










概叙
Redisson简介
Redission是一个基于Redis实现的Java分布式对象存储和缓存框架。它提供了丰富的分布式数据结构和服务。例如:分布式锁、分布式队列、分布式Rate Limiter等。
Redisson 顾名思义,Redis 的儿子,Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。
其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service) Redisson提供了使用Redis的最简单和最便捷的方法。
Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
一个基于Redis实现的分布式工具,有基本分布式对象和高级又抽象的分布式服务,为每个试图再造分布式轮子的程序员带来了大部分分布式问题的解决办法。
Redisson和Jedis、Lettuce、Spring Data Redis有什么区别?
Redis是一个高性能的键值存储数据库,它支持多种数据结构。在Java生态中,与Redis交互的客户端和库有很多,其中Lettuce、Jedis、Redisson和Spring Data Redis最为常用。这些工具之间有各自的特点、优势以及适合的使用场景,而且它们可以相互协作或独立使用,以满足不同的业务需求。
Redisson和它俩的区别就像一个用鼠标操作图形化界面,一个用命令行操作文件。Redisson是更高层的抽象,Jedis和Lettuce是Redis命令的封装。
- Jedis是Redis官方推出的用于通过Java连接Redis客户端的一个工具包,提供了Redis的各种命令支持。
- 相对于Lettuce,Jedis是一个更加轻量级和直接的Redis客户端。
- 提供了简便的方法来与Redis进行交互。Jedis主要关注于
同步的命令执行方式。 - 由于
Jedis不是线程安全的,因此通常推荐在多线程环境下通过连接池来使用Jedis。 - 虽然Jedis没有内置的异步支持,但它的简单性让它在小型或者中等规模的系统中非常受欢迎,并且它的直接性也使得它在性能上表现出色。
- Lettuce是一种可扩展的线程安全的 Redis 客户端,通讯框架基于Netty,支持高级的 Redis 特性,比如哨兵,集群,管道,自动重新连接和Redis数据模型。
- Spring Boot 2.x 开始 Lettuce 已取代 Jedis 成为首选 Redis 的客户端。
- 一个高性能的Redis客户端。基于Netty实现,并且提供了非阻塞和事件驱动的API;Lettuce客户端完全是
线程安全的,因此可以在多个线程间共享同一个连接实例。 - Lettuce的连接是基于Netty的连接实例,它支持多路复用,即多个命令可以在同一TCP连接上并行执行。
- 由于它的异步能力,Lettuce非常适合需要处理大量并发请求的应用程序,例如微服务架构和响应式编程模型。此外,Lettuce还支持集群、Sentinel、管道和事务等高级功能。
- Redisson是架设在Redis基础上,通讯基于Netty的综合的、新型的中间件,企业级开发中使用Redis的最佳范本。
- 一个在
Jedis和Lettuce之上构建的Redis客户端。 - 提供了一系列分布式Java对象和服务,比如:分布式锁、原子变量、计数器等。Redisson意在通过高层次的抽象使得开发者能够更容易地利用Redis提供的各种功能。
- Redisson通过封装底层的Redis命令,使得在Java代码中操作分布式数据结构就像操作本地数据结构一样自然。
- 如果你的应用程序需要分布式数据类型或者锁,Redisson可能是最佳选择。
- 一个在
- Spring Data Redis:Spring提供的对Redis的高级抽象,它旨在简化Redis的数据访问并与Spring框架无缝集成。
- Spring Data Redis支持Lettuce和Jedis作为其底层连接库,并为开发者提供了一致的操作接口,比如RedisTemplate和各种Repository支持。
- Spring Data Redis允许开发者通过声明式的方式来定义交云与Redis的交互,从而避免了冗余的样板代码,并且可以非常方便地与Spring的其他项目(如Spring Cache、Spring Session)整合。
小结:
- Jedis把Redis命令封装好,Lettuce则进一步有了更丰富的Api,也支持集群等模式。
- 但是两者也都点到为止,只给了你操作Redis数据库的脚手架,而Redisson则是基于Redis、Lua和Netty建立起了成熟的分布式解决方案,甚至redis官方都推荐的一种工具集。
- Spring Data Redis是Spring提供的对Redis的高级抽象,天生与spring无缝粘合。
锁和分布式锁

进程锁

java进程内部锁:synchronized关键字和java.util.concurrent.locks包下的锁。基于jvm,不能跨jvm运行,之所以叫进程锁,就是因为他们只能在进程内部生效,给多线程提供锁服务,分布式和微服务环境下,有一定的局限性,所以就引出来了分布式锁。

增加机器之后,多系统部署变成上图所示,我的天!
假设此时两个用户的请求同时到来(买同一个商品),但是落在了不同的机器上,那么这两个请求是可以同时执行了,还是会出现库存超卖的问题(两人各买一个商品,存在库存只减一个商品的情况;导致最终的超卖问题)。
为什么呢?因为上图中的两个A系统,运行在两个不同的JVM里面,他们加的锁只对属于自己JVM里面的线程有效,对于其他JVM的线程是无效的。
因此,这里的问题是:Java提供的原生锁机制在多机部署场景下失效了
这是因为两台机器加的锁不是同一个锁(两个锁在不同的JVM里面)。
分布式锁

那么,我们只要保证两台机器加的锁是同一个锁,问题不就解决了吗?
此时,就该分布式锁隆重登场了,分布式锁的思路是:
在整个系统提供一个全局、唯一的获取锁的“东西”,然后每个系统在需要加锁时,都去问这个“东西”拿到一把锁,这样不同的系统拿到的就可以认为是同一把锁。
至于这个“东西”,可以是Redis、Zookeeper,也可以是数据库。
图片参考:分布式锁实现方案,你选哪种?_分布式锁的实现知道到哪些?你更推荐哪一种锁?-CSDN博客
进程锁和分布式锁示例
进程锁

分布式锁


触发点

进程锁和分布式锁运行结果:http://localhost:6001/api/v1/redisson/lock?name=Tom

分布式锁
在分布式系统中,实现并发控制是一项非常关键的任务。分布式锁是一种重要的机制,用于确保在分布式环境下只有一个客户端能够执行临界区代码。在前面例子中“库存”,就是一种临界资源,进程锁只能保证在当前进程内部,线程争用临界资源有效;在分布式环境下,进程锁无效,只能通过分布式锁,确保分布式环境下只有一把锁。

在单机系统中,通常使用锁来保护共享资源,以防止多个线程同时访问,确保数据的一致性。然而,在分布式系统中,由于数据分散在不同的节点上,使用单机锁无法解决并发控制的问题。分布式锁的目标是在分布式环境中协调多个客户端之间的访问,以确保数据的一致性和可靠性。
分布式锁有哪些特点呢?
以下是分布式锁的一些特点,分布式锁家族成员并不一定都满足这个要求,实现机制不大一样。
互斥性: 分布式锁要保证在多个客户端之间的互斥。分布式锁必须是互斥的,即同一时刻只有一个客户端能够获取锁,其他客户端必须等待。
可重入性:同一客户端的相同线程,允许重复多次加锁。分布式锁应该支持可重入,允许同一个客户端多次获取同一个锁,而不会被自己阻塞。
锁超时:和本地锁一样支持锁超时,防止死锁。分布式锁通常支持设置超时时间,以避免某个客户端获取锁后发生故障而导致锁永远不释放。
支持阻塞和非阻塞: 能与 ReentrantLock 一样支持 trylock() 非阻塞方式获得锁。Synchronized是阻塞的,ReentrantLock.tryLock()就是非阻塞的。
支持公平锁和非公平锁:公平锁是指按照请求加锁的顺序获得锁,非公平锁真好相反请求加锁是无序的。Synchronized是非公平锁,ReentrantLock(boolean fair)可以创建公平锁。
基本原理和实现方式、以及抉择
分布式锁的基本原理是利用分布式系统中的共享存储来协调客户端之间的访问。常用的共享存储包括:ZooKeeper、Redis、Etcd、Consul
这些共享存储提供了分布式环境下的数据存储和同步机制,可以用于实现分布式锁。

选择分布式锁的实现方式时,需要考虑其优缺点以及适用场景。
-
基于数据库实现分布式锁
- 优点:实现简单,易于控制,能轻松处理一些容易发生死锁或锁竞争问题。
- 缺点:可能会引起严重的性能瓶颈,特别是当锁的数量特别大时。
-
基于Redis实现分布式锁(Redisson)(其次选择)
- 优点:提供了高效的获取锁和释放锁的操作,不需要像使用数据库那样频繁读写数据库,使用起来非常高效。
- 缺点:可能会存在死锁问题,需要谨慎处理。当某个进程获取锁之后,由于某些原因没有来得及释放锁,可能导致其他进程无法获取该锁。
-
Redis 实现的分布式锁的话,不能够 100% 保证可用性 ,因为在真实环境中使用分布式锁,一般都会集群部署 Redis ,来避免单点问题,那么 Redisson 去 Redis 集群上锁的话,先将锁信息写入到主节点中,如果锁信息还没来得及同步到从节点中,主节点就宕机了,就会导致这个锁信息丢失。并且在分布式环境下可能各个机器的时间不同步,都会导致加锁时出现一系列无法预知的问题。
-
因此 RedLock 被 Redis 作者提出用于保证在集群模式下加锁的可靠性,就是去多个 Redis 节点上都尝试加锁,超过一半节点加锁成功,并且加锁后的时间要保证没有超过锁的过期时间,才算加锁成功,具体的流程比较复杂,并且性能较差,了解一下即可
-
-
基于Redis实现分布式锁(红锁Redlock 尽量不使用)
- 优点:提供了多节点分布式锁的实现方式,增加了可靠性。
- 缺点:可靠性还没有被广泛验证,并且严重依赖时间,可能会因为系统延迟或网络问题导致时间错误。
- Redis 中的 RedLock 尽量不使用,因为它为了保证加锁的安全牺牲掉了很多的性能,并且部署成本高(至少部署 5 个 Redis 的主库),使用 Redis 分布式锁建议通过【主从 + 哨兵】部署集群,使用它的分布式锁。
-
基于ZooKeeper实现分布式锁(优先选择)
- 优点:具有良好的顺序性,能够很好地避免死锁和竞争问题,具备高可用性。
-
ZooKeeper 的分布式锁的特点就是:稳定、健壮、可用性强。
-
这得益于 ZooKeeper 这个框架本身的定位就是用来做 分布式协调 的,因此在需要保证可靠性的场景下使用 ZooKeeper 做分布式锁是比较好的
-
- 缺点:实施代价较高,需要依赖ZooKeeper,需要准备一个独立的ZooKeeper集群以维护状态。
- 优点:具有良好的顺序性,能够很好地避免死锁和竞争问题,具备高可用性。
-
基于Etcd实现分布式锁
- 优点:Etcd作为一个可靠的键值存储系统,提供了分布式锁的功能,具有高可用性和一致性保证。
- 缺点:相对于其他轻量级解决方案,Etcd的部署和维护可能更为复杂。
选择合适的分布式锁实现时,应考虑以下几点:
- 性能需求:如果系统对性能要求较高,Redis或Redisson可能是更好的选择,因为它们提供了高效的锁操作。
- 可靠性需求:如果系统对数据的可靠性和一致性有较高要求,ZooKeeper或Etcd可能更适合,因为它们提供了更强的一致性保证和容错能力。
- 成本考虑:如果系统资源有限,可能需要考虑成本较低的解决方案,如基于数据库或Redis的简单实现。
- 系统复杂性:如果系统已经集成了ZooKeeper或Etcd,那么利用这些系统的分布式锁功能可能是最合适的选择。
综上所述,选择分布式锁的实现方式应根据系统的具体需求和约束来决定,综合考虑性能、可靠性、成本和系统复杂性等因素。
基于zookeeper实现分布式锁
常见的分布式锁实现方案里面,除了使用redis来实现之外,使用zookeeper也可以实现分布式锁。
在介绍zookeeper(下文用zk代替)实现分布式锁的机制之前,先粗略介绍一下zk是什么东西:
Zookeeper是一种提供配置管理、分布式协同以及命名的中心化服务。
ZooKeeper 的分布式锁的特点就是:稳定、健壮、可用性强
这得益于 ZooKeeper 这个框架本身的定位就是用来做 分布式协调 的,因此在需要保证可靠性的场景下使用 ZooKeeper 做分布式锁是比较好的。
zk的模型是这样的:zk包含一系列的节点,叫做znode,就好像文件系统一样每个znode表示一个目录,然后znode有一些特性:
- 有序节点:假如当前有一个父节点为/lock,我们可以在这个父节点下面创建子节点;
- zookeeper提供了一个可选的有序特性,例如我们可以创建子节点“/lock/node-”并且指明有序,那么zookeeper在生成子节点时会根据当前的子节点数量自动添加整数序号
- 也就是说,如果是第一个创建的子节点,那么生成的子节点为/lock/node-0000000000,下一个节点则为/lock/node-0000000001,依次类推。
- 临时节点:客户端可以建立一个临时节点,在会话结束或者会话超时后,zookeeper会自动删除该节点。
- 事件监听:在读取数据时,我们可以同时对节点设置事件监听,当节点数据或结构变化时,zookeeper会通知客户端。当前zookeeper有如下四种事件:
- 节点创建
- 节点删除
- 节点数据修改
- 子节点变更
基于以上的一些zk的特性,我们很容易得出使用zk实现分布式锁的落地方案:
- 使用zk的临时节点和有序节点,每个线程获取锁就是在zk创建一个临时有序的节点,比如在/lock/目录下。
- 创建节点成功后,获取/lock目录下的所有临时节点,再判断当前线程创建的节点是否是所有的节点的序号最小的节点
- 如果当前线程创建的节点是所有节点序号最小的节点,则认为获取锁成功。
- 如果当前线程创建的节点不是所有节点序号最小的节点,则对节点序号的前一个节点添加一个事件监听。
- 比如当前线程获取到的节点序号为/lock/003,然后所有的节点列表为[/lock/001,/lock/002,/lock/003],则对/lock/002这个节点添加一个事件监听器。
如果锁释放了,会唤醒下一个序号的节点,然后重新执行第3步,判断是否自己的节点序号是最小。
比如/lock/001释放了,/lock/002监听到时间,此时节点集合为[/lock/002,/lock/003],则/lock/002为最小序号节点,获取到锁。
整个过程如下:

具体的实现思路就是这样,至于代码怎么写,这里比较复杂就不贴出来了。
Curator介绍
Curator是一个zookeeper的开源客户端,也提供了分布式锁的实现。
他的使用方式也比较简单:
InterProcessMutex interProcessMutex = new InterProcessMutex(client,"/anyLock");
interProcessMutex.acquire();
interProcessMutex.release();其实现分布式锁的核心源码如下:
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
{
boolean haveTheLock = false;
boolean doDelete = false;
try {
if ( revocable.get() != null ) {
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ) {
// 获取当前所有节点排序后的集合
List<String> children = getSortedChildren();
// 获取当前节点的名称
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
// 判断当前节点是否是最小的节点
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() ) {
// 获取到锁
haveTheLock = true;
} else {
// 没获取到锁,对当前节点的上一个节点注册一个监听器
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this){
Stat stat = client.checkExists().usingWatcher(watcher).forPath(previousSequencePath);
if ( stat != null ){
if ( millisToWait != null ){
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 ){
doDelete = true; // timed out - delete our node
break;
}
wait(millisToWait);
}else{
wait();
}
}
}
// else it may have been deleted (i.e. lock released). Try to acquire again
}
}
}
catch ( Exception e ) {
doDelete = true;
throw e;
} finally{
if ( doDelete ){
deleteOurPath(ourPath);
}
}
return haveTheLock;
}其实curator实现分布式锁的底层原理和上面分析的是差不多的。这里我们用一张图详细描述其原理:

学完了两种分布式锁的实现方案之后,本节需要讨论的是redis和zk的实现方案中各自的优缺点。
对于redis的分布式锁而言,它有以下缺点:
- 它获取锁的方式简单粗暴,获取不到锁直接不断尝试获取锁,比较消耗性能。
- 另外来说的话,redis的设计定位决定了它的数据并不是强一致性的,在某些极端情况下,可能会出现问题。锁的模型不够健壮
- 即便使用redlock算法来实现,在某些复杂场景下,也无法保证其实现100%没有问题,关于redlock的讨论可以看How to do distributed locking
- redis分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能。
但是另一方面使用redis实现分布式锁在很多企业中非常常见,而且大部分情况下都不会遇到所谓的“极端复杂场景”
所以使用redis作为分布式锁也不失为一种好的方案,最重要的一点是redis的性能很高,可以支撑高并发的获取、释放锁操作。
ZooKeeper 的分布式锁是 基于临时节点 来做的,多个客户端去创建临时同一个节点,第一个创建客户端抢锁成功,释放锁时只需要删除临时节点即可
因此 ZooKeeper 的分布式锁适用于 对可靠性要求较高 的业务场景,这里是相对于 Redis 分布式锁来说相对 更见健壮 一些
并且 ZooKeeper 的分布式锁在 极端情况下也会存在不安全的问题 ,也不能保证绝对的可靠性:
如果加锁的客户端长时间 GC 导致无法与 ZooKeeper 维持心跳,那么 ZK 就会认为这个客户端已经挂了,于是将该客户端创建的临时节点删除,那么当这个客户端 GC 完成之后还以为自己持有锁,但是它的锁其实已经没有了,因此也会存在不安全的问题
- 真实项目实际使用建议
这里最后再说一下真实项目中使用如何进行选型,其实两种锁使用哪一个都可以,主要看公司技术栈如何以及架构师对两种锁的看法:
具体选用哪一种分布式锁的话,可以根据需要使用的功能和已经引入的技术栈来进行选择,比如恰好已经引入了 ZK 依赖,就可以使用 ZK 的分布式锁
其实这两种锁在真正的项目中使用的都是比较多的
而且要注意的是无论是使用 Redis 分布式锁还是 ZK 分布式锁其实在极端情况下都会出现问题,都不可以保证 100% 的安全性,不过 ZK 锁在健壮性上还是强于 Redis 锁的
可以通过分布式锁在上层互斥掉大量的请求,如果真有个别请求出现锁失效,可以在底层资源层做一些互斥保护,作为一个兜底
因此如果是对可靠性要求非常高的应用,不可以把线程安全的问题全部寄托于分布式锁,而是要在资源层也做一些保护,来保证数据真正的安全
对于zk分布式锁而言:
- zookeeper天生设计定位就是分布式协调,强一致性。锁的模型健壮、简单易用、适合做分布式锁。
- 如果获取不到锁,只需要添加一个监听器就可以了,不用一直轮询,性能消耗较小。
- 但是zk也有其缺点:如果有较多的客户端频繁的申请加锁、释放锁,对于zk集群的压力会比较大。
综上所述,redis和zookeeper都有其优缺点。我们在做技术选型的时候可以根据这些问题作为参考因素。
选择建议
通过前面的分析,实现分布式锁的两种常见方案:redis和zookeeper,他们各有千秋。应该如何选型呢?
就个人而言的话,我比较推崇zk实现的锁:
因为redis是有可能存在隐患的,可能会导致数据不对的情况。但是,怎么选用要看具体在公司的场景了。
如果公司里面有zk集群条件,优先选用zk实现,但是如果说公司里面只有redis集群,没有条件搭建zk集群。
那么其实用redis来实现也可以,另外还可能是系统设计者考虑到了系统已经有redis,但是又不希望再次引入一些外部依赖的情况下,可以选用redis。
分布式锁的问题与挑战
尽管分布式锁提供了一种有效的并发控制机制,但它们也面临一些问题和挑战:
1 死锁
在分布式系统中,由于网络延迟、故障等原因,可能会导致死锁情况。解决死锁问题需要使用超时机制和心跳机制。
2 性能
分布式锁的性能通常比单机锁低,因为涉及到网络通信和共享存储访问。因此,在设计时需要权衡性能和一致性需求。
3 安全性
分布式锁需要考虑安全性问题,防止恶意客户端的攻击。通常会使用加密和认证机制来保护锁。
4 锁丢失和红锁
集群环境下,分布式锁丢失和不唯一下。
一、主从redis架构中分布式锁存在的问题
1、线程A从主redis中请求一个分布式锁,获取锁成功;
2、从redis准备从主redis同步锁相关信息时,主redis突然发生宕机,锁丢失了;
3、触发从redis升级为新的主redis;
4、线程B从继任主redis的从redis上申请一个分布式锁,此时也能获取锁成功;
5、导致,同一个分布式锁,被两个客户端同时获取,没有保证独占使用特性;
为了解决这个问题,redis引入了红锁的概念。
二、红锁算法原理
需要准备多台redis实例,这些redis实例指的是完全互相独立的Redis节点,这些节点之间既没有主从,也没有集群关系。客户端申请分布式锁的时候,需要向所有的redis实例发出申请,只有超过半数的redis实例报告获取锁成功,才能算真正获取到锁。
具体的红锁算法主要包括如下步骤:
1、应用程序获取当前系统时间(单位是毫秒);
2、应用程序使用相同的key、value依次尝试从所有的redis实例申请分布式锁,这里获取锁的尝试时间要远远小于锁的超时时间,防止某个master Down了,我们还在不断的获取锁,而被阻塞过长的时间;
3、只有超过半数的redis实例反馈获取锁成功,并且获取锁的总耗时小于锁的超时时间,才认为锁获取成功;
4、如果锁获取成功了,锁的超时时间就是最初的锁超时时间减去获取锁的总耗时时间;
5、如果锁获取失败了,不管是因为获取成功的redis节点没有过半,还是因为获取锁的总耗时超过了锁的超时时间,都会向已经获取锁成功的redis实例发出删除对应key的请求,去释放锁;
三、RedLock算法问题(集群持久化问题和时钟问题)
1、持久化问题
假设一共有5个Redis节点:A, B, C, D, E:
客户端1成功锁住了A, B, C,获取锁成功,但D和E没有锁住。
节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
节点C重启后,客户端2锁住了C, D, E,获取锁成功。
这样,客户端1和客户端2同时获得了锁(针对同一资源)。
2、客户端长时间阻塞,导致获得的锁释放,访问的共享资源不受保护的问题。
3、Redlock算法对时钟依赖性太强, 若某个节点中发生时间跳跃(系统时间戳不正确),也可能会引此而引发锁安全性问题。
四、红锁总结
红锁其实也并不能解决根本问题,只是降低问题发生的概率。完全相互独立的redis,每一台至少也要保证高可用,还是会有主从节点。既然有主从节点,在持续的高并发下,master还是可能会宕机,从节点可能还没来得及同步锁的数据。很有可能多个主节点也发生这样的情况,那么问题还是回到一开始的问题,红锁只是降低了发生的概率。
其实,在实际场景中,红锁是很少使用的。这是因为使用了红锁后会影响高并发环境下的性能,使得程序的体验更差。所以,在实际场景中,我们一般都是要保证Redis集群的可靠性。同时,使用红锁后,当加锁成功的RLock个数不超过总数的一半时,会返回加锁失败,即使在业务层面任务加锁成功了,但是红锁也会返回加锁失败的结果。另外,使用红锁时,需要提供多套Redis的主从部署架构,同时,这多套Redis主从架构中的Master节点必须都是独立的,相互之间没有任何数据交互。
Distributed Locks with Redis | Docs




简单的说:红锁本来是为了解决问题,然而事与愿违,这个并没有解决问题。
Redlock算法设计理念
redis之父提出了Redlock算法解决这个问题
Redis也提供了Redlock算法,用来实现基于多个实例的分布式锁。
锁变量由多个实例维护,即使有实例发生了故障,锁变量仍然是存在的,客户端还是可以完成锁操作。
Redlock算法是实现高可靠分布式锁的一种有效解决方案,可以在实际开发中使用。


分布式锁的最佳实践
1 避免锁滥用
分布式锁是一种有限资源,滥用锁可能导致性能问题。因此,在设计时要避免不必要的锁。
2 超时机制
分布式锁应该支持超时机制,以避免死锁。客户端在获取锁时可以设置一个最大等待时间,在超时后放弃获取锁。
3 心跳机制
为了避免死锁,可以引入心跳机制,即锁的持有者定期发送心跳消息,如果其他客户端长时间没有收到心跳,可以释放锁。
4 安全性
分布式锁需要考虑安全性问题,防止恶意客户端的攻击。可以使用加密和认证机制来保护锁。
5 优化性能
分布式锁的性能通常比单机锁低,因为涉及到网络通信和共享存储访问。可以通过优化算法和减少锁的粒度来提高性能。
分布式锁的应用场景
分布式锁在各种应用场景中发挥着重要作用,以下是一些常见的应用场景:
- 分布式数据库事务:在分布式数据库中,多个事务可能同时操作相同的数据。使用分布式锁可以确保只有一个事务能够修改数据,从而维护数据的一致性。
- 分布式任务调度:分布式任务调度系统通常需要协调多个调度节点,以避免重复执行任务。分布式锁可以用来确保每个任务只会被执行一次。
- 缓存更新:在分布式缓存系统中,缓存的更新可能导致缓存雪崩或缓存穿透问题。分布式锁可以用来控制缓存的更新操作,避免并发更新。
- 幂等操作:幂等操作是指无论执行多少次,结果都相同的操作。分布式锁可以用来确保幂等操作的执行,从而保证系统的可靠性。
分布式锁使用场景分析
- 对同一资源的争夺,如秒杀商品,商品减少过程;
- 特点:与用户无关,与数据本身有关;
- 数据有唯一性要求,数据库中同一类型数据(绑定关系、认证等)只能存在一条,因查询和存储是两步操作,不支持原子性,在没有唯一索引情况下两个线程争抢可能都请求成功;
- 特点:可能和用户有关,如同一用户只能收藏一个任务,也可能与用户无关,如渠道商认证统一信用代码必须唯一,加锁的范围判断是否关联用户
- 同一功能有多个入口,如认证操作(新增认证信息,绑定用户两步操作),在PC和小程序有两端操作,可能在同时操作时导致重复数据入库;
- 用户手残重复请求,接口内部可能有唯一性校验,也可能需求本身可以不唯一,但是用户只是想请求一次,不小心点击了两次,则同样的数据进来两次;
- 接口需顺序访问,接口本身没有唯一要求,可以重复请求,但因对服务资源占用过大,过多请求会导致服务崩溃,同一时间只能处理一个请求,接口需阻塞进行。
Springboot整合Redisson

分布式对象: Redisson提供了诸如分布式集合(Set、List、Queue等)和分布式映射(Map)等数据结构,这些数据结构都能够在多个JVM和多个机器上进行协同操作,简化了分布式系统中数据的管理和同步。
分布式锁: Redisson实现了基于Redis的分布式锁,支持公平锁和非公平锁,能够在分布式环境下保证资源的互斥访问。
消息发布/订阅: Redisson支持基于Redis的发布/订阅模式,可以方便地进行消息的发布和订阅,实现解耦和异步通信。
异步执行: Redisson提供了异步API,支持异步执行操作,提升了系统的并发能力和响应速度。
Spring集成: Redisson提供了与Spring Framework的集成支持,可以方便地在Spring项目中使用Redisson来处理分布式数据。
1.引入maven依赖
<!-- 原生 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
<!-- 或者 另一种Spring集成starter -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.13.6</version>
</dependency>如果是通过starter引入,redisson-spring-boot-starter和springboot之间有对应关系,版本对不上启动会失败。
org.springframework.web.util.NestedServletException: Handler dispatch failed; nested exception is
java.lang.NoClassDefFoundError: Could not initialize class org.redisson.spring.data.connection.RedissonClusterConnection
我们用的 spring-boot 2.x.y 只能用 redisson-spring-data-2x,否则会出现版本不兼容问题。
redisson/redisson-spring-boot-starter/README.md at master · redisson/redisson · GitHub

1.配置文件的参数名不一样

2.自动装载类不一样


2.redis连接配置:单点和集群
package com.zxx.study.web.config;
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.codec.JsonJacksonCodec;
import org.redisson.config.Config;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author zhouxx
* @create 2024-07-19 2:44
*/
@Configuration
//@ConfigurationProperties(prefix = "spring.redis")
public class RedissionConfig {
@Value("${spring.redis.host}")
private String redisHost;
// @Value("${spring.redis.password}")
// private String password;
@Value("${spring.redis.port}")
private int port;
// 单点
@Bean
public RedissonClient getRedisson() {
Config config = new Config();
config.useSingleServer().
setAddress("redis://" + redisHost + ":" + port);
config.setCodec(new JsonJacksonCodec());
return Redisson.create(config);
//主从
// Config config = new Config();
// config.useMasterSlaveServers()
// .setMasterAddress("redis://127.0.0.1:6379").setPassword("123456")
// .addSlaveAddress("redis://127.0.0.1:6389")
// .addSlaveAddress("redis://127.0.0.1:6399");
// return Redisson.create(config);
//哨兵
// Config config = new Config();
// config.useSentinelServers()
// .setMasterName("myMaster")
// .addSentinelAddress("redis://127.0.0.1:6379", "redis://127.0.0.1:6389")
// .addSentinelAddress("redis://127.0.0.1:6399");
// return Redisson.create(config);
//集群
// Config config = new Config();
// config.useClusterServers()
// //cluster state scan interval in milliseconds
// .setScanInterval(2000)
// .addNodeAddress("redis://127.0.0.1:6379", "redis://127.0.0.1:6389")
// .addNodeAddress("redis://127.0.0.1:6399");
// return Redisson.create(config);
}
}Redisson锁


1.Rlock锁
RLock是Redisson分布式锁的最核心接口,继承了concurrent包的Lock接口和自己的RLockAsync接口,RLockAsync的返回值都是RFuture,是Redisson执行异步实现的核心逻辑,也是Netty发挥的主要阵地。
Redisson实现RLock锁底层原理

只要线程一加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程一还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了锁过期释放,业务没执行完问题。
加锁和解锁
从RLock进入,找到RedissonLock类,找到 tryLock 方法再递进到干活的tryAcquireOnceAsync 方法,有过期时间tryLockInnerAsync 部分,evalWriteAsync是eval命令执行lua的入口

Lua脚本
-- 不存在该key时
if (redis.call('exists', KEYS[1]) == 0) then
-- 新增该锁并且hash中该线程id对应的count置1
redis.call('hincrby', KEYS[1], ARGV[2], 1);
-- 设置过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
-- 存在该key 并且 hash中线程id的key也存在
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
-- 线程重入次数++
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);redisson具体参数分析
// keyName
KEYS[1] = Collections.singletonList(this.getName())
// leaseTime
ARGV[1] = this.internalLockLeaseTime
// uuid+threadId组合的唯一值
ARGV[2] = this.getLockName(threadId)总共3个参数完成了一段逻辑:
- 判断该锁是否已经有对应
hash表存在, - 没有对应的
hash表:则set该hash表中一个entry的key为锁名称,value为1,之后设置该hash表失效时间为leaseTime - 存在对应的
hash表:则将该lockName的value执行+1操作,也就是计算进入次数,再设置失效时间leaseTime - 最后返回这把锁的ttl剩余时间
也和上述自定义锁没有区别
既然如此,那解锁的步骤也肯定有对应的-1操作,再看unlock方法,同样查找方法名,一路到unlockInnerAsync方法

lua脚本
-- 不存在key
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then
return nil;
end;
-- 计数器 -1
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0) then
-- 过期时间重设
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
-- 删除并发布解锁消息
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
return nil;该Lua KEYS有2个Arrays.asList(getName(),getChannelName())
- name 锁名称
- channelName,用于pubSub发布消息的channel名称
ARGV变量有三个LockPubSub.UNLOCK_MESSAGE, internalLockLeaseTime, getLockName(threadId)
LockPubSub.UNLOCK_MESSAGE,channel发送消息的类别,此处解锁为0internalLockLeaseTime,watchDog配置的超时时间,默认为30slockName这里的lockName指的是uuid和threadId组合的唯一值
步骤如下:
- 如果该锁不存在则返回nil
- 如果该锁存在则将其线程的hash key计数器-1
- 计数器
counter>0,重置下失效时间,返回0;否则,删除该锁,发布解锁消息unlockMessage,返回1;
其中unLock的时候使用到了Redis发布订阅PubSub完成消息通知。
而订阅的步骤就在RedissonLock的加锁入口的lock方法里
long threadId = Thread.currentThread().getId();
Long ttl = this.tryAcquire(-1L, leaseTime, unit, threadId);
if (ttl != null) {
// 订阅
RFuture<RedissonLockEntry> future = this.subscribe(threadId);
if (interruptibly) {
this.commandExecutor.syncSubscriptionInterrupted(future);
} else {
this.commandExecutor.syncSubscription(future);
}
// 省略解锁消息
为了一探究竟通知了什么,通知后又做了什么,进入LockPubSub。
这里只有一个明显的监听方法onMessage,其订阅和信号量的释放都在父类PublishSubscribe,我们只关注监听事件的实际操作
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
发现一个是默认解锁消息 ,一个是读锁解锁消息 ,因为redisson是有提供读写锁的,而读写锁读读情况和读写、写写情况互斥情况不同,我们只看上面的默认解锁消息unlockMessage分支
LockPubSub监听最终执行了2件事
runnableToExecute.run()执行监听回调value.getLatch().release(); 释放信号量
Redisson通过LockPubSub 监听解锁消息,执行监听回调和释放信号量通知等待线程可以重新抢锁。
这时再回来看tryAcquireOnceAsync另一分支
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
可以看到,无超时时间时,在执行加锁操作后,还执行了一段费解的逻辑
| 1 2 3 4 5 6 7 |
|
此处涉及到Netty的Future/Promise-Listener模型,Redisson中几乎全部以这种方式通信(所以说Redisson是基于Netty通信机制实现的),理解这段逻辑可以试着先理解
在 Java 的
Future中,业务逻辑为一个Callable或Runnable实现类,该类的call()或 run()执行完毕意味着业务逻辑的完结,在Promise机制中,可以在业务逻辑中人工设置业务逻辑的成功与失败,这样更加方便的监控自己的业务逻辑。
这块代码的表面意义就是,在执行异步加锁的操作后,加锁成功则根据加锁完成返回的ttl是否过期来确认是否执行一段定时任务。这段定时任务的就是watchDog的核心。
锁续约
查看RedissonLock.this.scheduleExpirationRenewal(threadId)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
拆分来看,这段连续嵌套且冗长的代码实际上做了几步:
- 添加一个
netty的Timeout回调任务,每(internalLockLeaseTime / 3)毫秒执行一次,执行的方法是renewExpirationAsync renewExpirationAsync重置了锁超时时间,又注册一个监听器,监听回调又执行了renewExpiration
renewExpirationAsync 的Lua如下
| 1 2 3 4 5 6 7 8 |
|
重新设置了超时时间。Redisson加这段逻辑的目的是什么?
目的是为了某种场景下保证业务不影响,如任务执行超时但未结束,锁已经释放的问题。
当一个线程持有了一把锁,由于并未设置超时时间leaseTime,Redisson 默认配置了30S,开启watchDog,每10S对该锁进行一次续约,维持30S的超时时间,直到任务完成再删除锁。
这就是Redisson的锁续约 ,也就是WatchDog 实现的基本思路。
1.5.4 流程概括
通过整体的介绍,流程简单概括:
- A、B线程争抢一把锁,A获取到后,B阻塞
- B线程阻塞时并非主动
CAS,而是PubSub方式订阅该锁的广播消息 - A操作完成释放了锁,B线程收到订阅消息通知
- B被唤醒开始继续抢锁,拿到锁
详细加锁解锁流程总结如下图:

2.Redlock红锁
Redisson红锁原理
RedissonRedLock extends RedissonMultiLock,所以实际上,redLock.tryLock实际调用:org.redisson.RedissonMultiLock.java#tryLock(),进而调用到其同类的tryLock(long waitTime, long leaseTime, TimeUnit unit) ,入参为:tryLock(-1, -1, null)
org.redisson.RedissonMultiLock.java#tryLock(long waitTime, long leaseTime, TimeUnit unit)源码如下:
final List<RLock> locks = new ArrayList<>();
/**
* Creates instance with multiple {@link RLock} objects.
* Each RLock object could be created by own Redisson instance.
*
* @param locks - array of locks
*/
public RedissonMultiLock(RLock... locks) {
if (locks.length == 0) {
throw new IllegalArgumentException("Lock objects are not defined");
}
this.locks.addAll(Arrays.asList(locks));
}
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
long newLeaseTime = -1;
if (leaseTime != -1) {
newLeaseTime = unit.toMillis(waitTime)*2;
}
long time = System.currentTimeMillis();
long remainTime = -1;
if (waitTime != -1) {
remainTime = unit.toMillis(waitTime);
}
long lockWaitTime = calcLockWaitTime(remainTime);
/**
* 1. 允许加锁失败节点个数限制(N-(N/2+1))
*/
int failedLocksLimit = failedLocksLimit();
/**
* 2. 遍历所有节点通过EVAL命令执行lua加锁
*/
List<RLock> acquiredLocks = new ArrayList<>(locks.size());
for (ListIterator<RLock> iterator = locks.listIterator(); iterator.hasNext();) {
RLock lock = iterator.next();
boolean lockAcquired;
/**
* 3.对节点尝试加锁
*/
try {
if (waitTime == -1 && leaseTime == -1) {
lockAcquired = lock.tryLock();
} else {
long awaitTime = Math.min(lockWaitTime, remainTime);
lockAcquired = lock.tryLock(awaitTime, newLeaseTime, TimeUnit.MILLISECONDS);
}
} catch (RedisResponseTimeoutException e) {
// 如果抛出这类异常,为了防止加锁成功,但是响应失败,需要解锁所有节点
unlockInner(Arrays.asList(lock));
lockAcquired = false;
} catch (Exception e) {
// 抛出异常表示获取锁失败
lockAcquired = false;
}
if (lockAcquired) {
/**
*4. 如果获取到锁则添加到已获取锁集合中
*/
acquiredLocks.add(lock);
} else {
/**
* 5. 计算已经申请锁失败的节点是否已经到达 允许加锁失败节点个数限制 (N-(N/2+1))
* 如果已经到达, 就认定最终申请锁失败,则没有必要继续从后面的节点申请了
* 因为 Redlock 算法要求至少N/2+1 个节点都加锁成功,才算最终的锁申请成功
*/
if (locks.size() - acquiredLocks.size() == failedLocksLimit()) {
break;
}
if (failedLocksLimit == 0) {
unlockInner(acquiredLocks);
if (waitTime == -1 && leaseTime == -1) {
return false;
}
failedLocksLimit = failedLocksLimit();
acquiredLocks.clear();
// reset iterator
while (iterator.hasPrevious()) {
iterator.previous();
}
} else {
failedLocksLimit--;
}
}
/**
* 6.计算 目前从各个节点获取锁已经消耗的总时间,如果已经等于最大等待时间,则认定最终申请锁失败,返回false
*/
if (remainTime != -1) {
remainTime -= System.currentTimeMillis() - time;
time = System.currentTimeMillis();
if (remainTime <= 0) {
unlockInner(acquiredLocks);
return false;
}
}
}
if (leaseTime != -1) {
List<RFuture<Boolean>> futures = new ArrayList<>(acquiredLocks.size());
for (RLock rLock : acquiredLocks) {
RFuture<Boolean> future = ((RedissonLock) rLock).expireAsync(unit.toMillis(leaseTime), TimeUnit.MILLISECONDS);
futures.add(future);
}
for (RFuture<Boolean> rFuture : futures) {
rFuture.syncUninterruptibly();
}
}
/**
* 7.如果逻辑正常执行完则认为最终申请锁成功,返回true
*/
return true;
}

package com.online.taxi.order.service.impl;
import com.online.taxi.order.constant.RedisKeyConstant;
import com.online.taxi.order.service.GrabService;
import com.online.taxi.order.service.OrderService;
import org.redisson.Redisson;
import org.redisson.RedissonRedLock;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
@Service
public class GrabRedisRedissonRedLockLockServiceImpl implements GrabService {
// 红锁
@Autowired
@Qualifier("redissonRed1")
private RedissonClient redissonRed1;
@Autowired
@Qualifier("redissonRed2")
private RedissonClient redissonRed2;
@Autowired
@Qualifier("redissonRed3")
private RedissonClient redissonRed3;
@Autowired
@Qualifier("redissonRed4")
private RedissonClient redissonRed4;
@Autowired
@Qualifier("redissonRed5")
private RedissonClient redissonRed5;
@Autowired
OrderService orderService;
@Override
public String grabOrder(int orderId , int driverId){
System.out.println("红锁实现类");
//生成key
String lockKey = ("" + orderId).intern();
//redisson锁 单节点
// RLock rLock = redissonRed1.getLock(lockKey);
//红锁 redis son
RLock rLock1 = redissonRed1.getLock(lockKey);
RLock rLock2 = redissonRed2.getLock(lockKey);
RLock rLock3 = redissonRed3.getLock(lockKey);
RLock rLock4 = redissonRed4.getLock(lockKey);
RLock rLock5 = redissonRed5.getLock(lockKey);
RedissonRedLock rLock = new RedissonRedLock(rLock1,rLock2,rLock3,rLock4,rLock5);
try {
/**红锁
* waitTimeout 尝试获取锁的最大等待时间,超过这个值,则认为获取锁失败
* leaseTime 锁的持有时间,超过这个时间锁会自动失效(值应设置为大于业务处理的时间,确保在锁有效期内业务能处理完)
*/
boolean b1 = rLock.tryLock((long)waitTimeout, (long)leaseTime, TimeUnit.SECONDS);
if (b1){
System.out.println("加锁成功");
// 此代码默认 设置key 超时时间30秒,过10秒,再延时
System.out.println("司机:"+driverId+" 执行抢单逻辑");
boolean b = orderService.grab(orderId, driverId);
if(b) {
System.out.println("司机:"+driverId+" 抢单成功");
}else {
System.out.println("司机:"+driverId+" 抢单失败");
}
System.out.println("加锁成功");
}else {
System.out.println("加锁失败");
}
} finally {
rLock.unlock();
}
return null;
}
}
本地redisson实现红锁


3.RedissonFairLock公平锁
以上介绍的可重入锁是非公平锁,Redisson还基于Redis的队列(List)和ZSet实现了公平锁。
公平的定义是什么?
公平就是按照客户端的请求先来后到排队来获取锁,先到先得,也就是FIFO,所以队列和容器顺序编排必不可少
回顾JUC的ReentrantLock公平锁的实现
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
AQS已经提供了整个实现,是否公平取决于实现类取出节点逻辑是否顺序取

AbstractQueuedSynchronizer是用来构建锁或者其他同步组件的基础框架,通过内置FIFO队列来完成资源获取线程的排队工作,自身没有实现同步接口,仅仅定义了若干同步状态获取和释放的方法来供自定义同步组件使用(上图),支持独占和共享获取,这是基于模版方法模式的一种设计,给公平/非公平提供了土壤。
我们用2张图来简单解释AQS的等待流程
一张是同步队列(FIFO双向队列)管理 获取同步状态失败(抢锁失败)的线程引用、等待状态和前驱后继节点的流程图

一张是独占式获取同步状态的总流程 ,核心acquire(int arg)方法调用流程

可以看出锁的获取流程AQS维护一个同步队列,获取状态失败的线程都会加入到队列中进行自旋,移出队列或停止自旋的条件是前驱节点为头节点切成功获取了同步状态。而比较另一段非公平锁类NonfairSync可以发现,控制公平和非公平的关键代码,在于hasQueuedPredecessors方法。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
NonfairSync减少了了hasQueuedPredecessors判断条件,该方法的作用就是
- 查看同步队列中当前节点是否有前驱节点,如果有比当前线程更早请求获取锁则返回true。
- 保证每次都取队列的第一个节点(线程)来获取锁,这就是公平规则
为什么JUC以默认非公平锁呢?
因为当一个线程请求锁时,只要获取来同步状态即成功获取。在此前提下,刚释放的线程再次获取同步状态的几率会非常大,使得其他线程只能在同步队列中等待。但这样带来的好处是,非公平锁大大减少了系统线程上下文的切换开销。
可见公平的代价是性能与吞吐量。
Redis里没有AQS,但是有List和zSet,看看Redisson是怎么实现公平的RLock fairLock = redissonClient.getFairLock(lockName);fairLock.lock();


这里有2段冗长的Lua,但是Debug发现,公平锁的入口在 command == RedisCommands.EVAL_LONG 之后,此段Lua较长,参数也多,我们着重分析Lua的实现规则
参数
| 1 2 3 4 5 6 7 8 9 10 |
|
公平锁实现的Lua脚本
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
|
公平锁加锁步骤
通过以上Lua,可以发现,lua操作的关键结构是列表(list)和有序集合(zSet)。
其中 list 维护了一个等待的线程队列 redisson_lock_queue:{xxx},zSet维护了一个线程超时情况的有序集合 redisson_lock_timeout:{xxx},尽管lua较长,但是可以拆分为6个步骤
- 队列清理
保证队列中只有未过期的等待线程 - 首次加锁
hset加锁,pexpire过期时间 - 重入判断
此处同可重入锁lua - 返回ttl
- 计算尾节点ttl
初始值为锁的剩余过期时间 - 末尾排队
ttl + 2 * currentTime + waitTime是score的默认值计算公式
Redisson信号量
一、RSemaphore的使用
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
二、RSemaphore设置许可数量
初始化RSemaphore,需要调用trySetPermits()设置许可数量:
| 1 2 3 4 |
|
trySetPermits()内部调用了trySetPermitsAsync():
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
可以看到,设置许可数量底层使用LUA脚本,实际上就是使用redis的String数据结构,保存了我们指定的许可数量。如下图:

参数说明:
- KEYS[1]: 我们指定的分布式信号量key,例如redissonClient.getSemaphore("semaphore")中的"semaphore")
- KEYS[2]: 释放锁的channel名称,redisson_sc:{分布式信号量key},在本例中,就是redisson_sc:{semaphore}
- ARGV[1]: 设置的许可数量
总结设置许可执行流程为:
- get semaphore,获取到semaphore信号量的当前的值
- 第一次数据为0, 然后使用set semaphore 3,将这个信号量同时能够允许获取锁的客户端的数量设置为3。(注意到,如果之前设置过了信号量,将无法再次设置,直接返回0。想要更改信号量总数可以使用addPermits方法)
- 然后redis发布一些消息,返回1
三、RSemaphore的加锁流程
许可数量设置好之后,我们就可以调用acquire()方法获取了,如果未传入许可数量,默认获取一个许可。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
可以看到,获取许可的核心逻辑在tryAcquire()方法中,如果tryAcquire()返回true说明获取许可成功,直接返回;如果返回false,说明当前没有许可可以使用,则对于没有获取锁的那些线程,订阅redisson_sc:{分布式信号量key}通道的消息,并通过死循环不断尝试获取锁。
我们看一下tryAcquire()方法的逻辑,内部调用了tryAcquireAsync()方法:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
从源码可以看到,获取许可就是操作redis中的数据,首先获取到redis中剩余的许可数量,只有当剩余的许可数量大于线程申请的许可数量时,才获取成功,返回1;否则获取失败,返回0;
总结加锁执行流程为:
- get semaphore,获取到一个当前的值,比如说是3,3 > 1
- decrby semaphore 1,将信号量允许获取锁的客户端的数量递减1,变成2
- decrby semaphore 1
- decrby semaphore 1
- 执行3次加锁后,semaphore值为0
- 此时如果再来进行加锁则直接返回0,然后进入死循环去获取锁
四、RSemaphore的解锁流程
通过前面对RSemaphore获取锁的分析,我们很容易能猜到,释放锁,无非就是归还许可数量到redis中。我们查看具体的源码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
Redisson阻塞队列
一、案例场景
定时调度基本是每个项目都会遇到的业务场景,一般地,都会通过任务调度工具执行定时任务完成,定时任务有两点缺陷:
- 定时任务执行频度限制,实际执行的时间可能会晚于理想的设定时间,例如,如果要通过定时任务实现在下单后15分钟仍未支付则取消订单的功能,假设定时任务的执行频度为每分钟执行一次,对于有些订单而言,其实际取消时间是介于15-16分钟之间,不够精确;
- 定时任务执行需要时间,定时任务的执行也需要时间,如果业务场景的数据量较大,执行一次定时任务需要足够长的时间,进一步放大了缺点一。
二、技术选型
Redis实现延时队列有两种实现方式:
- key失效监听回调;
key失效监听存在两个问题:① Redis的pubsub不会被持久化,服务器宕机就会被丢弃,这点就很致命,因为谁也无法保证redis服务一直不宕机;②没有高级特性,没有ack机制,可靠性不高。 - zset分数存时间戳。
zset的实现是,轮询队列头部来获取超期的时间戳,实现延时效果,可靠性更高,并且数据会被持久化,这就很好的规避了key失效监听回调的问题,如果redis服务崩溃,还是有丢失数据的可能。
Redisson的RDelayedQueue是一个封装好的zset实现的延时队列,最终选择了这个方案。其实还有一些优秀的方案可供选择,例如rocketmq、pulsar等拥有定时投递功能的消息队列;我这边优先考虑在不引入新的中间键的情况下使用RDelayedQueue技术进行实现。
注意:在不方便获得专业消息队列时可以考虑使用redissondelayqueue等基于redis的延时队列方案,但要为redis崩溃等情况设计补偿保护机制。
三、原理
用户传进来的延迟时间必须大于0,小于0抛出异常代码结束。将用户传进来的时间转换为毫秒,并加上系统当前时间,计算出来的就是过期时间。到了过期时间消费者就可以把该任务取出来消费了。
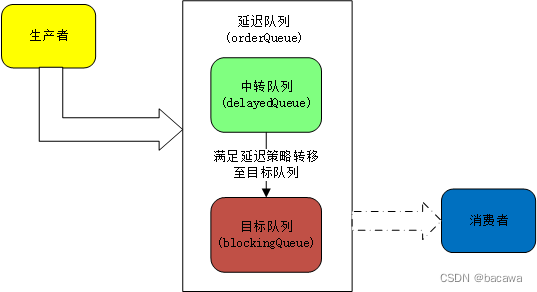
结合上图所示,首先创建了一个Redisson实现的阻塞队列RBlockingQueue的实例blockingQueue,然后又使用该阻塞队列blockingQueue创建了一个延时队列RDelayedQueue的实例delayedQueue。延时消息添加后并不是立即进入到阻塞队列blockingQueue中,而是到达了设定的延时时间之后才会从延时队列delayedQueue进入到阻塞队列blockingQueue;因此,延时消息的添加由延时队列delayedQueue完成,而延时队列的消费则由阻塞队列blockingQueue完成。注意,这里如果直接对延时队列delayedQueue进行监听,则延时消息刚加入时就会被消费,达不到延时的效果。
相比于Redisson官网文档延时队列中给出的代码示例,这里被包装队列使用阻塞队列RBlockingQueue的好处是blockingQueue.take()会一直阻塞直至队列内有可消费延时消息,避免无意义的循环占用CPU。
四、编码实现
创建配置类
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
其中RedisUtils.getClient()是为了获取RedissonClient 对象,这里我使用Redis工具类直接获取,我把工具类也简单展示出来吧。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
3、持续监听线程
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
4、编写controller进行测试调用
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
Redisson限流器
redis redisson 限流器实例
作用:限制一段时间内对数据的访问数量
相关接口
RRateLimiter
| 1 2 3 4 5 6 7 8 9 10 11 |
|
RateType:速度类型
| 1 2 3 4 5 6 7 |
|
RateInternalUnit:速度单位
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
示例
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
控制台输出
线程49进入数据区:1574672546522
线程55进入数据区:1574672546522
线程56进入数据区:1574672546526
线程50进入数据区:1574672546523
线程48进入数据区:1574672546523
线程51进入数据区:1574672666627
线程53进入数据区:1574672666627
线程54进入数据区:1574672666627
线程57进入数据区:1574672666628
线程52进入数据区:1574672666628
说明:两分钟之内最多只有5个线程在执行
分布式限流redission RRateLimiter使用及原理
前提:
最近公司在做有需求在做分布式限流,调研的限流框架大概有
- 1、spring cloud gateway集成redis限流,但属于网关层限流
- 2、阿里Sentinel,功能强大、带监控平台
- 3、srping cloud hystrix,属于接口层限流,提供线程池与信号量两种方式
- 4、其他:redission、手撸代码
实际需求情况属于业务端限流,redission更加方便,使用更加灵活,下面介绍下redission分布式限流如何使用及原理:
一、使用
使用很简单、如下
| 1 2 3 4 5 6 7 8 |
|
二、原理
1、getRateLimiter
| 1 2 |
|
2、trySetRate
trySetRate方法跟进去底层实现如下:
| 1 2 3 4 5 6 7 8 |
|
举个例子,更容易理解:
比如下面这段代码,5秒中产生3个令牌,并且所有实例共享(RateType.OVERALL所有实例共享、RateType.CLIENT单实例端共享)
| 1 |
|
那么redis中就会设置3个参数:
hsetnx,key,rate,3
hsetnx,key,interval,5
hsetnx,key,type,0
接着看tryAcquire(1)方法:底层源码如下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
第1、2、3备注行是获取上一步set的3个值:rate、interval、type,如果这3个值没有设置,直接返回rateLimiter没有被初始化。
第5备注行声明一个变量叫valueName 值为KEYS[2],KEYS[2]对应的值是getValueName()方法,getValueName()返回的就是上面第一步getRateLimiter我们设置的key;如果type=1,表示全局共享,那么valueName 的值改为取KEYS[3],KEYS[3]对应的值为getClientValueName(),查看getClientValueName()源码:
| 1 2 3 |
|
ConnectionManager().getId()如下:
| 1 2 3 4 |
|
这个getId()是每个客户端初始化的时候生成的UUID,即每个客户端的getId是唯一的,这也就验证了trySetRate方法中RateType.ALL与RateType.PER_CLIENT的作用。
- 接着看第7标准行,获取valueName对应的值currentValue;首次获取肯定为空,那么看第10标准行else的逻辑
- set valueName 3 px 5,设置key=valueName value=3 过期时间为5秒
- decrby valueName 1,将上面valueName的值减1
- 那么如果第二次访问,第7标注行返回的值存在,将会走第8标注行,紧接着走如下判断
- 如果当前valueName的值也就是3,小于要获得的令牌数量(tryAcquire方法中的入参),那么说明当前时间内(key的有效期5秒内),令牌的数量已经被用完,返回pttl(key的剩余过期时间);反之说明桶中有足够的令牌,获取之后将会把桶中的令牌数量减1,至此结束。
redission分布式限流器总结:
redission分布式限流采用令牌桶思想和固定时间窗口,trySetRate方法设置桶的大小,利用redis key过期机制达到时间窗口目的,控制固定时间窗口内允许通过的请求量。
Redisson操作
直接贴代码
package com.zxx.study.web.util;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.redisson.RedissonRedLock;
import org.redisson.api.*;
import org.redisson.client.protocol.ScoredEntry;
import java.util.*;
import java.util.concurrent.TimeUnit;
/**
* @author zhouxx
* @create 2024-07-17 12:45
*/
@Slf4j
public class RedissonUtil {
private RedissonUtil() {
}
private static final RedissonClient REDISSON_CLIENT = SpringUtils.getBean(RedissonClient.class);
/**
* 默认锁 10分钟
*/
private static final Long DEFAULT_LOCK_TIME_SECONDS = new Long(600L);
/**
* 一致等待直到获取锁并执行
*
* @param lockKey
* @param runnable
*/
@SneakyThrows
public static void lock(String lockKey, Runnable runnable) {
lock(lockKey, DEFAULT_LOCK_TIME_SECONDS, runnable);
}
/**
* 如果在指定时间内获取锁失败则什么也不做
*
* @param lockKey
* @param waitTimeSeconds
* @param onAcquire
*/
@SneakyThrows
public static void lock(String lockKey, long waitTimeSeconds, Runnable onAcquire) {
lock(lockKey, onAcquire, null, waitTimeSeconds, TimeUnit.SECONDS);
}
/**
* 如果在指定时间内获取锁失败则执行onAcquireFail
* 如果获取锁成功则执行onAcquire
*
* @param lockKey
* @param waitTimeSeconds
* @param onAcquire
* @param onAcquireFail
*/
@SneakyThrows
public static void lock(String lockKey
, long waitTimeSeconds
, Runnable onAcquire
, Runnable onAcquireFail) {
lock(lockKey, onAcquire, onAcquireFail, waitTimeSeconds, TimeUnit.SECONDS);
}
@SneakyThrows
public static void lock(String lockKey
, Runnable runnable
, Runnable onAcquireFail
, long waitTime, TimeUnit timeUnit) {
RLock lock = null;
try {
lock = REDISSON_CLIENT.getLock(lockKey);
if (lock.tryLock(waitTime, timeUnit)) {
log.debug("获取锁成功,key:{}", lockKey);
runnable.run();
} else if (onAcquireFail != null) {
onAcquireFail.run();
} else {
log.warn("获取锁失败,key:{}", lockKey);
}
} finally {
if (lock != null) {
if (lock.isHeldByCurrentThread()) {
log.debug("开始释放锁,key:{}", lockKey);
lock.unlock();
log.debug("释放锁完成,key:{}", lockKey);
} else {
log.warn("开始强制释放锁,key:{},name:{}", lockKey, lock.getName());
lock.forceUnlock();
log.warn("强制释放锁完成,key:{}", lockKey);
}
}
}
}
/**
* 默认锁 10分钟
*/
private static final Long DEFAULT_REDLOCK_TIME_SECONDS = new Long(600L);
/**
* 一致等待直到获取锁并执行
*
* @param lockKey
* @param runnable
*/
@SneakyThrows
public static void redLock(String lockKey, Runnable runnable) {
redLock(lockKey, DEFAULT_REDLOCK_TIME_SECONDS, runnable);
}
/**
* 如果在指定时间内获取锁失败则什么也不做
*
* @param lockKey
* @param waitTimeSeconds
* @param onAcquire
*/
@SneakyThrows
public static void redLock(String lockKey, long waitTimeSeconds, Runnable onAcquire) {
redLock(lockKey, onAcquire, null, waitTimeSeconds, TimeUnit.SECONDS);
}
/**
* 如果在指定时间内获取锁失败则执行onAcquireFail
* 如果获取锁成功则执行onAcquire
*
* @param lockKey
* @param waitTimeSeconds
* @param onAcquire
* @param onAcquireFail
*/
@SneakyThrows
public static void redLock(String lockKey
, long waitTimeSeconds
, Runnable onAcquire
, Runnable onAcquireFail) {
redLock(lockKey, onAcquire, onAcquireFail, waitTimeSeconds, TimeUnit.SECONDS);
}
@SneakyThrows
public static void redLock(String lockKey
, Runnable runnable
, Runnable onAcquireFail
, long waitTime, TimeUnit timeUnit) {
RLock lock1 = REDISSON_CLIENT.getLock(lockKey + "1");
RLock lock2 = REDISSON_CLIENT.getLock(lockKey + "2");
RLock lock3 = REDISSON_CLIENT.getLock(lockKey + "3");
RedissonRedLock redLock = null;
try {
redLock = new RedissonRedLock(lock1, lock2, lock3);
if (redLock.tryLock(waitTime, timeUnit)) {
log.debug("获取锁成功,key:{}", lockKey);
runnable.run();
} else if (onAcquireFail != null) {
onAcquireFail.run();
} else {
log.warn("获取锁失败,key:{}", lockKey);
}
} finally {
if (redLock != null) {
if (redLock.isHeldByCurrentThread()) {
log.debug("开始释放锁,key:{}", lockKey);
redLock.unlock();
log.debug("释放锁完成,key:{}", lockKey);
} else {
log.warn("开始强制释放锁,key:{},name:{}", lockKey, redLock.getName());
redLock.forceUnlock();
log.warn("强制释放锁完成,key:{}", lockKey);
}
}
}
}
/**
* 默认锁 10分钟
*/
private static final Long DEFAULT_FAIRLOCK_TIME_SECONDS = new Long(600L);
/**
* 一致等待直到获取锁并执行
*
* @param lockKey
* @param runnable
*/
@SneakyThrows
public static void fairLock(String lockKey, Runnable runnable) {
fairLock(lockKey, DEFAULT_FAIRLOCK_TIME_SECONDS, runnable);
}
/**
* 如果在指定时间内获取锁失败则什么也不做
*
* @param lockKey
* @param waitTimeSeconds
* @param onAcquire
*/
@SneakyThrows
public static void fairLock(String lockKey, long waitTimeSeconds, Runnable onAcquire) {
fairLock(lockKey, onAcquire, null, waitTimeSeconds, TimeUnit.SECONDS);
}
/**
* 如果在指定时间内获取锁失败则执行onAcquireFail
* 如果获取锁成功则执行onAcquire
*
* @param lockKey
* @param waitTimeSeconds
* @param onAcquire
* @param onAcquireFail
*/
@SneakyThrows
public static void fairLock(String lockKey
, long waitTimeSeconds
, Runnable onAcquire
, Runnable onAcquireFail) {
fairLock(lockKey, onAcquire, onAcquireFail, waitTimeSeconds, TimeUnit.SECONDS);
}
@SneakyThrows
public static void fairLock(String lockKey
, Runnable runnable
, Runnable onAcquireFail
, long waitTime, TimeUnit timeUnit) {
RLock lock = REDISSON_CLIENT.getFairLock(lockKey );
try {
if (lock.tryLock(waitTime, timeUnit)) {
log.debug("获取锁成功,key:{}", lockKey);
runnable.run();
} else if (onAcquireFail != null) {
onAcquireFail.run();
} else {
log.warn("获取锁失败,key:{}", lockKey);
}
} finally {
if (lock != null) {
if (lock.isHeldByCurrentThread()) {
log.debug("开始释放锁,key:{}", lockKey);
lock.unlock();
log.debug("释放锁完成,key:{}", lockKey);
} else {
log.warn("开始强制释放锁,key:{},name:{}", lockKey, lock.getName());
lock.forceUnlock();
log.warn("强制释放锁完成,key:{}", lockKey);
}
}
}
}
// 对String类型的操作
public void setString(String key, String value) {
RBucket<String> bucket = REDISSON_CLIENT.getBucket(key);
bucket.set(value);
}
public String getString(String key) {
RBucket<String> bucket = REDISSON_CLIENT.getBucket(key);
return bucket.get();
}
// 对Integer类型的操作
public void setInteger(String key, Integer value) {
RBucket<Integer> bucket = REDISSON_CLIENT.getBucket(key);
bucket.set(value);
}
public Integer getInteger(String key) {
RBucket<Integer> bucket = REDISSON_CLIENT.getBucket(key);
return bucket.get();
}
// 对Long类型的操作
public void setLong(String key, Long value) {
RBucket<Long> bucket = REDISSON_CLIENT.getBucket(key);
bucket.set(value);
}
public Long getLong(String key) {
RBucket<Long> bucket = REDISSON_CLIENT.getBucket(key);
return bucket.get();
}
// 对List类型的操作
public void setList(String key, Object... values) {
RList<Object> list = REDISSON_CLIENT.getList(key);
list.addAll(Arrays.asList(values));
}
public Object getList(String key) {
RList<Object> list = REDISSON_CLIENT.getList(key);
return list.readAll();
}
// 对Set类型的操作
public void setSet(String key, Object... values) {
RSet<Object> set = REDISSON_CLIENT.getSet(key);
set.addAll(Arrays.asList(values));
}
public Object getSet(String key) {
RSet<Object> set = REDISSON_CLIENT.getSet(key);
return set.readAll();
}
// 对Map类型的操作
public void setMap(String key, String mapKey, Object value) {
RMap<String, Object> map = REDISSON_CLIENT.getMap(key);
map.put(mapKey, value);
}
public Object getMap(String key, String mapKey) {
RMap<String, Object> map = REDISSON_CLIENT.getMap(key);
return map.get(mapKey);
}
// 对Queue类型的操作
public void setQueue(String key, Object... values) {
RQueue<Object> queue = REDISSON_CLIENT.getQueue(key);
queue.addAll(Arrays.asList(values));
}
public Object getQueue(String key) {
RQueue<Object> queue = REDISSON_CLIENT.getQueue(key);
return queue.poll(queue.size());
}
/**
* 默认Zset key
*/
public static final String DEFAULT_SCORE_KEY = "ZSKey";
/**
* 默认保存时间
*/
private static final long DEFAULT_EXPIRE_TIME_SECONDS = 3600L;
/**
* 新增ZSet元素,存在则刷新
*
* @param refreshExpire 过期时间,不为null则重新赋值
*/
public <T> void zscoreAddAsync(String key, double score, T member, Long refreshExpire) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
if (null != refreshExpire) {
if (refreshExpire <= 0) {
refreshExpire = DEFAULT_EXPIRE_TIME_SECONDS;
}
scoredSortedSet.expire(refreshExpire, TimeUnit.SECONDS);
}
scoredSortedSet.addAsync(score, member);
}
/**
* 批量新增
*/
public <T> void zScoreAddAsyncBatch(String key, Map<String, Double> map, Long seconds) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
// 只能针对 key 设置过期时间,zset 中的元素不能单独设置.
scoredSortedSet.add(0, DEFAULT_SCORE_KEY);
if (null != seconds) {
if (seconds <= 0) {
seconds = DEFAULT_EXPIRE_TIME_SECONDS;
}
scoredSortedSet.expire(seconds, TimeUnit.SECONDS);
}
RBatch batch = REDISSON_CLIENT.createBatch();
map.forEach((member, score) -> {
batch.getScoredSortedSet(key).addAsync(score, member);
});
batch.execute();
}
/**
* 读取指定 key 下所有 member, 按照 score 升序(默认)
*/
public Collection<Object> getZSetMembers(String key, int startIndex, int endIndex) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
return scoredSortedSet.valueRange(startIndex, endIndex);
}
/**
* 取指定 key 下所有 member, 按照 score 降序
*/
public Collection<Object> getZSetMembersReversed(String key, int startIndex, int endIndex) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
return scoredSortedSet.valueRangeReversed(startIndex, endIndex);
}
/**
* 读取 member和score, 按照 score 升序(默认)
*/
public Collection<ScoredEntry<Object>> getZSetEntryRange(String key, int startIndex, int endIndex) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
return scoredSortedSet.entryRange(startIndex, endIndex);
}
/**
* 读取 member和score, 按照 score 降序
*/
public Collection<ScoredEntry<Object>> getZSetEntryRangeReversed(String key, int startIndex, int endIndex) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
return scoredSortedSet.entryRangeReversed(startIndex, endIndex);
}
/**
* 读取指定 key 下 member 的 score
* 返回null 表示不存在
*/
public Double getZSetMemberScore(String key, String member) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
if (!scoredSortedSet.isExists()) {
return null;
}
return scoredSortedSet.getScore(member);
}
/**
* 读取指定 key 下 memberList 的 score
* 返回null 表示不存在
*/
public Double getZSetMemberScore(String key, List<String> memberList) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
if (!scoredSortedSet.isExists()) {
return null;
}
return scoredSortedSet.getScore(memberList);
}
/**
* 读取指定 key 下 member 的 rank 排名(升序情况)
* 返回null 表示不存在, 下标从0开始
*/
public Integer getZSetMemberRank(String key, String member) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
if (!scoredSortedSet.isExists()) {
return null;
}
return scoredSortedSet.rank(member);
}
/**
* 异步删除指定 ZSet 中的指定 memberName 元素
*/
public void removeZSetMemberAsync(String key, String memberName) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
if (!scoredSortedSet.isExists()) {
return;
}
scoredSortedSet.removeAsync(memberName);
}
/**
* 异步批量删除指定 ZSet 中的指定 member 元素列表
*/
public void removeZSetMemberAsync(String key, List<String> memberList) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
if (!scoredSortedSet.isExists()) {
return;
}
RBatch batch = REDISSON_CLIENT.createBatch();
memberList.forEach(member -> batch.getScoredSortedSet(key).removeAsync(member));
batch.execute();
}
/**
* 统计ZSet分数范围内元素总数. 区间包含分数本身
* 注意这里不能用 -1 代替最大值
*/
public int getZSetCountByScoresInclusive(String key, double startScore, double endScore) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
if (!scoredSortedSet.isExists()) {
return 0;
}
return scoredSortedSet.count(startScore, true, endScore, true);
}
/**
* 返回ZSet分数范围内 member 列表. 区间包含分数本身.
* 注意这里不能用 -1 代替最大值
*/
public Collection<Object> getZSetMembersByScoresInclusive(String key, double startScore, double endScore) {
RScoredSortedSet<Object> scoredSortedSet = REDISSON_CLIENT.getScoredSortedSet(key);
if (!scoredSortedSet.isExists()) {
return null;
}
return scoredSortedSet.valueRange(startScore, true, endScore, true);
}
/**
* 获取所有的指定前缀 keys
*/
public Set<String> getKeys(String prefix) {
Iterable<String> keysByPattern = REDISSON_CLIENT.getKeys().getKeysByPattern(prefix);
Set<String> keys = new HashSet<>();
for (String s : keysByPattern) {
keys.add(s);
}
return keys;
}
}
















 1183
1183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











