









kaldi 声纹识别系统(2)代码解读:基于x-vector
主要用来明确kaldi声纹识别的通用流程,以及各个脚本背后源码的思路。
kaldi 声纹识别系统(通用理论 + x-vector举例):
- 通用声纹识别流程
- 控制shell脚本和C++源码
特别说明:该篇默认已经完成了x-vector 模型的训练部分,也就是说这里主要涉及kaldi 中 x-vector模型(sre16/v2)的复用。
预备知识:常用术语
文件
(1)数据准备阶段生成的三个文件
-
utt2spk:(每一行代表)某个说话人以及对应的所有音频名
-
spk2utt:(每一行代表)某个音频名以及对应的说话人(一一对应)
-
wav.scp:(每一行代表)每个音频名对应的完整路径
注:
utt=utterance id,代表音频文件名;spk=speaker id,是说话人名;
详细结构看下表:文件名 格式 utt2spk 每一行:[音频名] [说话人名] spk2utt 每一行:[说话人名] [音频名1] [音频名2][音频名…] wav.scp 每一行:[音频名] [音频文件的具体路径]
(2)区分 .ark 和 .scp
-
.ark:archive,记录实际数据的
表格(table) -
.scp:script,记录数据具体位置的
表格(table)1、
.ark和.scp是 kaldi 中两种记录数据的格式, .ark 是数据(二进制文件),scp 是记录对应 ark 的路径。 .ark 文件一般都是很大的(因为他们里面是真正的数据)
2、.scp:第一列是utterance id,第二列是扩展文件名(extended filename),这里可以先把第二列当作录音文件的路径
脚本名称和文件夹名
| 名称 | 解释 |
|---|---|
| cmd.sh | 用来设置执行命令的方式,通常分为① run.pl(单机运行)② queue.pl (多台计算机并行运算) |
| path.sh | 环境变量相关脚本 |
| run.sh | 整体流程控制脚本,主入口脚本(下面有单独拿出来写) |
| steps | 存放单一步骤执行的脚本 |
| local | 工程定制化内容 |
| utils | 存放解析文件,预处理等相关的脚本 |
| config | 参数定制化配置文件,mfcc等配置 |
| … | … |
run.pl
对于单机执行,通常在 cmd.sh 中配置为 run.pl 即单机多进程执行。
基本用法:run.pl <options> <log-file> <command> (同样适用于queue.pl)
常见两种用法:
run.pl some.log a b c
即在 bash 环境中执行 a b c 命令,并将日志输出到 some.log 文件中run.pl JOB=1:4 some.JOB.log a b c JOB
即在 bash 环境中执行 a b c JOB 命令,并将日志输出到 some.JOB.log 文件中, 其中 JOB 表示执行任务的名称,JOB=1:4表示任务序号标记, 任意一个 Job 失败,整体失败。
更多可以参考:
kaldi 源码分析(三) - run.pl 分析、Kaldi中的并行化
0. 流程控制:总成 run.sh
0.1 通用流程
kaldi中的run.sh是整个声纹识别的流程控制脚本,(不论是哪个声纹模型)主要包含下面的几个基本内容:
-
特殊:参数配置
这部分在这里多说两点:1、修改自己主机或者所用服务器根目录下的
cmd.sh,将里面的"queue.pl",改为"run.pl",并设置一个合适自己计算机的内存大小。
2、打开path.sh(kaldi/egs/sre16/v2)将第一行改成自己的kaldi根目录路径:export KALDI_ROOT=pwd/../..
(pwd是linux指令,会打印出运行指令时的目录) -
Data Preparation
数据准备 -
Make MFCCs and compute VAD
提取 mfcc 特征,进行端点检测(VAD) -
Train the xvector DNN(本篇不作介绍,只用kaldi中现成的)
训练特征提取模型,比如xvector DNN -
Extract feature
提取特征,比如x-vector特征(用于plda模型的输入) -
Train the plda model
训练打分模型(plda模型) -
Compute plda score
获取plda的结果
以上基本算是通用流程的几个步骤,如果具体来看,还有许多其它内容,比如x-vector之前的CMVN处理(倒普均值归一化),下面以x-vector进行初略分析。
0.2 基于 x-vector 的 run.sh (子流程控制)
这里只抽出核心代码来分析。
提取 mfcc 特征
steps/make_mfcc.sh --write-utt2num-frames true --mfcc-config conf/mfcc.conf --nj 40 --cmd "$train_cmd" \
data/${name} exp/make_mfcc $mfccdir
make_mfcc.sh 的使用格式:steps/make_mfcc.sh [options] <data-dir> [<log-dir> [<mfcc-dir>] ]
steps/make_mfcc.sh [options] <data-dir> [<log-dir> [<mfcc-dir>] ]
Options:
--mfcc-config <config-file> # config passed to compute-mfcc-feats.
--nj <nj> # number of parallel jobs.
--cmd <run.pl|queue.pl <queue opts>> # how to run jobs.
--write-utt2num-frames <true|false> # If true, write utt2num_frames file.
--write-utt2dur <true|false> # If true, write utt2dur file.
# steps/make_mfcc.sh --nj 1 data/train exp/make_mfcc/train mfcc
第一个参数是 ,指定输入数据位置;第二个参数指定输出日志保存的目录位置(若未指定,则默认为 data_dir/log );第三个参数指定mfcc的输出位置(若未指定,则默认为data_dir/data )。
compute the energy-based VAD
sid/compute_vad_decision.sh --nj 40 --cmd "$train_cmd" \
data/${name} exp/make_vad $vaddir
utils/fix_data_dir.sh data/${name}
apply CMVN
# This script applies CMVN and removes nonspeech frames. Note that this is somewhat
# wasteful, as it roughly doubles the amount of training data on disk. After
# creating training examples, this can be removed.
local/nnet3/xvector/prepare_feats_for_egs.sh --nj 40 --cmd "$train_cmd" \
data/swbd_sre_combined data/swbd_sre_combined_no_sil exp/swbd_sre_combined_no_sil
utils/fix_data_dir.sh data/swbd_sre_combined_no_sil
create training examples
# Extract xvectors for SRE data (includes Mixer 6). We'll use this for
# things like LDA or PLDA.
sid/nnet3/xvector/extract_xvectors.sh --cmd "$train_cmd --mem 12G" --nj 40 \
$nnet_dir data/sre_combined \
exp/xvectors_sre_combined
Compute the mean vector
# Compute the mean vector for centering the evaluation xvectors.
$train_cmd exp/xvectors_sre16_major/log/compute_mean.log \
ivector-mean scp:exp/xvectors_sre16_major/xvector.scp \
exp/xvectors_sre16_major/mean.vec || exit 1;
uses LDA
# This script uses LDA to decrease the dimensionality prior to PLDA.
lda_dim=150
$train_cmd exp/xvectors_sre_combined/log/lda.log \
ivector-compute-lda --total-covariance-factor=0.0 --dim=$lda_dim \
"ark:ivector-subtract-global-mean scp:exp/xvectors_sre_combined/xvector.scp ark:- |" \
ark:data/sre_combined/utt2spk exp/xvectors_sre_combined/transform.mat || exit 1;
Train an out-of-domain PLDA model
$train_cmd exp/xvectors_sre_combined/log/plda.log \
ivector-compute-plda ark:data/sre_combined/spk2utt \
"ark:ivector-subtract-global-mean scp:exp/xvectors_sre_combined/xvector.scp ark:- | transform-vec exp/xvectors_sre_combined/transform.mat ark:- ark:- | ivector-normalize-length ark:- ark:- |" \
exp/xvectors_sre_combined/plda || exit 1;
adapt the out-of-domain PLDA model
# Here we adapt the out-of-domain PLDA model to SRE16 major, a pile
# of unlabeled in-domain data. In the future, we will include a clustering
# based approach for domain adaptation, which tends to work better.
$train_cmd exp/xvectors_sre16_major/log/plda_adapt.log \
ivector-adapt-plda --within-covar-scale=0.75 --between-covar-scale=0.25 \
exp/xvectors_sre_combined/plda \
"ark:ivector-subtract-global-mean scp:exp/xvectors_sre16_major/xvector.scp ark:- | transform-vec exp/xvectors_sre_combined/transform.mat ark:- ark:- | ivector-normalize-length ark:- ark:- |" \
exp/xvectors_sre16_major/plda_adapt || exit 1;
Get results using the out-of-domain PLDA model
# Get results using the out-of-domain PLDA model.
$train_cmd exp/scores/log/sre16_eval_scoring.log \
ivector-plda-scoring --normalize-length=true \
--num-utts=ark:exp/xvectors_sre16_eval_enroll/num_utts.ark \
"ivector-copy-plda --smoothing=0.0 exp/xvectors_sre_combined/plda - |" \
"ark:ivector-mean ark:data/sre16_eval_enroll/spk2utt scp:exp/xvectors_sre16_eval_enroll/xvector.scp ark:- | ivector-subtract-global-mean exp/xvectors_sre16_major/mean.vec ark:- ark:- | transform-vec exp/xvectors_sre_combined/transform.mat ark:- ark:- | ivector-normalize-length ark:- ark:- |" \
"ark:ivector-subtract-global-mean exp/xvectors_sre16_major/mean.vec scp:exp/xvectors_sre16_eval_test/xvector.scp ark:- | transform-vec exp/xvectors_sre_combined/transform.mat ark:- ark:- | ivector-normalize-length ark:- ark:- |" \
"cat '$sre16_trials' | cut -d\ --fields=1,2 |" exp/scores/sre16_eval_scores || exit 1;
Get results using the adapted PLDA model
$train_cmd exp/scores/log/sre16_eval_scoring_adapt.log \
ivector-plda-scoring --normalize-length=true \
--num-utts=ark:exp/xvectors_sre16_eval_enroll/num_utts.ark \
"ivector-copy-plda --smoothing=0.0 exp/xvectors_sre16_major/plda_adapt - |" \
"ark:ivector-mean ark:data/sre16_eval_enroll/spk2utt scp:exp/xvectors_sre16_eval_enroll/xvector.scp ark:- | ivector-subtract-global-mean exp/xvectors_sre16_major/mean.vec ark:- ark:- | transform-vec exp/xvectors_sre_combined/transform.mat ark:- ark:- | ivector-normalize-length ark:- ark:- |" \
"ark:ivector-subtract-global-mean exp/xvectors_sre16_major/mean.vec scp:exp/xvectors_sre16_eval_test/xvector.scp ark:- | transform-vec exp/xvectors_sre_combined/transform.mat ark:- ark:- | ivector-normalize-length ark:- ark:- |" \
"cat '$sre16_trials' | cut -d\ --fields=1,2 |" exp/scores/sre16_eval_scores_adapt || exit 1;
1. 具体细节:前端提取
make_mfcc.sh
steps/make_mfcc.sh
#!/bin/bash
# Copyright 2012-2016 Johns Hopkins University (Author: Daniel Povey)
# Apache 2.0
# To be run from .. (one directory up from here)
# see ../run.sh for example
# Begin configuration section.
nj=4
cmd=run.pl
mfcc_config=conf/mfcc.conf
compress=true
write_utt2num_frames=true # If true writes utt2num_frames.
write_utt2dur=true
# End configuration section.
echo "$0 $@" # Print the command line for logging.
if [ -f path.sh ]; then . ./path.sh; fi
. parse_options.sh || exit 1;
if [ $# -lt 1 ] || [ $# -gt 3 ]; then
cat >&2 <<EOF
Usage: $0 [options] <data-dir> [<log-dir> [<mfcc-dir>] ]
e.g.: $0 data/train
Note: <log-dir> defaults to <data-dir>/log, and
<mfcc-dir> defaults to <data-dir>/data.
Options:
--mfcc-config <config-file> # config passed to compute-mfcc-feats.
--nj <nj> # number of parallel jobs.
--cmd <run.pl|queue.pl <queue opts>> # how to run jobs.
--write-utt2num-frames <true|false> # If true, write utt2num_frames file.
--write-utt2dur <true|false> # If true, write utt2dur file.
EOF
exit 1;
fi
data=$1
if [ $# -ge 2 ]; then
logdir=$2
else
logdir=$data/log
fi
if [ $# -ge 3 ]; then
mfccdir=$3
else
mfccdir=$data/data
fi
# make $mfccdir an absolute pathname.
mfccdir=`perl -e '($dir,$pwd)= @ARGV; if($dir!~m:^/:) { $dir = "$pwd/$dir"; } print $dir; ' $mfccdir ${PWD}`
# use "name" as part of name of the archive.
name=`basename $data`
mkdir -p $mfccdir || exit 1;
mkdir -p $logdir || exit 1;
if [ -f $data/feats.scp ]; then
mkdir -p $data/.backup
echo "$0: moving $data/feats.scp to $data/.backup"
mv $data/feats.scp $data/.backup
fi
scp=$data/wav.scp
required="$scp $mfcc_config"
for f in $required; do
if [ ! -f $f ]; then
echo "$0: no such file $f"
exit 1;
fi
done
utils/validate_data_dir.sh --no-text --no-feats $data || exit 1;
if [ -f $data/spk2warp ]; then
echo "$0 [info]: using VTLN warp factors from $data/spk2warp"
vtln_opts="--vtln-map=ark:$data/spk2warp --utt2spk=ark:$data/utt2spk"
elif [ -f $data/utt2warp ]; then
echo "$0 [info]: using VTLN warp factors from $data/utt2warp"
vtln_opts="--vtln-map=ark:$data/utt2warp"
else
vtln_opts=""
fi
for n in $(seq $nj); do
# the next command does nothing unless $mfccdir/storage/ exists, see
# utils/create_data_link.pl for more info.
utils/create_data_link.pl $mfccdir/raw_mfcc_$name.$n.ark
done
if $write_utt2num_frames; then
write_num_frames_opt="--write-num-frames=ark,t:$logdir/utt2num_frames.JOB"
else
write_num_frames_opt=
fi
if $write_utt2dur; then
write_utt2dur_opt="--write-utt2dur=ark,t:$logdir/utt2dur.JOB"
else
write_utt2dur_opt=
fi
if [ -f $data/segments ]; then
echo "$0 [info]: segments file exists: using that."
split_segments=
for n in $(seq $nj); do
split_segments="$split_segments $logdir/segments.$n"
done
utils/split_scp.pl $data/segments $split_segments || exit 1;
rm $logdir/.error 2>/dev/null
$cmd JOB=1:$nj $logdir/make_mfcc_${name}.JOB.log \
extract-segments scp,p:$scp $logdir/segments.JOB ark:- \| \
compute-mfcc-feats $vtln_opts $write_utt2dur_opt --verbose=2 \
--config=$mfcc_config ark:- ark:- \| \
copy-feats --compress=$compress $write_num_frames_opt ark:- \
ark,scp:$mfccdir/raw_mfcc_$name.JOB.ark,$mfccdir/raw_mfcc_$name.JOB.scp \
|| exit 1;
else
echo "$0: [info]: no segments file exists: assuming wav.scp indexed by utterance."
split_scps=
for n in $(seq $nj); do
split_scps="$split_scps $logdir/wav_${name}.$n.scp"
done
utils/split_scp.pl $scp $split_scps || exit 1;
# add ,p to the input rspecifier so that we can just skip over
# utterances that have bad wave data.
$cmd JOB=1:$nj $logdir/make_mfcc_${name}.JOB.log \
compute-mfcc-feats $vtln_opts $write_utt2dur_opt --verbose=2 \
--config=$mfcc_config scp,p:$logdir/wav_${name}.JOB.scp ark:- \| \
copy-feats $write_num_frames_opt --compress=$compress ark:- \
ark,scp:$mfccdir/raw_mfcc_$name.JOB.ark,$mfccdir/raw_mfcc_$name.JOB.scp \
|| exit 1;
fi
if [ -f $logdir/.error.$name ]; then
echo "$0: Error producing MFCC features for $name:"
tail $logdir/make_mfcc_${name}.1.log
exit 1;
fi
# concatenate the .scp files together.
for n in $(seq $nj); do
cat $mfccdir/raw_mfcc_$name.$n.scp || exit 1
done > $data/feats.scp || exit 1
if $write_utt2num_frames; then
for n in $(seq $nj); do
cat $logdir/utt2num_frames.$n || exit 1
done > $data/utt2num_frames || exit 1
fi
if $write_utt2dur; then
for n in $(seq $nj); do
cat $logdir/utt2dur.$n || exit 1
done > $data/utt2dur || exit 1
fi
# Store frame_shift and mfcc_config along with features.
frame_shift=$(perl -ne 'if (/^--frame-shift=(\d+)/) {
printf "%.3f", 0.001 * $1; exit; }' $mfcc_config)
echo ${frame_shift:-'0.01'} > $data/frame_shift
mkdir -p $data/conf && cp $mfcc_config $data/conf/mfcc.conf || exit 1
rm $logdir/wav_${name}.*.scp $logdir/segments.* \
$logdir/utt2num_frames.* $logdir/utt2dur.* 2>/dev/null
nf=$(wc -l < $data/feats.scp)
nu=$(wc -l < $data/utt2spk)
if [ $nf -ne $nu ]; then
echo "$0: It seems not all of the feature files were successfully procesed" \
"($nf != $nu); consider using utils/fix_data_dir.sh $data"
fi
if (( nf < nu - nu/20 )); then
echo "$0: Less than 95% the features were successfully generated."\
"Probably a serious error."
exit 1
fi
echo "$0: Succeeded creating MFCC features for $name"
compute_vad_decision.sh
sid/compute_vad_decision.sh
#!/bin/bash
# Copyright 2017 Vimal Manohar
# Apache 2.0
# To be run from .. (one directory up from here)
# see ../run.sh for example
# Compute energy based VAD output
nj=4
cmd=run.pl
vad_config=conf/vad.conf
echo "$0 $@" # Print the command line for logging
if [ -f path.sh ]; then . ./path.sh; fi
. parse_options.sh || exit 1;
if [ $# -lt 1 ] || [ $# -gt 3 ]; then
echo "Usage: $0 [options] <data-dir> [<log-dir> [<vad-dir>]]";
echo "e.g.: $0 data/train exp/make_vad mfcc"
echo "Note: <log-dir> defaults to <data-dir>/log, and <vad-dir> defaults to <data-dir>/data"
echo " Options:"
echo " --vad-config <config-file> # config passed to compute-vad-energy"
echo " --nj <nj> # number of parallel jobs"
echo " --cmd (utils/run.pl|utils/queue.pl <queue opts>) # how to run jobs."
exit 1;
fi
data=$1
if [ $# -ge 2 ]; then
logdir=$2
else
logdir=$data/log
fi
if [ $# -ge 3 ]; then
vaddir=$3
else
vaddir=$data/data
fi
# make $vaddir an absolute pathname.
vaddir=`perl -e '($dir,$pwd)= @ARGV; if($dir!~m:^/:) { $dir = "$pwd/$dir"; } print $dir; ' $vaddir ${PWD}`
# use "name" as part of name of the archive.
name=`basename $data`
mkdir -p $vaddir || exit 1;
mkdir -p $logdir || exit 1;
if [ -f $data/vad.scp ]; then
mkdir -p $data/.backup
echo "$0: moving $data/vad.scp to $data/.backup"
mv $data/vad.scp $data/.backup
fi
for f in $data/feats.scp "$vad_config"; do
if [ ! -f $f ]; then
echo "compute_vad_decision.sh: no such file $f"
exit 1;
fi
done
utils/split_data.sh $data $nj || exit 1;
sdata=$data/split$nj;
$cmd JOB=1:$nj $logdir/vad_${name}.JOB.log \
compute-vad --config=$vad_config scp:$sdata/JOB/feats.scp \
ark,scp:$vaddir/vad_${name}.JOB.ark,$vaddir/vad_${name}.JOB.scp || exit 1
for ((n=1; n<=nj; n++)); do
cat $vaddir/vad_${name}.$n.scp || exit 1;
done > $data/vad.scp
nc=`cat $data/vad.scp | wc -l`
nu=`cat $data/feats.scp | wc -l`
if [ $nc -ne $nu ]; then
echo "**Warning it seems not all of the speakers got VAD output ($nc != $nu);"
echo "**validate_data_dir.sh will fail; you might want to use fix_data_dir.sh"
[ $nc -eq 0 ] && exit 1;
fi
echo "Created VAD output for $name"
extract_xvectors.sh
sid/nnet3/xvector/extract_xvectors.sh
#!/bin/bash
# Copyright 2017 David Snyder
# 2017 Johns Hopkins University (Author: Daniel Povey)
# 2017 Johns Hopkins University (Author: Daniel Garcia Romero)
# Apache 2.0.
# This script extracts embeddings (called "xvectors" here) from a set of
# utterances, given features and a trained DNN. The purpose of this script
# is analogous to sid/extract_ivectors.sh: it creates archives of
# vectors that are used in speaker recognition. Like ivectors, xvectors can
# be used in PLDA or a similar backend for scoring.
# Begin configuration section.
nj=30
cmd="run.pl"
cache_capacity=64 # Cache capacity for x-vector extractor
chunk_size=-1 # The chunk size over which the embedding is extracted.
# If left unspecified, it uses the max_chunk_size in the nnet
# directory.
use_gpu=false
stage=0
echo "$0 $@" # Print the command line for logging
if [ -f path.sh ]; then . ./path.sh; fi
. parse_options.sh || exit 1;
if [ $# != 3 ]; then
echo "Usage: $0 <nnet-dir> <data> <xvector-dir>"
echo " e.g.: $0 exp/xvector_nnet data/train exp/xvectors_train"
echo "main options (for others, see top of script file)"
echo " --config <config-file> # config containing options"
echo " --cmd (utils/run.pl|utils/queue.pl <queue opts>) # how to run jobs."
echo " --use-gpu <bool|false> # If true, use GPU."
echo " --nj <n|30> # Number of jobs"
echo " --stage <stage|0> # To control partial reruns"
echo " --cache-capacity <n|64> # To speed-up xvector extraction"
echo " --chunk-size <n|-1> # If provided, extracts embeddings with specified"
echo " # chunk size, and averages to produce final embedding"
fi
srcdir=$1
data=$2
dir=$3
for f in $srcdir/final.raw $srcdir/min_chunk_size $srcdir/max_chunk_size $data/feats.scp $data/vad.scp ; do
[ ! -f $f ] && echo "No such file $f" && exit 1;
done
min_chunk_size=`cat $srcdir/min_chunk_size 2>/dev/null`
max_chunk_size=`cat $srcdir/max_chunk_size 2>/dev/null`
nnet=$srcdir/final.raw
if [ -f $srcdir/extract.config ] ; then
echo "$0: using $srcdir/extract.config to extract xvectors"
nnet="nnet3-copy --nnet-config=$srcdir/extract.config $srcdir/final.raw - |"
fi
if [ $chunk_size -le 0 ]; then
chunk_size=$max_chunk_size
fi
if [ $max_chunk_size -lt $chunk_size ]; then
echo "$0: specified chunk size of $chunk_size is larger than the maximum chunk size, $max_chunk_size" && exit 1;
fi
mkdir -p $dir/log
utils/split_data.sh $data $nj
echo "$0: extracting xvectors for $data"
sdata=$data/split$nj/JOB
# Set up the features
feat="ark:apply-cmvn-sliding --norm-vars=false --center=true --cmn-window=300 scp:${sdata}/feats.scp ark:- | select-voiced-frames ark:- scp,s,cs:${sdata}/vad.scp ark:- |"
if [ $stage -le 0 ]; then
echo "$0: extracting xvectors from nnet"
if $use_gpu; then
for g in $(seq $nj); do
$cmd --gpu 1 ${dir}/log/extract.$g.log \
nnet3-xvector-compute --use-gpu=yes --min-chunk-size=$min_chunk_size --chunk-size=$chunk_size --cache-capacity=${cache_capacity} \
"$nnet" "`echo $feat | sed s/JOB/$g/g`" ark,scp:${dir}/xvector.$g.ark,${dir}/xvector.$g.scp || exit 1 &
done
wait
else
$cmd JOB=1:$nj ${dir}/log/extract.JOB.log \
nnet3-xvector-compute --use-gpu=no --min-chunk-size=$min_chunk_size --chunk-size=$chunk_size --cache-capacity=${cache_capacity} \
"$nnet" "$feat" ark,scp:${dir}/xvector.JOB.ark,${dir}/xvector.JOB.scp || exit 1;
fi
fi
if [ $stage -le 1 ]; then
echo "$0: combining xvectors across jobs"
for j in $(seq $nj); do cat $dir/xvector.$j.scp; done >$dir/xvector.scp || exit 1;
fi
if [ $stage -le 2 ]; then
# Average the utterance-level xvectors to get speaker-level xvectors.
echo "$0: computing mean of xvectors for each speaker"
$cmd $dir/log/speaker_mean.log \
ivector-mean ark:$data/spk2utt scp:$dir/xvector.scp \
ark,scp:$dir/spk_xvector.ark,$dir/spk_xvector.scp ark,t:$dir/num_utts.ark || exit 1;
fi
1.3 中间量
- 训练好的x-vector模型:
exp/xvector_nnet_1a
2. 具体细节:后端识别
2.1 流程控制脚本
plda-scoring.sh:后端识别模块的流程控制脚本
plda-scoring.sh
- 命令行执行
local/plda_scoring.sh $tandem_feats_dir/sre $tandem_feats_dir/train $tandem_feats_dir/test \
exp/ivectors_sre exp/ivectors_train exp/ivectors_test $trials exp/scores_gmm_512_ind_pooled
该脚本命令行执行有8个参数,下面是脚本内容,可以看这个8个参数的具体所指。
- 脚本内容
plda_data_dir=$1
enroll_data_dir=$2
test_data_dir=$3
plda_ivec_dir=$4
enroll_ivec_dir=$5
test_ivec_dir=$6
trials=$7
scores_dir=$8
#由i-vector特征来训练一个plda模型,plda模型也是由sre集合训练的,所以这里传的参数都是sre的。
ivector-compute-plda ark:$plda_data_dir/spk2utt \
"ark:ivector-normalize-length scp:${plda_ivec_dir}/ivector.scp ark:- |" \
$plda_ivec_dir/plda 2>$plda_ivec_dir/log/plda.log
mkdir -p $scores_dir
ivector-plda-scoring --num-utts=ark:${enroll_ivec_dir}/num_utts.ark \
"ivector-copy-plda --smoothing=0.0 ${plda_ivec_dir}/plda - |"
"ark:ivector-subtract-global-mean ${plda_ivec_dir}/mean.vec \
scp:${enroll_ivec_dir}/spk_ivector.scp ark:- |" \
"ark:ivector-subtract-global-mean ${plda_ivec_dir}/mean.vec \
scp:${test_ivec_dir}/ivector.scp ark:- |" \
"cat '$trials' | awk '{print \$1, \$2}' |" $scores_dir/plda_scores
2.2 具体执行的脚本
从上面的内容可以看出,plda-scoring.sh 主要包括 ivector-compute-plda 和 ivector-plda-scoring 两个(具体的执行)部分。
ivector-compute-plda
ivector-compute-plda:训练plda模型
- 脚本执行(plda-scoring.sh中其实也有)
ivector-compute-plda ark:$plda_data_dir/spk2utt \
"ark:ivector-normalize-length scp:${plda_ivec_dir}/ivector.scp ark:- |" \
$plda_ivec_dir/plda 2>$plda_ivec_dir/log/plda.log
- 脚本源码(C++)的核心部分
int main(int argc, char *argv[]) {
try {
const char *usage =
"Computes a Plda object (for Probabilistic Linear Discriminant Analysis)\n"
"from a set of iVectors. Uses speaker information from a spk2utt file\n"
"to compute within and between class variances.\n" ";
ParseOptions po(usage);
bool binary = true;
PldaEstimationConfig plda_config;
plda_config.Register(&po);
po.Register("binary", &binary, "Write output in binary mode");
po.Read(argc, argv);
#需要三个参数:sre的spk2utt,sre的ivetor.scp, plda模型文件
std::string spk2utt_rspecifier = po.GetArg(1),
ivector_rspecifier = po.GetArg(2),
plda_wxfilename = po.GetArg(3);
int64 num_spk_done = 0, num_spk_err = 0,
num_utt_done = 0, num_utt_err = 0;
SequentialTokenVectorReader spk2utt_reader(spk2utt_rspecifier);
RandomAccessBaseFloatVectorReader ivector_reader(ivector_rspecifier);
PldaStats plda_stats;
for (; !spk2utt_reader.Done(); spk2utt_reader.Next()) {
std::string spk = spk2utt_reader.Key();
const std::vector &uttlist = spk2utt_reader.Value(); #所有spk的utts
std::vector<Vector<BaseFloat> > ivectors; #注意类型,所有的ivector
ivectors.reserve(uttlist.size());
#对每一句话进行处理
for (size_t i = 0; i < uttlist.size(); i++) {
std::string utt = uttlist[i];
ivectors.resize(ivectors.size() + 1);
ivectors.back() = ivector_reader.Value(utt);
num_utt_done++;
}
Matrix ivector_mat(ivectors.size(), ivectors[0].Dim()); #每个i-vector一行,组成一个矩阵,
for (size_t i = 0; i < ivectors.size(); i++){
ivector_mat.Row(i).CopyFromVec(ivectors[i]);
}
double weight = 1.0;
plda_stats.AddSamples(weight, ivector_mat); #每个人一个plda_stats,在plda.cc
num_spk_done++;
}
#对所有的plda_stats排序
#PLDA的实现是根据:"Probabilistic Linear Discriminant Analysis" by Sergey Ioffe, ECCV 2006.
plda_stats.Sort();
PldaEstimator plda_estimator(plda_stats);
Plda plda;
//默认迭代10次,更新类内协方差和类间协方差
plda_estimator.Estimate(plda_config, &plda);
ivector-plda-scoring
ivector-plda-scoring:使用plda模型进行(对数似然比,LLR)的计算
- 脚本执行(plda-scoring.sh中其实也有)
ivector-plda-scoring --num-utts=ark:${enroll_ivec_dir}/num_utts.ark \
"ivector-copy-plda --smoothing=0.0 ${plda_ivec_dir}/plda - |"
"ark:ivector-subtract-global-mean ${plda_ivec_dir}/mean.vec \
scp:${enroll_ivec_dir}/spk_ivector.scp ark:- |" \
"ark:ivector-subtract-global-mean ${plda_ivec_dir}/mean.vec \
scp:${test_ivec_dir}/ivector.scp ark:- |" \
"cat '$trials' | awk '{print \$1, \$2}' |" $scores_dir/plda_scores
//–num-utts是训练集中每个人对应的句子的数目:
//其中第二个参数的结果是: enrollment的每个说话人的ivector都减去mean.vec的结果
//其中第三个参数的结果是: test的每句话的ivector都减去mean.vec的结果,注意跟第二个参数的区别
//其中第四个参数的结果是: trials文件的前两列,
- 脚本源码(C++)的核心部分
int main(int argc, char *argv[]) {
using namespace kaldi;
std::string plda_rxfilename = po.GetArg(1),
train_ivector_rspecifier = po.GetArg(2),
test_ivector_rspecifier = po.GetArg(3),
trials_rxfilename = po.GetArg(4),
scores_wxfilename = po.GetArg(5);
// diagnostics:
double tot_test_renorm_scale = 0.0, tot_train_renorm_scale = 0.0;
int64 num_train_ivectors = 0, num_train_errs = 0, num_test_ivectors = 0;
int64 num_trials_done = 0, num_trials_err = 0;
Plda plda;
ReadKaldiObject(plda_rxfilename, &plda);
int32 dim = plda.Dim();
SequentialBaseFloatVectorReader train_ivector_reader(train_ivector_rspecifier);
SequentialBaseFloatVectorReader test_ivector_reader(test_ivector_rspecifier);
RandomAccessInt32Reader num_utts_reader(num_utts_rspecifier);
typedef unordered_map<string, Vector<BaseFloat>*, StringHasher> HashType;
// These hashes will contain the iVectors in the PLDA subspace
// (that makes the within-class variance unit and diagonalizes the
// between-class covariance).
HashType train_ivectors, test_ivectors;
KALDI_LOG << "Reading train iVectors";
for (; !train_ivector_reader.Done(); train_ivector_reader.Next()) {
std::string spk = train_ivector_reader.Key();
const Vector<BaseFloat> &ivector = train_ivector_reader.Value();
Vector<BaseFloat> *transformed_ivector = new Vector<BaseFloat>(dim);
tot_train_renorm_scale += plda.TransformIvector(plda_config, ivector,
transformed_ivector);
train_ivectors[spk] = transformed_ivector;
num_train_ivectors++;
}
KALDI_LOG << "Reading test iVectors";
for (; !test_ivector_reader.Done(); test_ivector_reader.Next()) {
std::string utt = test_ivector_reader.Key();
const Vector<BaseFloat> &ivector = test_ivector_reader.Value();
Vector<BaseFloat> *transformed_ivector = new Vector<BaseFloat>(dim);
tot_test_renorm_scale += plda.TransformIvector(plda_config, ivector,
transformed_ivector);
test_ivectors[utt] = transformed_ivector;
num_test_ivectors++;
}
KALDI_LOG << "Read " << num_test_ivectors << " test iVectors.";
Input ki(trials_rxfilename);
bool binary = false;
Output ko(scores_wxfilename, binary);
double sum = 0.0, sumsq = 0.0;
std::string line;
while (std::getline(ki.Stream(), line)) {
std::vector<std::string> fields;
SplitStringToVector(line, " \t\n\r", true, &fields);
std::string key1 = fields[0], key2 = fields[1];
const Vector<BaseFloat> *train_ivector = train_ivectors[key1],
*test_ivector = test_ivectors[key2];
Vector<double> train_ivector_dbl(*train_ivector),
test_ivector_dbl(*test_ivector);
int32 num_train_examples;
num_train_examples += 1;
BaseFloat score = plda.LogLikelihoodRatio(train_ivector_dbl,
num_train_examples,
test_ivector_dbl);
sum += score;
sumsq += score * score;
num_trials_done++;
ko.Stream() << key1 << ' ' << key2 << ' ' << score << std::endl;
}
}
计算对数似然比(LLR)
-
计算对数似然比(LLR)的函数: n Ψ n Ψ + I u ˉ g \frac{n \Psi}{n \Psi + I} \bar{u}^g nΨ+InΨuˉg
Ψ Ψ Ψ 是类内协方差矩阵(对角)的元素,维度为 dim(ivector)
-
源码
double Plda::LogLikelihoodRatio(
const VectorBase<double> &transformed_train_ivector,
int32 n, // number of training utterances.
const VectorBase<double> &transformed_test_ivector) const {
int32 dim = Dim();
double loglike_given_class, loglike_without_class;
{ // work out loglike_given_class.
// "mean" will be the mean of the distribution if it comes from the
// training example. The mean is \frac{n \Psi}{n \Psi + I} \bar{u}^g
// "variance" will be the variance of that distribution, equal to
// I + \frac{\Psi}{n\Psi + I}.
Vector<double> mean(dim, kUndefined);
Vector<double> variance(dim, kUndefined);
for (int32 i = 0; i < dim; i++) {
mean(i) = n * psi_(i) / (n * psi_(i) + 1.0) * transformed_train_ivector(i);
variance(i) = 1.0 + psi_(i) / (n * psi_(i) + 1.0);
}
double logdet = variance.SumLog();
Vector<double> sqdiff(transformed_test_ivector);
sqdiff.AddVec(-1.0, mean);
sqdiff.ApplyPow(2.0);
variance.InvertElements();
loglike_given_class = -0.5 * (logdet + M_LOG_2PI * dim +
VecVec(sqdiff, variance));
}
{ // work out loglike_without_class. Here the mean is zero and the variance
// is I + \Psi.
Vector<double> sqdiff(transformed_test_ivector); // there is no offset.
sqdiff.ApplyPow(2.0);
Vector<double> variance(psi_);
variance.Add(1.0); // I + \Psi.
double logdet = variance.SumLog();
variance.InvertElements();
loglike_without_class = -0.5 * (logdet + M_LOG_2PI * dim +
VecVec(sqdiff, variance));
}
double loglike_ratio = loglike_given_class - loglike_without_class;
return loglike_ratio;
}
精简版
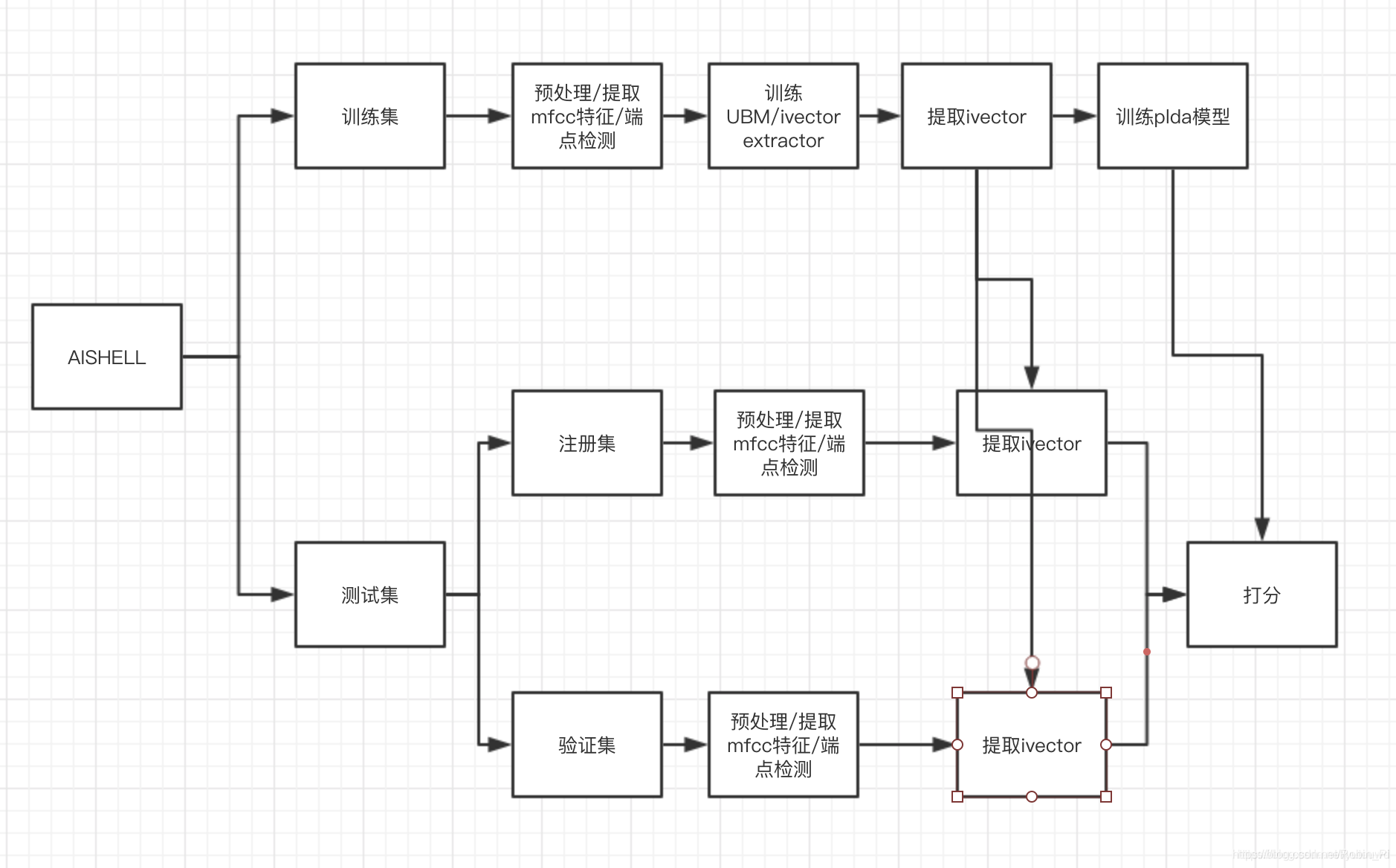
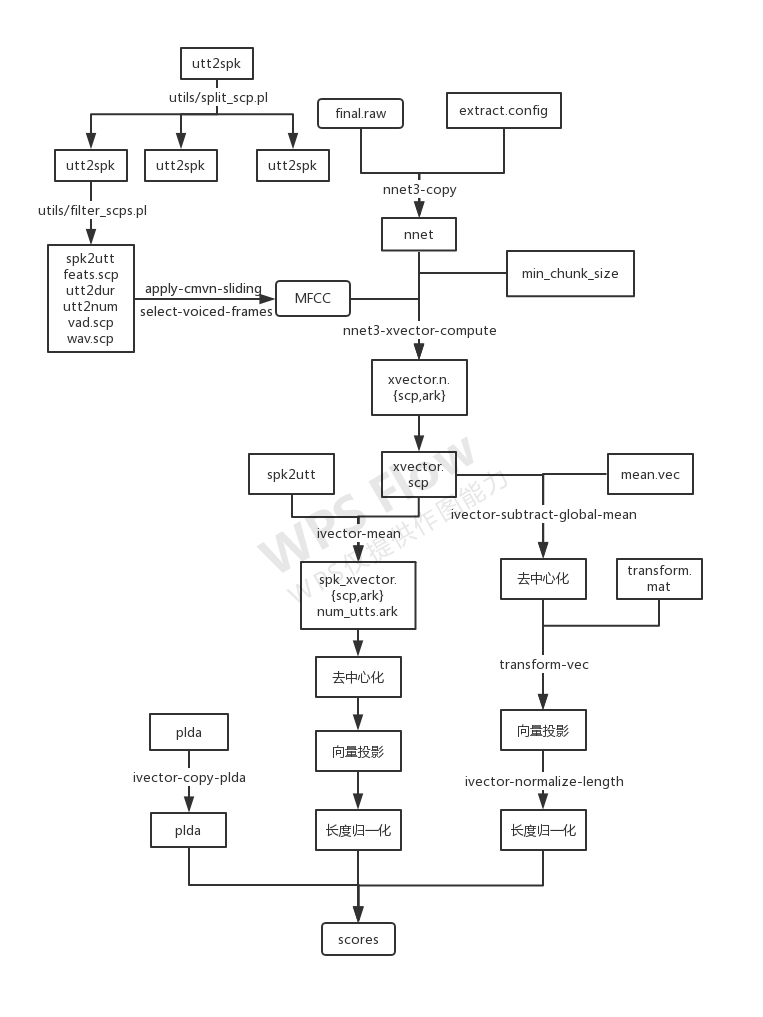
流程图
基于x-vector的声纹识别流程
(暂且拿一张i-vector的来示意)
主要参考:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









