






文章目录
4.4.2 时间注意力
在时间维度上,不同时间片之间的交通状况存在相关性,而且这些相关性在不同情况下也是变化的。同样地,我们使用注意力机制来自适应地给数据赋予不同的重要性:
E
=
V
e
⋅
σ
(
(
(
X
h
(
r
−
1
)
)
T
U
1
)
U
2
(
U
3
X
h
(
r
−
1
)
)
+
b
e
)
(
3
)
\mathbf{E}=\mathbf{V}_e\cdot\sigma(((\boldsymbol{\mathcal{X}}_h^{(r-1)})^T\mathbf{U}_1)\mathbf{U}_2(\mathbf{U}_3\boldsymbol{\mathcal{X}}_h^{(r-1)})+\mathbf{b}_e)\quad(3)
E=Ve⋅σ(((Xh(r−1))TU1)U2(U3Xh(r−1))+be)(3)
其中:
- X h ( r − 1 ) = ( X 1 , X 2 , ⋯ , X T r − 1 ) ∈ R N × C r − 1 × T r − 1 \mathcal{X}_h^{(r-1)} = (X_1, X_2, \cdots, X_{T_{r-1}}) \in \mathbb{R}^{N \times C_{r-1} \times T_{r-1}} Xh(r−1)=(X1,X2,⋯,XTr−1)∈RN×Cr−1×Tr−1 是第 r r r 个时空块的输入。
- C r − 1 C_{r-1} Cr−1 是第 r r r 层输入数据的通道数。
- T r − 1 T_{r-1} Tr−1 是第 r r r 层的时间维度长度。
- V e V_e Ve 和 b e ∈ R T r − 1 × T r − 1 b_e \in \mathbb{R}^{T_{r-1} \times T_{r-1}} be∈RTr−1×Tr−1 是可学习的参数。
- U 1 ∈ R N , U 2 ∈ R C r − 1 × N , U 3 ∈ R C r − 1 U_1 \in \mathbb{R}^N, U_2 \in \mathbb{R}^{C_{r-1} \times N}, U_3 \in \mathbb{R}^{C_{r-1}} U1∈RN,U2∈RCr−1×N,U3∈RCr−1 是可学习的权重矩阵。
- σ \sigma σ 是激活函数,通常使用 sigmoid 函数。
E
i
,
j
′
=
exp
(
E
i
,
j
)
∑
j
=
1
T
r
−
1
exp
(
E
i
,
j
)
(
4
)
\mathbf{E}_{i,j}'=\frac{\exp(\mathbf{E}_{\mathrm{i,j}})}{\sum_{j=1}^{T_{r-1}}\exp(\mathbf{E}_{\mathrm{i,j}})}\quad(4)
Ei,j′=∑j=1Tr−1exp(Ei,j)exp(Ei,j)(4)
其中
E
′
E'
E′ 是归一化后的时间注意力矩阵,使用 softmax 函数确保每个时间片的注意力权重之和为 1。矩阵
E
E
E 的元素
E
i
,
j
E_{i,j}
Ei,j 表示时间片
i
i
i 和时间片
j
j
j 之间的依赖强度。
输入数据的动态调整:
X
^
h
(
r
−
1
)
=
(
X
^
1
,
X
^
2
,
⋯
,
X
^
T
r
−
1
)
=
(
X
1
,
X
2
,
⋯
,
X
T
r
−
1
)
E
′
∈
R
N
×
C
r
−
1
×
T
r
−
1
\hat{\mathcal{X}}_{h}^{(r-1)} = (\hat{X}_1, \hat{X}_2, \cdots, \hat{X}_{T_{r-1}}) = (X_1, X_2, \cdots, X_{T_{r-1}})E' \in \mathbb{R}^{N \times C_{r-1} \times T_{r-1}}
X^h(r−1)=(X^1,X^2,⋯,X^Tr−1)=(X1,X2,⋯,XTr−1)E′∈RN×Cr−1×Tr−1
直接将归一化的时间注意力矩阵
E
′
E'
E′ 应用于输入数据,通过合并相关信息来动态调整输入数据。(根据时间注意力调整输入数据)
4.4.2 计算示例
使用另一个输入数据更好查看转置
原始数据:表示第一个节点不同时间步的特征
X
h
(
r
−
1
)
=
(
(
1
3
5
7
2
4
6
8
)
(
9
11
13
15
10
12
14
16
)
(
17
19
21
23
18
20
22
24
)
)
\mathcal{X}_h^{(r-1)} = \begin{pmatrix} \begin{pmatrix} 1 & 3 & 5 & 7 \\ 2 & 4 & 6 & 8 \end{pmatrix} \\ \begin{pmatrix} 9 & 11 & 13 & 15 \\ 10 & 12 & 14 & 16 \end{pmatrix} \\ \begin{pmatrix} 17 & 19 & 21 & 23 \\ 18 & 20 & 22 & 24 \end{pmatrix} \end{pmatrix}
Xh(r−1)=
(12345678)(910111213141516)(1718192021222324)
进行转置 [0, 1, 2] => [2, 1,0]:表示第一个时间步不同节点的特征
第 3 个维度的所有第一个元素变成第 1 个维度的所有第一个元素
X
h
(
r
−
1
)
T
=
(
(
1
9
17
2
10
18
)
(
3
11
19
4
12
20
)
(
5
13
21
6
14
22
)
(
7
15
23
8
16
24
)
)
\mathcal{X}_h^{(r-1)T} = \begin{pmatrix} \begin{pmatrix} 1 & 9 & 17 \\ 2 & 10 & 18 \end{pmatrix} \\ \begin{pmatrix} 3 & 11 & 19 \\ 4 & 12 & 20 \end{pmatrix} \\ \begin{pmatrix} 5 & 13 & 21 \\ 6 & 14 & 22 \end{pmatrix} \\ \begin{pmatrix} 7 & 15 & 23 \\ 8 & 16 & 24 \end{pmatrix} \end{pmatrix}
Xh(r−1)T=
(129101718)(3411121920)(5613142122)(7815162324)
假设可学习参数如下:
U
1
=
(
0.1
0.2
0.3
)
∈
R
N
U
2
=
(
0.1
0.2
0.3
0.4
0.5
0.6
)
∈
R
C
r
−
1
×
N
U
3
=
(
0.1
0.2
)
∈
R
C
r
−
1
V
e
=
(
1
0
0
0
0
1
0
0
0
0
1
0
0
0
0
1
)
∈
R
T
r
−
1
×
T
r
−
1
b
e
=
(
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1.1
1.2
1.3
1.4
1.5
1.6
)
∈
R
T
r
−
1
×
T
r
−
1
\begin{gathered} U_1 = \begin{pmatrix} 0.1 & 0.2 & 0.3 \end{pmatrix} \in \mathbb{R}^N \\[7pt] U_2 = \begin{pmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \end{pmatrix} \in \mathbb{R}^{C_{r-1} \times N} \\[7pt] U_3 = \begin{pmatrix} 0.1 & 0.2 \end{pmatrix} \in \mathbb{R}^{C_{r-1}} \\[7pt] V_e = \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix} \in \mathbb{R}^{T_{r-1} \times T_{r-1}} \\[7pt] b_e = \begin{pmatrix} 0.1 & 0.2 & 0.3 & 0.4 \\ 0.5 & 0.6 & 0.7 & 0.8 \\ 0.9 & 1.0 & 1.1 & 1.2 \\ 1.3 & 1.4 & 1.5 & 1.6 \end{pmatrix} \in \mathbb{R}^{T_{r-1} \times T_{r-1}} \end{gathered}
U1=(0.10.20.3)∈RNU2=(0.10.40.20.50.30.6)∈RCr−1×NU3=(0.10.2)∈RCr−1Ve=
1000010000100001
∈RTr−1×Tr−1be=
0.10.50.91.30.20.61.01.40.30.71.11.50.40.81.21.6
∈RTr−1×Tr−1
计算步骤:
- 计算 ( X h ( r − 1 ) ) T U 1 (\mathcal{X}_h^{(r-1)})^TU_1 (Xh(r−1))TU1:进行计算后维度变化 [ 4, 2, 3 ] => [ 4, 2 ]
( X h ( r − 1 ) ) T U 1 = ( ( 1 9 17 2 10 18 ) ⋅ ( 0.1 0.2 0.3 0.4 ) ( 3 11 19 4 12 20 ) ⋅ ( 0.1 0.2 0.3 0.4 ) ( 5 13 21 6 14 22 ) ⋅ ( 0.1 0.2 0.3 0.4 ) ( 7 15 23 8 16 24 ) ⋅ ( 0.1 0.2 0.3 0.4 ) ) (\mathcal{X}_h^{(r-1)})^T U_1 = \begin{pmatrix} \begin{pmatrix} 1 & 9 & 17 \\ 2 & 10 & 18 \end{pmatrix} \cdot \begin{pmatrix} 0.1 \\ 0.2 \\ 0.3 \\ 0.4 \end{pmatrix} \\ \begin{pmatrix} 3 & 11 & 19 \\ 4 & 12 & 20 \end{pmatrix} \cdot \begin{pmatrix} 0.1 \\ 0.2 \\ 0.3 \\ 0.4 \end{pmatrix} \\ \begin{pmatrix} 5 & 13 & 21 \\ 6 & 14 & 22 \end{pmatrix} \cdot \begin{pmatrix} 0.1 \\ 0.2 \\ 0.3 \\ 0.4 \end{pmatrix} \\ \begin{pmatrix} 7 & 15 & 23 \\ 8 & 16 & 24 \end{pmatrix} \cdot \begin{pmatrix} 0.1 \\ 0.2 \\ 0.3 \\ 0.4 \end{pmatrix} \end{pmatrix} (Xh(r−1))TU1= (129101718)⋅ 0.10.20.30.4 (3411121920)⋅ 0.10.20.30.4 (5613142122)⋅ 0.10.20.30.4 (7815162324)⋅ 0.10.20.30.4
- 结果为
( X h ( r − 1 ) ) T U 1 = ( 7.0 7.6 8.2 8.8 9.4 10.0 10.6 11.2 ) (\mathcal{X}_h^{(r-1)})^T U_1 = \begin{pmatrix} 7.0 & 7.6 \\ 8.2 & 8.8 \\ 9.4 & 10.0 \\ 10.6 & 11.2 \end{pmatrix} (Xh(r−1))TU1= 7.08.29.410.67.68.810.011.2
- 计算 ( ( X h ( r − 1 ) ) T U 1 ) U 2 ((\mathcal{X}_h^{(r-1)})^TU_1)U_2 ((Xh(r−1))TU1)U2:
( ( X h ( r − 1 ) ) T U 1 ) U 2 = ( 7.0 7.6 8.2 8.8 9.4 10.0 10.6 11.2 ) ⋅ ( 0.1 0.2 0.3 0.4 0.5 0.6 ) ((\mathcal{X}_h^{(r-1)})^T U_1) U_2 = \begin{pmatrix} 7.0 & 7.6 \\ 8.2 & 8.8 \\ 9.4 & 10.0 \\ 10.6 & 11.2 \end{pmatrix} \cdot \begin{pmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \end{pmatrix} ((Xh(r−1))TU1)U2= 7.08.29.410.67.68.810.011.2 ⋅(0.10.40.20.50.30.6)
- 结果为
( ( X h ( r − 1 ) ) T U 1 ) U 2 = ( 3.74 5.2 6.66 4.34 6.04 7.74 4.94 6.88 8.82 5.54 7.72 9.9 ) ((\mathcal{X}_h^{(r-1)})^T U_1) U_2 = \begin{pmatrix} 3.74 & 5.2 & 6.66 \\ 4.34 & 6.04 & 7.74 \\ 4.94 & 6.88 & 8.82 \\ 5.54 & 7.72 & 9.9 \end{pmatrix} ((Xh(r−1))TU1)U2= 3.744.344.945.545.26.046.887.726.667.748.829.9
- 计算 U 3 X h ( r − 1 ) U_{3}\mathcal{X}_{h}^{(r-1)} U3Xh(r−1):
U 3 X h ( r − 1 ) = ( ( 0.1 0.2 ) ⋅ ( 1 3 5 7 2 4 6 8 ) ( 0.1 0.2 ) ⋅ ( 9 11 13 15 10 12 14 16 ) ( 0.1 0.2 ) ⋅ ( 17 19 21 23 18 20 22 24 ) ) U_{3}\mathcal{X}_{h}^{(r-1)} = \begin{pmatrix} \begin{pmatrix} 0.1 & 0.2 \end{pmatrix} \cdot \begin{pmatrix} 1 & 3 & 5 & 7 \\ 2 & 4 & 6 & 8 \end{pmatrix} \\ \begin{pmatrix} 0.1 & 0.2 \end{pmatrix} \cdot \begin{pmatrix} 9 & 11 & 13 & 15 \\ 10 & 12 & 14 & 16 \end{pmatrix} \\ \begin{pmatrix} 0.1 & 0.2 \end{pmatrix} \cdot \begin{pmatrix} 17 & 19 & 21 & 23 \\ 18 & 20 & 22 & 24 \end{pmatrix} \end{pmatrix} U3Xh(r−1)= (0.10.2)⋅(12345678)(0.10.2)⋅(910111213141516)(0.10.2)⋅(1718192021222324)
- 结果为
U
3
X
h
(
r
−
1
)
=
(
(
0.5
1.1
1.7
2.3
)
(
2.9
3.5
4.1
4.7
)
(
5.3
5.9
6.5
7.1
)
)
U_{3} \mathcal{X}_{h}^{(r-1)} = \begin{pmatrix} \begin{pmatrix} 0.5 & 1.1 & 1.7 & 2.3 \end{pmatrix} \\ \begin{pmatrix} 2.9 & 3.5 & 4.1 & 4.7 \end{pmatrix} \\ \begin{pmatrix} 5.3 & 5.9 & 6.5 & 7.1 \end{pmatrix} \end{pmatrix}
U3Xh(r−1)=
(0.51.11.72.3)(2.93.54.14.7)(5.35.96.57.1)
4. 计算
(
(
X
h
(
r
−
1
)
)
T
U
1
)
U
2
(
U
3
X
h
(
r
−
1
)
)
((\mathcal{X}_h^{(r-1)})^TU_1)U_2(U_3\mathcal{X}_h^{(r-1)})
((Xh(r−1))TU1)U2(U3Xh(r−1)):
( ( X h ( r − 1 ) ) T U 1 ) U 2 ( U 3 X h ( r − 1 ) ) = ( 3.74 5.2 6.66 4.34 6.04 7.74 4.94 6.88 8.82 5.54 7.72 9.9 ) ⋅ ( 0.5 1.1 1.7 2.3 2.9 3.5 4.1 4.7 5.3 5.9 6.5 7.1 ) ((\mathcal{X}_h^{(r-1)})^T U_1) U_2 (U_3 \mathcal{X}_h^{(r-1)}) = \begin{pmatrix} 3.74 & 5.2 & 6.66 \\ 4.34 & 6.04 & 7.74 \\ 4.94 & 6.88 & 8.82 \\ 5.54 & 7.72 & 9.9 \end{pmatrix} \cdot \begin{pmatrix} 0.5 & 1.1 & 1.7 & 2.3 \\ 2.9 & 3.5 & 4.1 & 4.7 \\ 5.3 & 5.9 & 6.5 & 7.1 \end{pmatrix} ((Xh(r−1))TU1)U2(U3Xh(r−1))= 3.744.344.945.545.26.046.887.726.667.748.829.9 ⋅ 0.52.95.31.13.55.91.74.16.52.34.77.1
- 结果为
( ( X h ( r − 1 ) ) T U 1 ) U 2 ( U 3 X h ( r − 1 ) ) = ( 52.248 61.608 70.968 80.328 62.828 74.308 85.788 97.268 73.408 87.008 100.608 114.208 83.988 99.708 115.428 131.148 ) ((\mathcal{X}_h^{(r-1)})^TU_1)U_2(U_3\mathcal{X}_h^{(r-1)}) = \begin{pmatrix} 52.248 & 61.608 & 70.968 & 80.328 \\ 62.828 & 74.308 & 85.788 & 97.268 \\ 73.408 & 87.008 & 100.608 & 114.208 \\ 83.988 & 99.708 & 115.428 & 131.148 \end{pmatrix} ((Xh(r−1))TU1)U2(U3Xh(r−1))= 52.24862.82873.40883.98861.60874.30887.00899.70870.96885.788100.608115.42880.32897.268114.208131.148
[!note]+ 怎么来解释这个时间注意力
通过 E = V e ⋅ σ ( ( ( X h ( r − 1 ) ) T U 1 ) U 2 ( U 3 X h ( r − 1 ) ) + b e ) \mathbf{E}=\mathbf{V}_e\cdot\sigma(((\boldsymbol{\mathcal{X}}_h^{(r-1)})^T\mathbf{U}_1)\mathbf{U}_2(\mathbf{U}_3\boldsymbol{\mathcal{X}}_h^{(r-1)})+\mathbf{b}_e) E=Ve⋅σ(((Xh(r−1))TU1)U2(U3Xh(r−1))+be) 的一系列操作,目的是生成一个 T r − 1 × T r − 1 T_{r-1}\times T_{r-1} Tr−1×Tr−1 的矩阵,将各个时间步的各节点综合通道特征关联起来
E = ( E 1 , 1 E 1 , 2 E 1 , 3 E 1 , 4 E 2 , 1 E 2 , 2 E 2 , 3 E 2 , 4 E 3 , 1 E 3 , 2 E 3 , 3 E 3 , 4 E 4 , 1 E 4 , 2 E 4 , 3 E 4 , 4 ) E=\begin{pmatrix}E_{1,1}&E_{1,2}&E_{1,3}&E_{1,4}\\E_{2,1}&E_{2,2}&E_{2,3}&E_{2,4}\\E_{3,1}&E_{3,2}&E_{3,3}&E_{3,4}\\E_{4,1}&E_{4,2}&E_{4,3}&E_{4,4}\end{pmatrix} E= E1,1E2,1E3,1E4,1E1,2E2,2E3,2E4,2E1,3E2,3E3,3E4,3E1,4E2,4E3,4E4,4 计算过程解析:
- 节点特征提取 ( X h ( r − 1 ) ) T U 1 (\mathcal{X}_h^{(r-1)})^TU_1 (Xh(r−1))TU1:
- X h ( r − 1 ) ∈ R N × C r − 1 × T r − 1 \mathcal{X}_{h}^{(r-1)} \in \mathbb{R}^{N \times C_{r-1} \times T_{r-1}} Xh(r−1)∈RN×Cr−1×Tr−1 是输入数据。
- U 1 ∈ R N U_1 \in \mathbb{R}^N U1∈RN 是用于节点特征提取的权重。
- 通过 ( X h ( r − 1 ) ) T U 1 (\mathcal{X}_h^{(r-1)})^TU_1 (Xh(r−1))TU1,我们对节点维度进行加权求和,得到每个时间步在不同通道上的综合节点特征。即在每个时间步上,将各通道不同节点的信息汇总到一起,生成一个特征表示。
- 通道融合 ( ( X h ( r − 1 ) ) T U 1 ) U 2 ((\mathcal{X}_h^{(r-1)})^TU_1)U_2 ((Xh(r−1))TU1)U2:
- U 2 ∈ R C r − 1 × N U_2 \in \mathbb{R}^{C_{r-1} \times N} U2∈RCr−1×N 是用于通道融合的权重。
- 将节点特征表示与 U 2 U_2 U2 相乘,融合不同通道的信息,生成每个时间步在不同节点上的综合通道特征。将压缩后的节点特征与通道特征结合起来,生成新的各节点综合通道特征表示。
- 通道特征提取 U 3 X h ( r − 1 ) U_{3}\mathcal{X}_{h}^{(r-1)} U3Xh(r−1):
- U 3 ∈ R C r − 1 U_3 \in \mathbb{R}^{C_{r-1}} U3∈RCr−1 是用于通道特征提取的权重。
- 通过 U 3 X h ( r − 1 ) U_{3}\mathcal{X}_{h}^{(r-1)} U3Xh(r−1),我们对通道维度进行加权求和,得到 ( U 3 X h ( r − 1 ) ) T (U_{3}\mathcal{X}_{h}^{(r-1)})^T (U3Xh(r−1))T每个时间步在不同节点上的综合通道特征。即在每个时间步上,将各节点不同通道的信息汇总到一起,生成一个特征表示。
- 关联矩阵 ( ( X h ( r − 1 ) ) T U 1 ) U 2 ( U 3 X h ( r − 1 ) ) ((\mathcal{X}_h^{(r-1)})^TU_1)U_2(U_3\mathcal{X}_h^{(r-1)}) ((Xh(r−1))TU1)U2(U3Xh(r−1)):
( ( X h ( r − 1 ) ) T U 1 ) U 2 ((\mathcal{X}_h^{(r-1)})^TU_1)U_2 ((Xh(r−1))TU1)U2 生成的矩阵表示每个时间步在不同节点上的综合通道特征。
( U 3 X h ( r − 1 ) ) T (U_{3}\mathcal{X}_{h}^{(r-1)})^T (U3Xh(r−1))T 生成的矩阵同样表示每个时间步在不同节点上的综合通道特征。
将 ( ( X h ( r − 1 ) ) T U 1 ) U 2 ((\mathcal{X}_h^{(r-1)})^TU_1)U_2 ((Xh(r−1))TU1)U2 与 U 3 X h ( r − 1 ) U_{3}\mathcal{X}_{h}^{(r-1)} U3Xh(r−1) 相乘,得到的结果是一个 T r − 1 × T r − 1 T_{r-1}\times T_{r-1} Tr−1×Tr−1 的矩阵。这个矩阵的每个元素 E i , j E_{i,j} Ei,j 表示节点 i i i 和节点 j j j 之间的关联强度。
矩阵一行和一列进行计算实际上就是各时间步与各时间步之间进行点积,对时间步特征向量进行点积建立关联程度(时间步与时间步之间建立关联)
节点的关联程度由 V e , b e \mathbf{V}_e,\mathbf{b}_e Ve,be 来学习,决定各节点的关联程度
4.5 空间-时间卷积
空间-时间注意力模块让网络能够自动关注更有价值的信息。经过注意力机制调整的输入数据会被送入空间-时间卷积模块,其结构如图5所示。这里提出的空间-时间卷积模块包括空间维度上的图卷积,用于捕捉邻域中的空间依赖关系,以及沿时间维度的卷积,用于利用附近时间的时间依赖关系。
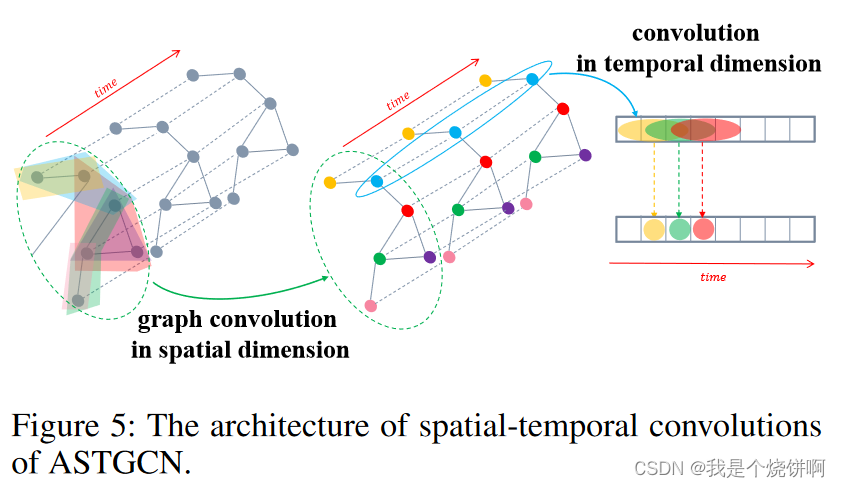
4.5.1 空间维度上的图卷积
图论中的谱图理论将卷积操作从基于网格的数据推广到图结构数据。在本研究中,交通网络本质上是一种图结构,每个节点的特征可以看作是图上的信号(Shuman et al. 2013)。因此,为了充分利用交通网络的拓扑属性,在每个时间片上,我们采用基于谱图理论的图卷积直接处理信号,在空间维度上利用交通网络上的信号相关性。
谱方法:
谱方法将图转化为代数形式来分析图的拓扑属性,例如图结构中的连通性。在谱图分析中,图由其对应的拉普拉斯矩阵表示。通过分析拉普拉斯矩阵及其特征值可以获得图结构的属性。
- 图的拉普拉斯矩阵定义为
L
=
D
−
A
L=D-A
L=D−A,其标准化形式为
L
=
I
N
−
D
−
1
/
2
A
D
−
1
/
2
∈
R
N
×
N
L=I_N-D^{-1/2}AD^{-1/2}\in\mathbb{R}^{N\times N}
L=IN−D−1/2AD−1/2∈RN×N
- 其中 A A A 是邻接矩阵, I N I_{N} IN 是单位矩阵,度矩阵 D ∈ R N × N D\in\mathbb{R}^{N\times N} D∈RN×N 是一个对角矩阵,由节点的度组成, D i i = ∑ j A i j D_{ii}=\sum_jA_{ij} Dii=∑jAij 。
- 拉普拉斯矩阵的特征值分解为
L
=
U
Λ
U
T
L=U\Lambda U^T
L=UΛUT
- 其中 Λ = d i a g ( [ λ 0 , . . . , λ N − 1 ] ) ∈ R N × N \Lambda=\mathrm{diag}([\lambda_0,...,\lambda_{N-1}])\in\mathbb{R}^{N\times N} Λ=diag([λ0,...,λN−1])∈RN×N 是对角矩阵, U U U 是傅里叶基。
图傅里叶变换:
以时间
t
t
t 的交通流量为例, 图上的信号为
x
=
x
f
t
∈
R
N
x=x_f^t\in\mathbb{R}^N
x=xft∈RN,信号的图傅里叶变换定义为
x
^
=
U
T
x
\hat{x}=U^{T}x
x^=UTx .根据拉普拉斯矩阵的性质,
U
U
U 是正交矩阵,因此相应的逆傅里叶变换为
x
=
U
x
^
x=U\hat{x}
x=Ux^
图卷积:
图卷积是通过使用在傅里叶域中对角化的线性算子来替代经典的卷积算子实现的(Henaff, Bruna, and LeCun 2015)。基于此,图
G
G
G 上的信号
x
x
x 被核
g
θ
g_{\theta}
gθ 过滤:
g
θ
∗
G
x
=
g
θ
(
L
)
x
=
g
θ
(
U
Λ
U
T
)
x
=
U
g
θ
(
Λ
)
U
T
x
(
5
)
g_\theta*_Gx=g_\theta(\mathbf{L})x=g_\theta(\mathbf{U}\mathbf{\Lambda}\mathbf{U}^T)x=\mathbf{U}g_\theta(\mathbf{\Lambda})\mathbf{U}^Tx\quad(5)
gθ∗Gx=gθ(L)x=gθ(UΛUT)x=Ugθ(Λ)UTx(5)
- 其中 ∗ G *_{G} ∗G 表示图卷积操作。由于图信号的卷积运算等于这些信号通过图傅立叶变换转换到谱域后的乘积(Simonovsky and Komodakis 2017),上述公式可以理解为分别将 g θ g_{\theta} gθ 和 x x x 进行傅里叶变换到谱域,然后将它们的变换结果相乘,再做逆傅里叶变换得到卷积运算的最终结果。
计算优化:
然而,当图的规模很大时,直接对拉普拉斯矩阵进行特征值分解的计算代价很高。因此,本文采用切比雪夫多项式来近似但有效地解决这个问题(Simonovsky and Komodakis 2017):
g
θ
∗
G
x
=
g
θ
(
L
)
x
=
∑
k
=
0
K
−
1
θ
k
T
k
(
L
~
)
x
(
6
)
g_\theta*_Gx=g_\theta(\mathbf{L})x=\sum_{k=0}^{K-1}\theta_kT_k(\tilde{\mathbf{L}})x\quad(6)
gθ∗Gx=gθ(L)x=k=0∑K−1θkTk(L~)x(6)
- 其中参数 θ ∈ R K \theta\in\mathbb{R}^{K} θ∈RK 是多项式系数向量。 L ~ = 2 λ max L − I N \tilde{L}=\frac2{\lambda_{\max}}L-I_N L~=λmax2L−IN, λ m a x \lambda_{\mathrm{max}} λmax 是拉普拉斯矩阵的最大特征值。
- 切比雪夫多项式的递归定义为 T k ( x ) = 2 x T k − 1 ( x ) − T k − 2 ( x ) T_k(x)=2xT_{k-1}(x)-T_{k-2}(x) Tk(x)=2xTk−1(x)−Tk−2(x),其中 T 0 ( x ) = 1 T_0(x)=1 T0(x)=1, T 1 ( x ) = x T_1(x)=x T1(x)=x 。
使用切比雪夫多项式的近似展开来求解这个公式,相当于通过卷积核 g θ g_{\theta} gθ 提取以每个节点为中心的图中周围0到(K − 1)阶邻居的信息。
空间注意力机制与图卷积结合:
为了动态调整节点之间的相关性,对于切比雪夫多项式的每一项, 我们将
T
k
(
L
~
)
T_k(\tilde{L})
Tk(L~) 与空间注意力矩阵
S
′
∈
R
N
×
N
S^{\prime}\in\mathbb{R}^{N\times N}
S′∈RN×N 结合,然后得到
T
k
(
L
~
)
⊙
S
′
T_k(\tilde{L})\odot S'
Tk(L~)⊙S′,其中
⊙
\odot
⊙ 是哈达玛积。因此,上述图卷积公式变为:
g
θ
∗
G
x
=
g
θ
(
L
)
x
=
∑
k
=
0
K
−
1
θ
k
(
T
k
(
L
~
)
⊙
S
′
)
x
g_\theta*_Gx=g_\theta(L)x=\sum_{k=0}^{K-1}\theta_k(T_k(\tilde{L})\odot S')x
gθ∗Gx=gθ(L)x=k=0∑K−1θk(Tk(L~)⊙S′)x
多通道图信号:
我们可以将这个定义推广到具有多个通道的图信号。例如在近期组件中,输入为
X
^
h
(
r
−
1
)
=
(
X
^
1
,
X
^
2
,
.
.
.
,
X
^
T
r
−
1
)
∈
R
N
×
C
r
−
1
×
T
r
−
1
\hat{\mathcal{X}}_h^{(r-1)}=(\hat{X}_1,\hat{X}_2,...,\hat{X}_{T_{r-1}})\in \mathbb{R}^{N\times C_{r-1}\times T_{r-1}}
X^h(r−1)=(X^1,X^2,...,X^Tr−1)∈RN×Cr−1×Tr−1
- 其中每个节点的特征有 C r − 1 C_{r-1} Cr−1 个通道。
对于每个时间片 t t t , 在图 X ^ t \hat{\mathcal{X}}_{t} X^t 上执行 C r C_{r} Cr 个滤波器,我们得到 g θ ∗ G X ^ t g_\theta*_G\hat{X}_t gθ∗GX^t
- 其中 Θ = ( Θ 1 , Θ 2 , . . . , Θ C r ) ∈ R K × C r − 1 × C r \Theta=(\Theta_1,\Theta_2,...,\Theta_{C_r})\in\mathbb{R}^{K\times C_{r-1}\times C_r} Θ=(Θ1,Θ2,...,ΘCr)∈RK×Cr−1×Cr 是卷积核参数 (Kipf and Welling 2017)。
因此,每个节点都通过节点的0∼K-1邻居的信息进行更新。
[[ASTGCN_空间卷积计算示例]]
4.5.2 时间维度上的图卷积
在空间维度上的图卷积操作捕获了图中每个节点的邻域信息后,我们进一步在时间维度上堆叠一个标准卷积层,通过合并相邻时间片的信息来更新节点的信号,如图5右侧所示。以近期组件中的第
r
r
r 层操作为例:
X
h
(
r
)
=
R
e
L
U
(
Φ
∗
(
R
e
L
U
(
g
θ
∗
G
X
^
h
(
r
−
1
)
)
)
)
∈
R
C
r
×
N
×
T
r
(
7
)
\mathcal{X}_h^{(r)}=ReLU(\Phi*(ReLU(g_\theta*_G\hat{\mathcal{X}}_h^{(r-1)})))\in\mathbb{R}^{C_r\times N\times T_r} \quad(7)
Xh(r)=ReLU(Φ∗(ReLU(gθ∗GX^h(r−1))))∈RCr×N×Tr(7)
其中:
- ∗ * ∗ 表示标准卷积操作
- Φ \Phi Φ 是时间维度卷积核的参数
- 激活函数为ReLU
计算步骤:
- 空间卷积:
- 首先,使用图卷积 g θ ∗ G g_{\theta}*_{G} gθ∗G 在空间维度上捕捉每个节点的邻居信息。
- 例如,对于近期组件中的第 r − 1 r-1 r−1 层输入数据 X ^ h ( r − 1 ) \hat{\mathcal{X}}_h^{(r-1)} X^h(r−1)(经过时间注意力更新后的输入),图卷积捕捉每个节点的邻居信息并更新节点的信号。
- 时间卷积:
- 接着,使用标准卷积 Φ ∗ \Phi \ast Φ∗ 在时间维度上处理更新后的节点信号。
- 通过合并相邻时间片的信息来更新每个节点的信号。例如,对于更新后的节点信号 R e L U ( g θ ∗ G X ^ h ( r − 1 ) ) ReLU(g_\theta*_G\hat{\mathcal{X}}_h^{(r-1)}) ReLU(gθ∗GX^h(r−1)),时间卷积进一步捕捉时间维度上的动态变化。
- 激活函数:
- ReLU(Rectified Linear Unit)激活函数用于引入非线性,提高模型的表达能力。
4.5.3 空间-时间卷积模块总结
空间-时间卷积模块能够很好地捕捉交通数据的时间和空间特征。一个空间-时间注意力模块和一个空间-时间卷积模块组成一个时空块(空间-时间块)。多个时空块堆叠在一起,以进一步提取更大范围的动态时空相关性。最后,附加一个全连接层以确保每个组件的输出具有与预测目标相同的维度和形状。最后的全连接层使用ReLU作为激活函数。
4.6 多组件融合
在本节中,我们将讨论如何整合三个组件的输出。以预测周五早上8:00的整个交通网络的交通流量为例。可以观察到,某些地区的交通流量在早高峰时段有明显的高峰期,因此日周期和周周期组件的输出更加重要。然而,在其他一些地方,可能没有明显的交通周期模式,因此日周期和周周期组件可能没有帮助。因此,在融合不同组件的输出时,三个组件对每个节点的影响权重是不同的,这些权重应该从历史数据中学习。所以融合后的最终预测结果是:
Y ^ = W h ⊙ Y ^ h + W d ⊙ Y ^ d + W w ⊙ Y ^ w \hat{\mathbf{Y}}=\mathbf{W}_h\odot\hat{\mathbf{Y}}_h+\mathbf{W}_d\odot\hat{\mathbf{Y}}_d+\mathbf{W}_w\odot\hat{\mathbf{Y}}_w Y^=Wh⊙Y^h+Wd⊙Y^d+Ww⊙Y^w
其中, ⊙ \odot ⊙ 是 Hadamard 积(元素级乘法)。 W h \mathbf{W}_h Wh、 W d \mathbf{W}_d Wd 和 W w \mathbf{W}_w Ww 是学习参数,反映了三个时间维度组件对预测目标的影响程度。
5 实验
为了评估我们模型的性能,我们在两个实际高速公路交通数据集上进行了比较实验。
5.1 数据集
我们在加利福尼亚的两个高速公路交通数据集 PeMSD4 和 PeMSD8 上验证了我们的模型。这些数据集由加利福尼亚交通性能测量系统(PeMS)(Chen et al. 2001)每30秒实时收集一次。交通数据从原始数据聚合为每5分钟一个间隔。该系统在加利福尼亚主要大都市地区的高速公路上部署了超过39,000个检测器。数据集中记录了传感器站点的地理信息。我们的实验考虑了三种交通测量指标,包括总流量、平均速度和平均占用率。
5.1.1 PeMSD4
该数据集指的是旧金山湾区的交通数据,包含29条道路上的3848个检测器。数据时间跨度为2018年1月至2月。我们选择前50天的数据作为训练集,剩余的数据作为测试集。
5.1.2 PeMSD8
该数据集是2016年7月至8月圣贝纳迪诺的交通数据,包含8条道路上的1979个检测器。前50天的数据用作训练集,最后12天的数据作为测试集。
5.2 数据预处理
我们移除了一些冗余检测器,以确保任何相邻检测器之间的距离超过3.5英里。最终,PeMSD4 有307个检测器,PeMSD8 有170个检测器。交通数据每5分钟汇总一次,因此每个检测器每天包含288个数据点。缺失值通过线性插值填充。此外,数据通过零均值归一化 x ′ = x − m e a n ( x ) x'=x-mean(x) x′=x−mean(x) 进行转换,使平均值为0。
5.3 实验设置
我们基于 MXNet 框架实现了 ASTGCN 模型。根据 Kipf 和 Welling (2017) 的工作,我们测试了切比雪夫多项式的项数 K ∈ 1 , 2 , 3 K \in {1, 2, 3} K∈1,2,3 。随着 K K K 的增大,预测性能略有提高。同样,时间维度上的卷积核大小也会影响性能。考虑到计算效率和预测性能的提高程度,我们将 K 设置为3,并将时间维度上的卷积核大小设置为 3。
模型设置:
- 图卷积层(空间卷积层):所有图卷积层使用 64 个卷积核。
- 时间卷积层:所有时间卷积层使用64个卷积核,并通过控制时间卷积的步长来调整数据的时间跨度。
- 时间片长度:
- 近期片段 T h T_h Th :24个时间片(即过去2小时的数据)。
- 日周期片段 T d T_d Td :12个时间片(即前一天相同时段的1小时的数据)。
- 周周期片段 T w T_w Tw :24个时间片(即前两周相同时段的2小时的数据)。
- 预测窗口:预测窗口 T p T_p Tp 设置为12个时间片(即预测未来1小时的交通流量)。
- 损失函数:使用估计值与真实值之间的均方误差(MSE)作为损失函数,并通过反向传播进行最小化。
- 训练参数:批量大小为 64 ,学习率为 0.0001。
对比实验:
为了验证所提出的时空注意力机制的影响,我们还设计了一个退化版本的 ASTGCN,命名为多组件时空图卷积网络(MSTGCN),该版本去掉了时空注意力机制。MSTGCN 的设置与 ASTGCN 相同,除了没有时空注意力机制。
5.4 基线模型
我们将我们的模型与以下八个基线模型进行比较:
- HA(历史平均法):使用过去12个时间片的平均值来预测下一个时间片的值。
- ARIMA(自回归综合移动平均法):Williams 和 Hoel(2003)提出的一种著名的时间序列分析方法,用于预测未来值。
- VAR(向量自回归):Zivot 和 Wang(2006)提出的一种更先进的时间序列模型,可以捕捉所有交通流量序列之间的成对关系。
- LSTM(长短期记忆网络):Hochreiter 和 Schmidhuber(1997)提出的一种特殊的循环神经网络(RNN)模型。
- GRU(门控循环单元网络):Chung 等人(2014)提出的一种特殊的RNN模型。
- STGCN(时空图卷积网络):Li 等人(2018)提出的一种基于空间方法的时空图卷积模型。
- GLU-STGCN(门控时空图卷积网络):Yu、Yin 和 Zhu(2018)提出的一种带有门控机制的图卷积网络,专为交通预测设计。
- GeoMAN(基于地理传感的多级注意力RNN模型):Liang 等人(2018)提出的一种基于多级注意力的循环神经网络模型,用于地理传感时间序列预测问题。
评价指标:
我们使用均方根误差(RMSE)和平均绝对误差(MAE)作为评价指标。
-
均方根误差(RMSE):
R M S E = 1 n ∑ i = 1 n ( y ^ i − y i ) 2 \mathrm{RMSE}=\sqrt{\frac1n\sum_{i=1}^n(\hat{y}_i-y_i)^2} RMSE=n1i=1∑n(y^i−yi)2
其中 y ^ i \hat{y}_i y^i 是预测值, y i y_i yi 是实际值, n n n 是样本数量。 -
平均绝对误差(MAE):
M A E = 1 n ∑ i = 1 n ∣ y ^ i − y i ∣ \mathrm{MAE}=\frac1n\sum_{i=1}^n|\hat{y}_i-y_i| MAE=n1i=1∑n∣y^i−yi∣
5.5 比较与结果分析
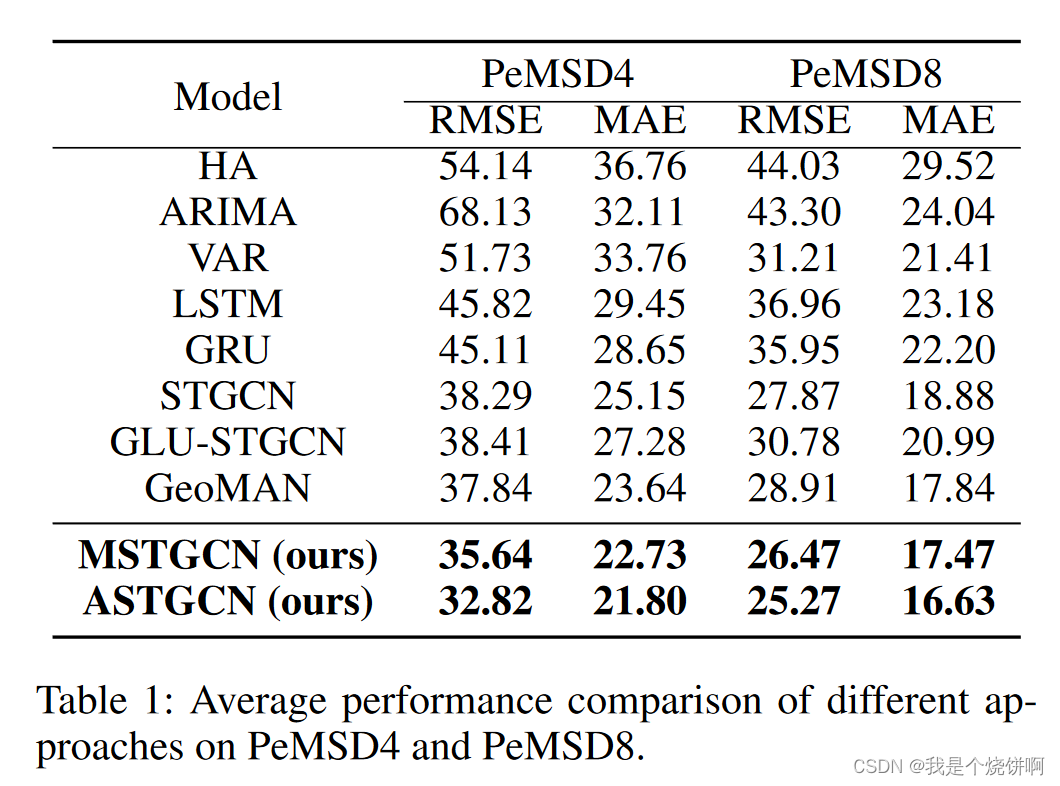
我们将我们的模型与八种基线方法在 PeMSD4 和 PeMSD8 数据集上进行了比较。表1显示了未来一小时内交通流量预测性能的平均结果。从表1中可以看出,我们的 ASTGCN 模型在这两个数据集上都取得了最佳性能,在所有评价指标上都表现优异。
5.5.1 主要发现
- 传统时间序列分析方法:传统时间序列分析方法(如 HA 和 ARIMA)的预测结果通常不理想,表明这些方法在建模非线性和复杂交通数据方面能力有限。
- 深度学习方法:与传统时间序列分析方法相比,基于深度学习的方法通常获得更好的预测结果。其中同时考虑时间和空间相关性的模型(如 STGCN、GLU-STGCN、GeoMAN 和我们模型的两个版本)优于传统的深度学习模型(如 LSTM 和 GRU)。
- 多级注意力机制:GeoMAN 的表现优于 STGCN 和 GLU-STGCN,表明在 GeoMAN 中应用的多级注意力机制在捕捉交通数据动态变化方面是有效的。
- MSTGCN 和 ASTGCN:
- 我们的 MSTGCN(没有任何注意力机制)在结果上优于之前的最先进模型,证明了我们模型在描述高速公路交通数据的时空特征方面的优势。
- 结合时空注意力机制后,我们的 ASTGCN 进一步减少了预测误差。
5.5.2 长期预测表现
图6显示了随着预测间隔增加,各种方法的预测性能变化。总体而言,随着预测间隔的增加,预测难度加大,预测误差也随之增加。从图中可以看出:
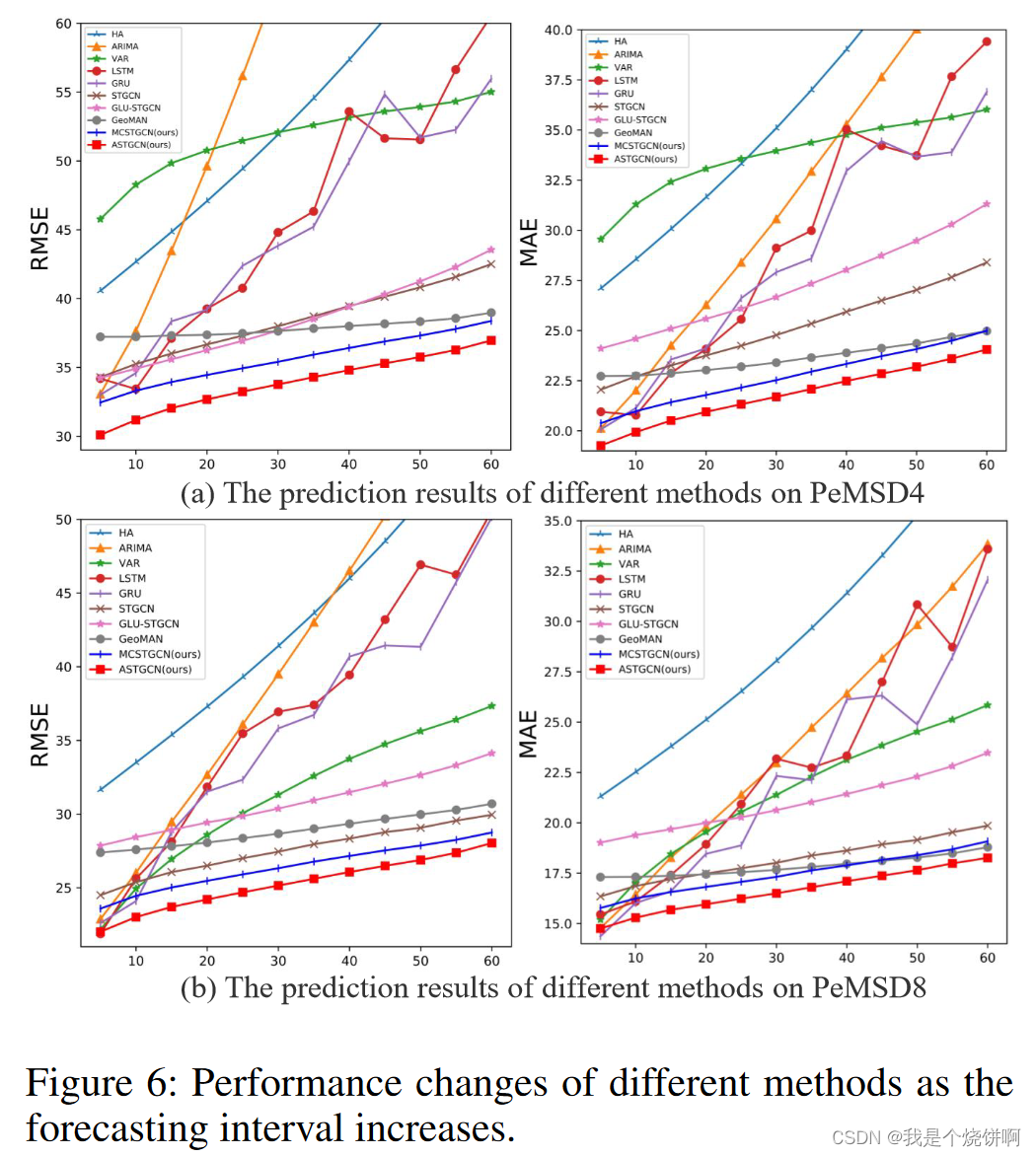
- 仅考虑时间相关性的方法:如 HA、ARIMA、LSTM 和 GRU,在短期预测中可以取得较好的结果,但随着预测间隔的增加,预测准确性显著下降。
- VAR 方法:VAR的性能下降速度比比仅考虑时间相关性的方法慢,这主要是因为 VAR 能同时考虑时空相关性,而时空相关性在长期预测中更为重要。然而,当交通网络的规模变大时,即模型中考虑的时间序列更多时,VAR的预测误差会增加,如图所示,其在 PeMSD4 上的表现比在 PeMSD8 上的表现更差。
- 深度学习方法:随着预测间隔的增加,深度学习方法的误差增加较慢,且总体表现良好。我们的 ASTGCN 模型几乎在所有时间都取得了最佳的预测性能,尤其是在长期预测中,ASTGCN 与其他基线模型的差距更为显著,显示出将注意力机制与图卷积相结合的策略可以更好地挖掘交通数据的动态时空模式。
5.5.3 注意力机制是如何作用的
为了直观地研究注意力机制在我们模型中的作用,我们进行了一个案例研究:从 PeMSD8 数据集中挑选出一个包含 10 个检测器的子图,并展示训练集中检测器之间的平均空间注意力矩阵。如图7右侧所示,在空间注意力矩阵中,第 i i i 行表示每个检测器与第 i i i 个检测器之间的相关强度。
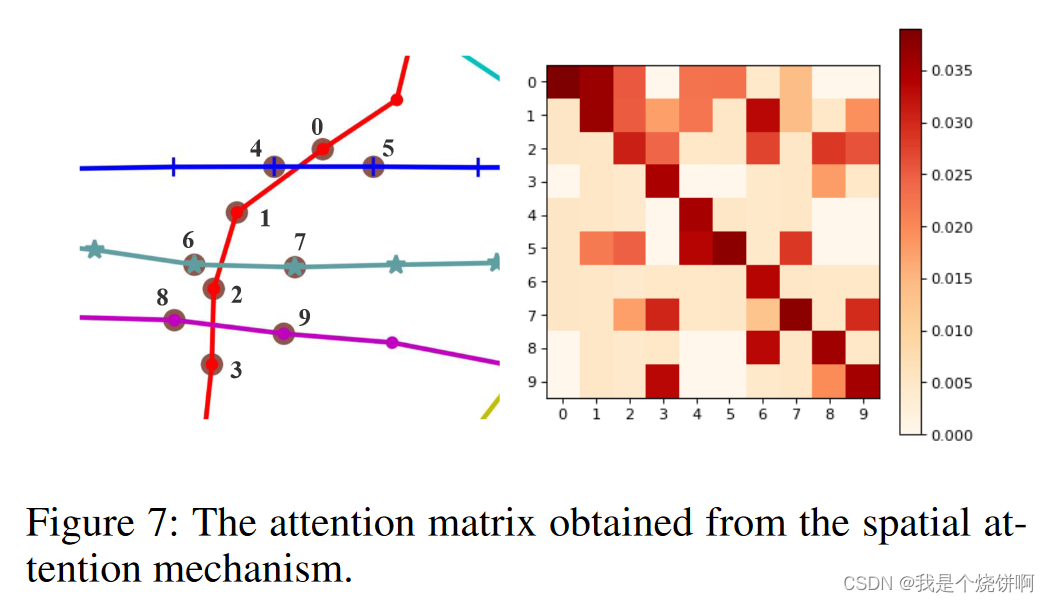
例如,查看最后一行,可以知道第 9 个检测器的交通流量与第 3 个和第 8 个检测器的交通流量密切相关。这是合理的,因为这三个检测器在实际交通网络中的空间位置很接近,如图7左侧所示。因此,我们的模型不仅在预测性能上表现最佳,而且还显示出解释性的优势。
6 结论和未来工作
在本文中,我们提出了一种新的基于注意力机制的时空图卷积模型,称为 ASTGCN,并成功应用于交通流量预测。该模型结合了时空注意力机制和时空卷积,包括空间维度上的图卷积和时间维度上的标准卷积,以同时捕捉交通数据的动态时空特征。对两个真实数据集的实验表明,所提出模型的预测准确性优于现有模型。代码已发布在:ASTGCN: Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting。
实际上,高速公路交通流量受许多外部因素的影响,如天气和社会事件。在未来,我们将考虑一些外部影响因素,以进一步提高预测准确性。由于 ASTGCN 是一个通用的图结构数据的时空预测框架,我们也可以将其应用于其他实际应用,例如估计到达时间。















 2005
2005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









