









用R语言已经有一段时间了,R语言的统计以及作图功能的确十分强大,暑假我也看完了《基于R语言的网络数据采集》一书,算是对爬虫有了初步的了解。
在看完那本书之后我也写了一些爬虫,爬过厦大的图书馆,爬过京东的暴风魔镜评论,爬过厦大周围外卖的评论,爬过蚂蚁短租,效果还是不错的。但在我爬取拉勾网的时候就出现问题了,我想爬取拉勾网量化投资的招聘信息,用谷歌的开发者工具可以知道向
http://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false
网址发送三个变量first=false pn=2 kd='量化投资' 即可获得想要的json数据,first关键字不知道是什么鬼,pn是页码,kd是搜索的关键词。首先先看R语言的效果,先上代码
library(RCurl)
library(stringr)
url <- 'http://www.lagou.com/jobs/positionAjax.json?
needAddtionalResult=false'
doc <- postForm(url,.params = list(first = 'false',pn = 2,kd = '量化投资'))
cat(doc)
cat(str_replace_all(doc,',','\n'))再看效果:
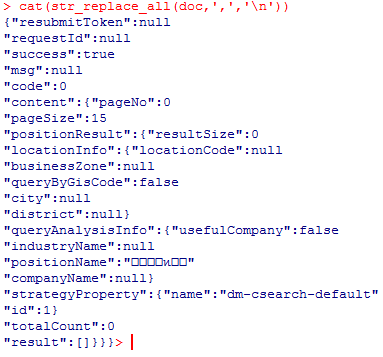
显然,这里返回的数据为空的。懂R语言的人可能会说,R语言中逻辑型变量是大写而且不用引号,那我们再试把代码换成first = FALSE 试试。再次上图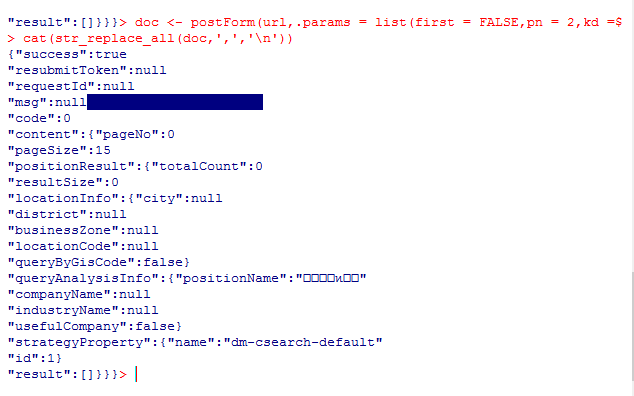
又是空的,这真的很让人抓狂,之前我还尝试过给post请求加一个句柄来更加真实的模拟浏览器,但是仍然没有效果,即使有效果我也不想在这种小爬虫上浪费太多精力,还是直接看Python吧。老规矩,先上代码:
import requests
url = 'http://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
data = {'first':'false','pn':2,'kd':'量化投资'}
html = requests.post(url,data)
doc = html.json()
print(doc)看Python的效果:
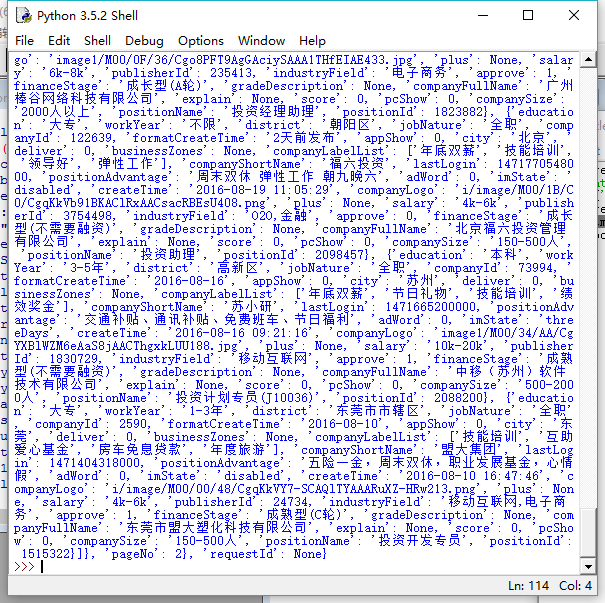
可见此次得到的数据是正确的,以后要学习一下Python了,并且为了达到好的学习效果,会不定期地写一下博客。















 2226
2226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









