









头文件是堆排序的代码,mian函数是一个测试样例

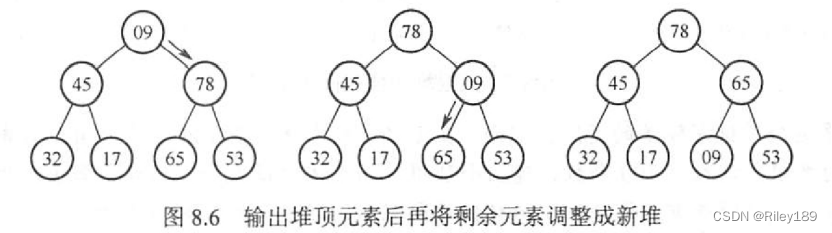
实际原理理解起来还是很简单的,就是建立大根堆,然后每次利用大根堆的第一个数(最大)和最后一个叶节点交换,然后将这个叶节点从树中删去(因为已经排到了他该在位置,就是当前的还没有排序好的最大值,放在最末尾),然后利用保持大根堆特性,将头沉沉沉沉到他该在的位置,不断循环。
代码特别注意的点是在:树的第k个位置调整时
heapsort1.h
#pragma once
//要小心的一点是此处的数 data[0]没有存储东西,data从1开始存数据,因为方便对应哈~
template<typename keyname>
void swap(keyname & a, keyname & b) {
keyname temp = a;
a = b;
b = temp;
}
//将heap 第k位置的调整为最大根结构,也就是意味着第k位置的值一定会给他安排到最后的位置上去,一直向下沉到沉不动
template<typename keyname>
void keepHeap(keyname data[], int k, int length) {//length还是实际的树的节点个数,所以数组长度是length+1。其实应该传的是1,length,从多少开头到多少结尾,不过因为这块是一直不动前面的所以不用写
data[0] = data[k];
for (int i = 2 * k; i <= length; i *= 2) {
if (i < length && data[i] < data[i + 1]) ++i;//<length很重要!小心
if (data[0] >= data[i]) break;//这里这一步是不影响算法的稳定性的,影响在其他地方,并且这里只能是break不是return,因为data[k]还是上一个的值,需要覆盖成最开始要调整的值
else {
data[k] = data[i];
k = i;
}
}
data[k] = data[0];//其实也可以用交换的上面也能直接return了,但是交换多了点运算所以选择了一个data[0]
}
template<typename keyname>
void BuildmaxHeap(keyname data[], int length) {//为啥不是从上到下呢,可能这样才能不断地将最大的退退退推上去?
//因为每一轮堆会让小的一直往下沉到它能沉到的位置,而没有往上到头到她想到的位置的一步,所以需要用这个顺序来实现
//这么理解的话,可能要是每次每轮让最上面的飞到她改在的位置,那么这步就需要从上往下走了
//目前想来这两种实现大根堆都是可以的,可能因为后续在找最大值的两者具有差别?dui
//因为后续在做(下一个函数)的时候,最大值和叶子节点换(叶子节点消失),所以需要往下沉,而不是往上冒,因为叶子都没有了
for (int i = length / 2; i > 0; --i) {
keepHeap(data, i, length);
}
}
template<typename keyname>
void heapSort(keyname data[], int length) {
BuildmaxHeap(data, length);
for (int i = length; i > 1; --i) {//--i 不是++i!!!!小心
swap(data[i], data[1]);//1
keepHeap(data, 1, i - 1);//这个i-1真的很美妙
}
}8.6heapsort.cpp
// 8.6heapsort.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//堆排序
#include <iostream>
#include"heapsort1.h"
using namespace std;
int main()
{
int data[9] = { 0,43,35,1,87,99,67,78,10 };//树实际结构标号对应 data[0]无实际含义
int length = 8;
cout << "原数列:" << endl;
for (int i = 1; i <= length; ++i)
cout << data[i] << " ";
cout << endl;
cout << "堆排序数列1:" << endl;
heapSort(data, length);
for (int i = 1; i <= length; ++i)
cout << data[i] << " ";
cout << endl;
}
特别的:
1、用小根堆也是可以的,大根堆之间的区别在于排序结果的顺序和逆序,因为头是能确保是当前的最大(最小)的,而树都是从1-length嘛
即:基于大根堆的堆排序就是得到递增序列,机遇小根堆的堆排序得到就是递减序列
关于时间和空间复杂度:
堆排序,主要分成两步,第一步就是大根堆的建立,第二步就是不断找出最大值(体现了选择排序,为选择排序的一种),复杂度就是取决于这两者
而第一步的复杂度:很神奇!!

一般来想我就直接nlogn,没想到不是的,很神奇这个记住!!!(其实也可以考虑一下交换的次数,但也就是从 2(h-i)变成了3(h-i),还是单纯前面的系数问题
第二步的复杂度还是很好理解哈:
轮n-1轮,然后每次都是调用1位置的大根堆调整,就是一个最多的h-1轮(h深度,但是后面这个深度还会变成越来越小,直到1)但是课本结果是nlogn
所以综上o(n)+o(nlogn)->o(nlogn)
空间复杂度:o(1)
时间复杂度:o(nlogn)上面有写,看两步,o(n)+o(nlogn)->o(nlogn)
稳定性:不稳定,不稳定的原因在于最后最大根节点和最小叶节点的交换存在把顺序换的了情况
适用于:数组可实现,链表不太行,因为有跳跳找的过程
存疑:
关于为啥在树的对应位置调整的时候,是将头不断往下沉,而到了最大堆的建立的时候就变成了从下往上的构建。当时想的就是这两个能不能交换,先树的i位置调整的往上调到他该飞到的位置,然后之后建立大根堆的时候就是从头往下去调整。我目前觉得在大根堆的这步这两种方法都是挺合理的,但是因为此处还是需要去排序,而排序的时候(最大和最后一个叶节点交换,然后将这个叶节点从树中删去,再将第一个节点再去沉沉沉这一步是需要往下沉的,因为叶子没有了不能飞了),而且下一步的树就从原来的长度-1,少的正好是叶子节点就很舒服,还是有点没有把握住...之后再想想。
还有我觉得每个子树在调整中是具有什么性质的,但是我还没有把握住















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









