







论文地址:Linguistic-Aware Patch Slimming Framework for Fine-grained Cross-Modal Alignment
代码地址:https://github.com/CrossmodalGroup/LAPS
bib引用:
@InProceedings{Fu_2024_CVPR,
author = {Fu, Zheren and Zhang, Lei and Xia, Hou and Mao, Zhendong},
title = {Linguistic-Aware Patch Slimming Framework for Fine-grained Cross-Modal Alignment},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
pages = {26307-26316}
}
InShort
提出Linguistic-Aware Patch Slimming(LAPS)框架,解决基于纯Transformer架构的跨模态对齐中补丁冗余和模糊问题,在多个基准测试和视觉编码器上验证了该框架的优越性。
- 研究背景
- 跨模态对齐任务:旨在连接视觉和语言模态,测量图像和文本语义相似性,是多模态任务基础,现有方法分为粗粒度和细粒度对齐两类。
- 现有问题:传统细粒度对齐依赖预训练目标检测器,计算成本高且存在误差传播;基于Transformer的方法虽成主流,但存在补丁冗余和语义模糊问题,影响对齐准确性。
- 相关工作
- 跨模态对齐方法:粗粒度方法将图像和文本编码到共享嵌入空间计算相似度;细粒度方法通过局部特征交互计算累积相似度,但大多依赖目标检测器获取区域特征,对基于Transformer架构在图像补丁上的探索有限。
- 高效视觉Transformer:Vision Transformer(ViT)将图像划分为补丁后用Transformer编码器处理,但计算和内存成本高。已有一些加速方法,但仅适用于单模态视觉任务,未考虑文本上下文,不适合跨模态对齐。
- 视觉语言预训练:早期VLP模型依赖目标检测器,计算成本高且训练不稳定;基于ViT的方法虽消除了对检测器的需求,但存在视觉令牌序列过长、缺乏细粒度对齐信息等问题。
- LAPS框架
- 令牌特征提取:用纯Transformer架构分别作为图像和文本的特征编码器,提取视觉补丁令牌和文本单词令牌特征。
- 语言上下文补丁选择:将补丁选择视为判别任务,通过引入空间信息和语言上下文计算显著性分数,用Gumbel-Softmax技术实现可微采样,确定保留或丢弃的补丁。
- 语义空间补丁校准:对选择的显著补丁进行聚合,融合冗余补丁,增强显著补丁语义表达,得到精简的视觉补丁集。
- 稀疏补丁词对齐:计算精简视觉补丁和文本单词的细粒度对齐分数,采用双向三元组损失和比率约束损失进行训练,推理时按显著性分数选择补丁,减少计算量。
- 实验
- 数据集和指标:使用Flickr30K和MS-COCO数据集,评估指标包括召回率R@K和rSum。
- 实验设置:以ViT和Swin Transformer为视觉编码器,BERT为文本编码器,统一特征维度,训练30个epoch,设置相关参数。
- 对比结果:LAPS在图像文本检索任务上优于现有方法,在视觉基础任务上也有显著优势,在不同视觉编码器下均表现出色。
- 消融实验:验证了LAPS中各模块的有效性,分析了选择和聚合比率的影响,表明文本模态的瘦身会降低性能。
- 可视化分析:展示了不同选择比率下补丁选择、不同聚合比率下补丁校准以及补丁词对齐的可视化结果,证明了框架的有效性和可解释性。
- 研究结论:LAPS是首个在纯Transformer架构上聚焦补丁词对齐、解决补丁冗余和模糊问题的工作,通过语言监督识别显著补丁并校准信息,实验证明其在跨模态对齐任务中的优越性。
摘要
跨模式对齐旨在搭建连接视觉和语言的桥梁。这是一项重要的多模态任务,可以有效地学习图像和文本之间的语义相似性。传统的细粒度对齐方法严重依赖预先训练的对象检测器来提取区域特征,用于后续的区域-词对齐,从而为两阶段训练的区域检测和错误传播问题产生大量的计算成本。在本文中,我们专注于主流的视觉转换器,结合补丁特征进行补丁字对齐,同时解决由此产生的视觉补丁冗余和语义对齐的补丁歧义问题。我们提出了一种新的语言感知补丁精简 (LAPS) 框架,用于细粒度对齐,该框架通过语言监督显式识别冗余的视觉补丁,并纠正它们的语义和空间信息,以促进更有效和一致的补丁词对齐。对各种评估基准和模型主干的广泛实验表明,LAPS 的性能比最先进的细粒度对齐方法高出 5%-15% rSum。我们的代码位于 https://github.com/CrossmodalGroup/LAPS。
Introduction
跨模态对齐旨在弥合不同模态之间的语义差距,例如视觉和语言模态。它是许多多模态任务的基础技术,包括图像文本检索 [14]、视觉问答 [15]、图像描述[27]。跨模态对齐的关键挑战在于有效地测量图像和文本之间的语义相似性,以实现高质量的对齐。
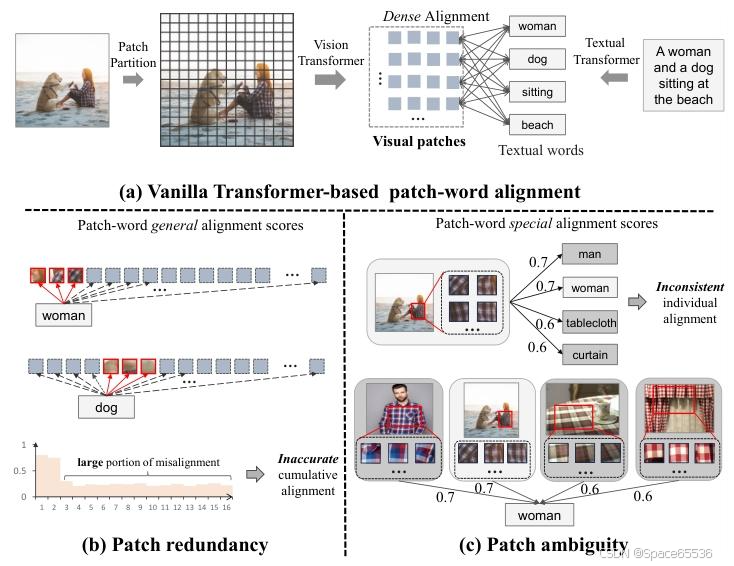
图 1.我们框架的动机。(a) 基于原版 transformer 的细粒度对齐使用视觉转换器 [8, 31] 将图像分成微小的补丁并提取补丁特征,然后在视觉补丁和文本单词之间的交互之间架起桥梁,以学习累积对齐分数。(b) 很大一部分视觉补丁对文本内容来说是多余的。这些冗余的补丁会掩盖关键的补丁,并积累不准确的比对。(c) 视觉补丁是图像的不相交片段,在训练期间与许多补丁相关联。这些补丁会获得各种对象的平均语义,缺乏结构信息,导致补丁语义模糊,总是获得不同文本的适度对齐分数,因此视觉补丁很容易在局部区域出现不匹配,与负面文本样本不一致。
一般来说,现有的跨模态对齐可以分为两种范式。第一种是粗粒度对齐,如[9,14,26]所示,将整个图像和文本分别编码到一个统一的嵌入空间中,然后直接计算全局嵌入的相似度。第二种是细粒度对齐,如[7,21,35]所示,在视觉和文本局部特征之间应用跨模态交互,然后聚合局部对齐以学习累积相似度。
以前的细粒度方法遵循基于检测器的路线图,这需要一个两步过程:首先通过预训练的对象检测器(例如 Faster-RCNN[38])提取区域特征,然后计算视觉区域和文本单词之间的区域-单词对齐。这些框架严重依赖检测器的能力,并带来昂贵的计算(如[24,25]所提到的)。
最近的工作采用纯 Transformer 架构(例如视觉 Transformer[8]),将图像分割为不重叠的补丁,并编码补丁特征以构建补丁-单词对齐(如[23,25]所示)。基于 Transformer 的方法是一个灵活的端到端训练框架,在特征提取方面高效,与基于检测器的方法相比具有可扩展的性能,并且已经成为主流。
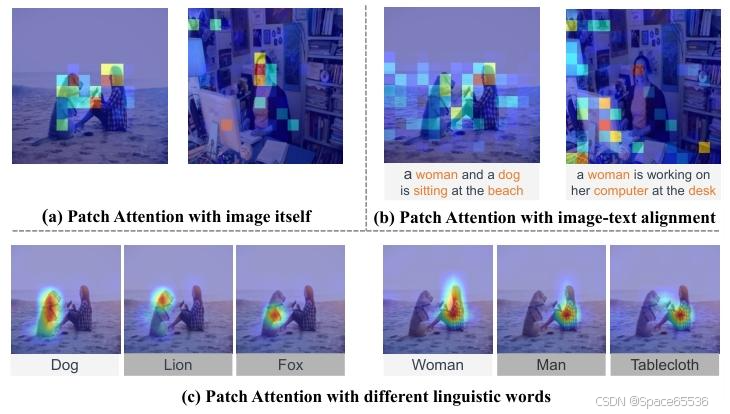
图 2.原版视觉转换器的补丁注意力可视化,其中红色代表高语义反应和图像中的重要区域,蓝色表示不重要。它表明,图像中的重要区域与 (a) 视觉显著性(例如,突出显示了 “狗 ”或 “女人 ”区域),或 (b) 具有图像-文本对齐的文本内容(例如,突出显示了 “海滩 ”或 “计算机 ”区域),而这些单独的补丁缺乏语义完整性和空间结构信息。(c) 因此,相邻区域会得到不同语言单词的高反应(例如,狗的部分视觉区域由文本“lion”或“fox”突出显示,而女人的部分区域由文本“man”或“tablecloth”突出显示)。
然而,基于 vanilla transformer 的 patch-word 框架存在固有的缺陷,即用于语义对齐的 patch redundancy 和 patch ambiguity 问题。视觉转换器 [8] 将图像分成微小的补丁(在 224 和 284 图像分辨率下,它生成
14
×
14
=
196
14 ×14=196
14×14=196 和
24
×
24
=
576
24 ×24=576
24×24=576 补丁),如图 1 所示,其中很大一部分被证明是多余的,例如,非突出的背景或与文本无关的区域,如图 2(a)(b)。海量的冗余补丁会掩盖关键的视觉补丁,并在补丁字交互过程中积累难以忍受的错位,最终带来不准确的累积对齐。
更重要的是,这些碎片化的补丁是图像的微小组成部分。与完整的视觉区域相比,微小的补丁缺乏语义完整性。这将导致语义表达式不明确。如图 2(c) 所示,视觉补丁对于不同的语言概念总是获得适中的对齐分数,这在具有负图像-文本对的局部区域中带来了不一致的补丁-单词对齐。
因此,如何确保视觉补丁的语义完整性以建立准确的对齐,是基于 Transformer 的跨模态框架的核心问题。为了解决这些问题,我们引入了一种语言感知补丁精简(Linguistic-Aware Patch Slimming,LAPS)框架,该框架通过语言监督有效地消除大量冗余补丁,并校准重要补丁的语义和结构信息,以将平均语义表达转换为特定图像的最佳语义。据我们所知,LAPS 是第一个明确探索利用语言上下文进行视觉补丁选择和补丁校准以促进补丁与单词对齐的方法。
如图 3 所示,我们首先使用语言上下文补丁选择(LanguageContext Patch Selection,LPS)模块有效地估计视觉补丁的语义重要性,以通过可微采样挑选出重要补丁。
接下来,我们通过语义 - 空间补丁校准(Semantic-Spatial Patch Calibration,SPC)模块自适应地纠正重要补丁的语义和结构信息,以获得不同的语义表达。
最后,我们使用稀疏补丁 - 单词对齐(Sparse Patch-Word Alignment,SPA)模块促进视觉补丁和文本单词之间的细粒度交互。
因此,LAPS 扩展了基于原始 Transformer 的框架,以实现更准确和一致的补丁 - 单词对齐。
2. 相关工作
2.1. Cross-Modal Alignment
根据跨模态交互的实现方式,跨模态对齐方法大致可分为两类:粗粒度对齐和细粒度对齐。
粗粒度方法将图像和句子编码到一个共享的嵌入空间中[11–13],并通过跨模态嵌入的余弦相似度计算语义相似度。先前的方法[4,43]通常增强提取的局部特征并将其聚合以学习全局嵌入,例如,VSE++[9]利用区域特征上的平均池化来学习统一嵌入。
细粒度方法明确地在两种模态的局部特征之间执行跨模态交互,然后计算累积相似度得分。[3,7,21,47]。先前的工作通常强调图像区域和文本单词之间的语义对齐。例如,SCAN[21]引入了一种注意力机制,以关注显著对齐同时抑制错位。SGR[7]通过相似性推理网络扩展了 SCAN 框架,以细化区域-单词注意力。SHAN[35]将硬编码分配与 SCAN 相结合,以实现有效的区域-单词对齐。
然而,目前的细粒度方法 [7, 21, 35, 47] 严重依赖对象检测器作为视觉编码器来获取区域特征。在映像补丁上对基于 transformer 的架构的探索相对有限。我们专注于视觉补丁,并解决语义对齐的补丁冗余和歧义问题。
2.2. Efficient Vision Transformer
视觉Transformer(ViT)[8]是主流的视觉架构,它基于空间分布将整个图像分割为不重叠的块,并将这些块作为视觉标记序列输入到纯 Transformer [41]编码器中。原始 Transformer 具有较高的计算和内存成本,因为自注意力关于标记数量具有二次计算复杂度[31,42]。最近,提出了标记剪枝方法[28,34,37,44],通过在推理阶段减少标记数量来加速 ViT。一些工作[20,34,37]引入了预定义的预测网络来对视觉标记进行评分,并根据分数丢弃不重要的标记。其他工作[10,28,44]使用类别标记的注意力来评估标记的重要性并聚合冗余标记。然而,上述方法仅关注单模态的视觉任务,不适用于我们的跨模态对齐,因为它们在不考虑文本上下文的情况下直接修剪图像标记。
2.3. VLP
早期的视觉语言预训练 (VLP) 模型遵循基于检测器的路线图 [5, 22],这需要一个两步过程:首先,它通过预先训练的对象检测器提取视觉特征。然后,它将文本和视觉特征集成到多模态编码器中以进行预训练。尽管这种方法在各种下游任务中产生了强大的性能,但它也带来了昂贵的计算和不稳定的检测训练的挑战。最近,基于 ViT 的方法 [16, 19, 24] 采用纯 transformer 架构对图像进行编码,消除了对对象检测器的要求并启用了端到端 VLP 框架。然而,它们难以处理冗长的视觉标记序列,并且缺乏细粒度的跨模态比对信息。这些长视觉序列还增加了计算成本,并为跨模态融合引入了噪声视觉信息。一些工作 [17, 18] 提出了补丁融合方法,以学习视觉标记序列的简洁总结并增强跨模态融合。
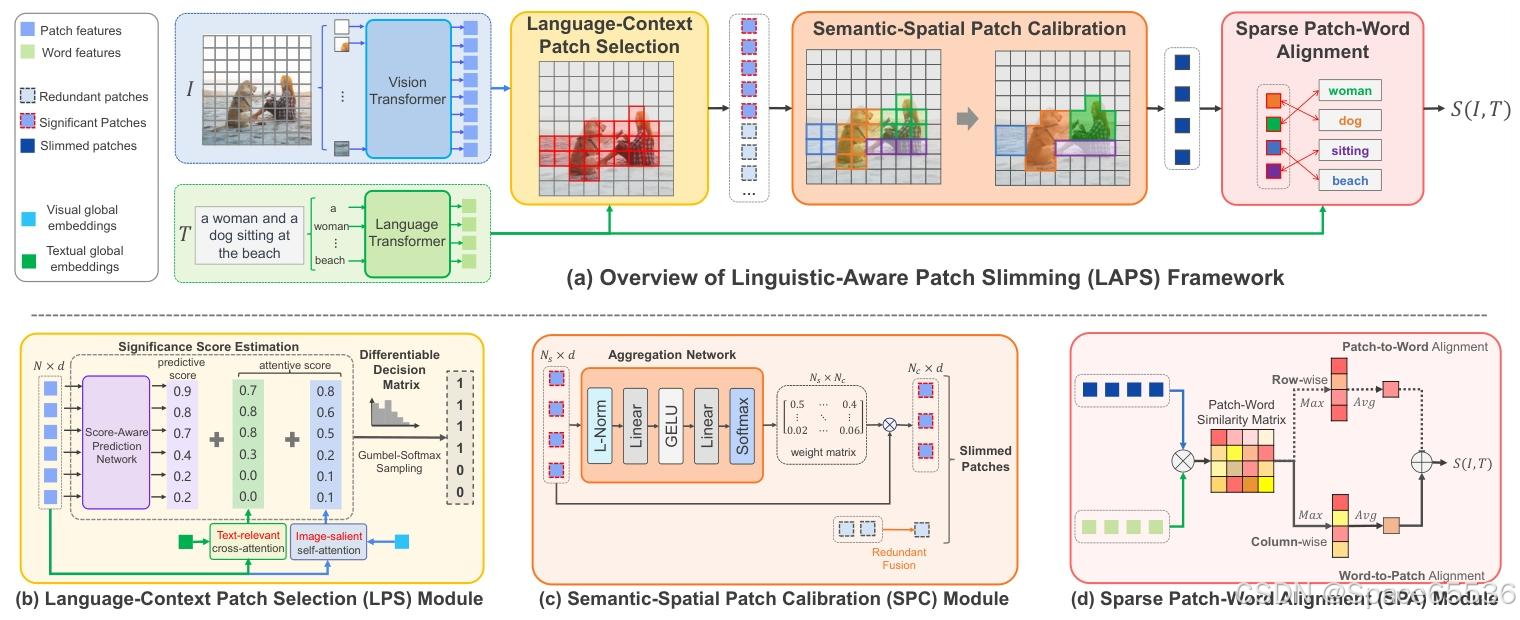
图 3.(a) 我们用于细粒度跨模态对齐的语言感知补丁精简 (LAPS) 框架概述。给定一个图像-文本对 ( I , T ) (I, T) (I,T) ,我们首先对它们进行标记化,然后使用纯 Transformer 编码器来提取视觉补丁特征和文本单词特征。然后,我们提出了语言-上下文补丁选择 (LPS) 模块,通过语言监督来识别与文本相关的补丁。接下来,我们提出了语义空间补丁校准 (SPC) 模块来纠正重要补丁的语义和空间信息,然后获得不同的语义表达式。最后,我们提出了稀疏补丁字对齐 (SPA) 模块来计算稀疏补丁字对齐分数 S ( I , T ) S(I, T) S(I,T) 。(b)(c)(d) 分别介绍拟议的 LPS、SPC 和 SPA 模块的详细架构。
3. 方法
3.1. Token Feature Extraction
首先,我们采用纯 transformer 架构 [41] 作为图像和文本输入的特征编码器,分别提取视觉和文本标记序列。
Visual Patch Tokens.
对于一张图像 I,我们将视觉变换器(如[8,31]中所提及的)作为视觉编码器。图像基于空间分布被划分成 N 个不重叠的小块。随后,我们将这些小块作为视觉标记序列输入到视觉变换器中,视觉变换器由多个自注意力层组成。我们可以获得一组视觉小块特征
V
=
{
v
c
l
s
,
v
1
,
⋯
,
v
N
}
∈
R
(
N
+
1
)
×
d
V=\{v_{cls},v_{1},\cdots,v_{N}\}\in\mathbb{R}^{(N + 1)\times d}
V={vcls,v1,⋯,vN}∈R(N+1)×d。其中
v
c
l
s
v_{cls}
vcls是图像中的[CLS]标记,d 是特征维度。
Textual Word Tokens.
对于句子 T ,我们使用 standard sequence transformer BERT [6] 作为文本编码器。同样,句子被分词化为语言单词 linguistic words,并被馈送到编码器。我们得到一组文本单词特征
T
=
t
1
,
⋯
,
t
M
∈
R
M
×
d
T={t_{1}, \cdots, t_{M}} \in \mathbb{R}^{M ×d}
T=t1,⋯,tM∈RM×d ,M 是句子中的单词数。
3.2. Language-Context Patch Selection 文本上下文patch 选择
在获得第 3.1 节获得的视觉补丁特征和文本单词特征后,我们想为图像挑选出重要的视觉补丁,如图 3(b) 所示。
3.2.1 Significance Score Estimation
与 ViT 的 token pruning (标记修剪) [28, 44] 类似,我们将补丁选择视为一项判别性任务,即估计每个补丁的显着性分数,然后根据分数确定选择。我们首先将图像中的空间信息引入补丁特征,并使用 Score-Aware Prediction Network 来学习显着分数。该网络由一个两层 MLP 和一个 Sigmoid 函数组成。
a
i
p
=
S
i
g
m
o
i
d
(
M
L
P
(
v
i
)
)
,
i
∈
{
1
,
.
.
.
,
N
}
(
1
)
a_{i}^{p}=Sigmoid\left(M L P\left(v_{i}\right)\right), i \in\{1, ..., N\} (1)
aip=Sigmoid(MLP(vi)),i∈{1,...,N}(1),
其中
a
i
p
∈
[
0
,
1
]
a_{i}^{p} \in[0,1]
aip∈[0,1] 是第 i 个补丁的显著性分数。值
a
i
p
a_{i}^{p}
aip 高表示补丁值更重要
v
i
v_{i}
vi 。然而,对于跨模态对齐来说,仅仅依靠评分网络来预测没有文本监督的重要补丁是不够的 [34, 37] 。因此,我们计算视觉补丁和文本单词之间的注意力分数,以引入语言上下文。
我们提出两种不同的注意力分数:首先,我们计算视觉块与文本表示之间的交叉注意力,从而得到与文本相关的注意力分数
a
r
a^{r}
ar。其次,我们计算视觉块内部的自注意力,产生图像显著的注意力分数
a
s
a^{s}
as:
a
i
r
=
N
o
r
m
(
v
i
T
⋅
t
g
l
o
/
d
)
,
a
i
s
=
N
o
r
m
(
v
i
T
⋅
v
g
l
o
/
d
)
(
2
)
a_{i}^{r}=Norm\left(v_{i}^{T} \cdot t_{g l o} / d\right), a_{i}^{s}=Norm\left(v_{i}^{T} \cdot v_{g l o} / d\right) (2)
air=Norm(viT⋅tglo/d),ais=Norm(viT⋅vglo/d)(2)
这里“Norm”表示将注意力得分归一化到 0 - 1 的范围,以确保与预测得分
a
i
p
a_{i}^{p}
aip具有一致性。“
v
g
l
o
v_{glo}
vglo”“
t
g
l
o
t_{glo}
tglo”是视觉和文本的全局嵌入,是对图像块特征或单词特征的平均池化结果。
我们整合上述分数以得出最终的重要性得分,其中 β 作为一个权重参数。
a
i
=
(
1
−
β
)
a
i
p
+
β
2
(
a
i
s
+
a
i
r
)
a_{i}=(1-\beta) a_{i}^{p}+\frac{\beta}{2}\left(a_{i}^{s}+a_{i}^{r}\right)
ai=(1−β)aip+2β(ais+air)
3.2.2 Differentiable Decision Matrix 可微决策矩阵
选择显著性补丁的挑战在于将显著性分数 a = [ a 1 , a 2 , . . . , a N ] ∈ R N a=[a_{1}, a_{2}, ..., a_{N}] \in \mathbb{R}^{N} a=[a1,a2,...,aN]∈RN 转换为二元决策矩阵 0 , 1 N {0,1}^{N} 0,1N ,该矩阵决定是否选择每个补丁。朴素采样,例如根据显著性分数的值选择前 K 个补丁,是不可微分的,因此阻碍了端到端优化的可行性。为了克服这一挑战,我们采用了 Gumbel-Softmax 技术 [33] 来提供平滑且可区分的采样过程。
Gumbel-Softmax 矩阵的推导公式为:
M
i
,
l
=
e
x
p
(
l
o
g
(
m
i
,
l
+
G
i
,
l
)
/
τ
)
∑
j
=
1
L
e
x
p
(
l
o
g
(
m
i
,
j
+
G
i
,
j
)
/
τ
)
M_{i, l}=\frac{exp \left(log \left(m_{i, l}+G_{i, l}\right) / \tau\right)}{\sum_{j=1}^{L} exp \left(log \left(m_{i, j}+G_{i, j}\right) / \tau\right)}
Mi,l=∑j=1Lexp(log(mi,j+Gi,j)/τ)exp(log(mi,l+Gi,l)/τ) 其中
M
∈
R
N
×
L
M \in \mathbb{R}^{N ×L}
M∈RN×L 和 L 是类别的总数(
L
=
2
L=2
L=2 用于二进制决策,
m
i
,
1
=
a
i
m_{i, 1}=a_{i}
mi,1=ai ,
m
i
,
2
=
1
−
a
i
m_{i, 2}=1-a_{i}
mi,2=1−ai )。
G
i
=
−
l
o
g
(
−
l
o
g
(
U
i
)
)
G_{i}=-log (-log (U_{i}))
Gi=−log(−log(Ui)) 是 Gumbel 分布,
U
i
U_{i}
Ui 是均匀分布 (0, 1),T 控制 M 的平滑度。最后,我们使用 arg-max 操作从 M 中采样,得到可微决策矩阵 D 。
D = S a m p l i n g ( M ) ∗ , 1 ∈ { 0 , 1 } N , ( 5 ) D=Sampling(M)_{*, 1} \in\{0,1\}^{N}, (5) D=Sampling(M)∗,1∈{0,1}N,(5),其中 D 作为采样 M 的第一列获得,该列是通过 arg-max 运算获得的独热矩阵。因此,D 表示补丁选择的结果: 1表示重要补丁,“0”是冗余补丁。在训练阶段,梯度可以通过可微决策矩阵反向传播到分数预测网络。 1 表示重要补丁,0是冗余补丁。在训练阶段,梯度可以通过可微决策矩阵反向传播到分数预测网络。
3.3. Semantic-Spatial Patch Calibration
在通过 3.2 节中的语言监督选择了重要的视觉补丁后,我们希望增强重要补丁的语义表达,如图 3©所示。
我们将选定的重要补丁标记为 V s = { v 1 , … , v N s } ∈ R N s × d V_{s}=\{v_{1},\ldots,v_{N_{s}}\}\in\mathbb{R}^{N_{s}×d} Vs={v1,…,vNs}∈RNs×d,其中 N s N_{s} Ns是重要补丁的数量。我们使用聚合网络[48]来学习多个聚合权重,并聚合 N s N_{s} Ns个重要补丁以生成 N c N_{c} Nc个信息丰富的补丁。
v
^
j
=
∑
i
=
1
N
s
(
W
)
i
j
⋅
v
i
,
j
=
[
1
,
.
.
.
,
N
c
]
\hat{v}_{j}=\sum_{i=1}^{N_{s}}(W)_{i j} \cdot v_{i}, j=\left[1, ..., N_{c}\right]
v^j=∑i=1Ns(W)ij⋅vi,j=[1,...,Nc]
(
W
)
i
j
(W)_{i j}
(W)ij是归一化权重矩阵
W
∈
R
N
s
×
N
c
W\in\mathbb{R}^{N_{s}×N_{c}}
W∈RNs×Nc的元素,有一个权重矩阵 W,它的元素用
(
W
)
i
j
(W)_{i j}
(W)ij表示,并且这个矩阵的维度是
N
s
×
N
c
N_{s}×N_{c}
Ns×Nc,其中
N
c
N_{c}
Nc是聚合块的数量,且
N
c
<
N
s
N_{c}\lt N_{s}
Nc<Ns。同时满足“
∑
i
=
1
N
s
(
W
)
i
j
=
1
\sum_{i=1}^{N_{s}}(W)_{i j}=1
∑i=1Ns(W)ij=1”,即对于每一列 j,所有行的元素之和为 1。
接着,提到权重矩阵是通过一个多层感知机(MLP)和 softmax 函数学习得到的,输入是显著块。即w = Softmax (MLP
(
V
s
)
)
(V_{s}))
(Vs)),其中
V
s
V_{s}
Vs是显著块特征,通过 MLP 和 softmax 函数得到权重 w。
然后,将决策矩阵 D 视为掩码矩阵,在计算 softmax 函数之前选择显著块特征
V
s
V_{s}
Vs。最后,说明聚合网络可以自适应地聚合具有相似语义的块,并且对于端到端的训练是可微的。
虽然冗余的 patch 可以直接丢弃,但它们可能包含用于跨模态对齐的有价值的视觉语义,因此我们将冗余的 patch 融合成一个 patch。
v
^
f
=
∑
i
∈
N
a
^
i
⋅
v
i
,
a
^
i
=
e
x
p
(
a
i
)
D
i
∑
i
=
1
N
e
x
p
(
a
i
)
D
i
,
(
7
)
\hat{v}_{f}=\sum_{i \in \mathcal{N}} \hat{a}_{i} \cdot v_{i}, \hat{a}_{i}=\frac{exp \left(a_{i}\right) D_{i}}{\sum_{i=1}^{N} exp \left(a_{i}\right) D_{i}}, (7)
v^f=∑i∈Na^i⋅vi,a^i=∑i=1Nexp(ai)Diexp(ai)Di,(7),
其中 N 是为冗余补丁设置的索引, a ^ i \hat{a}_{i} a^i 是基于显著性分数 a i a_{i} ai 的标准化权重。
最后,我们得到一组精简的视觉补丁 V ^ = \hat{V}= V^= v c l s , v ^ 1 , ⋯ , v ^ N c , v ^ f {v_{c l s}, \hat{v}_{1}, \cdots, \hat{v}_{N_{c}}, \hat{v}_{f}} vcls,v^1,⋯,v^Nc,v^f,[CLS] 令牌始终被保留。
3.4. Sparse Patch-Word Alignment
如图 3(d) 所示,我们通过一组精简的视觉补丁
V
^
\hat{V}
V^ 和初始文本单词 T 来计算细粒度对齐。
为方便起见,我们近似为
∣
V
^
∣
=
|\hat{V}|=
∣V^∣=
N
c
N_{c}
Nc ,
∣
T
∣
=
M
|T|=M
∣T∣=M 。我们首先计算标记相似度,生成补丁字相似度矩阵
A
∈
R
N
c
×
M
A \in \mathbb{R}^{N_{c} ×M}
A∈RNc×M ,其中,
(
A
)
i
j
=
(
v
^
i
)
T
t
j
∥
v
^
i
∥
∥
t
j
∥
(A)_{i j}=\frac{(\hat{v}_{i})^{T} t_{j}}{\left\|\hat{v}_{i}\right\|\left\|t_{j}\right\|}
(A)ij=∥v^i∥∥tj∥(v^i)Ttj表示第 i 个视觉块与第 j 个文本单词之间的对齐分数。
接下来,我们采用最大对应交互来聚合对齐方式:我们首先为每个补丁(或每个单词)选择对齐程度最高的文本单词(或视觉补丁)。然后,我们计算这些对齐分数的平均值,以表示图像 I 和句子 T 之间的总体对齐分数,表示为
S
(
I
,
T
)
S(I, T)
S(I,T) 。
S
(
I
,
T
)
=
1
N
c
∑
i
=
1
N
c
m
a
x
j
(
A
)
i
j
⏟
p
a
t
c
h
−
t
o
−
w
o
r
d
a
l
i
g
n
m
e
n
t
+
1
M
∑
j
=
1
M
m
a
x
i
(
A
)
i
j
⏟
w
o
r
d
−
t
o
−
p
a
t
c
h
a
l
i
g
n
m
e
n
t
,
(
8
)
S(I, T)=\underbrace{\frac{1}{N_{c}} \sum_{i=1}^{N_{c}} max _{j}(A)_{i j}}_{patch-to-word alignment }+\underbrace{\frac{1}{M} \sum_{j=1}^{M} max _{i}(A)_{i j}}_{word-to-patch alignment }, \quad(8)
S(I,T)=patch−to−wordalignment
Nc1i=1∑Ncmaxj(A)ij+word−to−patchalignment
M1j=1∑Mmaxi(A)ij,(8)
按照以前的方法,我们使用 bi-direction triplet loss with hard negative mining [9]。
L a l i g n = ∑ ( I , T ) [ α − S ( I , T ) + S ( I , T ^ ) ] + + [ α − S ( I , T ) + S ( I ^ , T ) ] + , \begin{aligned} \mathcal{L}_{align }= & \sum_{(I, T)}[\alpha-S(I, T)+S(I, \hat{T})]_{+} \\ & +[\alpha-S(I, T)+S(\hat{I}, T)]_{+}, \end{aligned} Lalign=(I,T)∑[α−S(I,T)+S(I,T^)]++[α−S(I,T)+S(I^,T)]+,
其中α表示边距参数, [ x ] + = m a x ( x , 0 ) [x]_{+}=max (x, 0) [x]+=max(x,0) 和 ( I , T ) (I, T) (I,T) 是小批量中的正图像-文本对。
我们将 T ^ = a r g m a x j ≠ T S ( I , j ) \hat{T}=argmax_{j ≠T} S(I, j) T^=argmaxj=TS(I,j) 和 I ^ = \hat{I}= I^= a r g m a x i ≠ I S ( i , I ) argmax_{i ≠I} S(i, I) argmaxi=IS(i,I) 分别表示为小批量中最难的否定文本和图像示例。
此外,我们将所选补丁的比例限制为预定义值 ρ,以实现稳定训练[37],使用均方误差损失来监督该过程。最后,我们将跨模态对齐损失 L a l i g n L_{align } Lalign(公式(9))与比例约束损失 L r a t i o L_{ratio } Lratio相结合:
L = L a l i g n + L r a t i o , L r a t i o = ( ρ − 1 N ∑ i = 1 N D i ) 2 , ( 10 ) \mathcal{L}=\mathcal{L}_{align }+\mathcal{L}_{ratio }, \mathcal{L}_{ratio }=\left(\rho-\frac{1}{N} \sum_{i=1}^{N} D_{i}\right)^{2},(10) L=Lalign+Lratio,Lratio=(ρ−N1∑i=1NDi)2,(10)
在推理阶段,我们不是使用 Gumbel Softmax 采样,而是根据重要性得分的值直接选择常数
N
s
N_{s}
Ns个补丁。
N
s
N_{s}
Ns由选择比率
P
P
P确定,即
N
s
=
ρ
N
N_{s}=\rho N
Ns=ρN。
使用选定的
N
s
N_{s}
Ns个补丁在没有决策矩阵的情况下执行后续过程,以减少计算量。还预先定义了聚合比率
λ
\lambda
λ,
N
c
=
λ
N
s
=
(
λ
⋅
ρ
)
N
N_{c}=\lambda N_{s}=(\lambda\cdot\rho)N
Nc=λNs=(λ⋅ρ)N。
4. 实验
4.2. 实现细节
我们使用 Vision Transformer (ViT) [8] (一个补丁为 16×16 像素)和 Swin Transformer (Swin) [31] (一个补丁为 32×32 像素)作为视觉编码器,然后使用 BERT [6] 作为文本编码器。所有编码器都是Base版本。
图像分辨率为 224×224 或 384×384,ViT 为 14×14 和 24×24 补丁(Swin 为 7×7 和 12×12 补丁)。此外,我们在编码器顶部引入了一个额外的线性层,以统一特征维度为
d
=
512
d=512
d=512 。
整个框架使用 AdamW [32] 优化器训练了 30 个 epoch,三元组损失的边际为
α
=
0.2
\alpha=0.2
α=0.2 。权重参数
β
=
0.8
\beta=0.8
β=0.8 ,ViT 主干的选择比例
ρ
=
0.5
\rho=0.5
ρ=0.5 和聚合比例
λ
=
0.4
\lambda=0.4
λ=0.4(
ρ
=
0.8
\rho=0.8
ρ=0.8 和
λ
=
0.6
\lambda=0.6
λ=0.6 用于 Swin 主干)。
4.4. 消融实验
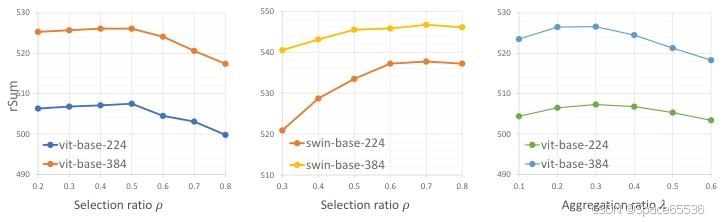
图 7.Flick30K 上不同选择比率 ρ 和聚合比率 λ 与各种可视编码器的比较。
4.4.1.选择和聚合比例
我们在图 7 中显示了选择比率 P 和聚集比率 λ 对不同可视编码器的影响。我们的框架可以有效地缩小视觉补丁以增强跨模式对齐。过多的 patch 选择和小比率的聚合也会损害性能,尤其是在 Swin [31] 编码器上,在小窗口内使用局部注意力。
4.4.2.模块增益
补丁选择和补丁校准模块在语义对齐中起重要作用,语言监督对选择与文本相关的视觉补丁很重要,聚合冗余补丁有帮助。使用特定聚类算法聚合补丁会降低性能且效率低,稀疏机制适合补丁与单词的对齐,双向对齐是最优的。此外,LAPS 是一个独立的框架,可以与其他对齐方法以即插即用的方式结合,用 SCAN 替换稀疏对齐时模型性能得到提升。
Table 4. Comparison of different module ablations for our framework on Flickr30K. We also show the results of the word slimming (selection + aggregation) of textual modality for our framework.
| Modules | Different Settings | IMG→TEXT | TEXT→IMG | ||
|---|---|---|---|---|---|
| R@1 | R@5 | R@1 | R@5 | ||
| LPS | without patch selection process | 69.2 | 91.9 | 58.5 | 84.9 |
| without language-context | 71.1 | 92.2 | 59.4 | 85.5 | |
| only attentive scores | 73.5 | 93.1 | 61.9 | 86.8 | |
| SPC | without patch calibration process | 70.4 | 91.3 | 58.9 | 85.3 |
| without redundant fusion | 73.5 | 93.2 | 61.1 | 87.2 | |
| use the clustering algorithm [46] | 68.4 | 88.5 | 57.0 | 82.6 | |
| SPA | replace with SCAN alignment [21] | 71.3 | 91.4 | 60.8 | 85.6 |
| only patch-to-word alignment | 70.9 | 90.8 | 58.9 | 85.1 | |
| only word-to-patch alignment | 72.7 | 92.5 | 60.3 | 86.4 | |
| introduce word selection | 70.1 | 90.3 | 57.5 | 82.7 | |
| introduce word aggregation | 71.3 | 91.6 | 58.8 | 84.3 | |
| introduce word selection & aggregation | 67.7 | 88.2 | 55.1 | 80.5 | |
| Complete LAPS | 74.0 | 93.4 | 62.5 | 87.3 |
4.4.3. Word Slimming
我们的框架试图解决视觉冗余和歧义的问题。而这些挑战对于文本模态来说同样重要。如表 4 所示,我们将 word slimming 过程(包括选择和聚合)引入我们的框架。我们发现互补词的精简会阻碍语义对齐并降低性能,因为文本标记通常具有很高的信息密度 [6]。首先,文本由人类创造的离散单词组成。与像素图像相比,文本本质上具有更高的语义特征。因此,文本冗余比图像弱。此外,典型数据集的文本长度较短(在 COCO/Flickr 中平均为 10 个单词)。LAPS 的功能不能在现有数据集中发布。
5. 总结
在本文中,我们介绍了一种用于跨模态对齐的新型语言感知补丁精简框架 (LAPS),这是第一个明确关注纯基于 transformer 架构的补丁词对齐以解决patch冗余和歧义问题的工作。LAPS 通过语言监督识别重要的视觉补丁,然后纠正语义和结构信息,以构建更准确和一致的对齐方式。对各种基准测试和可视化编码器的广泛实验证明了我们框架的优越性。


















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









