






Word2Vec
语言模型
语⾔模型:预测每个句⼦在语⾔中出现的概率
P(S)也被称为语言模型,即用来计算一个句子概率的模型。
计算
表示整句话在训练语料库中出现的次数除以不算当前词Wi后句⼦
出现的次数。
缺点
- 数据过于稀疏
- 参数空间太大
解释:虽然能够表示出一句话的概率,但是这样的计算的计算量特别大,会导致数据过于稀疏,因为每一个词都要考虑前⾯很多很多的词,而前面很多词组合在以起的概率其实并没有很高,组合到⼀起的词越多,它的数据模型是越稀疏的。因为数据非常稀疏,这会导致参数空间太大。
基于马尔科夫的假设
为了解决上述缺点,下面介绍基于马尔科夫的假设。
基于马尔科夫的假设:下一个词的出现仅依赖于它前面的一个或几个词。
- 假设下一个词的出现依赖它前面的一个词,则有:
- 假设下一个词的出现依赖它前面的两个词,则有:
n-gram模型
n-gram模型:假设当前词的出现概率只与它前面的N-1个词有关。
如何选择n:
- 更大的n:对下ー个词出现的约束信息更多,具有更大的辨别力;
- 更小的n:在训练语料库中出现的次数更多,具有更可靠的统计信息,具有更高的可靠性。
理论上,n大越好,经验上,trigram用的最多,尽管如此,原则上,能用
bigram解决,绝不使用 trigram。
构造语言模型
构造语言模型:最大似然估计。
Count(X):在训练语料库单词序列X在训练语料中出现的次数。
词向量
- 词表示为:[0.792,-0.177,-0.107,0.109,0.542,…]
- 常见维度50或者100
- 解决”语义鸿沟“问题
- 可以通过计算向量之间的距离(欧式距离、余弦距离等)来体现词与词的相似性
独热编码
语言模型生成词向量
神经网络语言模型(NNLM):直接从语言模型出发,将模型最优化过程转化为求词向量表示的过程。
目标函数:
模型结构:

- NNLM是从语言模型出发(即计算概率角度),构建神经网络针对目标函数对模型进行最优化,训练的起点是使用神经网络去搭建语言模型实现词的预测任务,并且在优化过程后模型的副产品就是词向量。
- 进行神经网络模型的训练时,目标是进行词的概率预测,就是在词环境下,预则下一个该是什么词,目标函数如下式,通过对网络训练一定程度后,最后的模型参数就可当成词向量使用。
循环神经网络语言模型(RNNLN):基于循环神经网络的语言模型。
w(t)表示第t个时刻的当前输入单词,维度为V,V是词典大小。one-hot表示。
s(t-1)代表隐层的前一次输出,
y(t)表示输出的。
循环神经网络的最⼤优势在于,可以真正充分地利⽤所有上文信息来预测下⼀个词,而不像前⾯的其它工作那样,只能开⼀个 n 个词的窗口,只⽤前 n 个词来预测下⼀个词。
缺点:
- 计算复杂度大
- 参数较多
所以接下来介绍word2vec
word2vec
Continuous Bag of Words(CBOW)
Continuous Bag of Words(CBOW):连续词袋模型,即利用中心词(Wt)
的上下文( context)来预测中心词(Wt)。
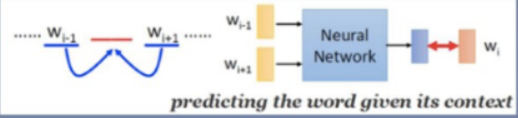
- 目标函数:
- 无隐层
- 使用双向上下文窗口
- 上下文词序无关(BoW)
- 输入层直接始用低维稠密向量表示
- 投影层简化为求和(平均)
CBOW模型结构图:

Skip-gram
Skip-gram,跳字模型,是根据中心词(Wt)来预测周围的词,即预测上下文( context)。
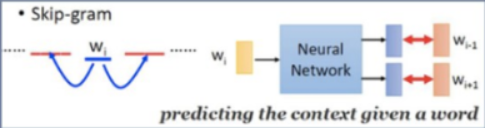
- 目标函数:
- 输入层:只含当前样本的中心词w的词向量
- 投影层:恒等投影,为了和CBOW模型对比
- 输出层:和CBOW模型一样,输出层也是一棵 Huffman树
Skip-gram模型结构图:

训练技巧
- 层次softmax(Hierarchical Softmax)
- 负采样(Negative Sampling)
目标函数

最小化目标函数⟺最大化预测精度

我们需要最小化目标函数,那么对于每个单词w我们将使用两个向量:
- v_(w):当w是中心词时
- u_(w):当w是上下文词时
然后对于中心词c和上下文词o:
公式推导

代码实现
用gensim学习word2vec(gensim是一个NLP的包)
下面所使用的数据集为小说《人民的名义》,参照
链接:https://pan.baidu.com/s/1ojWGMI756SO93OCAMNXFVg
提取码:l0zv
复制这段内容后打开百度网盘手机App,操作更方便哦
# -*- coding: utf-8 -*-
import jieba
import jieba.analyse
jieba.suggest_freq('沙瑞金', True)
jieba.suggest_freq('田国富', True)
jieba.suggest_freq('高育良', True)
jieba.suggest_freq('侯亮平', True)
jieba.suggest_freq('钟小艾', True)
jieba.suggest_freq('陈岩石', True)
jieba.suggest_freq('欧阳菁', True)
jieba.suggest_freq('易学习', True)
jieba.suggest_freq('王大路', True)
jieba.suggest_freq('蔡成功', True)
jieba.suggest_freq('孙连城', True)
jieba.suggest_freq('季昌明', True)
jieba.suggest_freq('丁义珍', True)
jieba.suggest_freq('郑西坡', True)
jieba.suggest_freq('赵东来', True)
jieba.suggest_freq('高小琴', True)
jieba.suggest_freq('赵瑞龙', True)
jieba.suggest_freq('林华华', True)
jieba.suggest_freq('陆亦可', True)
jieba.suggest_freq('刘新建', True)
jieba.suggest_freq('刘庆祝', True)
with open('./in_the_name_of_people.txt',encoding='utf-8') as f:
document = f.read()
#document_decode = document.decode('GBK')
document_cut = jieba.cut(document)
#print ' '.join(jieba_cut) //如果打印结果,则分词效果消失,后面的result无法显示
result = ' '.join(document_cut)
result = result.encode('utf-8')
with open('./in_the_name_of_people_segment.txt', 'wb') as f2:
f2.write(result)
f.close()
f2.close()
# import modules & set up logging
import logging
import os
from gensim.models import word2vec
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.LineSentence('./in_the_name_of_people_segment.txt')
model = word2vec.Word2Vec(sentences, hs=1,min_count=1,window=3,size=100)
req_count = 5 #输出几组
#找出某一个词向量最相近的词集合
for key in model.wv.similar_by_word('李达康', topn =100):
if len(key[0])==3: #第一列的长度
req_count -= 1
print (key[0],key[1])
if req_count == 0:
break;

req_count = 5
for key in model.wv.similar_by_word('赵东来', topn =100):
if len(key[0])==3:
req_count -= 1
print (key[0], key[1])
if req_count == 0:
break;

req_count = 5
for key in model.wv.similar_by_word('高育良', topn =100):
if len(key[0])==3:
req_count -= 1
print (key[0], key[1])
if req_count == 0:
break;

req_count = 5
for key in model.wv.similar_by_word('沙瑞金', topn =100):
if len(key[0])==3:
req_count -= 1
print (key[0], key[1])
if req_count == 0:
break;

#看两个词向量的相近程度
print (model.wv.similarity('沙瑞金','高育良'))
print (model.wv.similarity('李达康','王大路'))
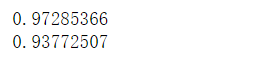
#找出不同类的词
print (model.wv.doesnt_match(u"沙瑞金 高育良 李达康 刘庆祝".split()))
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









