







 本文详细阐述了MySQL索引在后端面试中的重要性,包括内存限制下的排序处理策略、磁盘预读技术以及B+树索引的工作原理。文章还介绍了索引设计的关键原则,如唯一性、选择性、覆盖索引等,以提升数据库查询性能和效率。
本文详细阐述了MySQL索引在后端面试中的重要性,包括内存限制下的排序处理策略、磁盘预读技术以及B+树索引的工作原理。文章还介绍了索引设计的关键原则,如唯一性、选择性、覆盖索引等,以提升数据库查询性能和效率。
在后端面试中,MySQL的索引是一个常见问题,尤其是最近掀起了去Oracle的风向。作为一个很宽泛的面试题,不仅考验对MySQL整体知识的了解,也方便面试官随着我们的回答逐渐往下延伸问题。众所周知,面试问题的答案,不仅仅只有结论,很多面试官要的是你对这个问题的分析,看你对这个知识点的掌握程度,而不是只要最后的结论。
一、什么是MySQL索引
首先,MySQL是一个数据库,负责存储数据,需要支撑业务系统,这就要求需要在短时间内返回数据 。我们知道 MySQL的真实行记录信息存储在磁盘中 。所以想要从MySQL中获取信息,就意味着去磁盘中获取消息,就需要进行IO操作。如何减少IO次数,减少IO量就变成我们的设计准则。
当数据量很小的时候,这些IO操作带来的影响可以忽略不计,但随着项目的扩展,数据量会逐渐上升,就会导致大量的IO操作,极大的浪费了性能。这时,如果有一个数据量特别的大的文件,超过了内存的容量,那么就不可能会一次性将所有的数据都加载到内存中,这时候需要 分而治之 的思想,进行分块读取数据。块的大小就是设计的一个标准。
前几年常见的一道面试题
1、如果有1TB的数据需要排序,但只有32GB的内存如何排序处理?
传统的排序算法一般指 内排序 算法,针对的是数据可以一次全部载入内存中的情况。但是面对海量数据,即数据不可能一次全部载入内存,需要用到 外排序 的方法。
外排序采用分块的方法(分而治之) ,首先将数据分块,对块内数据按选择一种高效的内排序策略进行排序。然后采用归并排序的思想对于所有的块进行排序,得到所有数据的一个有序序列。
实际做法:
- 首先把磁盘上的1TB数据分割为40块(chunks),每份25GB。(尽量预留一定空间!)
- 顺序将每份25GB数据读入内存,使用算法排序(大数据情况下最好选择快排)。
- 把排序好的数据(也是25GB)存放回磁盘。
- 循环40次以后,即所有的40个块都已经各自排序了。(剩下的工作就是如何把它们合并排序!)
- 合并排序就是将所有块一起排序,但是只有25GB可用内存,所以先对40块的每一块进行分割。
- 从40个块中分别读取25G/40=0.625G入内存(40 input buffers)。
- 执行40路合并,并将合并结果临时存储于2GB 基于内存的输出缓冲区中。当缓冲区写满2GB时,写入硬盘上最终文件,清空输出缓冲区。
- 当40个输入缓冲区中任何一个处理完毕时(40个块都是有序的,数据小的块会优先处理完),写入该缓冲区所对应的块中的下一个0.625GB则会进入排序中,直到全部处理完成。
了解完 分而治之 之后,再来了解一个概念:磁盘预读。
2、磁盘预读
磁盘预读是一种优化文件读写性能的技术手段 。在计算机中,当需求读取文件时,系统会先预读取一定量的文件数据到内存中,以提高后续读取的效率。这是基于磁盘的物理特性,通过提前读取数据并加载到缓存中,从而加快文件的读取速度。
原理:在读取磁盘数据时,系统会自动预读取相邻的数据块到内存中。预读取的大小一般为一个或多个簇(cluster),也就是连续的物理块,通常为4KB或8KB等常见大小。我们在进行数据读取的时候,一般选择页的整数倍进行读取。这是因为磁盘读取数据时,需要转动磁盘、定位磁头等操作,这些操作需要一定的时间,而预读取可以在等待时间内同时读取更多的数据,减少后续读取时的等待时间。
例如:MySQL默认引擎Innodb每次读取16KB的数据。
3、MySQL索引是什么
了解了MySQL数据库中行记录信息存储在磁盘中,又知道数据库需要响应业务在短时间返回数据,这就需要一定的方式去获取数据!例如在文件夹中寻找一个信息需要经历以下条件:
文件名称+偏移量(offset)+长度(length)
MySQL数据库也不例外。MySQL是采用B+树作为数据结构。
1、B+树
MySQL主要使用B+树作为其索引的数据结构。B+树是B-树的变体,B+树不是直接的k-v存储。
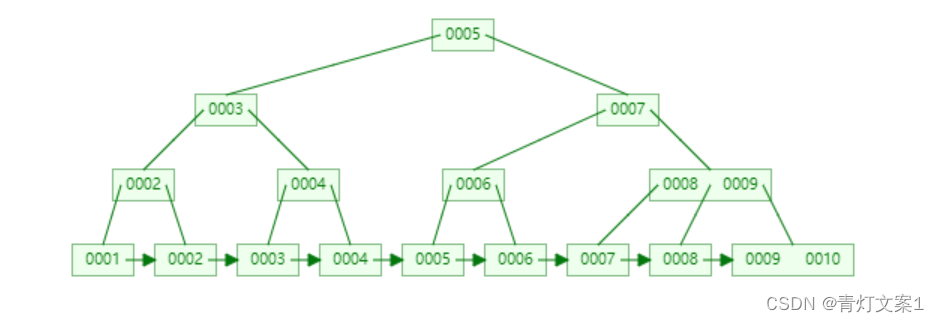
B+树是一种树数据结构,是一个n叉排序树,每个节点通常有多个孩子。它包含根节点、内部节点和叶子节点。在B+树中,非叶子节点只存储关键字信息,用于索引,并不保存具体的数据值,而所有的数据值都保存在叶子节点中。此外,叶子节点之间通过 指针 相连,以维护数据的 有序性。
可以将B+树视为一种特殊的键值存储结构。在B+树中,每个关键字(或键)对应一个值,这些值存储在叶子节点中。通过查找关键字,可以定位到包含相应数据的叶子节点,从而实现数据的检索。这就是MySQL查找数据的方式。
2、索引
索引是帮助数据库高效获取数据的数据结构。它是一张描述索引列的列值与元表中记录行之间一一对应关系的序表。索引除了包含数据本身外,还维护着一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,以实现高级查找算法。具体来说,索引是一个指向表中数据的指针,数据库系统可以利用这些指针快速找到所需的数据,而无需扫描整个表。
主要作用如下:
- 提高查询速度: 通过索引,数据库系统可以不必扫描整个表,而是直接定位到包含所需数据的行,从而显著减少查询时间。这对于大型表来说尤为重要。
- 加速表与表之间的连接: 在执行连接操作时,如果连接字段已经被索引,那么数据库系统就可以更快地找到匹配的记录,从而提高连接操作的速度。
- 优化排序和分组操作: 如果经常需要对表中的数据进行排序或分组,那么对排序或分组字段建立索引可以显著提高这些操作的性能。
- 保证数据的唯一性: 通过创建唯一索引,可以确保表中的每一行数据的某个字段或某几个字段组合的值是唯一的,从而避免重复数据的出现。
虽然索引可以提高查询性能,但它也会占用额外的磁盘空间,并可能增加插入、删除和更新操作的开销。 因此,在创建索引时需要根据实际情况进行权衡,选择最合适的索引策略。同时,也需要定期维护和优化索引,以确保其始终保持良好的性能。
4、索引设计有哪些原则
索引设计在数据库和信息检索系统中起着至关重要的作用,通俗来讲,索引就是数据库表中某个比较有能力的字段, 好的索引直接会影响查询的性能和效率。
以下是一些关键的索引设计原则:
- 唯一性原则:数据库表结构在设计时判断有没有唯一性字段,如果没有可以提前设计自增主键,通常都是有唯一性字段的。唯一字段作为索引不仅可以加速查询,还可以确保数据的完整性。
- 选择性原则:优先选择性高的列即不同值的比例高的列。具有高选择性的列可以使得查询结果集更小,从而提高查询效率。
- 覆盖索引原则:如果一个索引包含了查询需要的所有字段,那么查询就只需要扫描索引,而无需回表获取数据,这被称为覆盖索引。设计索引时,应尽可能使索引覆盖更多的查询场景。
- 小索引原则:尽量使索引键的长度小,因为小的索引键不仅节省存储空间,还能提高查询效率。例如,对于字符串类型的字段,可以考虑使用前缀索引。
- 最左前缀原则:对于复合索引,即包含多个字段的索引,查询条件应尽量使用索引的最左字段,这样可以最大限度地利用索引。
- 更新频率原则:索引虽然可以加速查询,但也会增加数据更新的开销。因此,对于频繁更新的字段,应谨慎考虑是否为其创建索引。
- 数量限制原则:索引并不是越多越好。过多的索引不仅会占用更多的存储空间,还会降低写操作的性能。
- 定期维护原则:索引的性能会随着数据的变化而发生变化。因此,应定期对索引进行优化和维护,确保其保持良好的性能。















 249
249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









