







前言
印度和中国是世界上人口最多的两个国家,它们的人口变化对全球经济、社会和环境都有重要影响。根据联合国《2022 年世界人口展望》报告²,印度人口将在今年4月中旬超过中国,增至14.1亿,成为全球人口第一大国。到2023年底,印度人口可能接近14.29亿。
那么,如何使用Python这一流行的编程语言来收集、处理和可视化印度和中国的人口数据呢?本文将向你介绍一些基本的步骤和技巧,帮助你掌握Python进行可视化分析的方法。我们将使用以下几个库来进行数据分析和可视化:
-
pandas:一个提供高性能、易用的数据结构和数据分析工具的库。
-
requests:一个简洁、优雅的HTTP库,用于发送网络请求和获取数据。
-
matplotlib:一个强大的绘图库,支持多种图形和样式。
-
seaborn:一个基于matplotlib的统计数据可视化库,提供了更美观、更高级的图形接口。
获取数据
我们可以从一些公开的数据源获取印度和中国的人口数据,例如世界银行、联合国等。
我们选择使用以下在线数据资源:
-
世界银行Open Data (https://data.worldbank.org/),收集1960年至2019年的人口数据。
我已经将CSV文件保存为“population_data_world_bank.csv”。使用Pandas读取并查看前几行数据:
# 读取CSV文件
df = pd.read_csv('population_data_world_bank.csv')
df.head()
输出结果如下:

处理数据
我们只需要提取印度和中国的数据行,并剔除其他的国家,得到每年两个国家的总人口。我们可以使用df来提取行,然后使用pandas的loc方法来筛选数据。
india_wb = df[df['Country Name'] == 'India']
china_wb = df[df['Country Name'] == 'China']
# 提取历史人口数量数据
india = india_wb.loc[:, '1960': '2021'].T
china = china_wb.loc[:, '1960': '2021'].T
我们从“ Country Name”列中选择了印度和中国的行,并且只选取了1960年至2021年的历史人口数据。
我们可以查看一下处理后的数据,它们是一个pandas的Series对象,索引是年份,值是人口。
india.head()
输出:
109
1960 445954579.0
1961 456351876.0
1962 467024193.0
1963 477933619.0
1964 489059309.0
china.head()
输出:
40
1960 667070000.0
1961 660330000.0
1962 665770000.0
1963 682335000.0
1964 698355000.0
可视化数据
最后,我们可以使用matplotlib和seaborn来绘制印度和中国的人口变化曲线图,比较两个国家的人口差异和趋势。我们可以使用plt.plot方法来绘制折线图,然后使用plt.legend方法来添加图例,使用plt.xlabel和plt.ylabel方法来添加坐标轴标签,使用plt.title方法来添加标题,使用plt.show方法来显示图形。
import matplotlib.pyplot as plt
import seaborn as sns
plt.plot(india.index, india.values, label='India')
plt.plot(china.index, china.values, label='China')
plt.legend()
plt.xlabel('Year')
plt.ylabel('Population')
plt.title('Population of India and China')
plt.show()
输出:
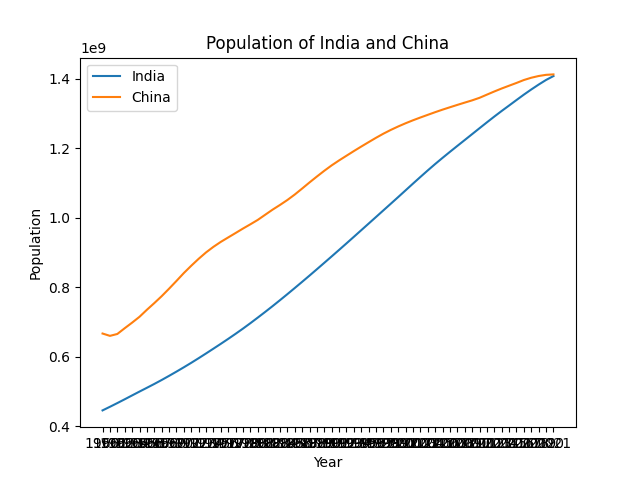
从图中我们可以看到,印度和中国的人口在过去两个多世纪都呈现出快速增长的趋势,但中国的人口增长速度在1970年代以后明显放缓,而印度的人口增长速度则相对稳定。预计在2022年左右,印度的人口将超过中国,成为世界上人口最多的国家。
为了使图形更加直白易懂,我们可以做一些改进:
-
使用seaborn的set_style方法来设置图形的风格,例如darkgrid、whitegrid、dark、white或ticks。
-
使用seaborn的set_context方法来设置图形的上下文,例如paper、notebook、talk或poster。这会影响图形的尺寸、字体大小等。
-
使用seaborn的set_palette方法来设置图形的颜色方案,例如deep、muted、bright、pastel或dark。
-
使用plt.xlim和plt.ylim方法来设置x轴和y轴的范围,以便突出重点区域。
-
使用plt.xticks和plt.yticks方法来设置x轴和y轴的刻度标签,以便提高可读性。
-
使用sns.despine方法来去除图形边框中不需要的部分。
以下是改进后的代码:
sns.set_style('whitegrid')
sns.set_context('talk')
sns.set_palette('dark')
plt.plot(india.index.astype('int'), india.values, label='India')
plt.plot(china.index.astype('int'), china.values, label='China')
plt.legend()
plt.xlabel('Year')
plt.ylabel('Population')
plt.title('Population of India and China')
plt.xlim(1955, 2025)
plt.ylim(0, 1500000000)
plt.xticks(range(1955, 2026, 10))
plt.yticks(range(0, 1600000000, 200000000))
sns.despine(left=True, bottom=True)
plt.show()
输出:
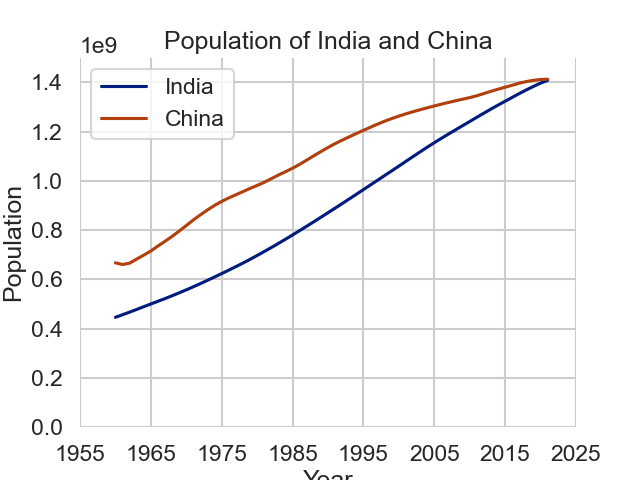
从图中我们可以看到,改进后的图形更加清晰、美观、易于理解。我们可以更清楚地看到印度和中国人口的变化趋势和差异,以及两国人口在2022年左右的交叉点。
总结
本文介绍了如何使用Python对印度和中国人口进行可视化分析,包括获取数据、处理数据和可视化数据三个步骤。通过这个示例,我们可以学习到一些Python进行数据分析和可视化的基本方法和技巧。当然,这只是一个简单的入门教程,如果你想深入学习Python进行可视化分析的话,你还需要掌握更多的知识和技能。希望本文对你有所帮助。
今天的内容就到这里,如果老铁觉得还行,可以来一波三连,感谢!
















 4161
4161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











