







论文地址:https://arxiv.org/abs/2004.13379
bib引用:
@article{
Vandenhende_2021,
title={
Multi-Task Learning for Dense Prediction Tasks: A Survey},
ISSN={
1939-3539},
url={
http://dx.doi.org/10.1109/TPAMI.2021.3054719},
DOI={
10.1109/tpami.2021.3054719},
journal={
IEEE Transactions on Pattern Analysis and Machine Intelligence},
publisher={
Institute of Electrical and Electronics Engineers (IEEE)},
author={
Vandenhende, Simon and Georgoulis, Stamatios and Van Gansbeke, Wouter and Proesmans, Marc and Dai, Dengxin and Van Gool, Luc},
year={
2021},
pages={
1–1} }
实验数据集:NYUD-v2[73](795Train+654Test)和PASCAL[74](10581Train+1449Test)
现代架构总结:以编码器为核心的;以解码器为核心的
方法总结:
- Uncertainty Weighting:基于同方差不确定性【与任务本身相关且与输入样本无关的噪声】,动态调整各任务的权重。
- GradNorm:通过任务的梯度幅度来调整任务的权重。优势——平衡任务的学习速度,同时避免由于任务梯度差异过大导致的训练失衡问题。
- DWA(Dynamic Weight Averaging):基于任务损失下降速度的相对变化来动态调整权重
- DTP(Dynamic Task Prioritization):通过动态调整不同任务的权重,将更多的精力分配给学习“困难”任务。方法的核心思想是根据任务的难度调整权重,但不同于通过损失值直接衡量任务难度的传统方法(例如 GradNorm),DTP 利用关键性能指标(Key Performance Indicators, KPIs)来更准确和直观地度量任务的难易程度。
- MGDA(multiple gradient descent algorithm):通过在特定任务梯度中找到共同方向来更新共享网络权重,只要有共同方向能使特定任务损失降低,就还未达到帕累托最优点。这种方法的优点是在权重更新步骤中避免了冲突梯度。
- (Lin 等人观察到 MGDA 只能找到众多帕累托最优解中的一个,且不能保证得到的解满足用户需求,于是将 MGDA 进行了推广以生成一组具有代表性的帕累托解,以便从中选择一个首选解。但目前该方法仅应用于小规模数据集(如 Multi-MNIST)。)
一些结论:
- 多任务学习相对于单任务学习有几个优势,即更小的内存占用、更少的计算量和更好的性能。然而,很少有模型能够完全发挥这种潜力。
- 当任务之间存在较强关联时,MTL能够更好地利用任务间的共享信息,提升模型对相关任务的综合处理能力。
- 在任务相关性高且字典规模适中的情况下MTL效果较好,而在任务字典庞大且多样化时MTL面临较大挑战
- 以解码器为核心的架构在多任务性能上通常优于encoder based architecture
- MTL架构的有效性 > 任务平衡策略的有效性
摘要
With the advent of deep learning, many dense prediction tasks, i.e. tasks that produce pixel-level predictions, have seen significant performance improvements. The typical approach is to learn these tasks in isolation, that is, a separate neural network is trained for each individual task. Yet, recent multi-task learning (MTL) techniques have shown promising results w.r.t. performance, computations and/or memory footprint, by jointly tackling multiple tasks through a learned shared representation. In this survey, we provide a well-rounded view on state-of-the-art deep learning approaches for MTL in computer vision, explicitly emphasizing on dense prediction tasks. Our contributions concern the following. First, we consider MTL from a network architecture point-of-view. We include an extensive overview and discuss the advantages/disadvantages of recent popular MTL models. Second, we examine various optimization methods to tackle the joint learning of multiple tasks. We summarize the qualitative elements of these works and explore their commonalities and differences. Finally, we provide an extensive experimental evaluation across a variety of dense prediction benchmarks to examine the pros and cons of the different methods, including both architectural and optimization based strategies.
随着深度学习的出现,许多密集预测任务,即产生像素级预测的任务,已经看到了显着的性能改进。典型的方法是孤立地学习这些任务,即为每个单独的任务训练一个单独的神经网络。然而,最近的多任务学习(MTL)技术通过学习的共享表示联合处理多个任务,在性能、计算和/或内存占用方面显示出有希望的结果。在本次调查中,我们全面介绍了计算机视觉中MTL的最先进深度学习方法,明确强调密集预测任务。我们的贡献涉及以下方面。首先,我们从网络架构的角度考虑MTL。我们包括广泛的概述并讨论了最近流行的MTL模型的优点/缺点。其次,我们研究了各种优化方法来解决多个任务的联合学习问题。我们总结了这些工作的定性元素,并探索了它们的共性和差异。最后,我们在各种密集的预测基准中提供了广泛的实验评估,以检查不同方法的优缺点,包括架构和基于优化的策略。
Introduction
- 多任务学习:旨在通过共享任务间的表示来提高每个任务的泛化能力。在深度学习时代,MTL转化为设计能够处理多个相关任务的训练信号的网络架构。
- 综述范围:本综述专注于密集预测任务的多任务学习,通过神经网络架构进行。涵盖了多任务学习中的多任务共享表示,包括跨任务的卷积层、池化层和全连接层等。研究了不同方法的优缺点,进行了详尽的文献综述,并讨论了各种基准测试,以衡量不同方法的优缺点,包括基于架构和基于优化的策略。
- 动机:大量关于MTL的文献相当零散。本文对深度多任务架构进行了系统回顾,旨在对不同的MTL方法进行全面比较,研究其在密集预测任务中的性能和优缺点。同时,解决场景理解中像素级任务常具有相似特征和结构的问题,利用MTL来平衡任务对网络权重更新的影响。
- 相关工作:不同的研究小组对MTL进行了综述,如Crawan等对MTL中的任务选择进行了综述,Peng等对基于优化的MTL方法进行了综述。但这些综述没有对密集预测任务给予足够关注。
- Paper overview:论文首先介绍了MTL的历史概述和分类,包括非深度学习和深度学习方法。接着,在深度多任务架构部分,分析了不同组的工作,并对每种架构进行了详细介绍。随后,在优化策略部分,回顾了相关技术和方法。最后,讨论了MTL与其他领域的关系,并总结了论文内容。
2. Deep Multi-Task Architectures
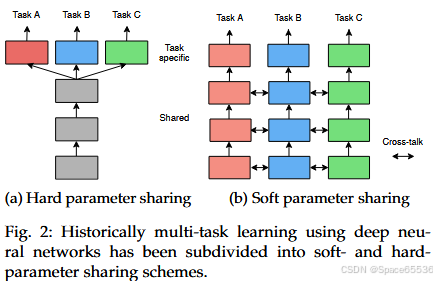
2.1 Historical Overview and Taxonomy【图2】
在深度学习时代之前,MTL works试图对任务之间的公共信息进行建模,希望联合任务学习能够带来更好的泛化性能。为了实现这一点,他们在任务参数空间上放置了假设,例如:任务参数应该彼此靠近,w. r.t.一些距离度量[38]、[39]、[40]、[41],共享一个共同的概率先验[42]、[43]、[44]、[45]、[46],或者驻留在低维子空间[47]、[48]、[49]或流形[50]中。当所有任务都相关时,这些假设效果很好[38]、[47]、[51]、[52],但如果信息共享发生在不相关的任务之间,则可能导致性能下降。后者是MTL中的一个已知问题,称为负迁移。为了缓解这个问题,其中一些作品选择根据先前对其相似性或相关性的信念将任务分组。
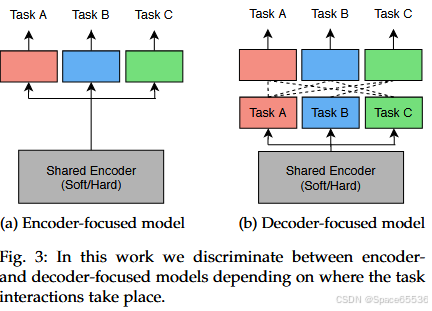
2.2. 以编码器为核心的架构
以编码器为中心的架构(参见图3a)在编码阶段共享任务特征,然后使用一组独立的特定任务头处理它们。许多作品[19]、[20]、[22]、[53]、[54]遵循临时策略,通过与小型特定任务头(参见图2a)共享现成的骨干网络。该模型依赖于编码器(即骨干网络)来学习场景的通用表示。然后,特定任务头使用编码器的特征来获得每个任务的预测。虽然这个简单的模型在所有任务中共享完整的编码器,但最近的作品考虑了特征共享应该在编码器中的位置和方式。我们将在以下部分讨论这种共享策略。
2.3 以解码器为核心的架构
第2.2节中以编码器为中心的架构遵循一个共同的模式:它们在一个处理周期中直接预测来自同一输入的所有任务输出(即所有预测都以并行或顺序生成一次,之后不进行细化)。通过这样做,它们无法捕捉任务之间的共性和差异,这些共性和差异可能对彼此都有成效(例如深度不连续性通常与语义边缘对齐)。可以说,这可能是以编码器为中心的MTL方法仅实现适度性能改进的原因(参见第4.3.1节)。为了缓解这个问题,最近的一些工作首先使用多任务网络进行初始任务预测,然后利用这些初始预测的特征以一次性或递归的方式进一步改进每个任务输出。由于这些MTL方法在解码阶段也共享或交换信息,我们将它们称为以解码器为中心的架构(参见图3b)。
3. Optimization in MTL
- Task Balancing 的定义:在多任务学习中,使各个任务在网络权重的学习过程中不会出现某个或某些任务占据主导地位的情况,通过一些方法实现所有任务在联合学习中的合理分配和平衡。
3.1. 任务平衡的方法
具体探讨如何在优化过程中平衡多个任务的影响,以及任务间梯度冲突的问题:
-
多任务学习中的优化目标:在多任务学习中,优化目标是所有任务的损失函数的加权和:
L M T L = ∑ i w i ⋅ L i , L_{MTL} = \sum_{i} w_i \cdot L_i, LMTL=i∑wi⋅Li, 其中: L i L_i Li :第 i 个任务的损失。 w i w_i wi:第 i个任务的权重,用于平衡不同任务的贡献。 -
梯度更新规则:使用随机梯度下降(SGD)优化时,共享层的权重 ( W_{sh} ) 的更新规则为:
W s h ← W s h − γ ∑ i w i ∂ L i ∂ W s h , W_{sh} \leftarrow W_{sh} - \gamma \sum_i w_i \frac{\partial L_i}{\partial W_{sh}}, Wsh←Wsh−γi∑wi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1956
1956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









