子中有唯一的标识号;
一个进程可以属于不同的通信子,它在不同通信子中的标识号不同;- 进程号为从0开始的连续非负整数, 0 - N
函数:
- MPI_Comm_create(MPI_COMM_WORLD,group,newcomm) : 创建通信子
- MPI_Comm_rank(MPI_COMM_WORLD,&my_rank):获取当前进程号
- MPI_Comm_size(MPI_Comm comm, int *size):获取给定通信子的所有进程数
MPI集合通信
- 集合通信:组通信、群通信
- 集合通信一般实现三个功能:通信、同步、计算
通信
- 三种方式:一对一、一对多、多对多
广播:一对多
一个进程的数据被发送到通信子中的所有进程,即广播
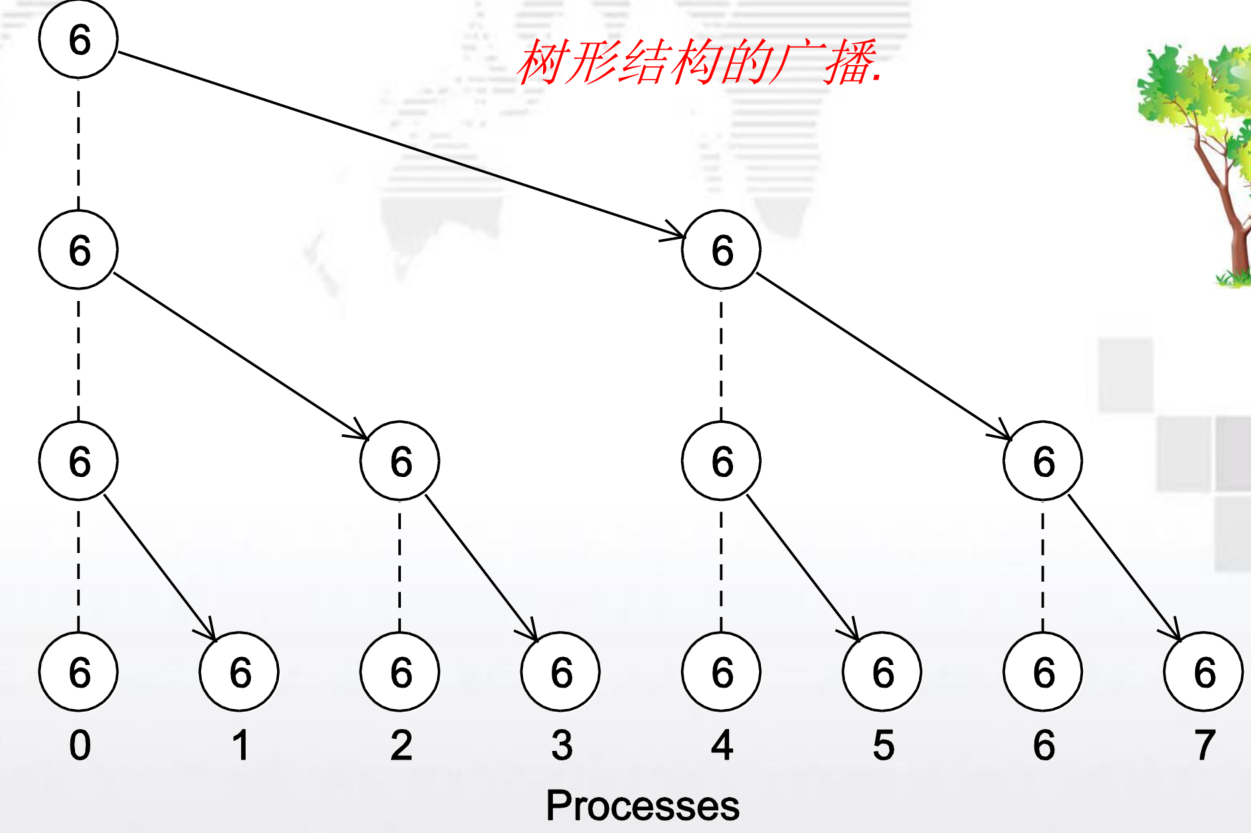
MPI_Bcast()函数
- 功能: 一个进程的数据被发送到通信子中的所有进程,即广播

MPI_Bcast(buffer,count,datatype,root,comm)
buffer 通信消息缓冲区的起始地址
count 将广播出去/或接收的数据个数
datatype 广播/接收数据的数据类型
root 广播数据根进程的标识号
comm 通信子
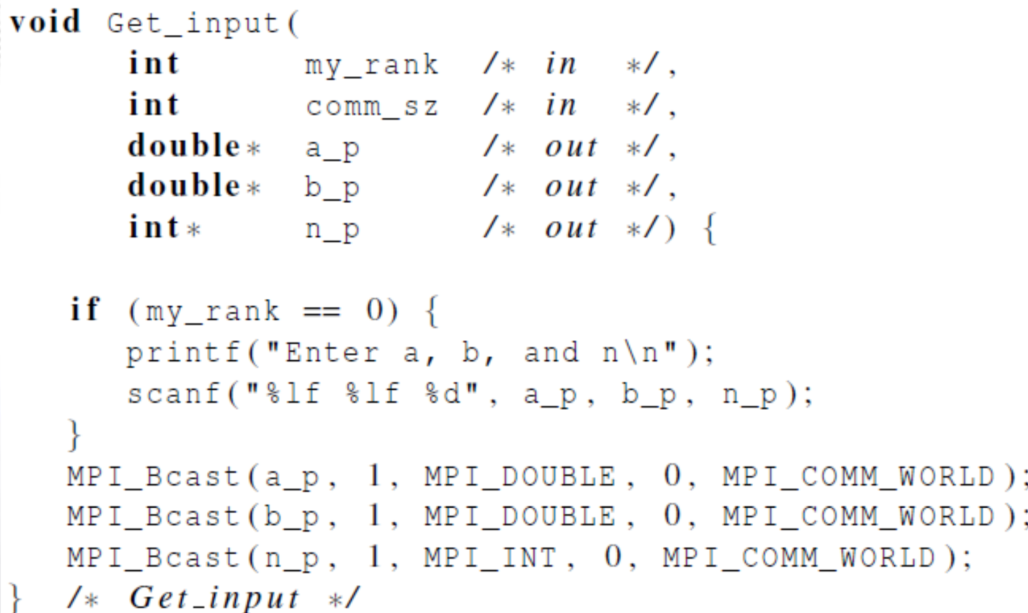
改进输入数据函数

- 点对点通信 改进 为集群通信
规约:多对一
除完成消息传递功能之外,还能对所传递的数据进行一定的操作或运算在进行通信的同时完成一定的计算
MPI_Reduce函数:
- 功能:
将组内每个进程输入缓冲区中的数据按给定的操作op进行运算,并将其结果返回到序列号为root进程的输出缓冲区中。

MPI_Reduce(sendbuf,recvbuf,count,datatype,op,root,comm)
sendbuf 发送消息缓冲区的起始地址
recvbuf 接收消息缓冲区的起始地址
count 发送消息缓冲区中的数据个数
datatype 发送消息缓冲区的元素类型
op 归约操作符
root 根进程号
comm 通信子
输入缓冲区由参数sendbuf、count和datatype定义;
输出缓冲区由参数recvbuf、count和datatype定义;
注意:所有进程输入和输出缓冲区的长度、元素类型相同.
MPI_Reduce(sendbuf,recvbuf,count,datatype,op,root,comm)
MPI_Allreduce()
规约+广播:所有的进程都有全局总和
-
区别:与MPI_Reduce相比,缺少dest_process这
个参数,因为所有进程都能得到结果 -
这个操作等价于首先进行一次MPI_Reduce, 然后再执行一次MPI_Bcast
散射:多对一
计算向量求和
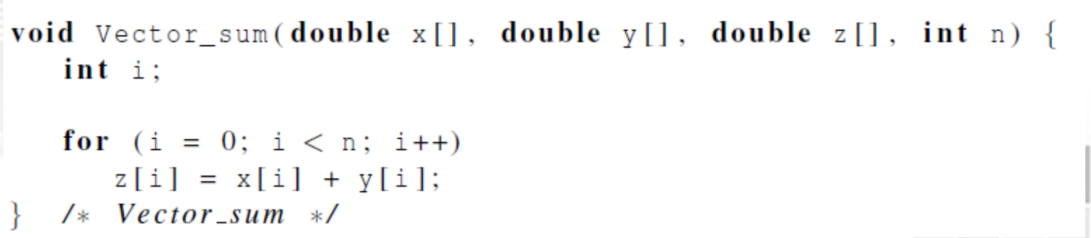
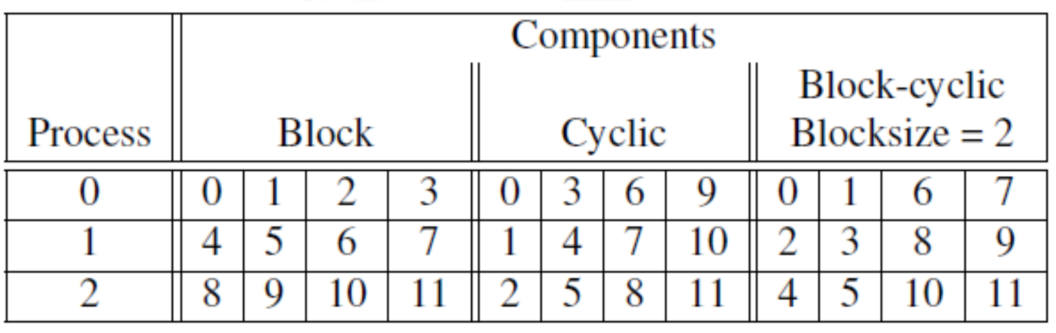
如何划分数据?
三种方法:块划分、循环划分、块循环划分
MPI_Scatter()函数

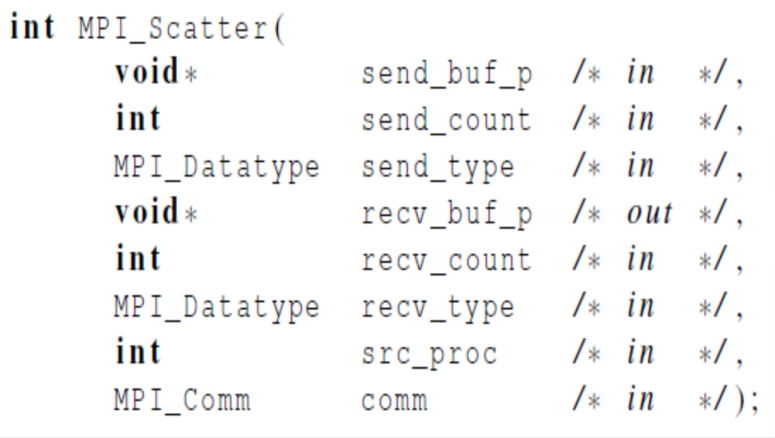
MPI_Scatter(sendbuf,sendcount,sendtype,recvbuf,recvcount,recvty
pe,src_proc,comm)
/*
sendbuf:发送消息缓冲区的起始地址
sendcount: 发送到每个进程的数据个数
sendtype:发送消息缓冲区中的元素类型
recvbuf: 接收消息缓冲区的起始地址
recvcount: 接收到的数据个数
recvtype: 发送消息缓冲区的元素类型
src_proc: 负责发送消息的源进程
comm: 通信子
*/
- 功能:将发送消息的源进程中sendbuf指向的数据,按照块大小为sendcount的块划分的方式发送给通信子中的其它进程。
- 注意:仅适用于块划分和向量分量个数n可以整除以comm_sz的情况。
读取并分发向量的函数

MPI_Gather() 函数
- 功能:按照进程编号将每个进程中sendbuf指向的数据按照块,依次存储在目的进程的recvbuf指向的地址。
- 注意:仅适用于块划分和每个块大小相同的情况。
将向量所有分量都收集到0号进程上,然后由0号进程将所有分量输出
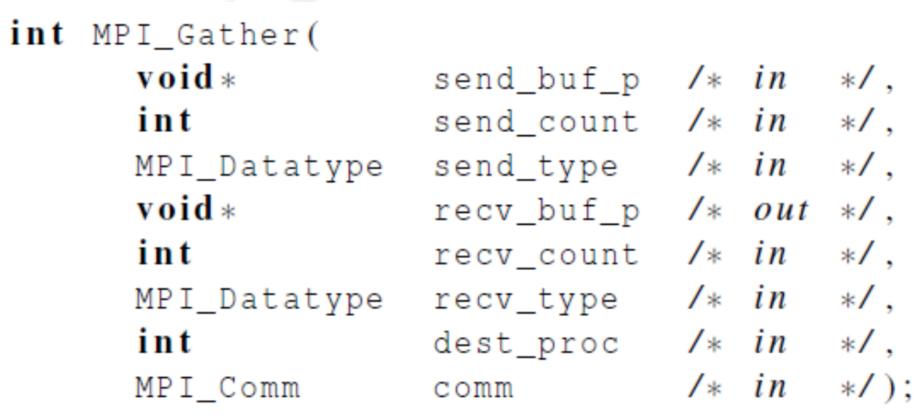
MPI_Gather(sendbuf,sendcount,sendtype,recvbuf,recvcount,recvtype,dest_proc,comm)
sendbuf:发送消息缓冲区的起始地址
sendcount: 发送到每个进程的数据个数
sendtype:发送消息缓冲区中的元素类型
recvbuf: 接收消息缓冲区的起始地址
recvcount: 每个进程接收到的数据个数
recvtype: 发送消息缓冲区的元素类型
dest_proc: 负责发送消息的源进程
comm: 通信子
输出分布式向量的函数

矩阵乘法-MPI_Allgather函数
对于这样的循环迭代,每个进程在执行如下语句时,就必须使得每个进程都能访问x中的所有分量
for(j=0;j<n;j++)
y[i]+=A[i*n+j]*x[j];
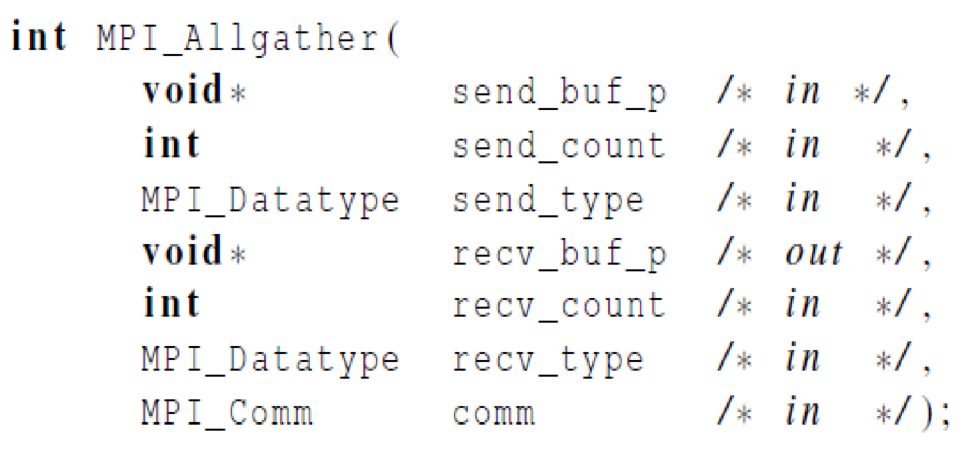
- 功能:将每个进程的send_buf_p内容串联起来,存储到每个进程的recv_buf_p参数
- 区别:与MPI_Gather相比,缺少dest_process这个参数,因为所有进程都能得到结果

点对点通信 与 集合通信 的区别
集合通信:
- 所有的进程都必须调用相同的集合通信函数
- MPI_Reduce不能用MPI_Recv
- 每个进程传送给MPI的集合通信函数的参数必须相容
- 参数recvbuf只用在dest_process上,数据的接收地址必须在目的进程上
- 所有进程仍需要传递一个与recvbuf相对应的实际参数,即使它的值是NULL
点对点通信:
-
点对点通信通过标签和通信子匹配,集合通信通过通信子和调用顺序匹配
- 使用同一缓冲区同时作为输入和输出调用求得所有进程里x的全局总和,并且将x的结果放在0号进程里:
MPI_Reduce(&x,&x,1,MPI_DOUBLE,MPI_SUM,0,comm);
- 使用同一缓冲区同时作为输入和输出调用求得所有进程里x的全局总和,并且将x的结果放在0号进程里:
如果通信子只包含一个进程,不同的MPI集合通信函数分别会做什么?
习题&作业


- 编写一个向量加法的MPI程序
- 3-9;3-10
同步
- 同步点:快的进程必须等待慢的进程,直到所有进程都执行到该语句后才可以向下进行
- 进程完成同步调用后,所有的进程都已执行同步点前面的操作
计算
- 组内消息通信 --> 相应进程的消息处理 --> 处理结果存入接收缓冲区
- MPI集合通信就是消息的处理,即,计算部分
MPI派生数据类型
MPI整合多条消息数据的方式:
- 不同通信函数中的count参数
- 派生数据类型
- MPI_Pack/Unpack函数
- 派生数据类型可以用于表示内存中数据项的任意集合
- 派生数据类型是由一系列的MPI基本数据类型和每个数据类型的偏移所组成的。
主要思想:如果发送数据的函数知道数据项的类型及内存中数据项集合的相对位置,就可以在数据项被发送出去之前在内存中将数据项聚集起来
接收函数可以在数据项被接收后将数据项分发到它们在内存中正确的目标地址上
MPI_Type_create_struct:可以用这个函数创建由不同基本数据类型的元素所组成的派生数据类型
MPI_Get_address:用这个函数可以找到相关地址的值,参数 MPI_Aint 是特殊的存储地址的类型.
MPI_Type_commit: 允许 MPI 在通信函数内部使用新的数据类型,并
优化数据类型内部表征
性能评估(必考)
一 计时功能
MPI_Wtime() / GET_TIME()
功能:返回一个用浮点数表示的秒数,从某一时刻到调用时刻所经历的时间(s)
MPI_Wtime()
- 注意:调用产生结果的单位为秒,需要用户自己转换成其它时间单位。
//MPI_Wtime函数的用法
double start_time,end_time,total_time;
………(变量说明、初始化与其它计算)
start_time=MPI_Wtime();
……….(需要计时的部分)
end_time=MPI_Wtime();
total_time=end_time-start_time;
Printf(“It tooks %f seconds\n”,total_time);
MPI_Wtick调用的说明原型: double MPI_Wtick(void)
功能:返回计算机时钟滴答一下所占用的时间(s){计算机所能分辨的最小时间}
示例:
……(包含头文件 )
int main(int argc, char **argv) {
double t1,t2,tick; int rank;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
t1=MPI_Wtime(); /*获取起始时间*/
Sleep(1000); /*系统睡眠一秒钟*/
t2=MPI_Wtime(); /*获取终止时间*/
tick=MPI_Wtick(); /*获取本机的时间分辨率*/
printf("id=%d totaltime=%f tick=%10e2\n",rank,t2-t1,tick);
MPI_Finalize();
}
二 同步路障
功能:实现通信的同步功能阻塞所有的进程,直到所有进程都调用了它
- 快的进程必须等待慢的进程,直到所有进程都执行到该语句后才可以向下进行
double local_start, local_finish,local_elapsed,elapsed;
…
MPI_Barrier(comm);
local_start=MPI_Wtime();
/* Code to be timed */
local_finish=MPI_Wtime();
local_elapsed=local_finish-local_start;
MPI_Reduce(&local_elapsed,&elapsed,1,MPI_DOUBLE,MPI_MAX,0,comm;
if (my_rank ==0)
printf(“Elapsed time = %e seconds\n”,elapsed)
获取机器名及版本号
int MPI_Get_version(int *version, int *subversion)
int MPI_Get_processor_name( char *name, int *resultlen )
#include <stdio.h>
#include <mpi.h>
void main(int argc, char **argv)
{
char name[MPI_MAX_PROCESSOR_NAME];
int resultlen,version,subversion;
MPI_Init(&argc,&argv);
MPI_Get_processor_name(name,&resultlen);
MPI_Get_version(&version,&subversion);
printf(“name=%s version=%d subversion=%d\n",name, version, subversion);
MPI_Finalize();
}
三 加速比和效率
-
comm_sz固定,n增大,那么矩阵的大小和程序的运行时间也会增加;
- comm_sz 较小,n增大1倍,运行时间变为原来的4倍;
- comm_sz 较大,公式不成立。
-
n固定,comm_sz增大,运行时间减少
- n较大:comm_sz增大,大约能减少一半的时间
- n较小:comm_sz增大,效果甚微


加速比:是用来衡量串行运算和并行运算时间之间的关系,表示为串行时间与并行时间的比值

效率:是每个进程的加速比
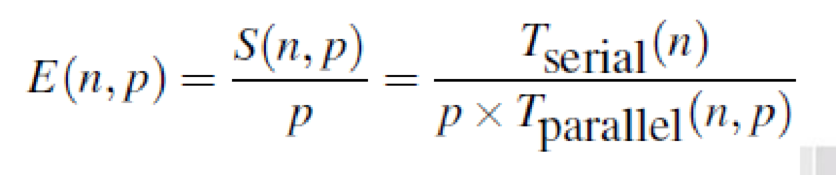
- 线性加速比相当于并行效率=1
- 通常效率都小于1
可扩展性
四 MPI程序的安全性
注意消息死锁
两个进程都是先接收,后发送。没有发送,何谈接收?
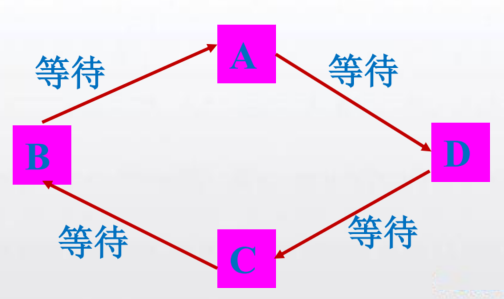
先发送,后接收? 在系统有缓存的情况下可以
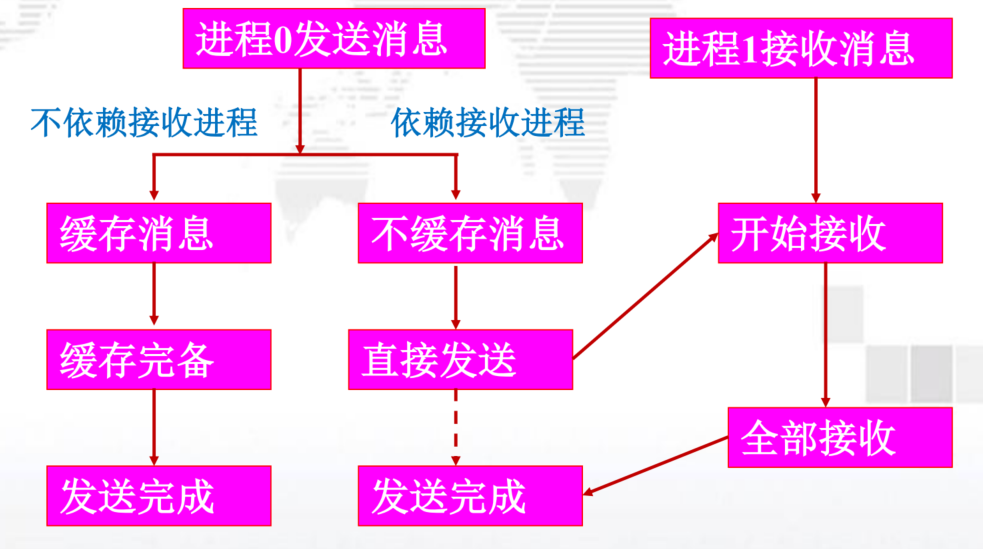
- 但是,如果系统缓存消息: A,C两个发送操作都需要系统缓冲区,如果系统缓存不足,消息传递将无法完成。
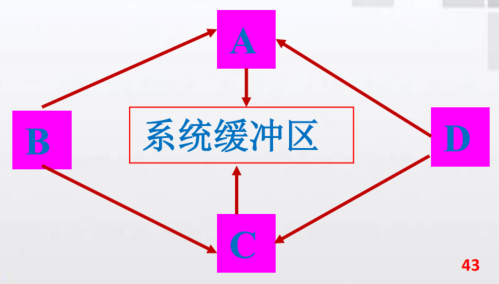
- 不安全通信:
- AC同时发:无缓冲区,消息死锁,所有线程全部阻塞
- AC同时发:有缓冲区,如果没有缓冲区就不行,不安全的调用次序
- 安全通信:
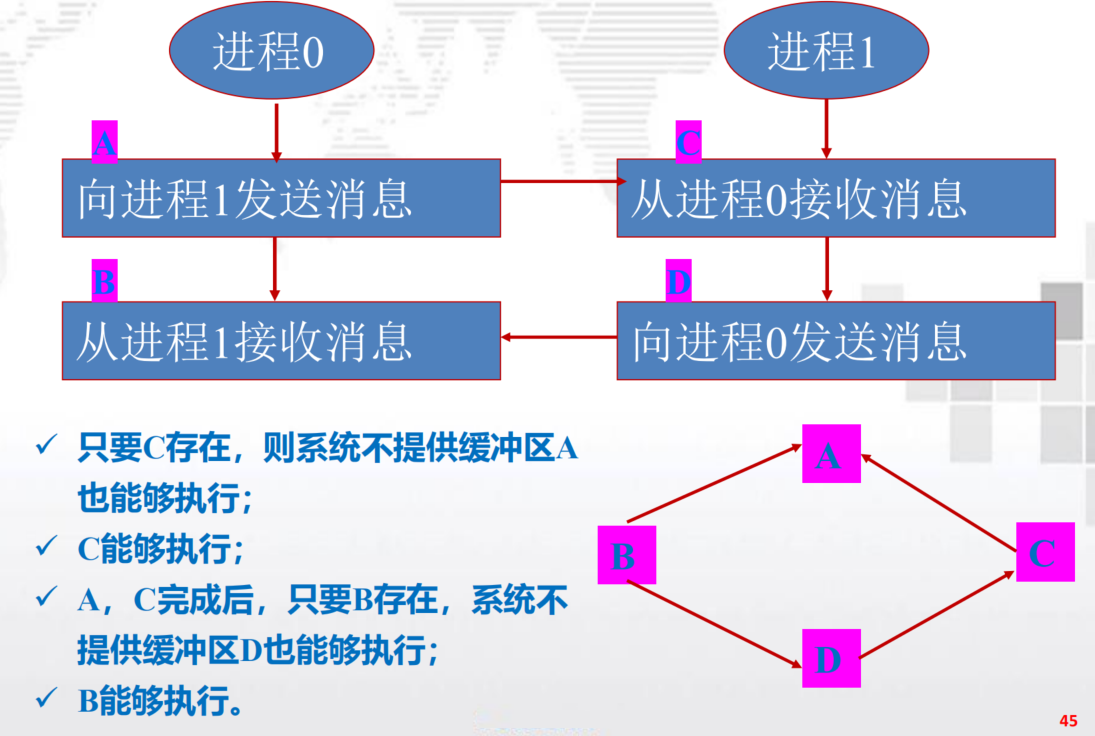
结论:
- 将发送与接收操作按照次序进行匹配
- 一个进程的发送操作在前,接收操作在后;另一个进行的接收操作在前,发送操作在后;
- 若将两个进程的发送与接收操作次序互换,其消息传递过程仍是安全的
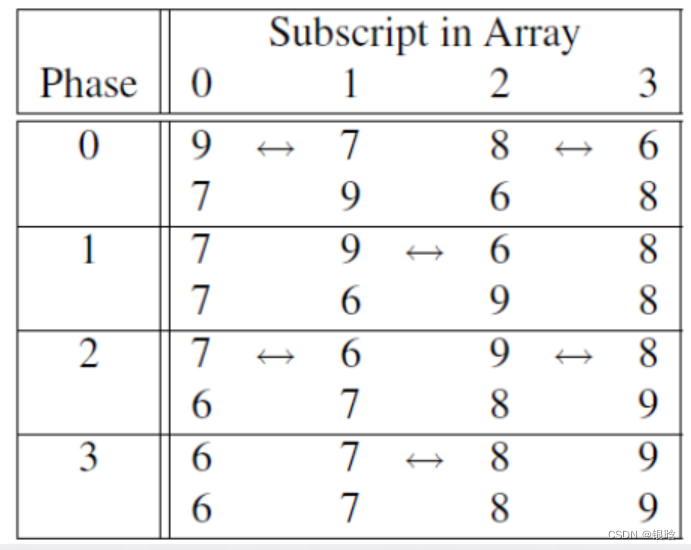
奇偶并行排序
定理:设A是一个拥有n个键值的列表,作为奇偶交换排序算法的输入,那么经过n个阶段后,A能够排好序。
步骤如下:
- 从数组中取数字
- 偶数阶段:将数组中的数字按偶数划分成组
- 奇数阶段:将数组中的数字按奇数划分成组
- 无法分成两两一组,就去掉头或尾
- 交换排序

- 伪代码

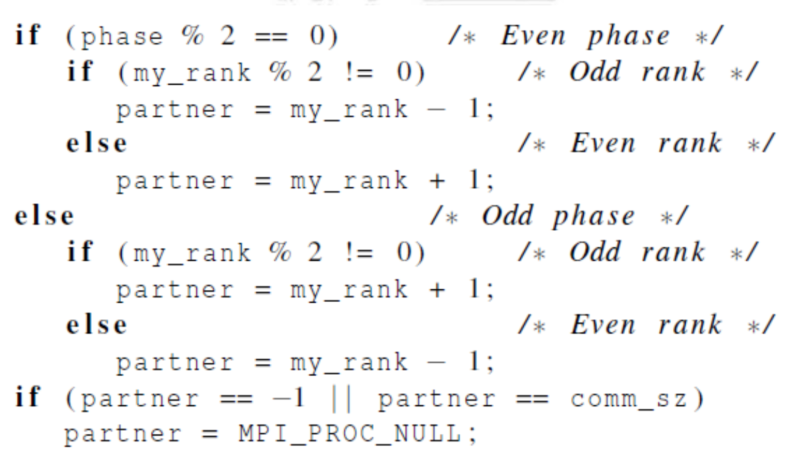
检验安全
- 输入合适的值和comm_sz,程序没有挂起或者崩溃。

MPI_Sendrecv(local_A, local_n, MPI_INT, even_partner, 0, temp_B, local_n,MPI_INT, even_partner, 0, comm, &status);
调用一次这个函数,分别执行一次阻塞式消息发送和一次消息接收
MPI库的这个函数实现了通信调度,使程序不再挂起或崩溃
Merge_low & Merge_high 函数


int main(int argc, char* argv[]) {
int my_rank, p;
int *local_A;
int n,local_n;
MPI_Comm comm;
MPI_Init(&argc, &argv);
comm = MPI_COMM_WORLD;
MPI_Comm_size(comm, &p);
MPI_Comm_rank(comm, &my_rank);
n = 16;//书上例子
local_n = n/p;
local_A = (int*) malloc(local_n*sizeof(int));
Read_list(local_A, local_n, my_rank, p, comm);
Print_local_lists(local_A, local_n, my_rank, p, comm);
Sort(local_A, local_n, my_rank, p, comm);
Print_global_list(local_A, local_n, my_rank, p, comm);
free(local_A);
MPI_Finalize();
return 0;
} /* main */
void Sort(int local_A[], int local_n, int my_rank, int p,MPI_Comm comm) {
int phase;
int *temp_B, *temp_C;
int even_partner; /* phase is even or left-looking */
int odd_partner; /* phase is odd or right-looking */
temp_B = (int*) malloc(local_n*sizeof(int));
temp_C = (int*) malloc(local_n*sizeof(int));
if (my_rank % 2 != 0) {
even_partner = my_rank - 1;
odd_partner = my_rank + 1;
if (odd_partner == p) {
// Idle during odd phase
odd_partner = MPI_PROC_NULL;
}
else {
even_partner = my_rank + 1;
}
// Idle during even phase
if (even_partner == p) {
even_partner = MPI_PROC_NULL;
odd_partner = my_rank-1;
}
qsort(local_A, local_n, sizeof(int), Compare); /* Sort local list using built-in quick sort */
for (phase = 0; phase < p; phase++){
Odd_even_iter(local_A, temp_B, temp_C, local_n, phase,even_partner, odd_partner, my_rank, p, comm);
free(temp_B);
free(temp_C);}
} /* Sort */
void Odd_even_iter(int local_A[], int temp_B[], int temp_C[], int local_n, int phase, int even_partner, int odd_partner, int my_rank, int p, MPI_Comm comm) {
MPI_Status status;
if (phase % 2 == 0) { /* even phase */
if (even_partner >= 0) {
MPI_Sendrecv(local_A, local_n, MPI_INT, even_partner,0, temp_B, local_n, MPI_INT, even_partner, 0, comm, &status);
if (my_rank % 2 != 0) {
Merge_high(local_A, temp_B, temp_C, local_n);}
else{
Merge_low(local_A, temp_B, temp_C, local_n);}
}
}
else { /* odd phase */
if (odd_partner >= 0) {
MPI_Sendrecv(local_A, local_n, MPI_INT, odd_partner, 0,
temp_B, local_n, MPI_INT, odd_partner, 0, comm, &status);
if (my_rank % 2 != 0){
Merge_low(local_A, temp_B, temp_C, local_n);
}
else{
Merge_high(local_A, temp_B, temp_C, local_n);}
}
}
} /* Odd_even_iter */
第4章 Pthreads
1个选择、半个简答(和MPI一起考)
POSIX线程库,也称为Pthreads线程库
POSIX是一个类Unix操作系统上的标准库,可链接到C程序中的库
Pthreads的API只在支持POSIX的系统上才有效—Linux, MacOS X, Solaris, HPUX, …(unix系统)
HelloWorld
#include<stdio.h>
#include<stdlib.h>
#include<pthread.h> # Pthread的包
int thread_count;
void *Hello(void* rank); // 线程函数
int main(int argc, char* argv[]){
long thread;
pthread_t* thread_handles; // 线程的指针变量
// 获取线程编号
thread_count = strtol(argv[1], NULL, 10)
// 给线程分配空间
thread_handles = malloc(thread_count*sizeof(pthread_t))
// 结束线程
for(thread = 0; thread < thread_count; thread++)
pthread_create(thread_handles[thread], NULL,Hello,(*void) thread); // 注意函数指针,将函数名作为指针变量传递
// 结束线程
for(thread = 0; thread < thread_count; thread++)
pthread_join(thread_handles[thread], NULL);
// 释放线程空间
free(thread_handles)
return 0;
}
void *Hello(void* rank){
long my_rank = (long) rank;
printf("Hello from thread %ld of %d\n",my_rank, thread_count);
return NULL;
}
- 编译:
gcc -g -Wall -o pth_hello pth_hello.c -lpthread- -lpthread : link in the Pthreads library
- 运行:
./pth_hello 线程数
-
strtol函数的功能是将字符串转化为long int
-
应该限制使用全局变量,除了确实需要用到的情况
- 如:— 线程间共享变量
第5章 OpenMP进行共享内存编程
HelloWorld程序理解、编译运行、PI值估值、梯形积分
临界区、常见指令、掌握openMP的函数(进程编号、个数、时间、设置)
变量
OpenMP是一个针对共享内存编程的API。
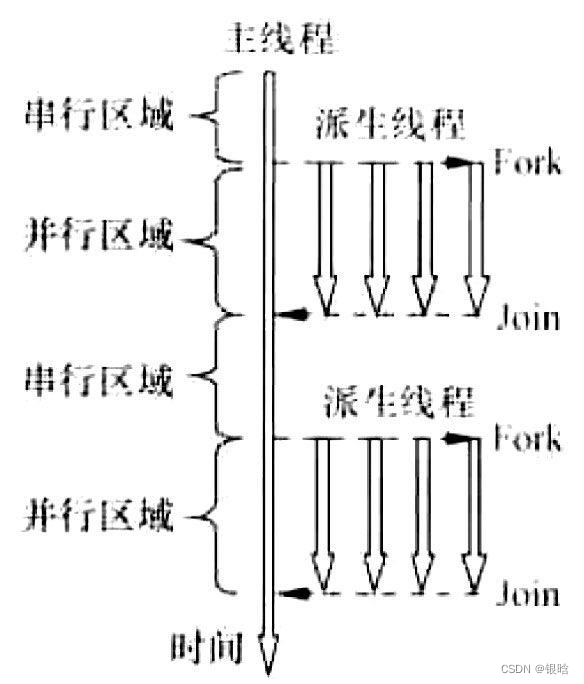
- Fork / Join 方式
- 基于指令的共享内存API
MP = multiprocessing(多处理)
- 在系统中,OpenMP的每个线程都有可能访问所有
可以访问的内存区域 - 共享内存系统:将系统看做一组核或CPU的集合,
它们都能访问主存
OpenMP和Pthread联系和区别

- 在Pthreads中,派生和合并多个线程时,需要为每个线程的特殊结构分配存储空间,需要使用一个for循环来启动每个线程,并使用另一个for循环来终止这些线程
- 在OpenMP中,不需要显式地启动和终止多个线程。它比Pthreads层次更高
#include<stdio.h>
#inclede<stdlib.h>
#include<omp.h>
void Hello(){
int my_rank = omp_get_thread_num(); //获取当前的线程号
int thread_count = omp_get_num_threads(); //获取线程的总数
printf(..., my_rank,thread_count);
}
int main(int argc, char* argv[]){
//从命令行读取设置的线程数
int thread_count = strtol(argv[1],NULL,10);
#pragma omp parallel num_threads(thread_count);
Hello();
return 0;
}
$gcc -g -Wall -fopenmp -o output_dir filename.c
$./filename.c thread_num
OpenMP线程概念
启动一个进程,然后由进程启动这些线程。
线程共享启动它们的进程的大部分资源,如对标准输入和标准输出的访问,但每个线程有它自己
的栈和程序计数器
在parallel之前,程序只使用一个线程,而当程序开始执行时,进程开始启动。当程序达到parallel指令时,原来的线程继续执行,另外thread_count-1个线程被启动。
- 在OpenMP语法中,执行并行代码块的线程集合( 由原始线程和新产生的线程组成)被称作线程组
- 原始的线程被称作主线程,新产生的线程被称作从线程
隐式路障:即完成代码块的线程将等待线程组中的所有其他线程返回
私有栈:每个线程有它自己的栈,所以一个执行Hello函数的线程将在函数中创建它自己的私有局部变量
乱序输出:注意因为标准输出被所有线程共享,所以每个线程都能够执行printf语句,打印它的线程编号和线程数。由于对标准输出的访问没有调度,因此线程打印它们结果的实际顺序不确定
错误检查
- 头文件omp.h以及调用omp_get_thread_num和
omp_get_num_threads将引起错误 - 如果编译器不支持OpenMP,那么它将只忽略parallel指令
- 为了处理这些问题,可以检查预处理器宏
_OPENMP是否定义。如果定义了,则能够包含
omp.h并调用OpenMP函数

变量作用域
-
共享作用域:能够被线程组中所有线程访问的变
量。 -
在 main 函 数 中 声 明 的 变 量 ( a,b,n,global_result 和
thread_count)对于所有线程组中被parallel指令启动的线
程都可访问- parallel块之前被声明的变量缺省作用域是共享的。
- 每个线程都能访问a,b,n(Trap的调用);
- 在Trap函数中,虽然global_result_p是私有变量,但
它引用了global_result变量,该变量是共享作用域的。
因此,
- global_result_p拥有共享作用域。
- parallel块之前被声明的变量缺省作用域是共享的。
-
私有作用域:只能被单个线程访问的变量。
- parallel块中声明的变量有私有作用域(函数中局部变量)
在parallel指令中,所有变量的缺省作用域是共享的
在parallel for中,由其并行化的循环中,循环变量的缺省作用域是私有的。
- 采用“Fork/Join”方式,并行执行模式
OpenMP程序编写
-
OpenMP是“基于指令”的共享内存API。
-
OpenMP的头文件为
omp.h -
omp.h是由一组函数和宏库组成
-
`stdlib.h``头文件即standard library标准库头文件。
- stdlib.h里面定义了五种类型、一些宏和通用工具函数
预处理指令
- 预处理指令是在C和C++中用来允许不是基本C语言规范部分的行为;
- eg:特殊的预处理器指令
#pragma - 不支持pragma的编译器会忽略pragma指令提示
的那些语句. - 允许使用pragma程序在不支持它们的平台上运
行。
- eg:特殊的预处理器指令
# pragma omp parallel:
parallel指令是用来表示之后的结构化代码块应该被多个线程并行执行
结构化代码块是一条C语言语句或者只有一个入口和出口的一组复合C语句
编写规范:
- 预处理器指令以#pragma开头
- #放在第一列
- pragma: 与其它代码对齐
- pragma的默认长度是一行
- 如果有一个pragma在一行中放不下,那么新行需要被转
义——’\’
OpenMP规则
OpenMP中,预处理器指令以#pragma omp开头
# pragma omp parallel clause1 \
clause2 … clauseN new-line
- 编译指导语句由directive(指令)和clause list(子句列表)组成
#pragma omp parallel [clause…] new-line
Structured-block
#pragma omp parallel private(i,j)
其中parallel就是指令,private是子句,且指令后
的子句是可选的。
编译指导语句后面需要跟一个new-line(换行符)。然后跟着的是一个structured-block
- structured-block: for循环或一个花括号对(及内部的全部代码)
当整个编译指导语句较长时,也可以分多行书写,用
C/C++的续行符“\”连接起来即可。如:
#progma omp parallel claused1 \
Claused2 … clausedN new-line
Structured-block
规约子句 reduction
-
规约操作是一个二元操作 (such as addition or multiplication).
-
规约操作就是将一个相同的操作重复应用在一个序列上,得到一个结果。所有的中间结果和最终结果都存储在规约变量里
-
规约子句的第二个好处:
- 当一个变量(线程组共享变量)在reduction子句内部时,每个线程在执行时都会创建并使用自己的私有变量,等parallel块结束之后,私有变量的值会被整合到一个共享变量里面去!
解决了critical语句的弊端
规约操作通过reduction指令实现:
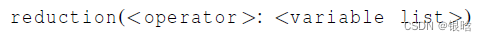

for & parallel for
for指令是用来将一个for循环分配到多个线程中执行
for指令的使用方式:
1.单独用在parallel语句的并行块中;
2.与parallel指令合起来形成parallel for指令
注意:for指令与parallel for指令
派生出一组线程来执行后面的结构化代码块
只能并行for语句
parallel 结合 for实例:
include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[]){
int j=0;
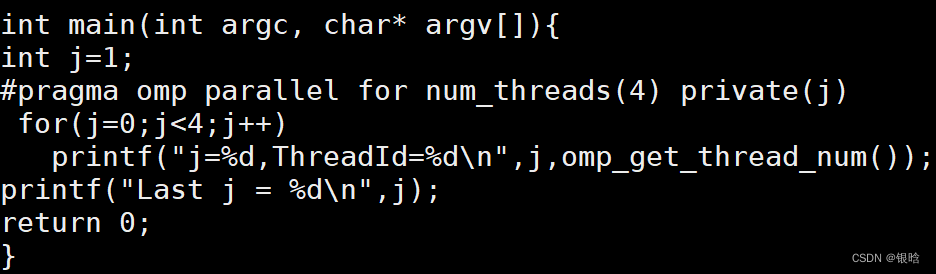
#pragma omp parallel num_threads(4)
{
#pragma omp for
for(j=0;j<4;j++)
printf("j=%d,ThreadId=%d\n",j,omp_get_thread_num());
}
return 0;
}
如果二者不结合,从结果可以看出四次循环都在一个线程里执行,可见,for指令要与parallel指令结合起来使用.
- 多个for
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[]){
int j=0;
#pragma omp parallel num_threads(4)
{
#pragma omp for
for(j=0;j<4;j++)
printf("First:j=%d,ThreadId=%d\n",j,omp_get_thread_num());
#pragma omp for
for(j=0;j<4;j++)
printf("Second:j=%d,ThreadId=%d\n",j,omp_get_thread_num());
}
return 0;
}
for循环的限制

for循环构造的一些限制如下:
变量index必须是整型或指针类型。
表达式start、end和incr必须是兼容类型。
表达式start、end和incr不能够在循环执行期间改变,也
就是迭代次数必须是确定的。
在循环执行期间,变量index只能够被for语句中的“增
量表达式”修改。
for语句中不能含有break。
- parallel for 并行化的循环中如果存在多个循环之间的迭代关系,程序不能识别这些依赖关系
- 依赖关系:数据依赖、循环依赖
private子句
- 出现在reduction子句中的参数不能出现在private
用private子句声明的私有变量的初始值在parallel块或parallel for块的开始处是未指定的,且在完成之后也是未指定的
- demo: for循环前的变量j和循环区域内的变量j其实是两个不同的变量
- 它不会继承同名共享变量的值
default子句
- default子句用来允许用户控制并行区域中变量的共享属性,
用法如下:default(shared|none)
- 使用shared时,缺省情况下,传入并行区域内的同名变量被
当做共享变量来处理,不会产生线程私有副本,除非使用
private等子句来指定某些变量为私有的才会产生副本。 - 如果使用none作为参数,那么线程中用到的变量必须显式指
定是共享变量还是私有变量,那些有明确定义的除外

shared子句
用来声明一个或多个变量是共享变量,
用法如下:shared(list)
注意的是:
在并行区域内使用共享变量时,如果存在写操作,必须对共享变量加以保护;
否则,不要轻易使用共享变量,尽量将共享变量的访问转化为私有变量的访问
概念总结


- parallel for 中缺省循环变量为私有作用域的权限大于default(none)或default(shared)的设置权限
实例代码
for循环串行代码:
#include <stdio.h>
int main(int argc, char *argv[]){
int i;
for (i=0; i<10; i++){
printf("i=%d\n",i);
}
printf("Finished.\n");
return 0;
}
并行代码:
#include <stdio.h>
#include <stdlib.h>
#include <omp.h>
int main(int argc, char *argv[]){
int i;
//用来指定执行之后的代码块的线程数目
int thread_count = strtol(argv[1],NULL,10);
# pragma omp parallel for num_threads(thread_count)
for (i=0; i<10; i++){
printf("i=%d\n",i);
}
printf("Finished.\n");
return 0;
}
编译:gcc −g −Wall −fopenmp −o omp_example omp_example .c
执行:. /omp_example 4 4个线程执行
HelloWorld代码
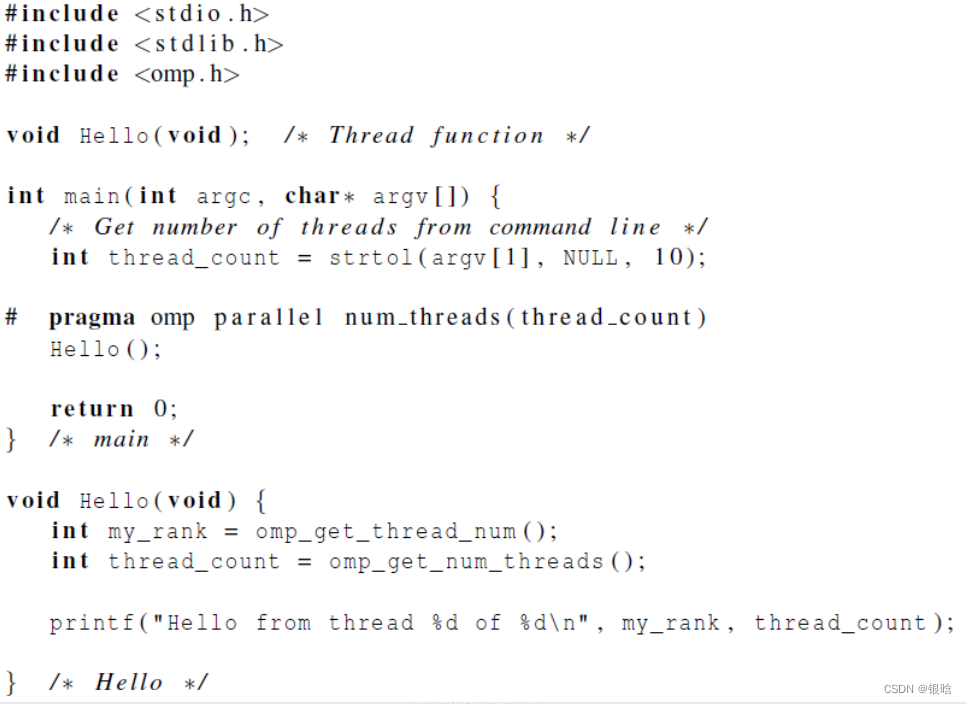
- 每个被启用的线程都执行Hello函数,并且当线程从Hello调用返回时,该线程就被终止。
- 先执行完的线程处于阻塞等待状态 (隐式路障)
- 在执行return语句时进程被终止
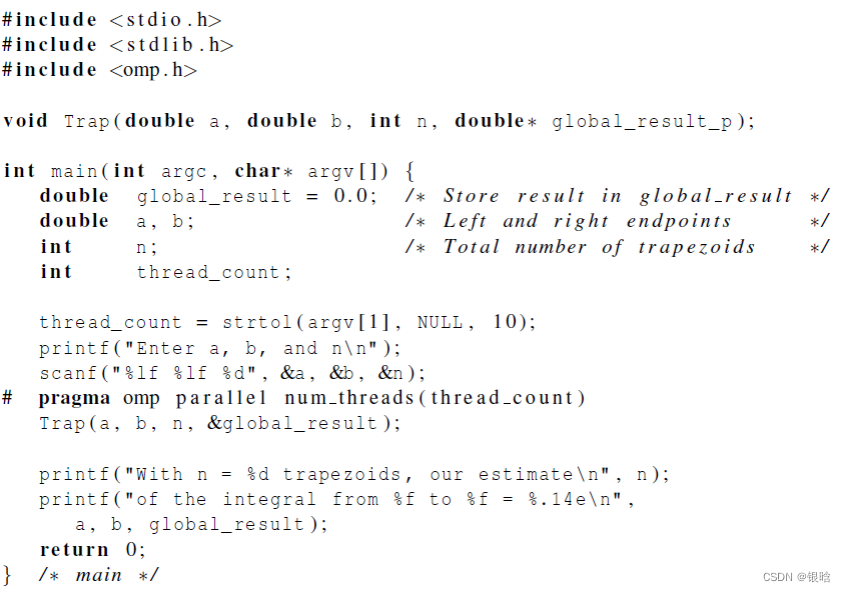
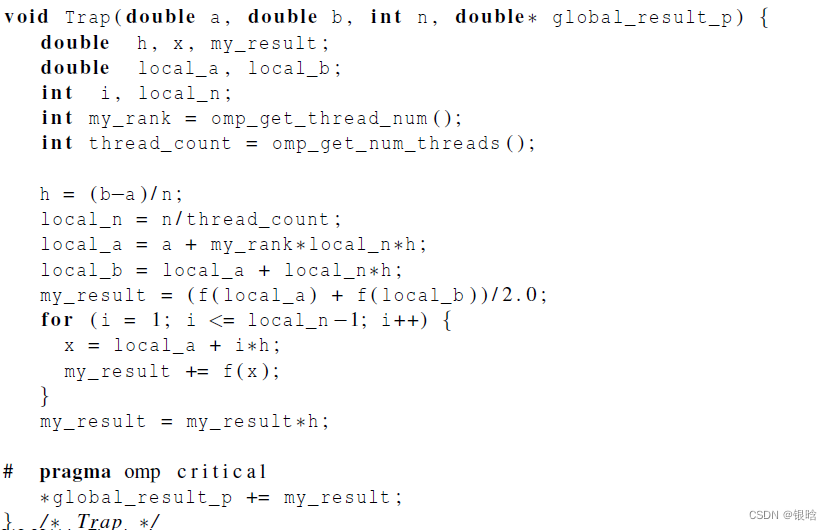
梯形积分
串行代码
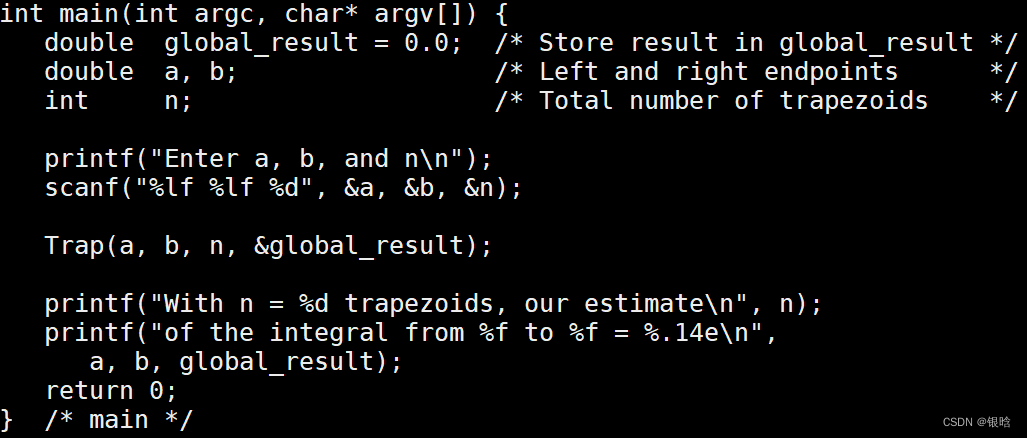
- 在trap函数中,每个线程获取它的编号,以及线程总数,然后确定以下的值:
1、梯形底长
2、给每个线程分配梯形数目
3、梯形的左右端点值
4、部分和my_result
5、将部分和增加到全局和global_result里
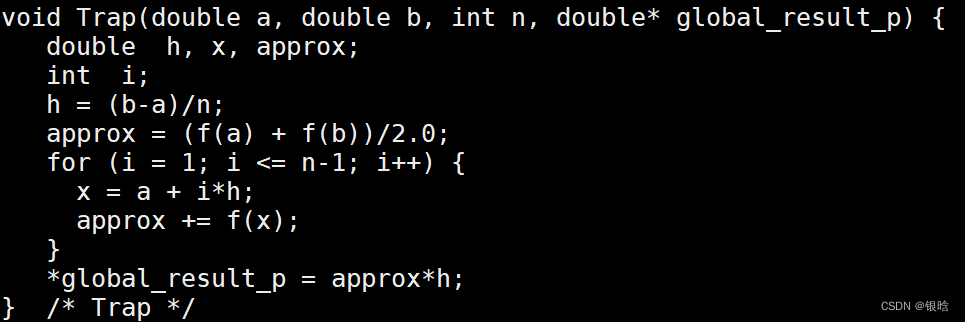
- 优化等效过程
// 利用规约子句,但是规约子句会有误差,运算不满足交换律结合律的时候,规约变量一定是float/double
global_result = 0.0 ;
#pragma omp parallel num_threads(thread_count) \
reduction(+: global_result)
global_result += Local_Trap(double a, double b, double n);
--------------------------------------------
//原代码,临界区会强制串行
global_result = 0.0;
#pragma omp parallel num_threads(thread_count)
{
double my_result = 0.0;
my_result += Local_Trap(double a, double b, double n);
# pragma omp critical
global_result += my_result;
}
- 给线程分配任务
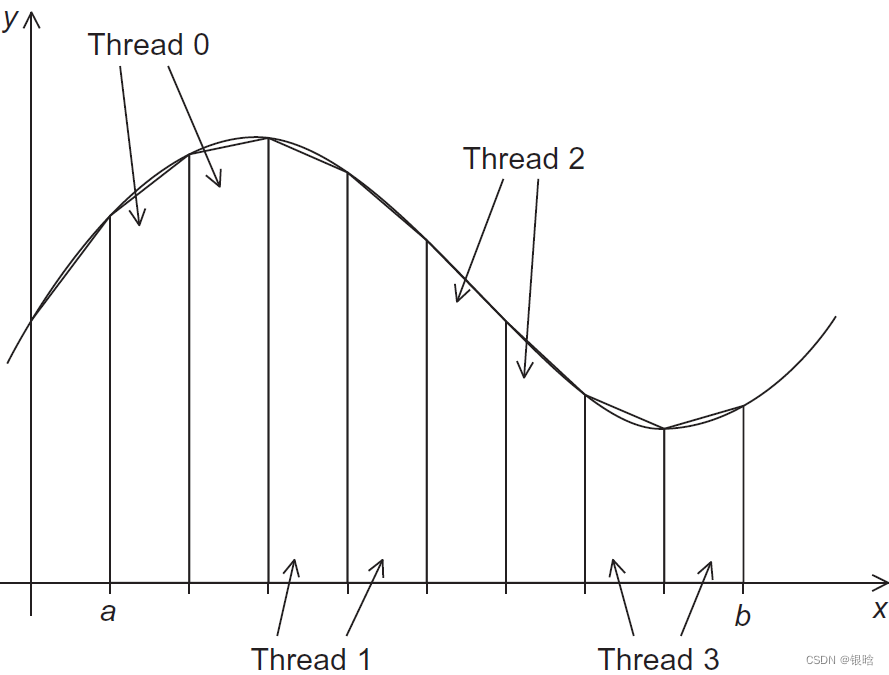
改并行
- 规约改进

临界区
- 引起竞争的代码,称为临界区
- 竞争条件:当多个线程都要访问共享变量或共享文件时,如果至少其中一个访问是更新操作,那么这种访问就可能导致某种错误。
- 因此需要一些机制来确保一次只有一个线程执行临界区,这种操作,我们称为互斥
后果:当两个或更多的线程加到global_result中,可能会出现不可预期的结果
- 解决方案:
- 忙等待
- 互斥量
- 信号量
忙等待
思想: 最小化临界区的执行次数
做法: 用一个flag(布尔变量)控制哪一个线程执行
- 因为处于忙等待的线程仍然在持续使用CPU,所忙等待不是限制临界区访问的最理想方法。
互斥量
互斥量是互斥锁的简称,它是一个特殊类型的变量,通过某些特殊类型的函数,互斥量可以用来限制每次只有一个线程能进入临界区
做法:
pthread_mutex_init(&head_mutex, NULL);//初始化
pthread_mutex_destroy(&head_mutex);//销毁
pthread_mutex_lock(&head_mutex);//获得临界区的访问权
pthread_mutex_unlock(&head_mutex);//退出临界区
critical子句
critical指令用在一段代码临界区之前,临界区在同一时间内只能有一个线程执行它,其他线程要执行临界区则需要排队来执行它。
#pragma omp critical[(name)] new-line
structured-block
# progma omp critical
global_result += my_result
梯形积分critical优化
- 低级的梯形积分,可以使用
for子句 + reduction子句优化
Π估计
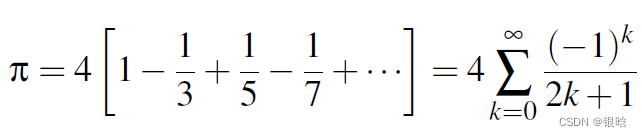
- 串行

- 并行
- 首先,原始想法存在循环依赖,for在循环,factor隔着循环变
- 请注意到 private(factor)这个语句,将检查因子factor私有化,消除循环依赖


奇偶交换排序
三个点:OpenMP实现奇偶排序,循环调度,环境变量
排序:

奇偶交换排序是冒泡排序的一个变种,该算法更适合并行化
- 串行函数实现:

- OpenMP并行实现(版本1):用两个 parallel for循环来实现奇偶
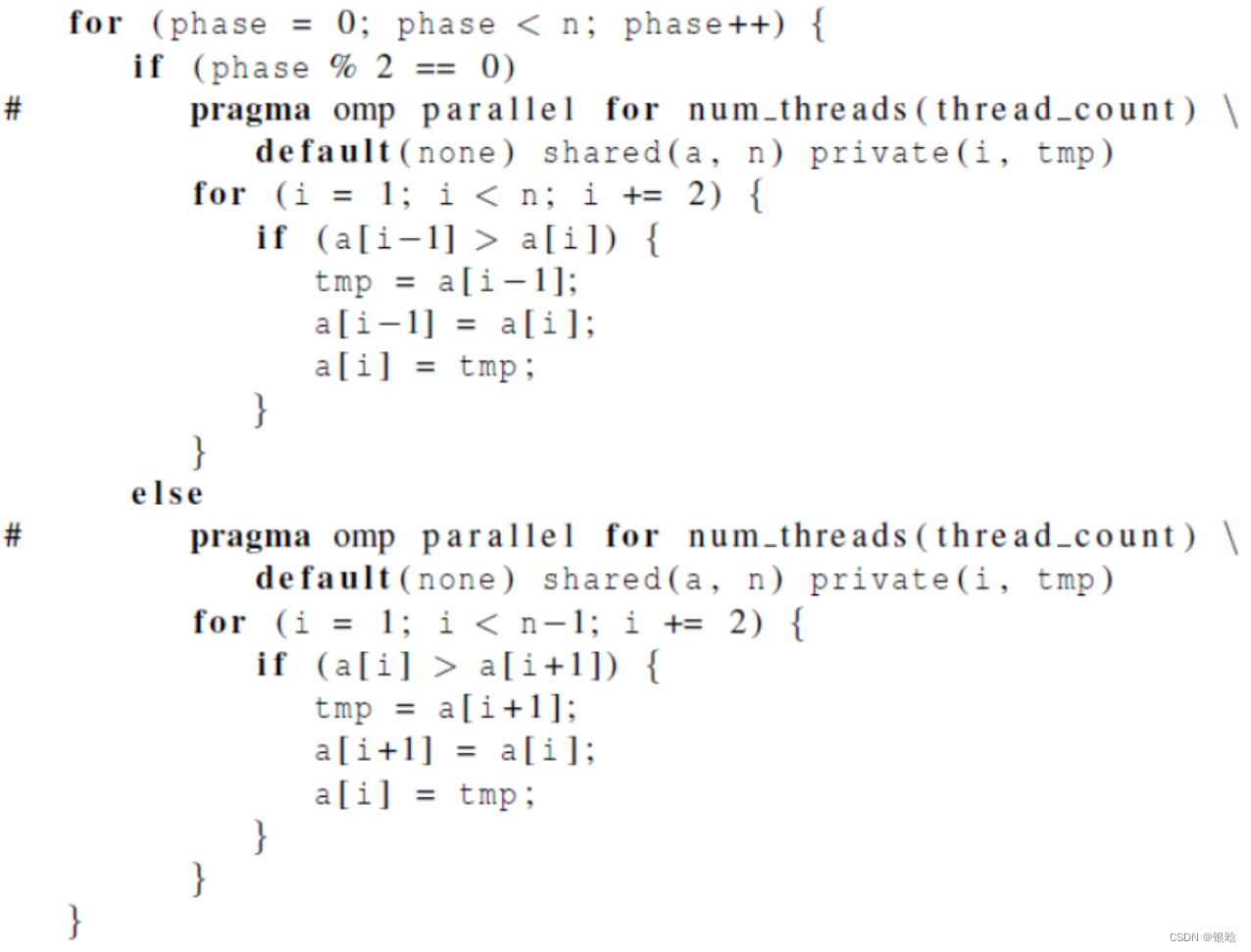
- OpenMP并行实现(版本2):用两个for循环来实现奇偶

double omp_get_wtime(void): 返回从某个特殊点所经过的时间,单位秒;(这个时间点在程序运行过程中必须是一致性)
- 两个方案对比:
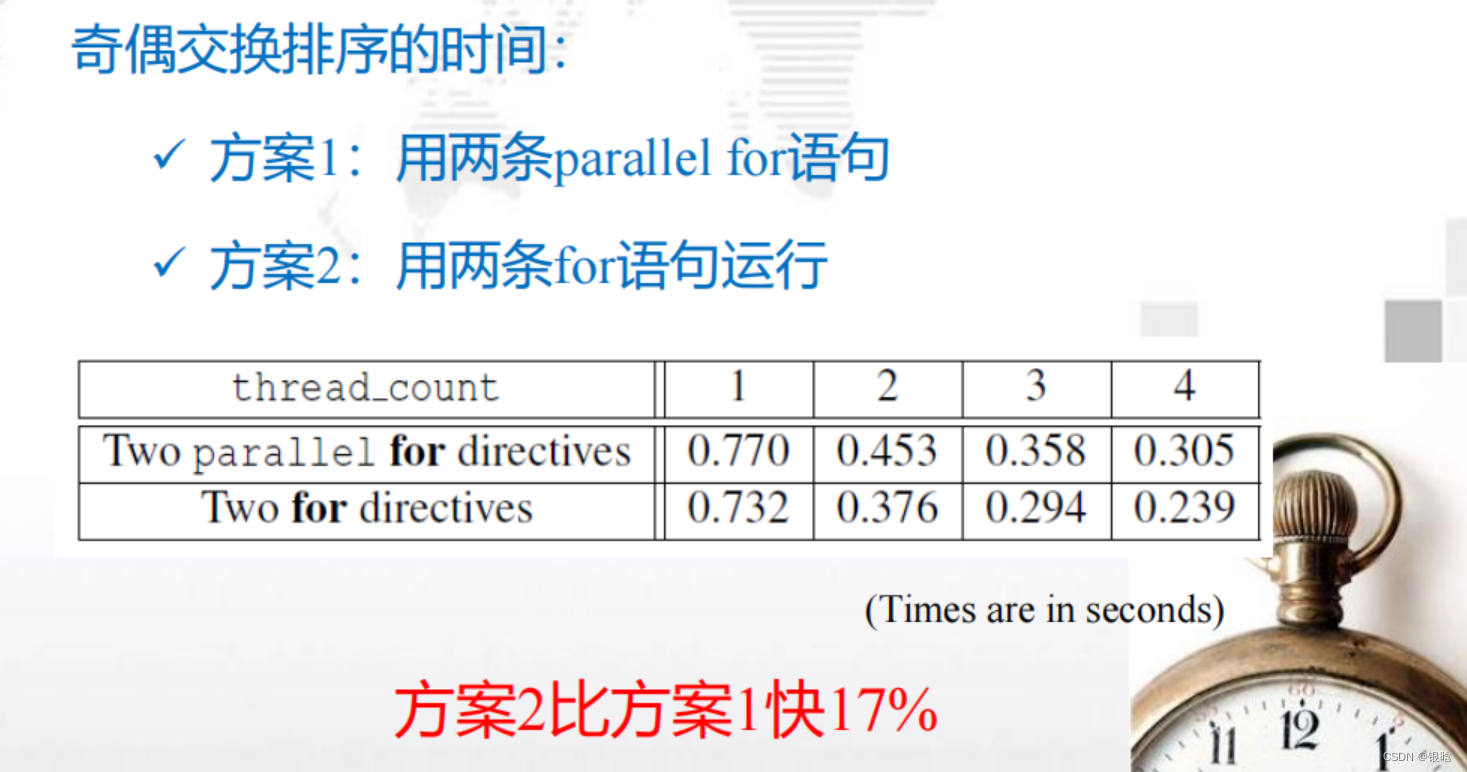
循环调度
OpenMP中,任务调度主要用于for循环的并行。当循环中每次迭代的计算量不等时,如果简单地给各个线程分配相同次数的迭代,则会造成各个线程计算负载不均衡,使得有些线程先执行完、有些后执行完,造成某些CPU核空闲,影响程序性能。
更好的方案是轮流分配线程的工作

schedule子句
OpenMP中,对for循环并行化的任务调度可使用schedule子句来实现。
schedule(<type[< chunksize >]>)
sum=0.0
#pragma omp paralell for num_threads(thread_count) \
reducion(+: sum) schedule(static,1)
type的类型:
-
static:迭代能够在
循环执行前分配给线程系统,以轮转的方式将任务分配给线程; -
dynamic 或 guided :迭代
循环执行时被分配给线程- 在循环执行时被分配给线程,因此在一个线程完成了它的当前迭代集合后,它能从运行时系统中请求更多 。
- 迭代被分成chunksize(默认为1)大小的连续迭代任务块
- 每个线程执行一块,执行完之后,将向系统请求另一块,新块大小会变化,越来越小
-
runtime:调度在
运行时决定- 当 schedule(runtime) 指定时 , 系统使用环境变量
- OMP_SCHEDULE 在 运 行 时 来 决 定 如 何 调 度 循 环 。
export OMP_SCHEDULE="static,1"- OMP_SCHEDULE可能会呈现任何能被static、dynamic或guided调度所使用的值。
- 当type参数类型为runtime时,
chunksize参数是非法的。
-
auto :编译器和运行时系统决定调度方式
-
块划分:chunksize是一个正整数,是块中的迭代次数 ,
一次分配一个线程几个数
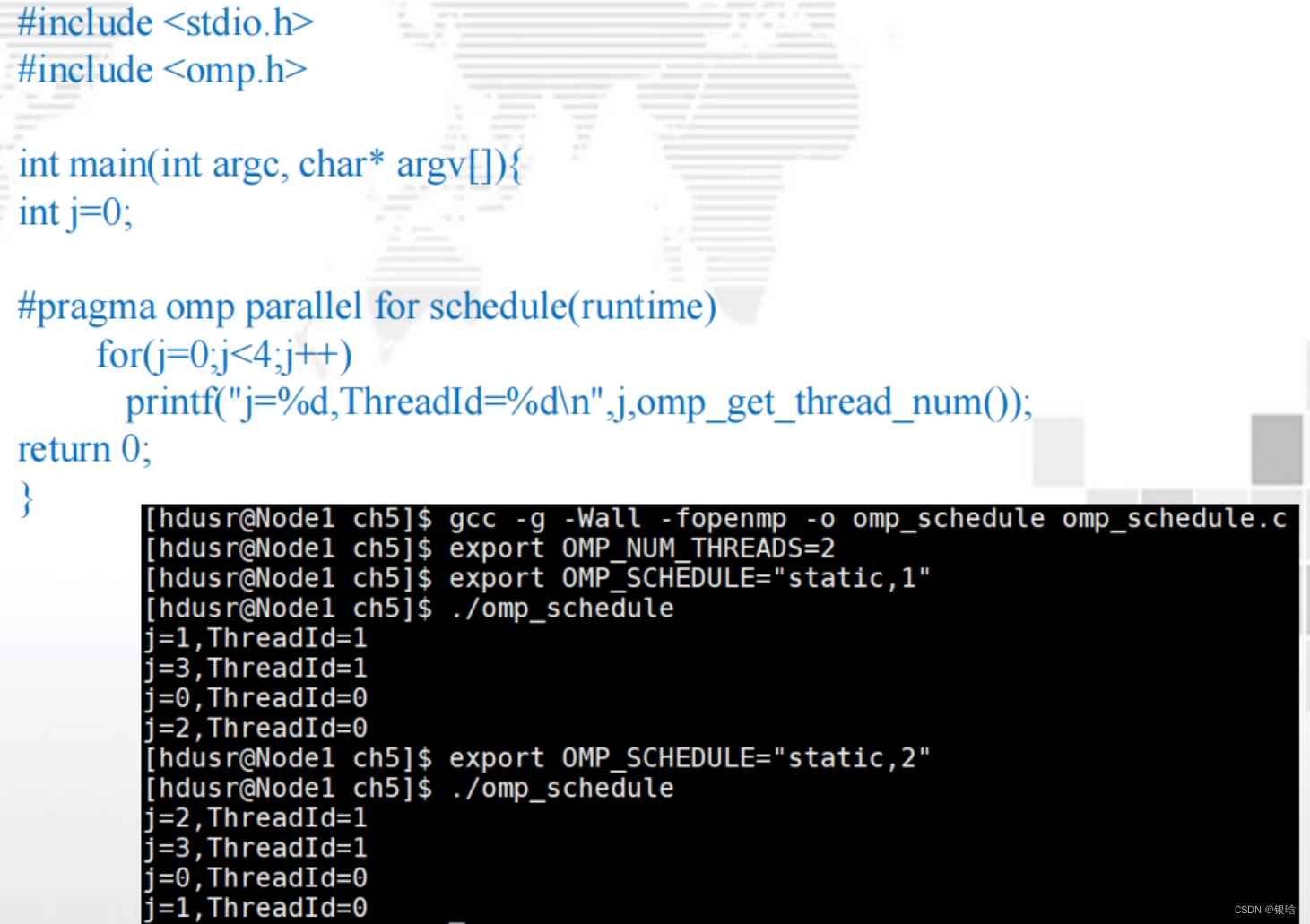
- 调度开销:
guided>dynamic>static- 如果我们断定默认的调度方式性能低下,那么我们会做大量的试验来寻找最优的调度方式和迭代次数。
环境变量
定义:环境变量是能够被运行时系统所访问的命名值,即它们在程序的环境中是可得的。
- Linux系统常见环境变量:PATH、HOME、SHELL
使用export命令设置环境变量值 export OMP_DYNAMIC=TRUE
OpenMP的环境变量主要有四个:
-
OMP_DYNAMIC
- FALSE:允许函数omp_set_num_thread()或者num_threads子句设置线程的数量;
- TRUE:那么运行时会根据系统资源等因素进行调整,一般而言,生成与CPU数量相等的线程就是最好的利用资源了。
-
OMP_NUM_THREADS
- OMP_NUM_THREADS环境变量主要用来设置parallel并行区域的默认线程数量。
- 必须OMP_DYNAMIC为FALSE时,OMP_NUM_THREADS环境变量才起作用。
指定线程数目的方法:
1. 不指定,即默认为处理器的核数;
2. 使用库函数omp_set_num_threads(int num)
3. 在#parama omp parallel num_threads(num)
4. 使用环境变量
$gcc –fopenmp -o 1 1.c
$OMP_NUM_THREADS =4
$export OMP_NUM_THREADS//设置环境变量值
-
OMP_NESTED
- OMP_NESTED为TURE时,将启动嵌套并行
- 可以使用omp_set_nested()函数用参数0调用来停止嵌套并行
-
OMP_SCHEDULE
- 主要是用来设置调度类型,只有在schedule子句的参数为runtime时才有效

- 主要是用来设置调度类型,只有在schedule子句的参数为runtime时才有效
内部控制变量
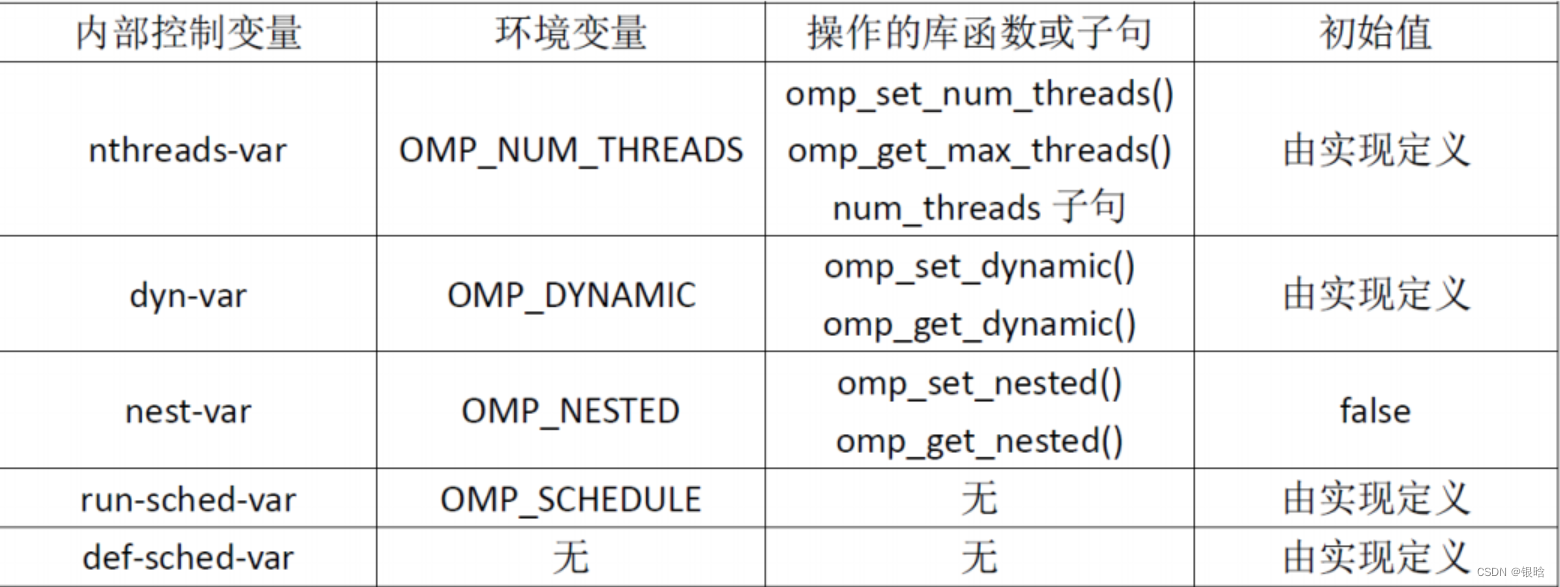
子句:
schedule:调度任务实现分配给线程任务的不同划分方式
函数:
omp_get_wtime():计算OpenMP并行程序花费时间
omp_set_num_thread(): 设置线程的数量
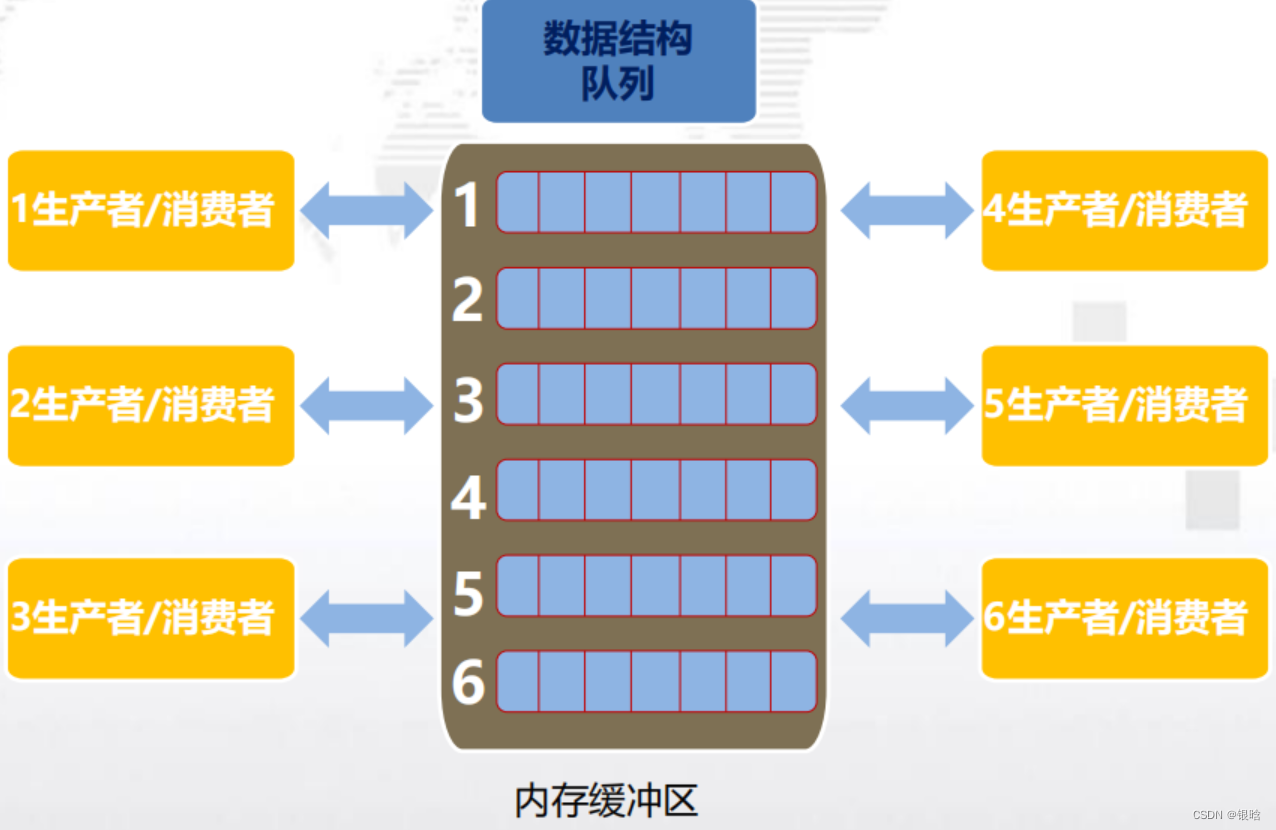
OpenMP实现生产者&消费者
生产者/消费者模型描述的是有一块缓冲区作为仓库,生产者可将产品放入仓库,消费者可以从仓库中取出产品,模型图如下所示:

- 三种关系:消费者和消费者;生产者和生产者;生产者和消费者;
- 两类角色:指的是生产者和消费者;
- 一个交易场所:交易场所指的是生产者和消费者之间进行数据交换的仓库,这块仓库相当于一个缓冲区,生产者负责把数据放入到缓冲区中,消费者负责把缓冲区中的数据取出来
队列
- 队列是一种抽象的数据结构,插入元素时将元素插入到队列的尾部,而读取元素时,队列头部的元素被返回并从队列中被移除(先进先出)
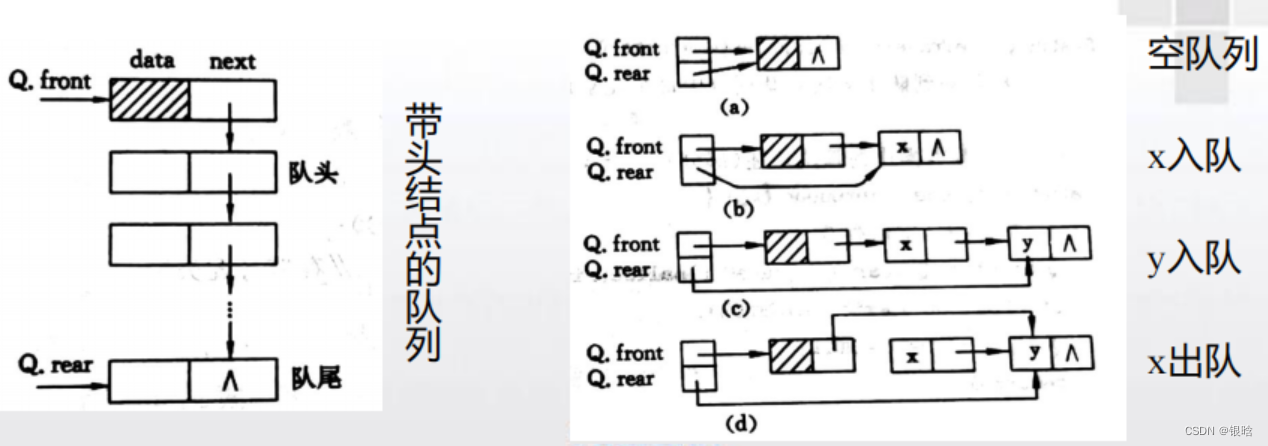
队列中的元素就是消费者
消息传递
生产者和消费者模型的另外一个应用:共享内存系统上实现多线程消息传递。
每一个线程有一个共享消息队列,当一个线程要向另外一个线程发送消息时,它将消息放入目标线程的消息队列中一个线程接收消息时,只需从它的消息队列的头部取出消息。
-
每个线程交替发送和接收消息,用户需要指定每个线程发送消息的数目。
-
当一个线程发送完所有消息后,该线程不断接收消息直到其他所有的线程都已完成,此时所有线程都结束了。
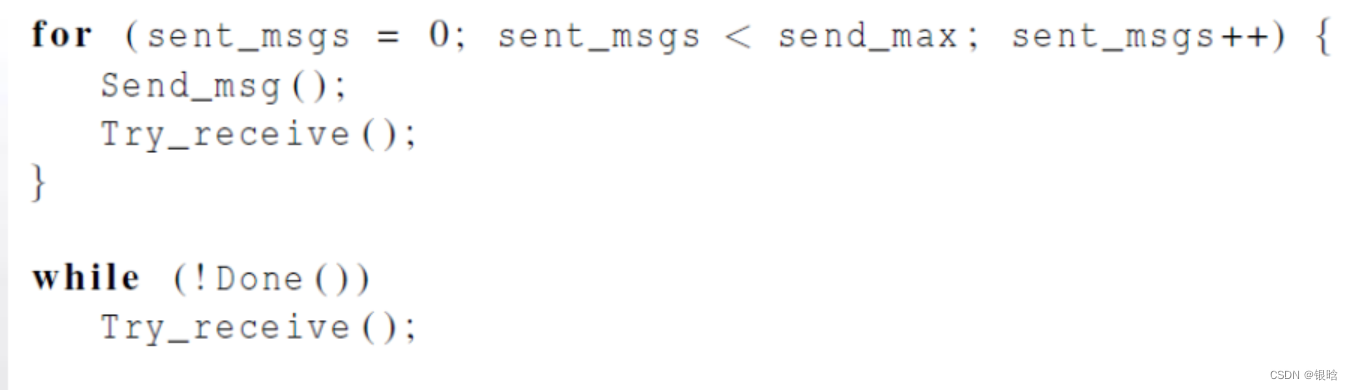
发送消息
注意:访问消息队列并将消息入队,可能是一个临界区
队尾指针:消息入队需要一个变量来跟踪队列的尾部- 如,使用一个单链表实现消息队列,链表的尾部对应队列尾部。然后,为了有效地进行入队操作,需要存储指向链表尾部的指针
- 当一条新消息入队时,需要检查和更新这个队尾指针
- 如果两个线程试图同时更新队尾指针,可能会丢失一条已经由其中一个线程入队的消息

接收消息
接收消息的临界区问题与发送消息有些不同。
- 只有消息队列的拥有者(即目标线程)可以从给定的消息队列中获取消息。
- 如果消息队列中至少有两条消息,只要每次只出队一条消息,那么出队操作和入队操作就不可能冲突。因此如果队列中至少有两条消息,通过跟踪队列的大小就可以避免临界区问题。
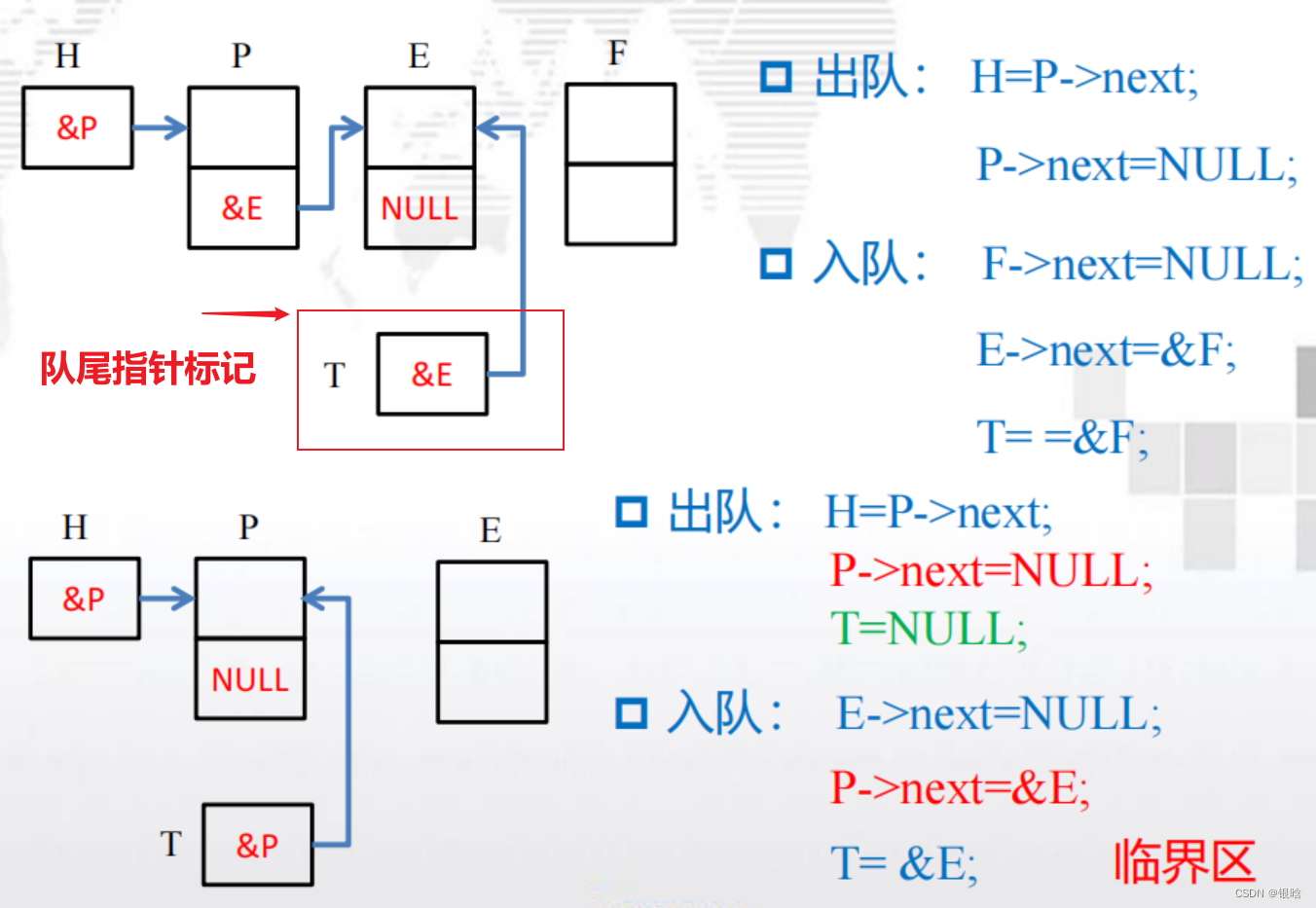

- 如何存储或计算队列大小queue_size?
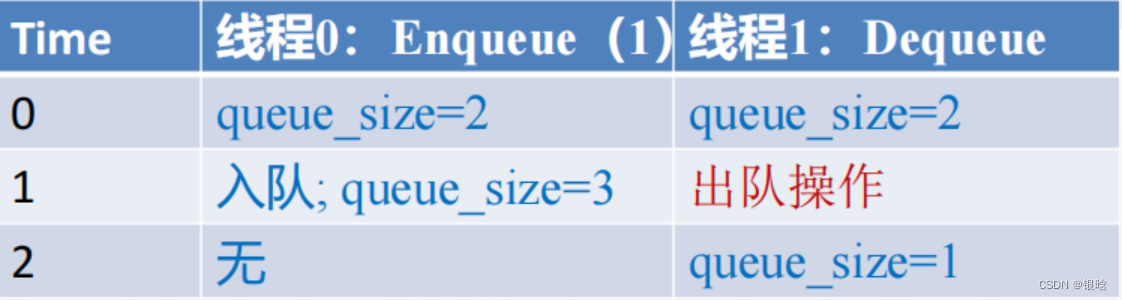
如果只使用一个变量来存储队列大小,那么对该变量的操作会形成临界区(有冲突)
如下:
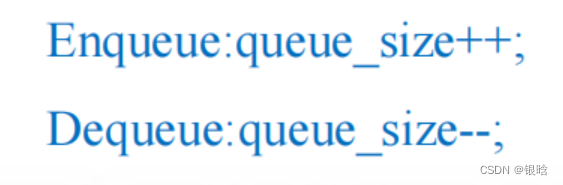
-
解决方案:
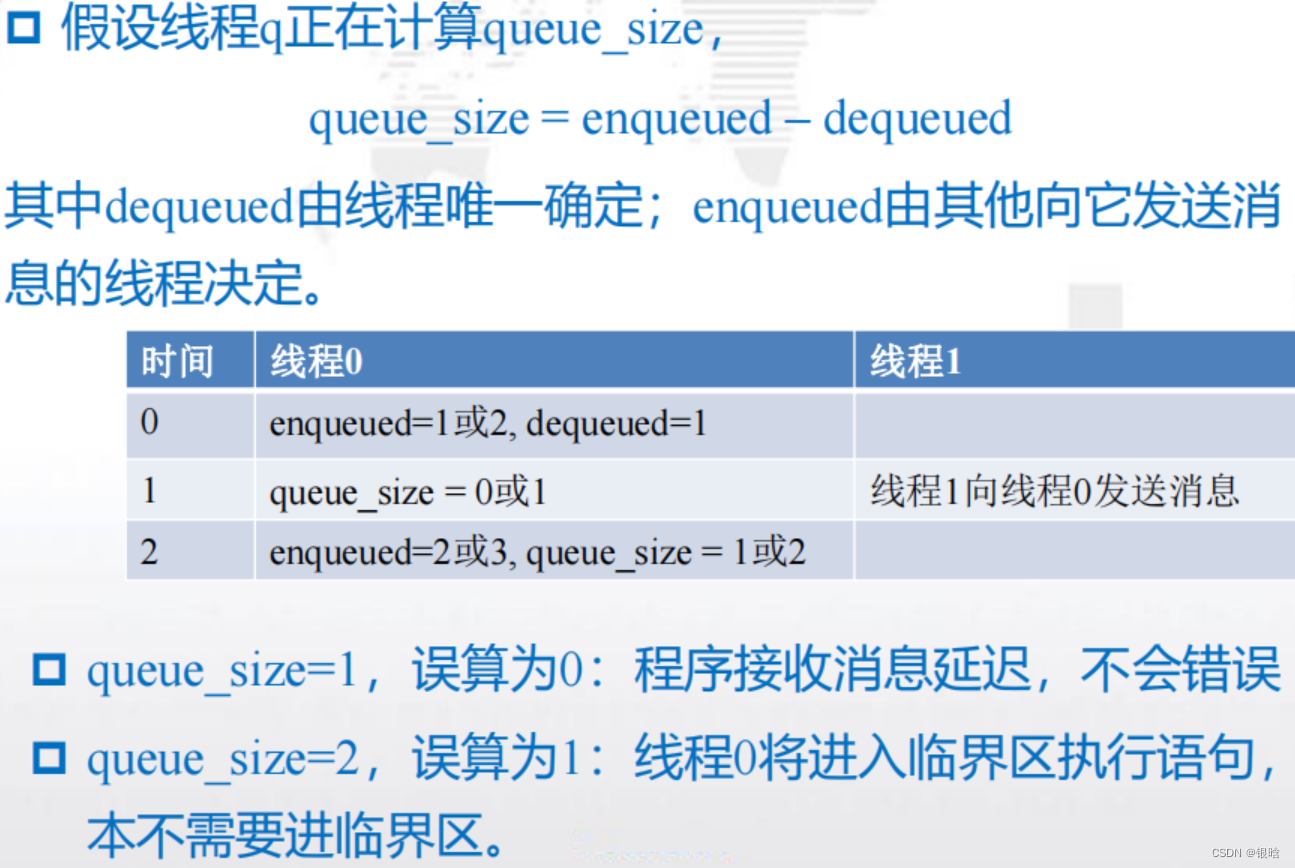
可以使用两个变量:enqueued和dequeued,那么队列中消
息的个数(队列的大小)就为queue_size = enqueued – dequeued- 唯一能够更新dequeued的线程是消息队列的拥有者。
- 对于enqueued,可以在一个线程使用enqueued计算队列大小的同时,另外一个线程可以更新enqueued.
终止检查
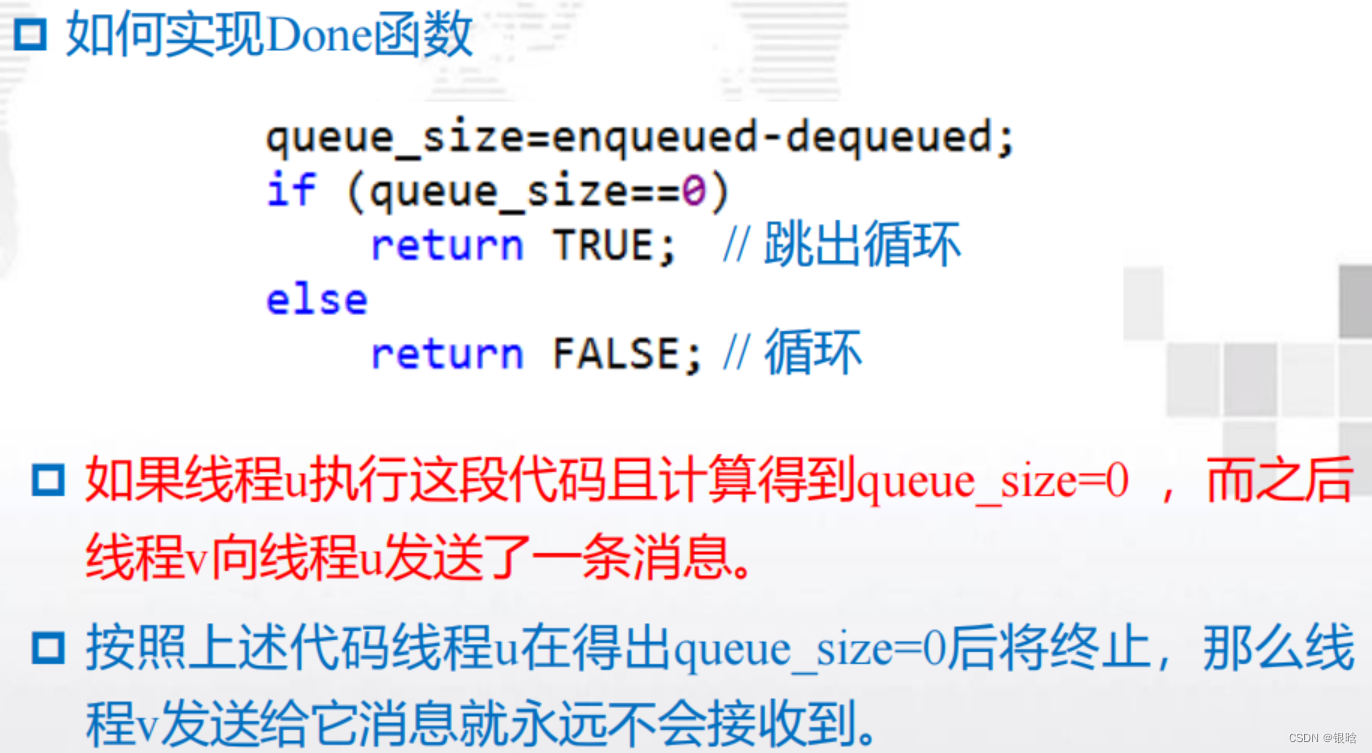
- 解决方案:
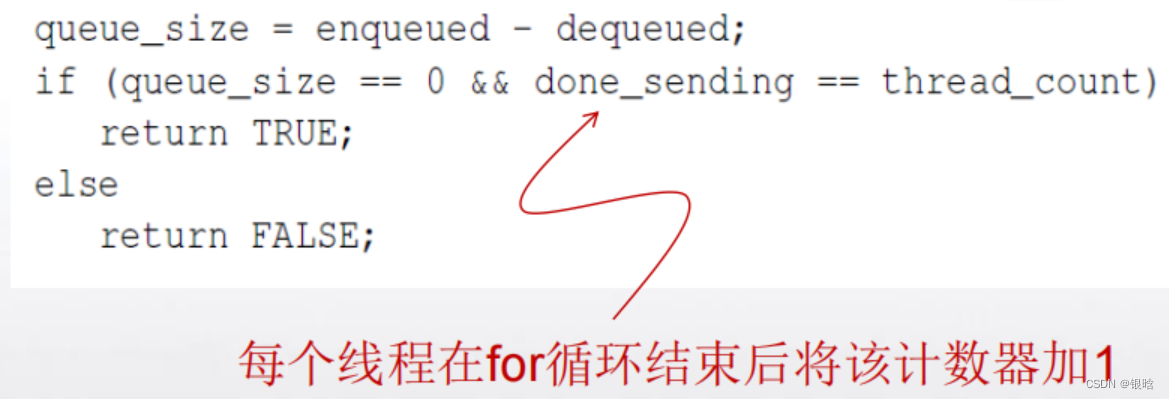
在我们的程序中,每个线程在执行完for循环后将不再发送任何消息。
可设置一个计数器done_sending,每个线程在for循环结束后将该计数器加1, Done的实现如下:
启动
- 当程序开始执行时,主线程将得到命令行参数并且分配一个消息队列的数组,每个线程对应着一个消息队列。
- 由于每个线程可以向其它任意的线程发送消息,即每个线程可以向任何一个消息队列插入一条消息,所以这个队列数组应该被所有的线程共享。
队列分配问题
问题:一个或多个线程可能在其它线程之前完成它的队列分配。那么完成分配的线程可能会试图开始向那些还没有完成队列分配的线程发送消息,这将导致程序崩溃。
必须确保任何一个线程都必须在所有线程都完成了队列分配后才开始发送消息
解决: 需要一个显式路障,使得当线程遇到路障时,它将被阻塞,直到组中所有的线程都达到这个路障。
- 隐式路障:OpenMP指令结束。
- 显式路障:OpenMP指令中间,如parallel块的中间。

- 阻塞:线程组中的线程都达到这个路障之后将接着往下执行。
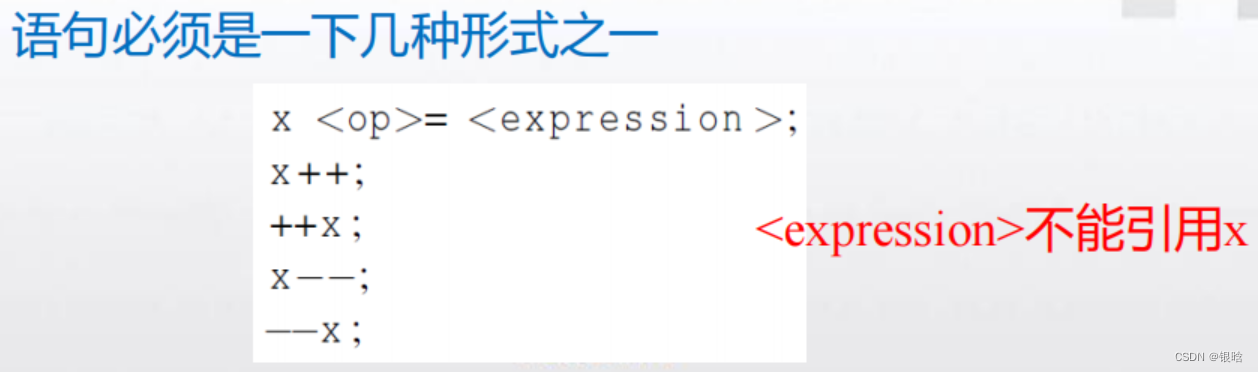
atomic
用来解决临界区的问题的
critical指令
atomic指令:只能保护由一条C语言赋值语句所形成的临界区。#pragma omp atomic
思想:
许多处理器提供专门的装载-修改-存储指令
使用这种专门的指令而不使用保护临界区的通用结构,可以更高效地保护临界区。
消息队列的结构:
1. 消息列表
2. 队尾指针
3. 队首指针
4. 入队消息的数目
5. 出队消息的数目
为了减少参数传递时复制的开销,最好使用指向结构体的指针数组来实现消息队列
一个数组,若其元素均为指针类型数据,称为指针数组。即指针数组中的每一个元素都相当于一个指针变量。
类型名 *数组名[数组长度]; 如int *p[4];



条件编译

互斥量 - 锁
- 锁机制:用于需要互斥的是某个数据结构而不是代码块的情况。
指令:
atomic指令: 实现互斥访问最快的方法。
critical指令:保护临界区,实现互斥访问。
函数:
void omp_init_lock(omp_lock_t*lock);//初始化锁
void omp_destroy_lock(omp_lock_t*lock)//销毁锁
void omp_set_lock(omp_lock_t*lock);//尝试获得锁
void omp_unset_lock(omp_lock_t*lock);//释放锁
临界区改进1
存在三个临界区:效率低下
- 被atomic指令保护的临界区、被critical指令保护的复合临界区
- 临界区争夺:复合临界区会使线程间强制互斥访问,使得程序的执行串行化
# pragma omp atomic
done_sending++
# pragma omp critical
/*q_p = msg_queues[dest]*/
Enqueue(q_p, my_rank, mesg);
#pragma omp critical
/* q_p = msg_queues[my_rank] */
Dequeue(q_p, &src, &mesg);
- 解决方案 : 命名的临界区
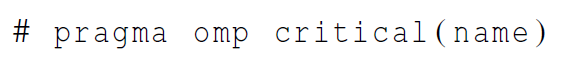
采用这种方式,两个用不同名字的critical指令保护的代码块就可以同时执行。


临界区改进2
锁
嵌套互斥结构可能会产生意料不到的结果
这段代码肯定会死锁:当一个线程试图进入第二个临界区时它将被永远阻塞
Critical & atomic & Lock
- atomic: 适用于代码块,单行代码的临界区;互斥访问最快
- 如果有多个atomic的临界区,应当用Critical或者锁
- Critical个atomic存在混合,使用命名的Critical
- Critical或者锁:使用于数据结构
关于互斥和锁:
1.同一个临界区要使用同一种机制的互斥机制,不应该混合
2.互斥执行不保证公平性
3.嵌套锁结构可能会产生死锁
MPI / OpenMP的编译命令
$gcc -g -Wall -fopenmp -o outputdir filename.c
$./outputdir
TSP问题
NP完全问题
- 穷举法——最优解(没有任何一个已知的算法可以比
穷举法更好地解决该问题) - 启发式方法——次优解。
方法:
- 深度优先遍历搜索(递归)
- 广度优先遍历搜索(递归)
- 函数调用(栈)
复习习题
第一章

- 高性能计算的概念
指通常使用很多处理器(作为单个机器的一部分)或者某一集群中组织的几台计算机(作为单个计算资源操作)的
计算系统和环境,执行一般个人电脑无法处理的大量资料与高速运算,其基本组成组件与个人电脑的概念无太大差异,但规格与性能则强大许多
- 高性能计算机的发展
电子管计算机 - 晶体管计算机 - 集成电路计算机 - 大规模集成电路计算机 - 异构计算机
天河二号 、神威太湖之光
- 高性能计算的应用
汽车制造(数值模拟、仿真模拟)、解码基因组、气象预测、航空航天
- 构建并行系统和编写并行程序的意义
并行系统:晶体管密度增加遇到瓶颈,在晶体管密度相同情况下,多核放在一个集成电路上,单核系统变成多核处理器CPU。
- 更块的处理器、不增加功耗、不增加热量、可靠
并行程序:在设计方案上提高运行速度
- 并行计算与分布式计算区别与联系(概念)
目的、应用场合、实现方式、实时性四个方面
- 并行方法的发展
- 请解释传统幵行计算框架MPI不大数据幵行计算模型MapReduce的共同点和区别
体系结构和容错性、硬件和扩展性、学习难度、应用场景


第二章
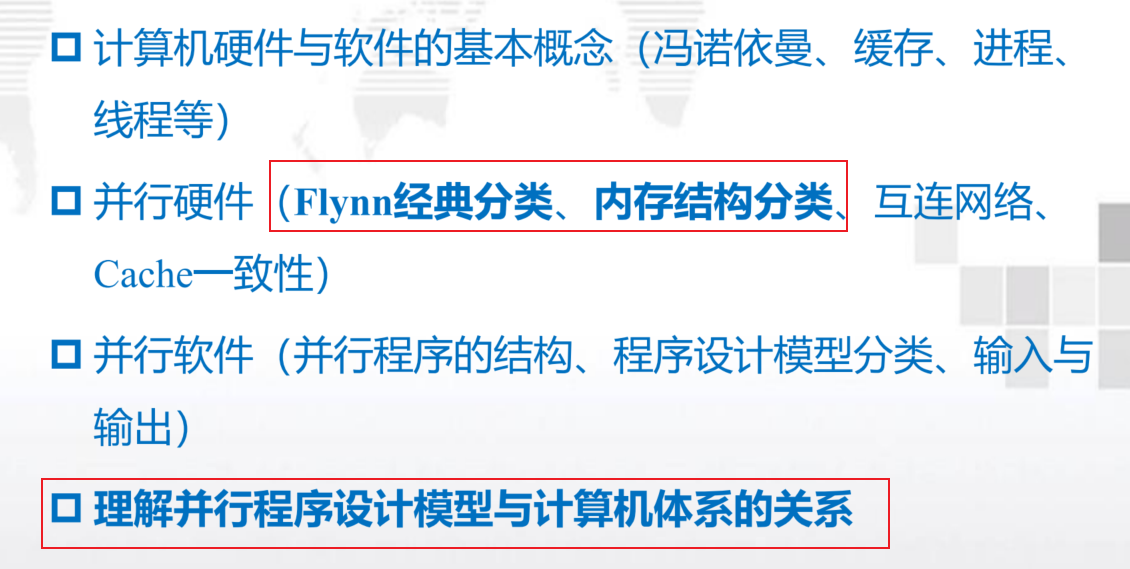
- 计算机硬件与软件的基本概念
冯诺伊曼计算机
缓存
进程
线程
- 并行硬件
Flynn经典分类
内存结构分类
互连网络
Cache一致性
- 并行软件
并行程序的结构
程序设计模型分类
输入与输出
- 并行程序设计模型和计算机系统之间的关系




第三章

- MPI 编译、运行命令
mpicc -g -Wall -o outputdir filename.c
mpiexec -n 10 ./filename
./filename
- 点对点通信函数(六个基本函数)
MPI初始化+结束
MPI_Init()
MPI_Finalize()
通信子:当前编号,总数,创建(mpi_type_struct_create)
MPI_Common_rank()
MPI_Common_size()
消息传递:Message-Passing Interface
MPI_Send()
MPI_Recv()
- 3+3
int MPI_Send(
void* msg_buf_p; send_buf : 发送哪些数据,从内存的哪个位置开始发送
int msg_size; count:发送数据的个数
MPI_DataType msg_type; dataType:发送的数据类型
int dest; 目的进程的进程号
int tag; 消息标志,如果进程短时间内发送了两条消息,用来区分
MPI_Common comm; 在哪些进程之间发送,发送范围
)
MPI_Send(void* buf, int count, datatype, int dest, int tag , comm )
- 3+1个参数
int MPI_Recv(
void* send_buf;
int count;
MPI_DataTYpe datatype;
int dest;
int tag;
MPI_Comm comm;
)
MPI_Resv(void* buf, int count, datatype, int dest, int tag , comm , MPI_STATUS_IGNORE);
- 集合通信函数(两组)
组通信、群通信
广播
MPI_Bocast()
规约
MPI_Reduce() :发送到缓存区过程中会进行计算
MPI_AllReduce() 广播+规约
散射
MPI_Scatter()
MPI_Gather()
MPI_AllGather() 所有进程都存着全局结果
- 性能评估
加速比 :S(n,p) = T(并行)/T(串行)
效率:S(n,p) / p
计时:MPI_Wtime()
同步:
程序安全: 不安全(死锁、缓存依赖),安全(按照一个先接受再发送,另一个先发送再接收)











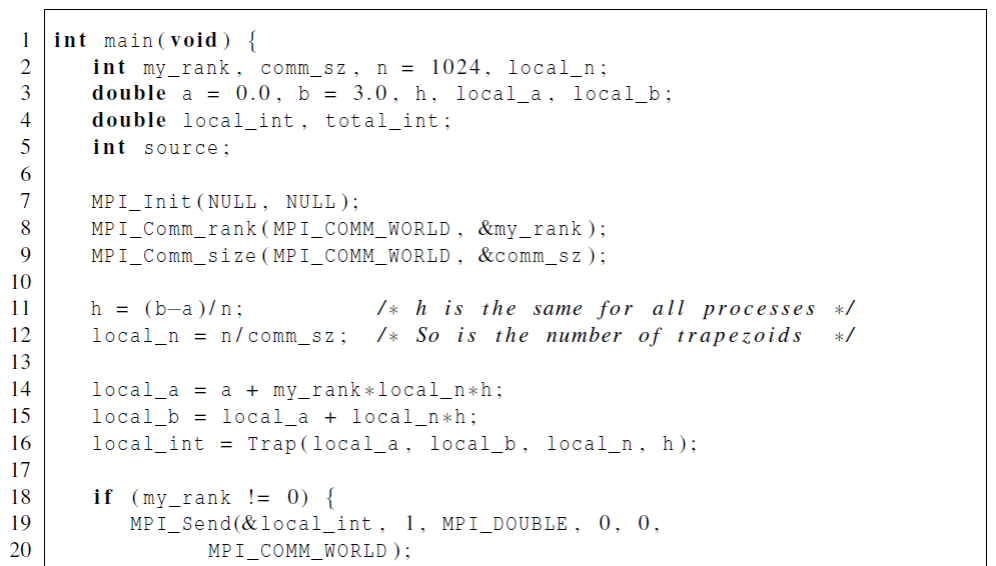


- 任务划分通式:
// n: 总任务数 , p是进程数
int comm_size = n / p;
int rest = n % p ;
int task_num
for(rank = 0 ; rank< thread_counts-1 ; rank++){
if(rank < rest){
task_num = comm_size +1;
first = rank * task_num
}else{
task = common_siz ;
first = rank * task_num + rest
}
last = first + task_num
}
/**
执行上述for循环结果:
pocess 0:(0,4) = 0 1 2 3 4
pocess 1:(4,8) = 5 6 7 8
pocess 2:(8,11) = 9 10 11 12
pocess 3:(11,14) = 11 12 13 14
*/




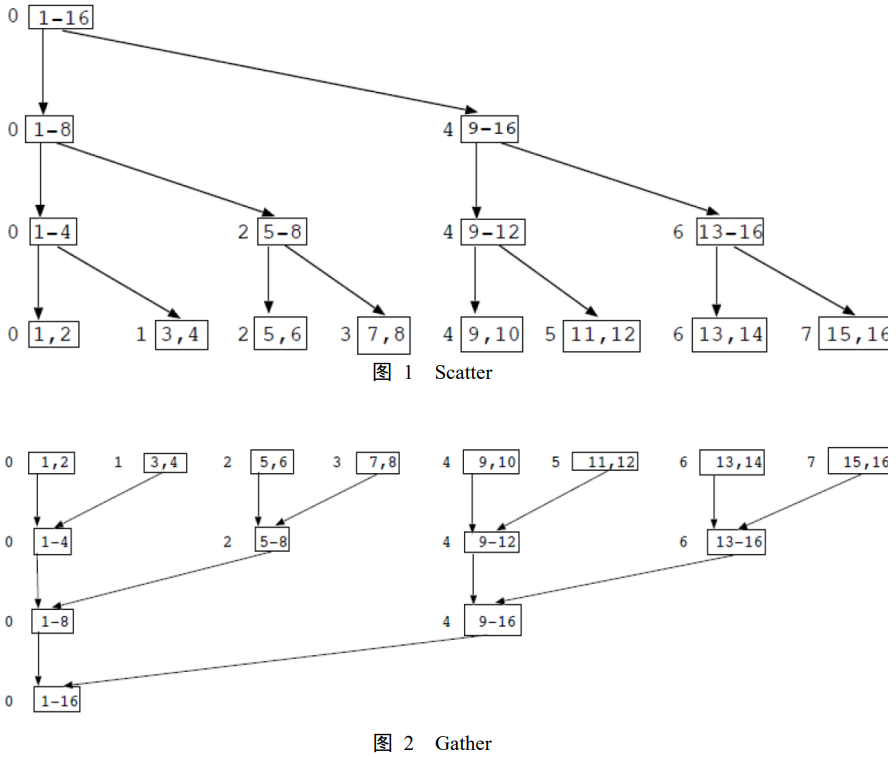
- 全局总和例子中的第一部分(每个核对分配给它的计算值求和),通常认为是数据并行的例子;
- 而第一个求全局总和例子的第二个部分(各个核将他们计算出的部分和发送给master核,master核将这些部分再累加求和),认为是任务并行。
- 第二个全局和例子中的第二部分(各个核使用树形结构累加他们的部分和),是数据并行的例子还是任务并行的例子?为什么?
该示例是任务和数据并行的组合。 在树结构全局求和的每个阶段,核心都在计算部分求和。 这可以看作是数据并行。 此外,在每个阶段,有两种类型的任务。 一些内核正在发送它们的总和,而一些内核正在接收另一个内核的部分总和。 这可以看作是任务并行。





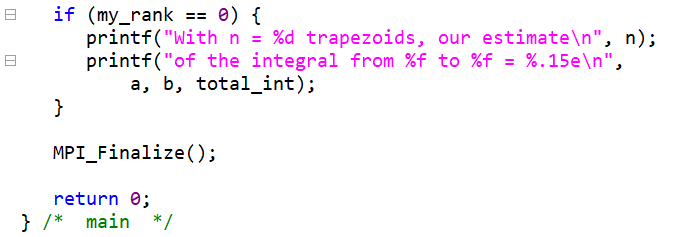
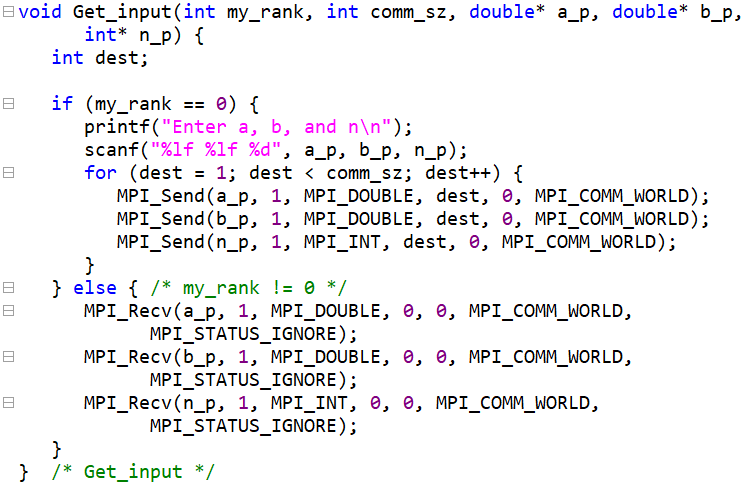
- Hello函数并行编程
MPI_Init(NULL,NULL);
MPI_Comm comm = MPI_COMM_WORLD;
MPI_Comm_rank(&comm);
MPI_Comm_size(&comm);
if(my_rank != 0){
sprintf(greeting,"%d of %d",my_rank,comm_sz)
MPI_Send(greeting, 1, MPI_CHAR, 0, 0, comm);
}else{
for(i=0;i<comm_sz;i++){
MPI_Recv(greeting, 2, MPI_CHAR, 0,0 ,comm, MPI_STATUS_IGNORE);
printf()
}
}
- 完整写出
MPI_Send()和MPI_Recv()
- 使用四个函数知道具体含义且会用
MPI_Reduce() 要求计算
MPI_Scatter()
MPI_Bcast()
MPI_Gather()
- 计时函数、安全通信
第四、五章
-
编程考:
Pi值计算和梯形积分 -
常见指令的考察:
- parallel :用在一个代码段之前,表示这段代码将被多个线程并行执行
- parallel for :使for循环的代码被多个线程并行执行
- for:使for循环被多个线程并行执行
- atomic:实现互斥访问最快的方法
- critical:保护临界区,实现互斥访问
- barrier:显式路障,线程组中的线程都达到这个路障,才能继续往下执行
-
子句
- num_threads: 指定执行之后的代码块的线程数目
- reduction:用来对一个或者多个参数条目指定一个操作符
- default:用来允许用户控制并行区域中变量的共享属性
- private:用来声明一个或者多个变量是私有变量
- shared:用来声明一个或者多个变量是共享变量
- schedule:调度任务实现分配给线程任务的不同划分方式
-
函数
- omp_get_num_threads() : 返回当前并行区域中的活动线程个数
- omp_get_thread_num():返回线程号
- omp_get_wtime():计算程序花费的时间
- omp_set_num_threads():设置线程的数量
- omp_init_lock(omp_lockt *lock):初始化锁
- omp_destroy_lock(omp_lock_t *lock):销毁锁
- omp_set_lock(omp_lock_t *lock):尝试获得锁
- omp_unset_lock(omp_lock_t *lock) :释放锁







- 去除循环依赖的方法:找出规律、通项公式






第二章补充作业
2.1
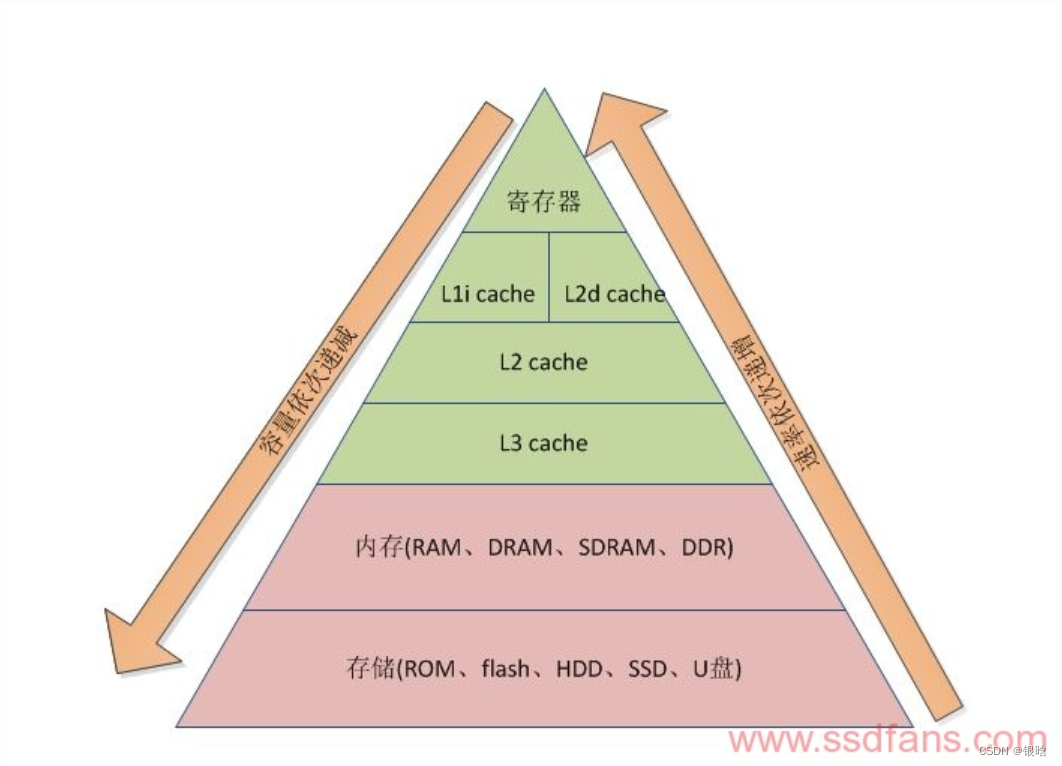
在梯形图中从上到下容量依次递增,速率依次递减,每字节的成本依次递减
2.2
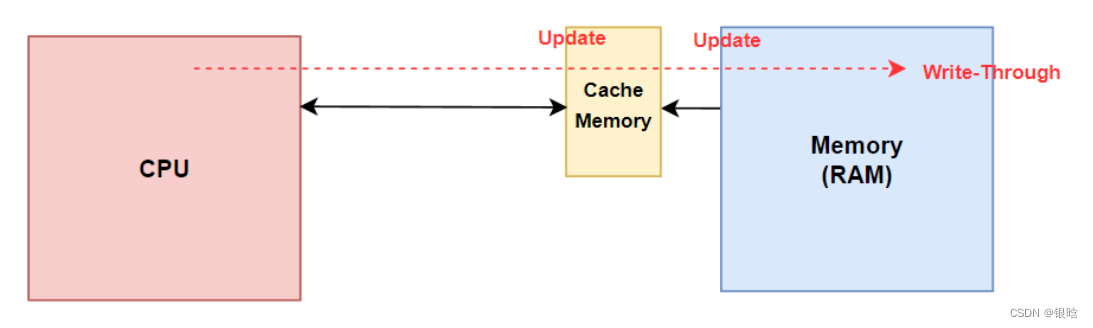
内存的数据被加载到Cache后,在某个时刻其要被写回内存,写内存有如下5种策略:写通(write-through)、写回(write-back)、写一次(write-once)、WC(write-combining)和UC(uncacheable)。

写通(write-through):
当cache写命中时,处理器对Cache写入的同时,将数据写入到内存中,内存的数据和Cache中的数据都是同步的,这种方式比较简单、可靠。但是处理每次对cache更新都需要对内存写操作,因此总线工作繁忙,内存的带宽被大大占用,因此运行速度会受到影响。
假设一段程序在频繁地修改一个局部变量,局部变量生存周期很短,而且其他进程/线程也用不到它,CPU依然会频繁地在Cache和内存之间交换数据,造成不必要的带宽损失。
当cache写未命中时,只有直接向主存写入了,但此时是否将修改过的主存块取到cache,写直达法却有两种选择。
一是取来并且为它分配一个位置,称为WTWA(Write–Through–with–Write–Allocate)。
另一种是不取称为WTNWA法(WriteThrough–with.NO-Write–Allocate)。
前 一种法保持了cache/主存的一致性,但操作复杂,而后一种方法操作简化,但命中率降低,内存的修改块只有在读未命中对cache 进行替换时,才有可能射到cache 。写通发保证了写cache与写主存同步进行,图中为写通法WTNWA法的流程图。
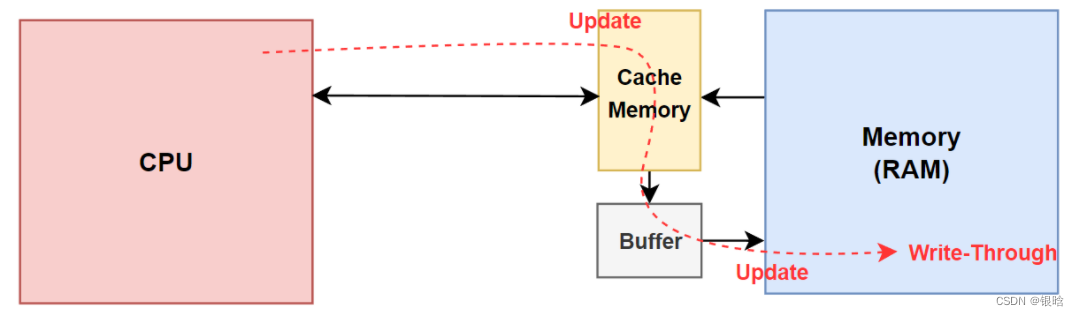
- 存在一个缓冲区,CPU写入高速缓存器的同时更新主存数据
















 2138
2138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









