






目录
一、算法基础
1.1 时空效率
时间复杂度:代码的总的运行次数->对内存访问的次数.
渐进符号 O(大欧):上界,等价于 <=
空间复杂度:空间消耗(为了解决问题额外的空间消耗)
常量简化为O(1),程序在有限可数的范围内完成。空间时间消耗不随待处理量的增大而增大
线性变化O(n)
复杂度要求:
1.多项式级运算结果,只保留最大项
2.常系数要舍去
3.如果程序可以在有限可数的资源消耗内完成,即为常量复杂度O(1)
经验性结论:
1.一个简单的顺序或选择结构,时间复杂度是O(1)
2.一般的一层循环时间复杂度是O(n)
3.一般的两层循环复杂度是O(n2)
4.顺序的两个循环,时间复杂度是max(O(n),O(m))
5.一般情况下的二分分治时间与log2n有关
6.时空权衡问题,大多数情况下,选择用空间换时间。可以用递归、分治、动态规划来换取时间效率
1.2 数据结构
数据结构:
数据排列和组合的形态
用来进行数据的存储和运算
线性结构(一对一)
非线性结构(一对多)
1.2.1 数组
数组定义:在内存中连续存储的固定大小的具有相同类型元素的顺序集合,可以用下标表示每个元素
数组特性:
1、类型相同、空间连续、长度固定
2、下标查找快,遍历慢
3、尾增删易,插入删除难
例:数组查重

//数组查重:n个元素,0~n-1
#include <iostream>
using namespace std;
bool check(int* a, int len) {
for (int i = 0; i < len; i++) {
if (i != a[i]) {
if (a[a[i]] == a[i]) {
return 0;
}
else {
swap(a[i], a[a[i]]);
i--;
}
}
}
return 1;
}
int main() {
int a[] = { 1,2,1,3,4 };
cout << check(a, sizeof(a));
}1.2.2 位运算
//n个元素,有一个元素仅出现一次,其他元素均出现两次,怎么找到这个元素
#include <iostream>
using namespace std;
int findans(int* a, int n) {
int res = 0;
for (int i = 0; i < n; i++) {
res = res ^ a[i];
}
return res;
}
int main() {
int a[] = { 1,2,2,3,1,5,6,9,6,3,9 };
int len = sizeof(a) / sizeof(a[0]);
cout << findans(a,len);
}//n个元素,有2个元素仅出现一次,其他元素均出现两次,怎么找到这个元素
#include <iostream>
using namespace std;
void findans(int* a, int n,int& x,int& y) {
//整体^,得到结果两值的异或值
int res = 0;
for (int i = 0; i < n; i++) {
res = res ^ a[i];
}
//找到结果最右非0位,说明结果的两个值,在这一位不同
//res = ~res + 1; //ERROR:溢出
//res=res&(-res); //ERROR:2147483648 的否定不能用类型“int”表示;当值位INT_MIN的时候,需要特殊判断
res = (res == INT_MIN) ? res : res & -res; //[1,1,0,-2147483648]
//根据这不同的一位,对原数据分组
for (int i = 0; i < n; i++) {
//每组^,得到结果的两个数
if (res & a[i])
x = x ^ a[i];
else y = y ^ a[i];
}
}
int main() {
int a[] = { 0,0,1,2,2,3,3,4,4,5,6,6,7,7 };
int len = sizeof(a) / sizeof(a[0]);
int x = 0, y = 0;
findans(a, len, x, y);
cout << x << " " << y << endl;
}//n个元素,有1个元素仅出现一次,其他元素均出现3次,怎么找到这个元素
//按位统计1个数count,count一定是3的倍数+1或者+0,那么结果的这位就是count%3
#include <iostream>
using namespace std;
int findans(int* a, int n) {
int res = 0;
for (int i = 0; i < 32; i++) {
int count = 0;
for (int j = 0; j < n; j++) {
if ((a[j] >> i) & 1) {
count++;
}
}
res = res | ((count % 3) << i);
}
return res;
}
int main() {
int a[] = { 1,1,1,3,4,4,4,5,5,5,6,6,6 };
int len = sizeof(a) / sizeof(a[0]);
cout << findans(a, len);
}使用位运算,避免越界问题,同时位运算快。
交换操作:
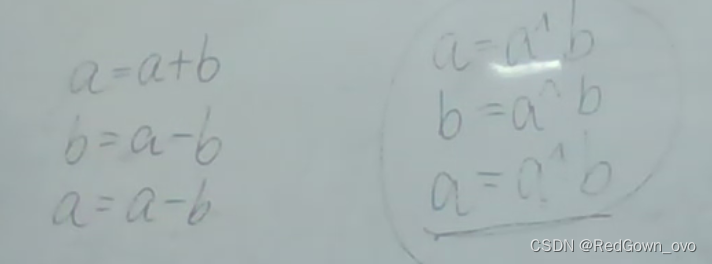
注意:ab不能代表同一块空间,且不能值相同
(a^b)&&(a=a^b);
x^=x; //清0操作
a^b //判断是否相等
a+b ——> (a^b)+((a&b)<<1) ——> (a^b)^((a&b)<<1) //加数 + 进位,直到没有进位
1.3 递归
return回到程序的调用位置 exit结束当前进程
斐波那契数列
将大的问题拆解成解决方案完全相同的子问题。要有明确的终止
1.4 分治法
将一个问题拆解成若干个解决方法完全相同的子问题
1.问题难度随问题缩小而降低
2.问题可拆分
3.子问题的解可合并
4.子问题的解相互独立
例:快速幂
1.5 二分
二分查找/折半搜索
等概率事件,可以得到最优下界(次数内一定能解决问题)
条件:有序的
//二分查找
#include <iostream>
using namespace std;
int ef1(int* a,int left,int right,int ans) {
//int mid = (left + right) / 2; //容易溢出
int mid = left + (right - left) / 2;
if (mid == left && a[mid] != ans)
return -1;
if (a[mid] == ans)
return mid;
else if (a[mid] < ans)
ef1(a, mid+1, right, ans);
else ef1(a, left, mid - 1, ans);
}
int ef2(int* a, int n,int ans) {
int left = 0;
int right = n;
int mid=-1;
while (left < right) {
mid = left + (right - left) / 2;
if (mid == left && a[mid] != ans) {
mid = -1;
break;
}
if (a[mid] == ans)
break;
else if (a[mid] < ans) {
left = mid + 1;
}
else {
right = mid;
}
}
return mid;
}
int main() {
int a[] = { 1,2,3,4,4,5,6,7,10,23,25,35,65,72,89,100 };
int len = sizeof(a) / sizeof(a[0]);
cout << ef1(a,0,len,35)<<endl;
cout << ef2(a, len, 1111)<<endl;
}二、链表
2.1 链表结构
链表的定义:一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
链表特性:中间插入和删除非常快
数组和链表的区别
(1)逻辑结构:数组内存中连续,长度大小固定。链表采用动态内存分配,内存中不连续,大小不固定。
(2)内存结构:数组从栈上分配内存,系统自动分配空间,自由度小。链表从堆上手动分配内存,自由度大。
堆区与栈区的区别?
1、生长方向:堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。
2、分配方式:堆是手工动态分配的malloc()。栈由操作系统静态分配(局部变量)或动态分配alloca()
malloc、alloc、calloc、realloc_malloc alloc calloc-CSDN博客
3、分配效率:栈由操作系统自动分配,会在硬件层级对栈提供支持,效率较高。堆由C/C++提供的库函数或运算符完成,易产生内存碎片,效率低下。
4、存储内容:堆中具体内容由程序员来填充。栈存放函数返回地址、相关参数、局部变量和寄存器内容等
5、管理方式:栈由系统自动分配释放。堆的申请和释放都由手工控制,易产生内存泄漏
6、空间大小:每个进程拥有的栈大小远小于堆
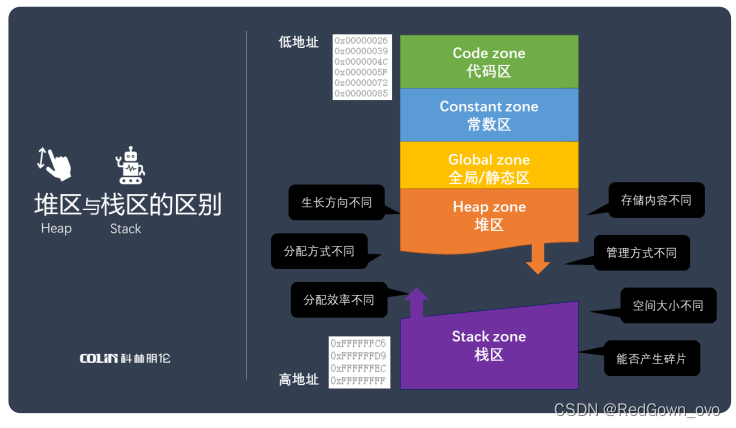
(3)访问效率:数组可通过下标访问,查找效率高,插入删除难。链表需从头遍历,插入删除效率高。
链表:数据域、指针域
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int data;
node* next;
}List;
void CreateList(List** p) {
int len;
//List* pHead = nullptr;
List * pTail = nullptr;
List* pNode = nullptr;
printf("请输入链表长度\n");
scanf("%d", &len);
while (len--) {
printf("输入节点数值\n");
int val;
scanf("%d", &val);
pNode = (List*)malloc(sizeof(List));
pNode->data = val;
pNode->next = nullptr;
if (*p == nullptr) {
*p = pNode;
}
else {
pTail->next = pNode;
}
pTail = pNode;
}
}
void printList(List* pHead) {
while (pHead != nullptr) {
printf("%d ", pHead->data);
pHead = pHead->next;
}
printf("\n");
}
void reversPrint(List* p) {
if (p == nullptr) {
return;
}
reversPrint(p->next);
printf("%d ", p->data);
}
int main() {
List* p = nullptr;
CreateList(&p);
printList(p);
reversPrint(p);
printf("\n");
}2.2 链表应用
循环链表:从任意节点出发,均可遍历整个链表
线性链表:
- 线性表都只有一个表头元素和一个表尾元素;
- 表头没有前驱,表尾没有后继;
- 除表头和表尾外,其他元素只有一个直接前驱和一个直接后继
数组模拟链表:除了存储数据,还有一个区域,存储下一个节点的下标
例:双指针
例:两链表交点?
1、哈希
2、 双指针,从a、b链表头同时移动,跑完a再从b头跑,返回指向同一个的结点(a+c+b=b+c+a)
3、记录两条链表长度,对齐,同时移动,返回指向同一个的结点
例:有环链表求入口节点?
1、哈希
2、快慢指针
a=(n-1)(b+c)+c,发现:从相遇点到入环点的距离加上 n−1 圈的环长,恰好等于从链表头部到入环点的距离。
3、先求得环长,ab指针从头,b先跑环长,ab同时跑,b到头,a到入口节点
4、反转链表,会回到表头。再反转还原链表,记录处理过程,可以得到入口节点
abcgfedcba
复杂链表,含有随机指针
跳跃链表(skipList跳表)(复合结构)
对有序链表进行快搜
哨兵
例:无序数组中查找合为n的两个数?
三、哈希表
应用:无序数组的多次查找
步骤:
(一)定散列(Hash)函数,按一定规则进行映射。常用除留取余法,p=key%M,M常取>=n的质数(减少冲突的可能性)
(二)解决哈希冲突。多个数据抢占同一个位置时,叫做哈希冲突。
(1) 开放地址法:① 线性探测:依次占用后续没有占用的位置
② 线性补偿探测:定义一个间隔,按间隔快速的向后查找后续没有占用的位置
③ 二次探测、线性探测散列:查找前后位置x^2(x=1,2,3,4,5...)的位置是否被占用
(2) 拉链法、链地址法:将哈希数组(指针数组)变成多条单向链表(省空间),发生冲突的键值对添加到对应的链表中
1. List struct
2. 表头数组hashTable,赋初值为空
3. 元素按哈希入组(头插,简单)
4. 查找,获得索引、遍历
两种方法对比:
①线性探测:本质是数组
装载因子α=元素个数/表长 < 0.8(元素少,表长)越稀疏,产生冲突的可能性越低
旧表转移到新表,散列函数也会有变化
线性探测删除:标记为删除态
②拉链法:兼具链表和数组
α < 1 ,链表过长会导致遍历时间长
扩容,节点可以直接指向新表,省去了空间开销
#include <iostream>
using namespace std;
#define M (13)
typedef struct node{
int vlue;
node* next;
}List;
List* hashTable[M] = { nullptr };
void insert(int v) {
List* nd = (List*)malloc(sizeof(node));
if (nd !=nullptr)
nd->vlue = v;
int hashvalue = v % M;
nd->next = hashTable[hashvalue];
hashTable[hashvalue] = nd;
}
bool Search(int v) {
int hashvalue = v % M;
cout << hashvalue << endl;
if (hashTable[hashvalue] == nullptr)
return 0;
List* head = hashTable[hashvalue];
while (head) {
if (head->vlue == v)
return 1;
head = head->next;
}
return 0;
}
int main() {
int a[] = { 85,14,2,116,34,7,82,15,26,45,202,31 };
int len = sizeof(a) / sizeof(a[0]);
for (int i = 0; i < len; i++) {
insert(a[i]);
}
for (int i = 0; i < M; i++) {
cout << i << ":";
List* p = hashTable[i];
while (p) {
cout << p->vlue << " ";
p = p->next;
}
cout << endl;
}
cout << Search(5);
}拉链法优点:1.处理冲突简单 2.删除简单 3.对于未知数据个数,拉链法可以用通过扩容来解决 4.数据量大,数据体积大(适合拉链法)。数据量小的时候更适合线性探测。
map和unorder_map原理
unordered_map和map的区别,从算法,底层实现原理区别,效率,桶树等结构等等多个层面解析(c++角度)-CSDN博客
vecter和list区别
四、栈 FILO
pop销毁栈顶,让当前变量用不了。此时top就不能定义在主函数(生存周期),定义另外一个结构体对top进行封装。
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int value;
struct node* pnext;
}Data;
typedef struct node2 {
Data* pTop;
int count;
}Stack;
void Init(Stack** pStack) {
*pStack = (Stack*)malloc(sizeof(Stack));
(*pStack)->pTop = NULL;
(*pStack)->count = 0;
}
void Push(Stack* pStack, int num) {
if (pStack == NULL) {
printf("stack is not exist\n");
return;
}
Data* pTmp = (Data*)malloc(sizeof(Data));
pTmp->value = num;
pTmp->pnext = pStack->pTop;
pStack->pTop = pTmp;
pStack->count++;
}
void Pop(Stack* pStack) {
if (pStack == NULL)
return;
if (pStack->count == 0)
return;
Data* pDel = pStack->pTop;
pStack->pTop = pStack->pTop->pnext;
free(pDel);
pStack->count--;
}
void Clear(Stack* pStack) {
if (pStack == NULL)
return;
while (pStack->count > 0) {
Pop(pStack);
}
}
void Destroy(Stack** pStack) {
Clear(*pStack);
free(*pStack);
*pStack = NULL;
}
int GetTop(Stack* pStack) {
if (pStack == NULL)
exit(1);
if (pStack->count == 0)
exit(1);
return pStack->pTop->value;
}
int GetCount(Stack* pStack) {
if (pStack == NULL)
exit(1);
return pStack->count;
}
int IsEmpty(Stack* pStack) {
if (pStack == NULL)
exit(1);
return pStack->count == 0 ? 1 : 0;
}
int main() {
Stack* pStack = NULL;
Init(&pStack);
Push(pStack, 1);
Push(pStack, 2);
Push(pStack, 3);
Push(pStack, 4);
printf("%d ", GetTop(pStack));
Pop(pStack);
printf("%d ", GetTop(pStack));
Pop(pStack);
printf("%d ", GetTop(pStack));
Pop(pStack);
printf("%d ", IsEmpty(pStack));
Destroy(&pStack);
Push(pStack, 100);
return 0;
}栈的应用
栈在四则运算中的应用:逆波兰表达式
中缀表达式转后缀表达式
‘( ’ => 无条件入栈
数字或字母 => 输出
运算符 => 把当前符号与栈顶元素进行优先级比较。当前符号优先级高,直接入栈;优先级低,栈内元素出栈,直到比当前符号优先级低,再将当前符号入栈。
')' => 栈内元素出栈,直到 '(' 停止。(前缀中缀表达式有括号,后缀表达式没有括号)
(9+6)*5-8/4
9 6 + 5 * 8 4 / -
简单方法:给所有可能的运算加括号
(((9+6)*5)-(8/4))
把符号转到所在的括号后
(((9 6)+ 5)* (8 4)/)-
然后再删去括号
后缀转中缀
数字或字母 => 入栈
运算符 => 将栈顶元素和栈顶元素的下一个构成表达式(加括号)
单调栈
实时返回栈内的最小值
维护一个单调递减栈,每有元素入栈,在单调栈里入栈当前最小值。这样单调栈栈顶永远是当前最小值。
五、队列 FIFO
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int vlaue;
struct node* pnext;
}Data;
typedef struct node2 {
int count;
Data* pFront;
Data* pRear;
}Queue;
void Init(Queue** pQueue) {
*pQueue = (Queue*)malloc(sizeof(Queue));
(*pQueue)->count = 0;
(*pQueue)->pFront = NULL;
(*pQueue)->pRear = NULL;
}
void Push(Queue* pQueue, int num) {
if (pQueue == NULL)
return;
Data* pTmp = NULL;
pTmp = (Data*)malloc(sizeof(Data));
pTmp->vlaue = num;
pTmp->pnext = NULL;
if (pQueue->pFront == NULL)
pQueue->pFront = pTmp;
else
pQueue->pRear->pnext = pTmp;
pQueue->pRear = pTmp;
pQueue->count++;
}
void Pop(Queue* pQueue) {
if (pQueue == NULL)
return;
if (pQueue->count == 0)
return;
Data* pDel = pQueue->pFront;
pQueue->pFront = pQueue->pFront->pnext;
printf("%d\n", pDel->vlaue);
free(pDel);
pDel = NULL;
pQueue->count--;
if (pQueue->count == 0)
pQueue->pRear = NULL;
}
int main() {
Queue* pQueue = NULL;
Init(&pQueue);
Push(pQueue, 1);
Push(pQueue, 2);
Push(pQueue, 3);
Push(pQueue, 4);
Pop(pQueue);
Pop(pQueue);
Pop(pQueue);
Pop(pQueue);
return 0;
}循环队列(底层是数组)
约瑟夫环
#include <iostream>
#include <queue>
using namespace std;
int Joseph(int n, int k) {
queue<int> q;
for (int i = 1; i <= n; i++) {
q.push(i);
}
int num = 0;
int count = 0;
while (q.size() > 1) {
num = q.front();
q.pop();
count++;
if (count % k != 0) {
q.push(num);
}
}
num = q.front();
q.pop();
return num;
}
int main() {
int n, k;
cin >> n >> k;
cout << Joseph(n, k);
}可得,第i个元素在一次出队操作时,位置向前移动了k。反过来,进行一次入队操作时,i元素向后移动了k。当队列只剩一个元素时,K(1)=0;进行一次入队时,K(2)=(K(1)+k)%2。
所以,K(n)=(K(n-1)+k)%n
子数组、子串:连续
子序列:可以不连续,相对位置不变
子集:包含
找长度为k的连续子数组中的最大值
维护一个单调递减队列,当有值大于队尾元素时,popback直到队尾元素比新元素大(>=)或队列为空,然后pushback新元素。(滑动窗口)
两个栈,实现当前队列的先进先出
入队栈和出队栈。入队时,先把 出队栈 出栈到 入队栈 再入栈新元素;出队时,先把 入队栈 出栈到 出队栈,再出栈 出队栈。
#include <iostream>
#include <stack>
using namespace std;
int pop(stack<int>* s1, stack<int>* s2) {
if (s1->empty() && s2->empty()) {
cout << "empty" << endl;
return 0;
}
while (!s1->empty()) {
int tmp = s1->top();
s1->pop();
s2->push(tmp);
}
int tmp = s2->top();
s2->pop();
return tmp;
}
void push(stack<int>* s1, stack<int>* s2,int val) {
while (!s2->empty()) {
int tmp = s2->top();
s2->pop();
s1->push(tmp);
}
s1->push(val);
}
int main() {
stack<int> s1;
stack<int> s2;
push(&s1, &s2, 1);
push(&s1, &s2, 2);
push(&s1, &s2, 3);
push(&s1, &s2, 4);
push(&s1, &s2, 5);
cout << pop(&s1, &s2) << endl;
cout << pop(&s1, &s2) << endl;
cout << pop(&s1, &s2) << endl;
push(&s1, &s2, 6);
push(&s1, &s2, 7);
cout << pop(&s1, &s2) << endl;
cout << pop(&s1, &s2) << endl;
cout << pop(&s1, &s2) << endl;
cout << pop(&s1, &s2) << endl;
cout << pop(&s1, &s2) << endl;
}两个队列,实现栈的先进后出
出栈时,先把 非空队列 除尾元素出队到 空队列,非空队列剩余元素弹出。
入栈时,入队非空队列。
#include <queue>
#include <iostream>
using namespace std;
int pop(queue<int>& l1, queue<int>& l2) {
if (l1.empty() && l2.empty()) {
cout << "empty()" << endl;
return 0;
}
queue<int>& ln = l1.empty() ? l2 : l1;
queue<int>& le = l1.empty() ? l1 : l2;
while (ln.size() > 1) {
int tmp = ln.front();
ln.pop();
le.push(tmp);
}
int ans = ln.front();
ln.pop();
return ans;
}
void push(queue<int>& l1, queue<int>& l2, int val) {
queue<int>& l = l1.empty() ? l2 : l1;
l.push(val);
}
int main() {
queue<int> l1;
queue<int> l2;
push(l1, l2, 1);
push(l1, l2, 2);
push(l1, l2, 3);
push(l1, l2, 4);
push(l1, l2, 5);
cout << pop(l1, l2) << endl;
cout << pop(l1, l2) << endl;
cout << pop(l1, l2) << endl;
push(l1, l2, 6);
cout << pop(l1, l2) << endl;
cout << pop(l1, l2) << endl;
cout << pop(l1, l2) << endl;
cout << pop(l1, l2) << endl;
}六、字符串(末尾有'\0'的字符数组)
字符串数组和字符串指针的区别
char str[] = "hello";
char *str = "hello";
1. 字符串数组存储位置在栈区,字符串指针在全局静态区
2. 大小不一样,字符串数组大小为6('\0')。指针大小为4
3. 权限不同,数组可以增删改查,指针只能查
足够长的字符串,对其所有的空格替换?
统计空格数,然后通过指针从尾部向前移动复制
反转字符串中的单词
字符串函数
strlen长度 strcmp比较 strcat连接 strstr查找位置 strcpy复制 substr子串 atoi字符串转数字(手写源码) sprintf拼接字符串 strtok 分解字符串为一组字符串 strdup字符串拷贝库
正则表达式
. 匹配任意一个字符
* 匹配前一个字符0次或多次
判断正则表达式是否能匹配字串
状态机
6.1 查找问题
6.1.1 在一个串中找符合条件的某个字符
找第一个只出现一次的字符?
桶排,开个256大小的数组计数
6.1.2 在一个串中找符合条件的子串
6.1.2.1 KMP
KMP算法图文详解(为什么是next[0]=-1、next[j]=k和k=next[k])_kmp算法的next初始值为-1-CSDN博客
KMP 改进的字符串匹配算法。用来查找匹配串(match)在原串(src)中的位置。
不让主串指针移动,而是让匹配串向前移动 j - 当前 前缀后缀相同的最大匹配长度 (在匹配失败时,让匹配部分的前缀与相同的后缀对齐,省去重复检查这一段的时间。同时取最大长度,使match尽可能靠左的进行比较)
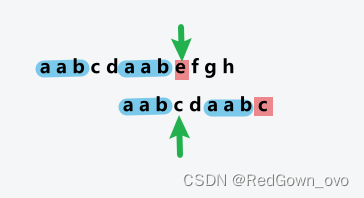
若移动时没有采取最大匹配长度,会导致匹配时错过答案

①求前缀后缀最大匹配长度next (用于下一次匹配的快速定位)
void getnext(string s, int next[],int len) {
cout << __func__ << endl;
int i = 1, j = 0;
next[0] = 0;
while (i < len) {
if (s[i] == s[j]) {
next[i] = j + 1;
i++;
j++;
}
else if (j == 0) {
next[i] = 0;
i++;
}
else j = next[j - 1];
}
}src: abcabceabcabcdabcabcabcdabcabcfabcabc
match:abcabcdabcabcf
next: 00012301234560
②进行匹配。当原串和匹配串匹配,二者同时移动;若二者不匹配,匹配串指针移动到next[j-1]
int KMP(string src, string match) {
cout << __func__ << endl;
int len_s = src.size();
int len_m = match.size();
int* next = (int*)malloc(len_m * sizeof(int));
getnext(match, next, len_m);
int i = 0, j = 0;
while (i < len_s && j < len_m) {
if (src[i] == match[j]) {
i++;
j++;
}
else if (j == 0) {
i++;
}
else j = next[j - 1];
}
if (j >= len_m)
return i - len_m;
else return -1;
}③检测匹配串是否遍历完成
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int* getnext(const char* s) {
int i = 1, j = 0;
int len = strlen(s);
int* next = (int*)malloc(len * sizeof(int));
next[0] = 0;
while (i < len) {
if (s[i] == s[next[j]]) {
next[i] = next[j] + 1;
i++;
j=i-1;
}
else if (next[j] == 0) {
next[i] = 0;
i++;
j = i - 1;
}
else j = next[j - 1];
}
return next;
}
int KMP(const char* src, const char* match) {
if (src == NULL || match == NULL)
return -1;
int len_s = strlen(src);
int len_m = strlen(match);
int* next = getnext(match);
int i = 0, j = 0;
while (i < len_s && j < len_m) {
if (src[i] == match[j]) {
i++;
j++;
}
else if (j == 0) {
i++;
}
else j = next[j - 1];
}
if (j >= len_m)
return i - len_m;
else return -1;
}
int main() {
char src[] = "abcabceabcabcdabcabcabcdabcabcfabcabc";
char match[] = "abcabcdabcabcf";
printf("%d\n", KMP(src, match));
}6.1.2.2 Sunday
在检索时,对模式串等长的原串进行比较。若不匹配,则该段不可能为匹配串,此时寻找匹配串在该段中最早可能出现的位置。即将当前匹配段的下一个字符,找到其对应的匹配串中从右向左第一个字符,并与其对齐,然后再进行比较。
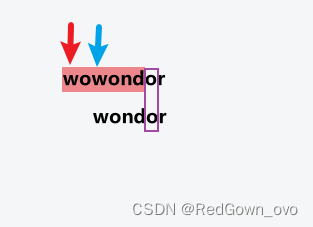
①next数组记录每个字符在匹配串中最靠右的位置
void getnext(string s, int next[]) {
for (int i = 0; i <= 255; i++) {
next[i] = -1;
}
for (int i = 0; i < s.size(); i++) {
next[s[i]] = i;
}
}②若不相同,该匹配串等长的段不可能为匹配串,找到当前段下一个字符,将其与匹配串最右对应位置对齐,再进行匹配这个新的等长的段。
int Sunday(string src, string match) {
if (src.empty() || match.empty())
return -1;
int i = 0, j = 0;
int next[256];
getnext(match, next);
int len_s = src.size();
int len_m = match.size();
while (i < len_s - len_m) {
j = 0;
while (src[i + j] == match[j]) {
j++;
if (j >= len_m)
return i;
}
i += len_m - next[src[i + len_m]];
}
return -1;
}#include <iostream>
using namespace std;
int Sunday(const char* src, const char* match) {
if (src==NULL || match==NULL)
return -1;
int len_s = strlen(src);
int len_m = strlen(match);
int* next = (int*)malloc(sizeof(int) * 256);
memset(next, -1, sizeof(int) * 256);
for (int i = 0; i < len_m; i++) {
next[match[i]] = i;
}
int i = 0, j = 0, k = 0;
while (i < len_s && j < len_m) {
if (src[i] == match[j]) {
i++;
j++;
}
else {
//下次位置确定
if (k + len_m < len_s) {
i = k + len_m - next[src[k + len_m]];
j = 0;
k = i;
}
else
return -1;
}
}
return i - len_m;
}
int main() {
char src[] = "wonwannrwawonnwonderowand";
char match[] = "wonder";
cout << Sunday(src, match) << endl;
}最长回文子串(子序列)
6.1.3 在多个串中找复合条件的某个串
字典树
6.1.4 找两个串的公共部分
最长公共子串(子序列)















 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









