







常见的聚类方法:K-Means,层次聚类,基于密度的聚类
1.K-Means(K均值)聚类
算法步骤:
(1) 首先我们选择一些类/组,并随机初始化它们各自的中心点。中心点是与每个数据点向量长度相同的位置。这需要我们提前预知类的数量(即中心点的数量)。
(2) 计算每个数据点到中心点的距离,数据点距离哪个中心点最近就划分到哪一类中。
(3) 计算每一类中中心点作为新的中心点。
(4) 重复以上步骤,直到每一类中心在每次迭代后变化不大为止。也可以多次随机初始化中心点,然后选择运行结果最好的一个。
下图演示了K-Means进行分类的过程:
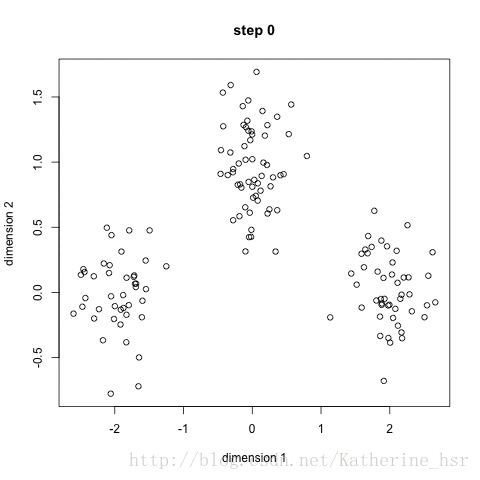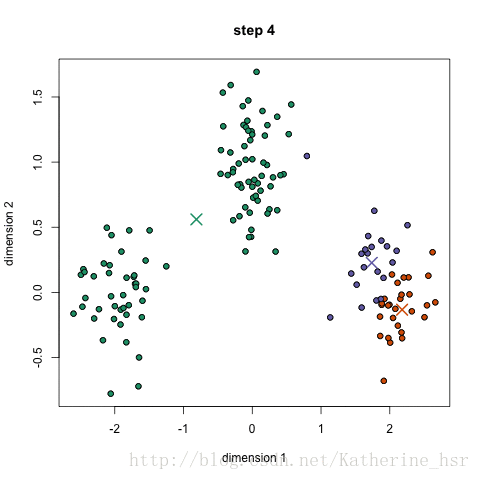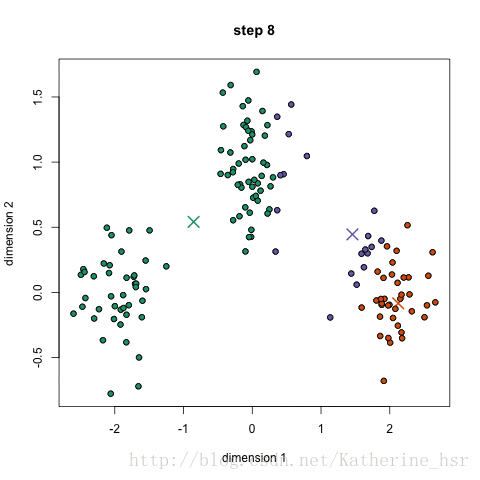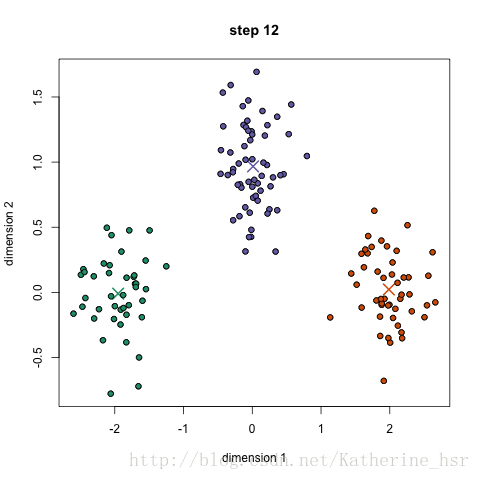
优点:速度快,计算简便
缺点:我们必须提前知道数据有多少类/组。
2.基于密度的聚类算法(如:DBSCAN)
详细讲解:https://blog.csdn.net/liudongdong19/article/details/80968459
其核心思想就是先发现密度较高的点,然后把相近的高密度点逐步都连成一片,进而生成各种簇。算法实现上就是,对每个数据点为圆心,以eps为半径画个圈(称为邻域ep
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3954
3954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









