






Pytorch 目标检测通过fssd训练自己的数据集
参考文章
代码参考:fssd-pytorch实现代码
1、下载代码
2、整理自己的数据集
- 根据VOC的格式整理自己的数据集,xml文件放到Annotations文件夹下面。然后Main放自己的数据集划分,格式如下面的val.txt格式。
- 更改一些数据集的代码
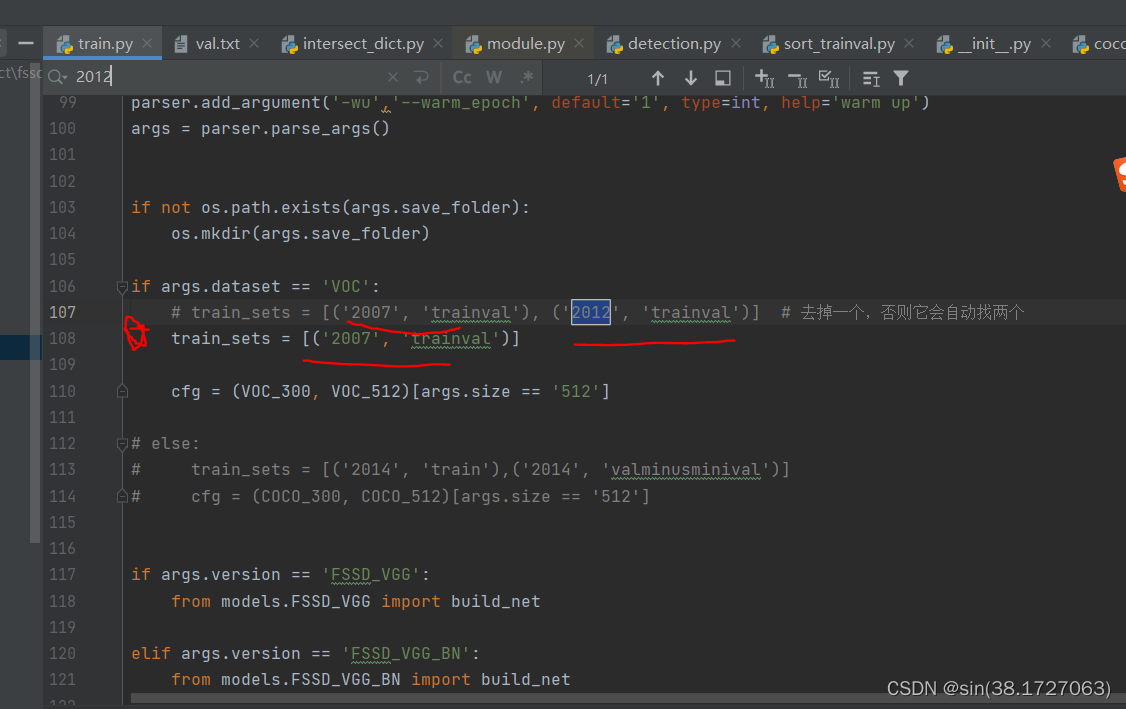
因为只用到一个数据集,所以不需要将两个数据集都弄上,否则检查会报错。就在train.py那里进行更改即可。根据数据集命名方式进行更改即可。
3、选用VOC格式将COCO相关内容进行注释
在train.py中


 在data.init_.py中
在data.init_.py中
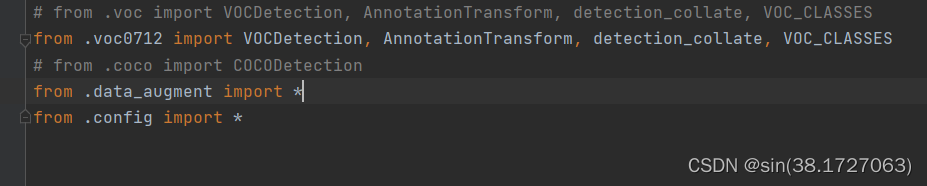
4、在data/voc0712.py中将检测类型改成自己要检测的类型
5、修改FSSD——VGG.py文件中的build_net的num_class修改为自己的种类(+背景)
6、因为pytorch版本问题,把VGG中的RELU(inplace)进行修改:
RELU(inplace=True)
RELU(inplace=False)
7、使用预训练模型进行训练
- 如果是只使用vgg16作为预训练模型,那么resume_net这里就不用管。
- 如果用别的预训练模型,如代码网站上的已经训练好的作为预训练模型,那么就得更改一些地方。
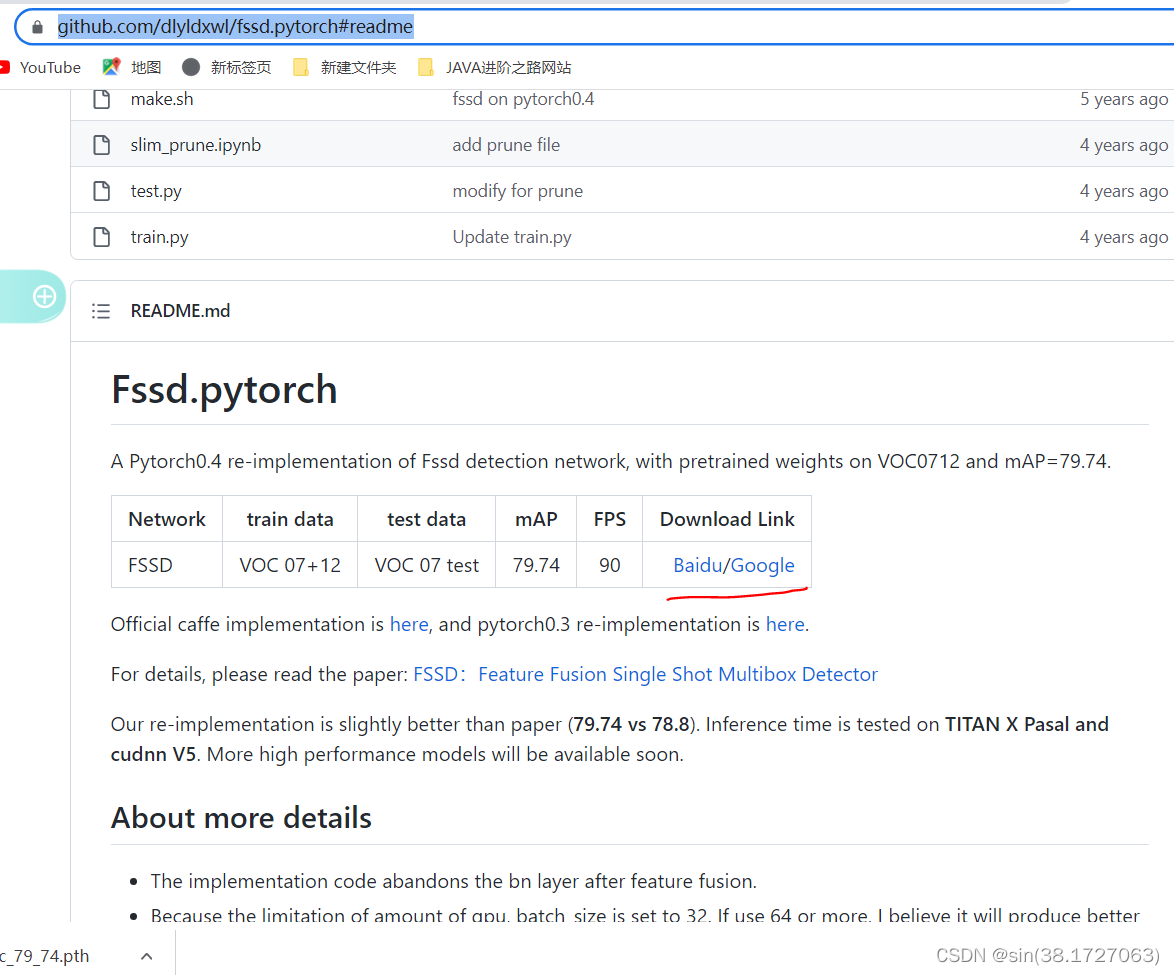
更改参数resume:
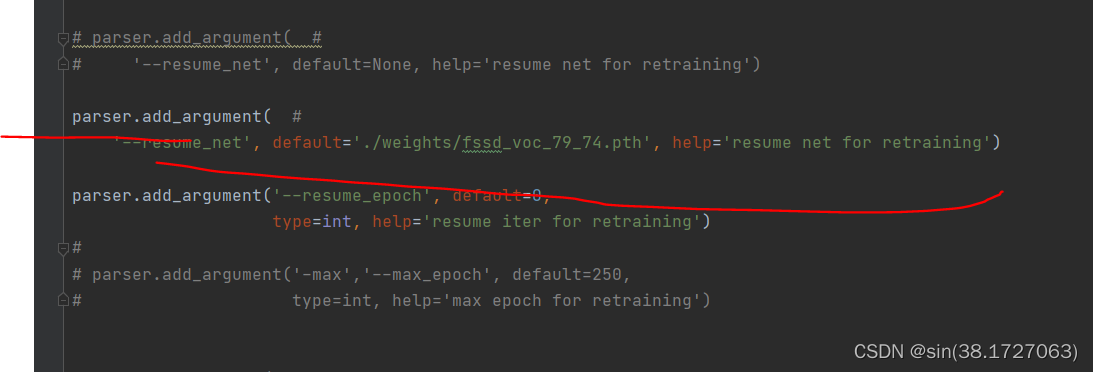
因为权重文件上有不能兼容模型的输入和输出的部分,所以需要定义交叉取值函数。

定义网络结构交叉取值函数
# 关键自定义函数
def intersect_dicts(da, db, exclude=()):
"""输入参数
da (state_dict) 加载权重的 state_dict
db (state_dict) 加载模型的 state_dict
exclude (list) 不想要的权重 keys()
返回参数
加载的部分权重 (state_dict)
"""
'''
print("exclude",exclude)
for k, v in da.items():
for x in exclude:
if x in k:
print('@ ',x ,k)
if v.shape != db[k].shape:
print('# ', x, k)
'''
return {k: v for k, v in da.items() if k in db and not any(x in k for x in exclude) and v.shape == db[k].shape}
else:
def xavier(param):
init.xavier_uniform(param)
def weights_init(m):
for key in m.state_dict():
if key.split('.')[-1] == 'weight':
if 'conv' in key:
# init.kaiming_normal(m.state_dict()[key], mode='fan_out')
init.kaiming_normal_(m.state_dict()[key], mode='fan_out')
if 'bn' in key:
m.state_dict()[key][...] = 1
elif key.split('.')[-1] == 'bias':
m.state_dict()[key][...] = 0
# 这里先对 不需要从权重载入的部分进行初始化。
print('Initializing weights...')
# initialize newly added layers' weights with kaiming_normal method
net.extras.apply(weights_init)
net.loc.apply(weights_init)
net.conf.apply(weights_init)
net.ft_module.apply(weights_init)
net.pyramid_ext.apply(weights_init)
print('Loading resume network')
# state_dict = torch.load(resume_net) # 这个地方进行重载新的网络
state_dict = torch.load(args.resume_net) # 这个地方进行重载新的网络
# create new OrderedDict that does not contain `module.`
print('net',net) # 先看看net长什么样子
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in state_dict.items():
print('key: ',k)
# print('value: ',v)
head = k[:7]
if head == 'module.':
name = k[7:] # remove `module.`
else:
name = k
new_state_dict[name] = v
# 权重取舍处理
net_dict1234=net.state_dict()
state_dict1234 = intersect_dicts(new_state_dict, net_dict1234, exclude=['loc.4.weight','loc.4.bias','conf.4.weight','conf.4.bias']) # 将不兼容的部分排除掉,不进行载入
# net.load_state_dict(new_state_dict) # 这里改造一下,不用一次性全部输入,而是一个一个键的输入即可
net.load_state_dict(state_dict1234,strict=False) # 这里改造一下,不用一次性全部输入,而是一个一个键的输入即可
然后就可以训练自己的模型了。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









