









一、Pix2Text正常识别图片内容的代码
先上源码,这是一个通过Pix2Text来识别图片内容的脚本,Pix2Text识别精度和速度都还不错,主要是能有效识别公式,并生成laTex代码。
import os
import glob
from pix2text import Pix2Text, merge_line_texts
# 获取待识别的图片列表
img_fp_list = glob.glob(r'E:\code\python\textRecognition\data\test\pic1.*.png')
for img_fp in img_fp_list:
# 新建pix2text对象,mfd是默认模式
p2t = Pix2Text(analyzer_config=dict(model_name='mfd'))
try:
print("---start to recognize---")
# 开始识别,得到该图片的识别结果
outs = p2t.recognize(img_fp) # can also use `p2t.recognize(img_fp)` or 'p2t(img_fp, resized_shape=600)'
print("---over---")
except Exception as e:
print("---error---")
print(e)
if outs:
# 将内容拼接到一起
img_name = img_fp.split('\\')[-1]
out_fp = img_fp.replace(img_name, 'pix2text.txt')
with open(out_fp, 'a', encoding='utf-8') as f:
f.write(outs)
outs = None这个源码大多数情况都能执行,有需要的兄弟请自取。(注意,有博客说outs = p2t.recognize(img_fp)的返回值是一个字典,但是我的返回值是个字符串,可能和版本有关,这个看具体的情况来修改读取和拼接的代码)
二、对于部分图片执行时出现的“list index out of range”报错
通过try-except是报这个错,如果不try直接跑应该会直接报源码的错,但是源码报错一般都是自己代码写错了,很难判断具体的原因。
这篇博客是要解决一个莫名其妙的bug,在双列识别时,内容量过多所出现的“list index out of range”报错。
举个例子,笔者识别这些图片都没问题


但是同一篇论文,同一种格式的图片产出,这样的图片就会报错

经过测试,发现只要是内容满满荡荡的就会报错,稍微有点空行、图片、表格什么的还是能正常识别,追溯到源码,发现问题出在源码的utils.py的merge_line_text当中。
三、解决方案(小白操作版,后面有原因推测)
现在提供一种解决的思路:
①先ctrl+点击p2t.recognize,进入到pix_to_text.py


②在pix_to_text.py中,找到344行的merge_line_texts方法,ctrl+点击它进入utils.py(如果找不到这个方法直接ctrl+f搜索也是可以的)

③在utils.py中,大概在710+行的位置,找到这个循环,将if(我注释掉的就是原代码)改成while即可。
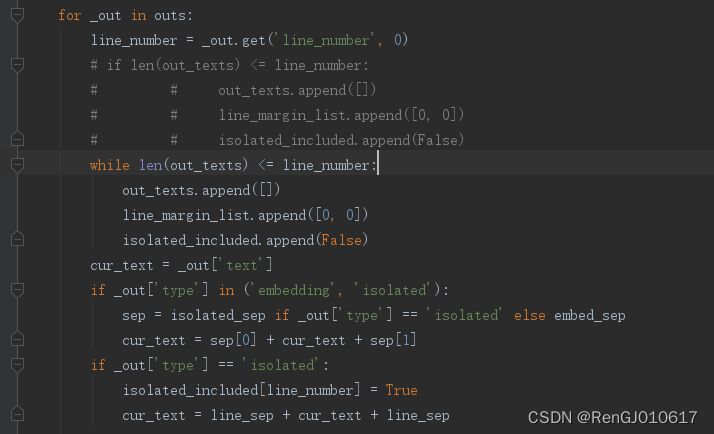
④原因推测
简单说一下报错原因,这里其实是pix2Text的开发者在遍历识别结果_out,按照line_number和type的值拿出不同的内容,但是可能存在空行或者其他原因,经常会出现line_number并没有递增,而是突然从15变成17这样的情况,那么后面执行的时候,out_texts扩容速度跟不上导致out_texts[line_number]这个操作超出数组限制,导致报错。于是开发者添加了一个判断,如果在某一轮次出现了len(out_texts) <= line_number的情况,就给out_texts多扩容一次,但这里有个逻辑错误,if判断只能执行一次,事实上只有len(out_texts) = line_number的时候扩容一次是有效的,所有len(out_texts) < line_number的情况扩容一次是解决不了问题的。恰好我就遇到了这种情况,于是将if改成wihle,不断地扩容直到刚好len(out_texts) > line_number,这样就能正常运行了。
至于为什么一定是内容满满当当的论文图片才会有这种错误,这就要看Pix2Text所依赖的OCR引擎CnOCR的执行逻辑了,这个我目前还没有过深的接触,有懂的大佬可以在评论区解释一下。
总之,有时候报错并不是你代码有问题,源码出错也是很常见的情况,比如之前使用mxgraph也出现了不知名bug,最后也是修改的源码解决的。有疑问欢迎交流~














 1153
1153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









