






1.概览
在本文中我们将了解Apache Calcite。它是一个强大的数据管理框架,可以应用于各种与数据访问相关的场景。Calcite的重点在于从任何源头获取数据,而不是存储数据。另外,它的查询优化功能使得数据获取更快、更高效。
接下来,我们将深入探讨更多细节,首先从Apache Calcite的应用场景开始。
2. Apache Calcite 用例
由于其强大的功能,Apache Calcite可以在多个应用场景中发挥作用:

为新数据库构建查询引擎需要花费很多时间。然而,Calcite提供了一个即插即用的可扩展SQL解析器,验证器和优化器,使我们能够立即开始工作。Calcite已经被应用于构建诸如HerdDB,Apache Druid,MapD等等的数据库。
由于Calcite能够与多个数据库集成,因此它在构建数据仓库和商业智能工具,中得到了广泛的应用。如Apache Kyline,Apache Wayang,阿里巴巴MaxCompute等等。
Calcite是流处理平台的重要组成部分,如Apache Kafka,Apache Apex和Flink等,它们帮助构建能够展示和分析实时数据流的工具。
3.任意来源数据获取
Apache Calcite提供了现成的适配器来集成第三方数据源,包括Cassandra,Elasticsearch,MongoDB等等
3.1 重要的类
Apache Calcite提供了一个强大的数据获取框架。这个框架是可扩展的,所以也可以创建自定义的新适配器。下面我们来看看一些重要的Java类。

Apache Calcite适配器提供了如ElasticsearchSchemaFactory,MongoSchemaFactory,FileSchemaFactory等类,它们实现了SchemaFactory接口。SchemaFactory通过在JSON/YAML模型文件中创建虚拟Schema,帮助以统一的方式连接底层数据源。
3.2 CSV适配器
现在让我们看一个例子,我们将使用SQL查询从CSV文件中读取数据。让我们从在pom.xml文件中导入使用文件适配器所需的必要Maven依赖开始
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-core</artifactId>
<version>1.36.0</version>
</dependency>
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-file</artifactId>
<version>1.36.0</version>
</dependency>
接着编写模型配置
{
"version": "1.0",
"defaultSchema": "TRADES",
"schemas": [
{
"name": "TRADES",
"type": "custom",
"factory": "org.apache.calcite.adapter.file.FileSchemaFactory",
"operand": {
"directory": "trades"
}
}
]
}
在model.json中指定的FileSchemaFactory查看trades目录下的CSV文件,并创建一个虚拟的TRADES schema。随后,trades目录下的CSV文件被视为表格。
tradeid:int,product:string,qty:int
232312123,"RFTXC",100
232312124,"RFUXC",200
232312125,"RFSXC",1000
CSV文件有三列:tradeid,product和qty。此外,列标题还指定了数据类型。总共,CSV文件中有三个交易记录。
model.json文件、TRADE.csv均放在resource目录下。
最后,让我们看看如何使用Calcite适配器获取记录:
import static org.junit.Assert.assertEquals;
import java.net.URL;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import org.junit.Test;
public class CsvTest {
@Test
public void whenCsvSchema_thenQuerySuccess() throws SQLException {
String fileName = "model.json";
Properties info = new Properties();
info.put("model", getPath(fileName));
try (Connection connection = DriverManager.getConnection("jdbc:calcite:", info);) {
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("select * from trades.trade");
assertEquals(3, resultSet.getMetaData().getColumnCount());
List<Integer> tradeIds = new ArrayList<>();
while (resultSet.next()) {
tradeIds.add(resultSet.getInt("tradeid"));
}
assertEquals(3, tradeIds.size());
}
}
private String getPath(String model) {
URL url = ClassLoader.getSystemClassLoader().getResource(model);
return url.getPath();
}
}
Calcite适配器使用模型属性来创建一个模拟文件系统的虚拟schema。然后,它使用常规的JDBC语义从trade.csv文件中获取记录。
文件适配器不仅可以读取CSV文件,还可以读取HTML和JSON文件。此外,为了处理CSV文件,Apache Calcite还提供了一个特殊的CSV适配器,用于处理使用CSVSchemaFactory的高级应用场景。
3.3. In-Memory SQL Operation on Java Objects
3.3 通过SQL访问Java内存对象
类似于CSV适配器的例子,让我们看另一个例子,借助Apache Calcite,我们将在Java对象上运行SQL查询。
假设CompanySchema类中有Employee和Department类的两个数组:
public class CompanySchema {
public Employee[] employees;
public Department[] departments;
}
public class Employee {
public String name;
public String id;
public String deptId;
public Employee(String name, String id, String deptId) {
this.name = name;
this.id = id;
this.deptId = deptId;
}
}
public class Department {
public String deptId;
public String deptName;
public Department(String deptId, String deptName) {
this.deptId = deptId;
this.deptName = deptName;
}
}
假设有三个部门:财务,市场和人力资源。我们将在CompanySchema对象上运行一个查询,以找出每个部门的员工人数:
import static org.junit.jupiter.api.Assertions.assertDoesNotThrow;
import calcite.memSql.CompanySchema;
import calcite.memSql.Department;
import calcite.memSql.Employee;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
import org.apache.calcite.adapter.java.ReflectiveSchema;
import org.apache.calcite.jdbc.CalciteConnection;
import org.apache.calcite.schema.Schema;
import org.apache.calcite.schema.SchemaPlus;
import org.junit.Before;
import org.junit.Test;
public class inMemTest {
static CompanySchema companySchema = new CompanySchema();
@Before
public void setup() {
Department dept1 = new Department("HR", "Human Resource");
Department dept2 = new Department("MKT", "Marketing");
Department dept3 = new Department("FIN", "Finance");
Employee emp1 = new Employee("Tom", "1234", "HR");
Employee emp2 = new Employee("Harry", "39731", "FIN");
Employee emp3 = new Employee("Danny", "45632", "FIN");
Employee emp4 = new Employee("Jenny", "78654", "MKT");
companySchema.departments = new Department[]{dept1, dept2, dept3};
companySchema.employees = new Employee[]{emp1, emp2, emp3, emp4};
}
@Test
public void whenQueryEmployeesObject_thenSuccess() throws SQLException {
Properties info = new Properties();
info.setProperty("lex", "JAVA");
Connection connection = DriverManager.getConnection("jdbc:calcite:", info);
CalciteConnection calciteConnection = connection.unwrap(CalciteConnection.class);
SchemaPlus rootSchema = calciteConnection.getRootSchema();
Schema schema = new ReflectiveSchema(companySchema);
rootSchema.add("company", schema);
Statement statement = calciteConnection.createStatement();
String query = "select dept.deptName, count(emp.id) "
+ "from company.employees as emp "
+ "join company.departments as dept "
+ "on (emp.deptId = dept.deptId) "
+ "group by dept.deptName";
assertDoesNotThrow(() -> {
ResultSet resultSet = statement.executeQuery(query);
while (resultSet.next()) {
System.out.println("Dept Name:" + resultSet.getString(1)
+ " No. of employees:" + resultSet.getInt(2));
}
});
}
}
该方法运行良好并且也获取到了结果。在该方法中,Apache Calcite类ReflectiveSchema帮助创建了CompanySchema对象的模式。然后它运行SQL查询并使用标准的JDBC语义获取记录。
这个例子证明了,无论源是什么,Calcite都可以使用SQL语句从任何地方获取数据。
4.查询处理
查询处理是Apache calcite的核心功能。
标准的JDBC驱动程序或SQL客户端在数据库上执行查询。相比之下,Apache Calcite在解析和验证查询后,会智能地优化它们以实现高效执行,节省资源并提高性能。
4.1解析查询处理步骤
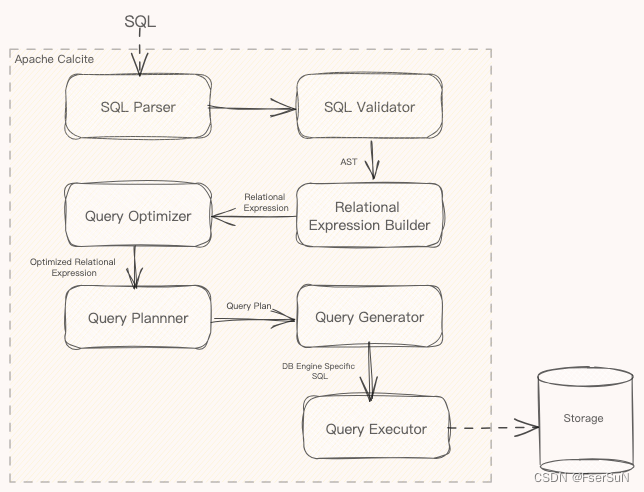
我们也可以扩展这些组件以满足任何数据库的特定要求。让我们更详细地了解这些步骤。
4.2 SQL 解析与验证
作为解析过程的一部分,解析器将SQL查询转换为名为AST(抽象语法树)的树状结构。
假设在两个表,Teacher和Department上的SQL查询:
Select Teacher.name, Department.name
From Teacher join
Department On (Department.deptid = Teacher.deptid)
Where Department.name = 'Science'
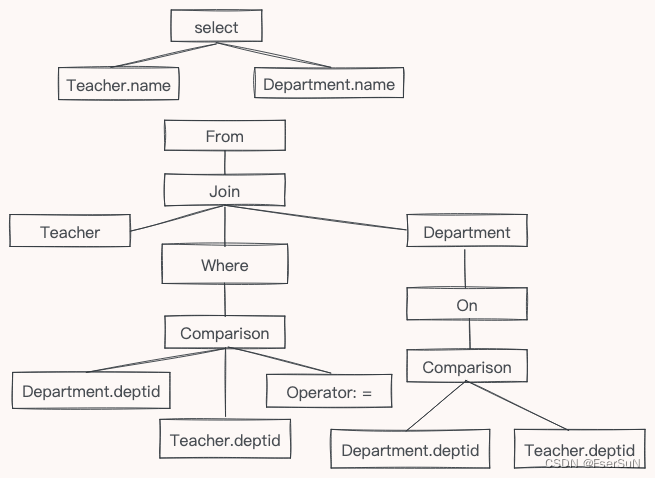
接下来,验证器会在语义层面上验证节点:
验证函数和运算符 根据数据库的目录验证数据库对象,如表和列
4.3. 关系表达式构建器
接下来,在验证步骤之后,关系表达式构建器会使用一些常见的关系运算符来转换语法树:
LogicalTableScan:从表中读取数据
LogicalFilter:根据条件选择行
LogicalProject:选择要包含的特定列
LogicalJoin:根据匹配的值从两个表中合并行 考虑到之前展示的AST,从中得到的对应的逻辑关系表达式将是:
LogicalProject(
projects=[
$0.name AS name0,
$1.name AS name1
],
input=LogicalFilter(
condition=[
($1.name = 'Science')
],
input=LogicalJoin(
condition=[
($0.deptid = $1.deptid)
],
left=LogicalTableScan(table=[[Teacher]]),
right=LogicalTableScan(table=[[Department]])
)
)
)
在关系表达式中,$0和$1代表Teacher和Department表。基本上,这是一个数学表达式,帮助我们理解要执行哪些操作才能得到结果。然而,它并没有包含执行相关的信息。
4.4. 查询优化器
然后,Calcite优化器对关系表达式进行优化。一些常见的优化包括:
谓词下推:尽可能将过滤器推近到数据源,以减少获取的数据量 联接重排序:重新排列联接顺序以最小化中间结果并提高效率 投影下推:下推投影以避免处理不必要的列 索引使用:识别和利用索引以加速数据检索
4.5 查询计划器,生成器和执行器
在优化之后,Calcite查询计划器会为执行优化后的查询创建一个执行计划。执行计划指定了查询引擎获取和处理数据的确切步骤。这也被称为特定于后端查询引擎的物理计划。
然后,Calcite查询生成器会在特定于所选执行引擎的语言中生成代码。
最后,执行器会连接到数据库执行最终的查询。
5. 总结
在这篇文章中,我们探讨了Apache Calcite的能力,它能快速地为数据库提供标准化的SQL解析器,验证器和优化器。这让供应商无需花费太多时间开发查询引擎,使他们能够优先考虑后端存储。此外,Calcite的适配器简化了与各种数据库的连接,有助于开发统一的集成接口。
更进一步,通过利用Calcite,数据库开发者可以加快产品上市的时间,同时提供强大、多功能的SQL功能。
附录
源码:https://github.com/eugenp/tutorials/tree/master/persistence-modules/java-calcite















 1213
1213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









