







赫夫曼的作用和效果这里不再叙说,这里只是我的实现。
- 实现原理
在数据结构(C语言版)中有详细的描述关于如何创建一颗赫夫曼树,也就是赫夫曼算法:
**(1)根据给定的n个权值构成n棵二叉树集合F,每棵二叉树的左右节点为空。
(2)在F中选取两棵根节点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根节点的权值为其左右子树上根节点的权值之和。
(3)在F中删除这两棵树,同时将新得到的二叉树插入F中。
(4)重复(2)和(3),直到F中只含一棵树为止。这棵树便是赫夫曼树。**
- 结构体声明和类声明
struct Hfm_info
{
Hfm_info(int a=0,char='\0');//构造函数
int weight; //权值
char ch; //字符
};这个结构体表示基本的节点信息,weight表示权值,ch表示字符。这里的构造函数是为了创建结构体方便,后面会说到这个问题。
struct Hfm_node
{
Hfm_info hfm_info;
Hfm_node *left;
Hfm_node *right;
};哈夫曼树的节点结构体,left表示左子树,right表示右子树。
typedef list<Hfm_node *>::iterator Hfm_iterator;这个typedef为了代码的书写方便,因为我使用了STL中的list容器来存储节点信息。
下面是赫夫曼树的类声明:
class Hfm_tree
{
public:
Hfm_tree(const vector<Hfm_info>&);//构造函数
~Hfm_tree();//析构函数
void print();//打印字符的赫夫曼编码
private:
Hfm_node *get_new_node(const Hfm_info&);//new一个Hfm_node结构体
void create_tree(); //完成主要的工作
void get_need_iterator(Hfm_iterator &min,Hfm_iterator &b_min);//得到集合中最小的连个权值的迭代器
void destory(Hfm_node *);//帮助析构函数释放内存
void prt(const Hfm_node *,int);//完成主要的打印工作
Hfm_tree(const Hfm_tree&); //forbid ==
void operator =(const Hfm_tree&);
Hfm_node *head; //The tree head
list<Hfm_node *> list_node; //save the point node of hfm
vector<int> array;
};
这个类声明中,需要注意,我的list_node存储的是Hfm_node*类型,而不是Hfm_node类型。array这个vector容器只是为了打印字符编码时候的帮助变量,后面会用到。
- 实现
首先是Hfm_indo结构体的构造函数:
Hfm_info::Hfm_info(int weight,char ch):weight(weight),ch(ch) {}接下来是Hfm_tree的构造函数:
Hfm_tree::Hfm_tree(const vector<Hfm_info> & info):head(NULL),list_node(),array(10,-1)
{
assert(!info.empty());
vector<Hfm_info>::const_iterator p=info.begin();
for(;p!=info.end();++p)
list_node.push_back(get_new_node(Hfm_info(p->weight,p->ch)));//根据传进来的信息,构建Hfm_node,并将指针存入list_node中,构建集合F
create_tree(); //创建赫夫曼树
}这里我为了方便,只写了一个构造函数,实际上应该最起码有一个默认的构造函数。拷贝构造函数和重载赋值操作符应该也是应该有的额,但是这些对我们的实现没有任何作用,为了偷懒,我就没写这些东西。
下面是算法的实现函数,create_tree()函数:
void Hfm_tree::create_tree()
{
Hfm_node *n_node=NULL;
while(!list_node.empty())
{
if(list_node.size()==1)//如果集合中只剩下一个节点,即为赫夫曼树
{
head=list_node.front();
list_node.clear();
return;
}
Hfm_iterator min,b_min;
get_need_iterator(min,b_min);//获得最小权值的两个节点的迭代器
n_node=get_new_node(Hfm_info((*min)->hfm_info.weight + (*b_min)->hfm_info.weight,'\0'));//新的节点
n_node->left=*min;
n_node->right=*b_min;
list_node.push_back(n_node);//插入新的节点
list_node.erase(min);//删除工作
list_node.erase(b_min);
}
}这个函数的逻辑很简单,如果list_node中只剩下一个节点,那么这个节点就是赫夫曼树,如果不是,就按照算法的思想,找到最小的两个权值的节点,用他们构造一棵新的二叉树,并且设置其权值,更新新节点的左右子树,在集合中新加入新二叉树,删除最小的两个节点。
下面是得到最小权值的两个节点的迭代器的代码:
void Hfm_tree::get_need_iterator(Hfm_iterator &min,Hfm_iterator &b_min)
{
Hfm_iterator p=list_node.begin();
min=p;b_min=++p;
if((*b_min)->hfm_info.weight < (*min)->hfm_info.weight)
{
Hfm_iterator pp=b_min;
b_min=min;
min=pp;
}
for(++p;p!=list_node.end();++p)
{
if((*p)->hfm_info.weight < (*b_min)-> hfm_info.weight)
{
if((*p)->hfm_info.weight < (*min)-> hfm_info.weight)
{
b_min=min;
min=p;
}
else
{
b_min=p;
}
}
}
}这个思路就是首先更新min和b_min为集合的前两个元素,且必须保证min的权值小于b_min,然后遍历整个集合,分别于min于b_min的权值比较,然后更新其值,始终保证min与b_min为当前的最小权值的节点的迭代器,当遍历终止后,这两个迭代器就是我们需要的,当然还有就是进行两次冒泡排序,当然,这种实现这里没有采用。
下面是get_new_node()函数:
Hfm_node *Hfm_tree::get_new_node(const Hfm_info& info)
{
Hfm_node *p=NULL;
p=new Hfm_node;
assert(p!=NULL);
p->hfm_info=info;
p->left=NULL;
p->right=NULL;
}很简单的实现,没什么技术含量。
下面是打印的实现:
void Hfm_tree::print()
{
prt(head,0);
}这里使用了回溯法来打印这些赫夫曼编码,可以发现,所有的一切都在prt函数中实现。
void Hfm_tree::prt(const Hfm_node *head,int i)
{
if(head ==NULL)
return;
if(head->hfm_info.ch!='\0')
{
for(int j=0;j<10;j++)
{
if(array[j]!=-1)
cout<<array[j]<<" ";
else
break;
}
cout<<head->hfm_info.ch<<endl;
}
if(head->left!=NULL)
{
array[i]=0;
prt(head->left,i+1);
array[i]=-1;//这里必须有
}
if(head->right!=NULL)
{
array[i]=1;
prt(head->right,i+1);
array[i]=-1;//同上
}
}这个函数的第二个参数指的是array函数的索引值,只要遇到叶子ch不是‘\0’就打印当前的array容器的值,最后打印这个字符,当然这个实现是有一定缺陷的,如果我们需要对‘\0’编码,就会出现问题,这里应该检验的是左右子树都为空,这里只为了方便,不是重点。
析构函数的实现也是递归:
Hfm_tree::~Hfm_tree()
{
destory(head);
}
void Hfm_tree::destory(Hfm_node *head)
{
if(head ==NULL )
return;
destory(head->left);
destory(head->right);
delete head;
}没什么好说的。
- 代码测试
这里是测试代码:
int main()
{
vector<Hfm_info> array;
array.push_back(Hfm_info(7,'a'));
array.push_back(Hfm_info(5,'b'));
array.push_back(Hfm_info(2,'c'));
array.push_back(Hfm_info(4,'d'));
Hfm_tree hfm_tree(array);
hfm_tree.print();
}专门给Hfm_info写一个构造函数,就是为了这个时候能方便一点。
这个函数的值就是书上给的一个例子,最后的二叉树构造的结果是这样的
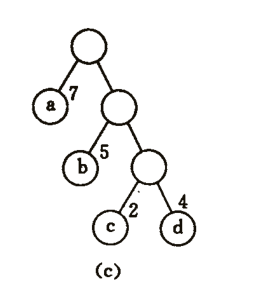
这里我们可以看到结果:
a 0
b 1 0
c 1 1 0
d 1 1 1
运行我们的程序,查看结果:
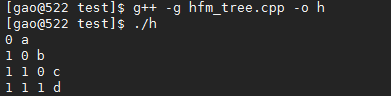
可以看到结果和我们预测的结果一样。
最后,希望大家多多提提意见。















 1275
1275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









