










概叙
本文通过编码规范和单元测试两个方面来指导java编程,写出高校代码。
编码规范
1、规范命名
命名是写代码中最频繁的操作,比如类、属性、方法、参数等。好的名字应当能遵循以下几点:
见名知意
比如需要定义一个变量需要来计数
int i = 0;
名称 i 没有任何的实际意义,没有体现出数量的意思,所以我们应当指明数量的名称
int count = 0;
能够读的出来
如下代码:
private String sfzh;
private String dhhm;
这些变量的名称,根本读不出来,更别说实际意义了。
所以我们可以使用正确的可以读出来的英文来命名
private String idCardNo;
private String phone;
2、规范代码格式
好的代码格式能够让人感觉看起来代码更加舒适。
好的代码格式应当遵守以下几点:
-
合适的空格
-
代码对齐,比如大括号要对齐
-
及时换行,一行不要写太多代码
好在现在开发工具支持一键格式化,可以帮助美化代码格式。
3、写好代码注释
在《代码整洁之道》这本书中作者提到了一个观点,注释的恰当用法是用来弥补我们在用代码表达意图时的失败。换句话说,当无法通过读代码来了解代码所表达的意思的时候,就需要用注释来说明。
作者之所以这么说,是因为作者觉得随着时间的推移,代码可能会变动,如果不及时更新注释,那么注释就容易产生误导,偏离代码的实际意义。而不及时更新注释的原因是,程序员不喜欢写注释。(作者很懂啊)
但是这不意味着可以不写注释,当通过代码如果无法表达意思的时候,就需要注释,比如如下代码
for (Integer id : ids) {
if (id == 0) {
continue;
}
//做其他事
}
为什么 id == 0 需要跳过,代码是无法看出来了,就需要注释了。
好的注释应当满足一下几点:
-
解释代码的意图,说明为什么这么写,用来做什么
-
对参数和返回值注释,入参代表什么,出参代表什么
-
有警示作用,比如说入参不能为空,或者代码是不是有坑
-
当代码还未完成时可以使用 todo 注释来注释
4、try catch 内部代码抽成一个方法
try catch代码有时会干扰我们阅读核心的代码逻辑,这时就可以把try catch内部主逻辑抽离成一个单独的方法
如下图是Eureka服务端源码中服务下线的实现中的一段代码
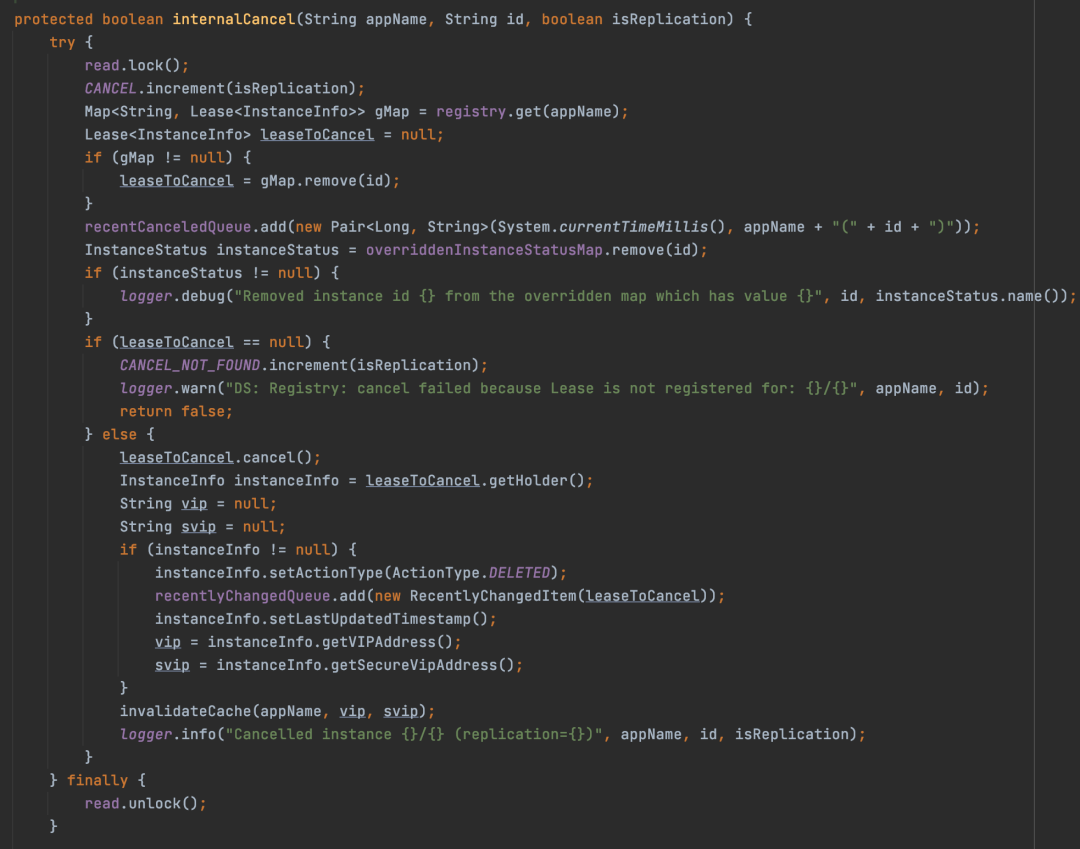
整个方法非常长,try中代码是真正的服务下线的代码实现,finally可以保证读锁最终一定可以释放。
所以这段代码其实就可以对核心的逻辑进行抽取。
protected boolean internalCancel(String appName, String id, boolean isReplication) {
try {
read.lock();
doInternalCancel(appName, id, isReplication);
} finally {
read.unlock();
}
// 剩余代码
}
private boolean doInternalCancel(String appName, String id, boolean isReplication) {
//真正处理下线的逻辑
}
5、方法别太长
方法别太长就是字面的意思。一旦代码太长,给人的第一眼感觉就很复杂,让人不想读下去;同时方法太长的代码可能读起来容易让人摸不着头脑,不知道哪一些代码是同一个业务的功能。
我曾经就遇到过一个方法写了2000+行,各种if else判断,我光理清代码思路就用了很久,最终理清之后,就用策略模式给重构了。
所以一旦方法过长,可以尝试将相同业务功能的代码单独抽取一个方法,最后在主方法中调用即可。
Long Method (长函数)
长函数是指一个函数方法几百行甚至上千行,可读性大大降低,不便于理解。反例如下:
public class Test {
private String name;
private Vector<Order> orders = new Vector<Order>();
public void printOwing() {
//print banner
System.out.println("****************");
System.out.println("*****customer Owes *****");
System.out.println("****************");
//calculate totalAmount
Enumeration env = orders.elements();
double totalAmount = 0.0;
while (env.hasMoreElements()) {
Order order = (Order) env.nextElement();
totalAmount += order.getAmout();
}
//print details
System.out.println("name:" + name);
System.out.println("amount:" + totalAmount);
......
}
}
可以使用Extract Method,抽取功能单一的代码段,组成命名清晰的小函数,去解决长函数问题,正例如下:
public class Test {
private String name;
private Vector<Order> orders = new Vector<Order>();
public void printOwing() {
//print banner
printBanner();
//calculate totalAmount
double totalAmount = getTotalAmount();
//print details
printDetail(totalAmount);
}
void printBanner(){
System.out.println("****************");
System.out.println("*****customer Owes *****");
System.out.println("****************");
}
double getTotalAmount(){
Enumeration env = orders.elements();
double totalAmount = 0.0;
while (env.hasMoreElements()) {
Order order = (Order) env.nextElement();
totalAmount += order.getAmout();
}
return totalAmount;
}
void printDetail(double totalAmount){
System.out.println("name:" + name);
System.out.println("amount:" + totalAmount);
}
}Large Class (过大的类)
一个类做太多事情,维护了太多功能,可读性变差,性能也会下降。举个例子,订单相关的功能你放到一个类A里面,商品库存相关的也放在类A里面,积分相关的还放在类A里面...反例如下:
Class A{
public void printOrder(){
System.out.println("订单");
}
public void printGoods(){
System.out.println("商品");
}
public void printPoints(){
System.out.println("积分");
}
}
试想一下,乱七八糟的代码块都往一个类里面塞,还谈啥可读性。应该按单一职责,使用Extract Class把代码划分开,正例如下:
Class Order{
public void printOrder(){
System.out.println("订单");
}
}
Class Goods{
public void printGoods(){
System.out.println("商品");
}
}
Class Points{
public void printPoints(){
System.out.println("积分");
}
}
}
Long Parameter List (过长参数列)
方法参数数量过多的话,可读性很差。如果有多个重载方法,参数很多的话,有时候你都不知道调哪个呢。并且,如果参数很多,做新老接口兼容处理也比较麻烦。
public void getUserInfo(String name,String age,String sex,String mobile){
// do something ...
}
如何解决过长参数列问题呢?将参数封装成结构或者类,比如我们将参数封装成一个DTO类,如下:
public void getUserInfo(UserInfoParamDTO userInfoParamDTO){
// do something ...
}
class UserInfoParamDTO{
private String name;
private String age;
private String sex;
private String mobile;
}6、抽取重复代码
当一份代码重复出现在程序的多处地方,就会造成程序又臭又长,当这份代码的结构要修改时,每一处出现这份代码的地方都得修改,导致程序的扩展性很差。
所以一般遇到这种情况,可以抽取成一个工具类,还可以抽成一个公共的父类。
Duplicated Code (重复代码)
重复代码就是不同地点,有着相同的程序结构。一般是因为需求迭代比较快,开发小伙伴担心影响已有功能,就复制粘贴造成的。重复代码很难维护的,如果你要修改其中一段的代码逻辑,就需要修改多次,很可能出现遗漏的情况。
如何优化重复代码呢?分三种情况讨论:
-
同一个类的两个函数含有相同的表达式
class A {
public void method1() {
doSomething1
doSomething2
doSomething3
}
public void method2() {
doSomething1
doSomething2
doSomething4
}
}
优化手段:可以使用Extract Method(提取公共函数) 抽出重复的代码逻辑,组成一个公用的方法。
class A {
public void method1() {
commonMethod();
doSomething3
}
public void method2() {
commonMethod();
doSomething4
}
public void commonMethod(){
doSomething1
doSomething2
}
}
-
两个互为兄弟的子类内含相同的表达式
class A extend C {
public void method1() {
doSomething1
doSomething2
doSomething3
}
}
class B extend C {
public void method1() {
doSomething1
doSomething2
doSomething4
}
}
优化手段:对两个类都使用Extract Method(提取公共函数),然后把抽取出来的函数放到父类中。
class C {
public void commonMethod(){
doSomething1
doSomething2
}
}
class A extend C {
public void method1() {
commonMethod();
doSomething3
}
}
class B extend C {
public void method1() {
commonMethod();
doSomething4
}
}
-
两个毫不相关的类出现重复代码
如果是两个毫不相关的类出现重复代码,可以使用Extract Class将重复代码提炼到一个类中。这个新类可以是一个普通类,也可以是一个工具类,看具体业务怎么划分吧。
7、多用return
在有时我们平时写代码的情况可能会出现if条件套if的情况,当if条件过多的时候可能会出现如下情况:
if (条件1) {
if (条件2) {
if (条件3) {
if (条件4) {
if (条件5) {
System.out.println("三友的java日记");
}
}
}
}
}
面对这种情况,可以换种思路,使用return来优化
if (!条件1) {
return;
}
if (!条件2) {
return;
}
if (!条件3) {
return;
}
if (!条件4) {
return;
}
if (!条件5) {
return;
}
System.out.println("三友的java日记");
这样优化就感觉看起来更加直观
8、if条件表达式不要太复杂
比如在如下代码:
if (((StringUtils.isBlank(person.getName())
|| "三友的java日记".equals(person.getName()))
&& (person.getAge() != null && person.getAge() > 10))
&& "汉".equals(person.getNational())) {
// 处理逻辑
}
这段逻辑,这种条件表达式乍一看不知道是什么,仔细一看还是不知道是什么,这时就可以这么优化
boolean sanyouOrBlank = StringUtils.isBlank(person.getName()) || "三友的java日记".equals(person.getName());
boolean ageGreaterThanTen = person.getAge() != null && person.getAge() > 10;
boolean isHanNational = "汉".equals(person.getNational());
if (sanyouOrBlank
&& ageGreaterThanTen
&& isHanNational) {
// 处理逻辑
}
此时就很容易看懂if的逻辑了
9、优雅地参数校验
当前端传递给后端参数的时候,通常需要对参数进场检验,一般可能会这么写
@PostMapping
public void addPerson(@RequestBody AddPersonRequest addPersonRequest) {
if (StringUtils.isBlank(addPersonRequest.getName())) {
throw new BizException("人员姓名不能为空");
}
if (StringUtils.isBlank(addPersonRequest.getIdCardNo())) {
throw new BizException("身份证号不能为空");
}
// 处理新增逻辑
}
这种写虽然可以,但是当字段的多的时候,光校验就占据了很长的代码,不够优雅。
针对参数校验这个问题,有第三方库已经封装好了,比如hibernate-validator框架,只需要拿来用即可。
所以就在实体类上加@NotBlank、@NotNull注解来进行校验
@Data
@ToString
private class AddPersonRequest {
@NotBlank(message = "人员姓名不能为空")
private String name;
@NotBlank(message = "身份证号不能为空")
private String idCardNo;
//忽略
}
此时Controller接口就需要方法上就需要加上@Valid注解
@PostMapping
public void addPerson(@RequestBody @Valid AddPersonRequest addPersonRequest) {
// 处理新增逻辑
}
10、统一返回值
后端在设计接口的时候,需要统一返回值
{
"code":0,
"message":"成功",
"data":"返回数据"
}
不仅是给前端参数,也包括提供给第三方的接口等,这样接口调用方法可以按照固定的格式解析代码,不用进行判断。如果不一样,相信我,前端半夜都一定会来找你。
Spring中很多方法可以做到统一返回值,而不用每个方法都返回,比如基于AOP,或者可以自定义HandlerMethodReturnValueHandler来实现统一返回值。
11、统一异常处理
当你没有统一异常处理的时候,那么所有的接口避免不了try catch操作。
@GetMapping("/{id}")
public Result<T> selectPerson(@PathVariable("id") Long personId) {
try {
PersonVO vo = personService.selectById(personId);
return Result.success(vo);
} catch (Exception e) {
//打印日志
return Result.error("系统异常");
}
}
每个接口都得这么玩,那不得满屏的try catch。
所以可以基于Spring提供的统一异常处理机制来完成。
12、尽量不传递null值
这个很好理解,不传null值可以避免方法不支持为null入参时产生的空指针问题。
当然为了更好的表明该方法是不是可以传null值,可以通过@NonNull和@Nullable注解来标记。@NonNull就表示不能传null值,@Nullable就是可以传null值。
//示例1
public void updatePerson(@Nullable Person person) {
if (person == null) {
return;
}
personService.updateById(person);
}
//示例2
public void updatePerson(@NonNull Person person) {
personService.updateById(person);
}
13、尽量不返回null值
尽量不返回null值是为了减少调用者对返回值的为null判断,如果无法避免返回null值,可以通过返回Optional来代替null值。
public Optional<Person> getPersonById(Long personId) {
return Optional.ofNullable(personService.selectById(personId));
}
如果不想这么写,也可以通过@NonNull和@Nullable表示方法会不会返回null值。
14、日志打印规范
好的日志打印能帮助我们快速定位问题
好的日志应该遵循以下几点:
-
可搜索性,要有明确的关键字信息
-
异常日志需要打印出堆栈信息
-
合适的日志级别,比如异常使用error,正常使用info
-
日志内容太大不打印,比如有时需要将图片转成Base64,那么这个Base64就可以不用打印
15、统一类库
在一个项目中,可能会由于引入的依赖不同导致引入了很多相似功能的类库,比如常见的json类库,又或者是一些常用的工具类,当遇到这种情况下,应当规范在项目中到底应该使用什么类库,而不是一会用Fastjson,一会使用Gson。
16、尽量使用工具类
比如在对集合判空的时候,可以这么写
public void updatePersons(List<Person> persons) {
if (persons != null && persons.size() > 0) {
}
}
但是一般不推荐这么写,可以通过一些判断的工具类来写
public void updatePersons(List<Person> persons) {
if (!CollectionUtils.isEmpty(persons)) {
}
}
不仅集合,比如字符串的判断等等,就使用工具类,不要手动判断。
17、尽量不要重复造轮子
就拿格式化日期来来说,我们一般封装成一个工具类来调用,比如如下代码
private static final SimpleDateFormat DATE_TIME_FORMAT = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static String formatDateTime(Date date) {
return DATE_TIME_FORMAT.format(date);
}
这段代码看似没啥问题,但是却忽略了SimpleDateFormat是个线程不安全的类,所以这就会引起坑。
一般对于这种已经有开源的项目并且已经做得很好的时候,比如Hutool,就可以把轮子直接拿过来用了。
18、类和方法单一职责
单一职责原则是设计模式的七大设计原则之一,它的核心意思就是字面的意思,一个类或者一个方法只做单一的功能。
就拿Nacos来说,在Nacos1.x的版本中,有这么一个接口HttpAgent
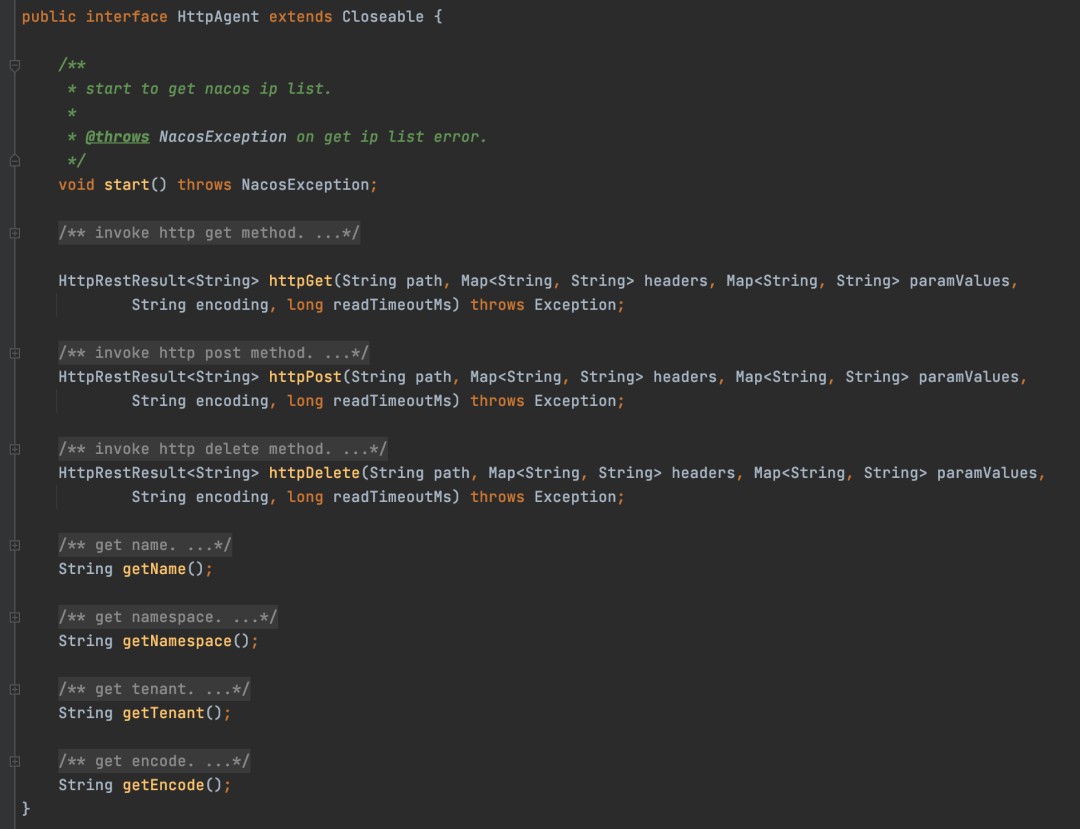
这个类只干了一件事,那就是封装http请求参数,向Nacos服务端发送请求,接收响应,这其实就是单一职责原则的体现。
当其它的地方需要向Nacos服务端发送请求时,只需要通过这个接口的实现,传入参数就可以发送请求了,而不需要关心如何携带服务端鉴权参数、http请求参数如何组装等问题。
19、尽量使用聚合/组合代替继承
继承的弊端:
-
灵活性低。java语言是单继承的,无法同时继承很多类,并且继承容易导致代码层次太深,不易于维护
-
耦合性高。一旦父类的代码修改,可能会影响到子类的行为
所以一般推荐使用聚合/组合代替继承。
聚合/组合的意思就是通过成员变量的方式来使用类。
比如说,OrderService需要使用UserService,可以注入一个UserService而非通过继承UserService。
聚合和组合的区别就是,组合是当对象一创建的时候,就直接给属性赋值,而聚合的方式可以通过set方式来设置。
组合:
public class OrderService {
private UserService userService = new UserService();
}
聚合:
public class OrderService {
private UserService userService;
public void setUserService(UserService userService) {
this.userService = userService;
}
}
20、使用设计模式优化代码
在平时开发中,使用设计模式可以增加代码的扩展性。
比如说,当你需要做一个可以根据不同的平台做不同消息推送的功能时,就可以使用策略模式的方式来优化。
设计一个接口:
public interface MessageNotifier {
/**
* 是否支持改类型的通知的方式
*
* @param type 0:短信 1:app
* @return
*/
boolean support(int type);
/**
* 通知
*
* @param user
* @param content
*/
void notify(User user, String content);
}
短信通知实现:
@Component
public class SMSMessageNotifier implements MessageNotifier {
@Override
public boolean support(int type) {
return type == 0;
}
@Override
public void notify(User user, String content) {
//调用短信通知的api发送短信
}
}
app通知实现:
public class AppMessageNotifier implements MessageNotifier {
@Override
public boolean support(int type) {
return type == 1;
}
@Override
public void notify(User user, String content) {
//调用通知app通知的api
}
}
最后提供一个方法,当需要进行消息通知时,调用notifyMessage,传入相应的参数就行。
@Resource
private List<MessageNotifier> messageNotifiers;
public void notifyMessage(User user, String content, int notifyType) {
for (MessageNotifier messageNotifier : messageNotifiers) {
if (messageNotifier.support(notifyType)) {
messageNotifier.notify(user, content);
}
}
}
假设此时需要支持通过邮件通知,只需要有对应实现就行。
21、不滥用设计模式
用好设计模式可以增加代码的扩展性,但是滥用设计模式确是不可取的。
public void printPerson(Person person) {
StringBuilder sb = new StringBuilder();
if (StringUtils.isNotBlank(person.getName())) {
sb.append("姓名:").append(person.getName());
}
if (StringUtils.isNotBlank(person.getIdCardNo())) {
sb.append("身份证号:").append(person.getIdCardNo());
}
// 省略
System.out.println(sb.toString());
}
比如上面打印Person信息的代码,用if判断就能够做到效果,你说我要不用责任链或者什么设计模式来优化一下吧,没必要。
22、面向接口编程
在一些可替换的场景中,应该引用父类或者抽象,而非实现。
举个例子,在实际项目中可能需要对一些图片进行存储,但是存储的方式很多,比如可以选择阿里云的OSS,又或者是七牛云,存储服务器等等。所以对于存储图片这个功能来说,这些具体的实现是可以相互替换的。
所以在项目中,我们不应当在代码中耦合一个具体的实现,而是可以提供一个存储接口
public interface FileStorage {
String store(String fileName, byte[] bytes);
}
如果选择了阿里云OSS作为存储服务器,那么就可以基于OSS实现一个FileStorage,在项目中哪里需要存储的时候,只要实现注入这个接口就可以了。
@Autowired
private FileStorage fileStorage;
假设用了一段时间之后,发现阿里云的OSS比较贵,此时想换成七牛云的,那么此时只需要基于七牛云的接口实现FileStorage接口,然后注入到IOC,那么原有代码用到FileStorage根本不需要动,实现轻松的替换。
23、经常重构旧的代码
随着时间的推移,业务的增长,有的代码可能不再适用,或者有了更好的设计方式,那么可以及时的重构业务代码。
就拿上面的消息通知为例,在业务刚开始的时候可能只支持短信通知,于是在代码中就直接耦合了短信通知的代码。但是随着业务的增长,逐渐需要支持app、邮件之类的通知,那么此时就可以重构以前的代码,抽出一个策略接口,进行代码优化。
24、null值判断
空指针是代码开发中的一个难题,作为程序员的基本修改,应该要防止空指针。
可能产生空指针的原因:
-
数据返回对象为null
-
自动拆箱导致空指针
-
rpc调用返回的对象可能为空格
所以在需要这些的时候,需要强制判断是否为null。前面也提到可以使用Optional来优雅地进行null值判断。
25、pojo类重写toString方法
pojo一般内部都有很多属性,重写toString方法可以方便在打印或者测试的时候查看内部的属性。
26、魔法值用常量表示
public void sayHello(String province) {
if ("广东省".equals(province)) {
System.out.println("靓仔~~");
} else {
System.out.println("帅哥~~");
}
}
代码里,广东省就是一个魔法值,那么就可以将用一个常量来保存
private static final String GUANG_DONG_PROVINCE = "广东省";
public void sayHello(String province) {
if (GUANG_DONG_PROVINCE.equals(province)) {
System.out.println("靓仔~~");
} else {
System.out.println("帅哥~~");
}
}
27、资源释放写到finally
比如在使用一个api类锁或者进行IO操作的时候,需要主动写代码需释放资源,为了能够保证资源能够被真正释放,那么就需要在finally中写代码保证资源释放。
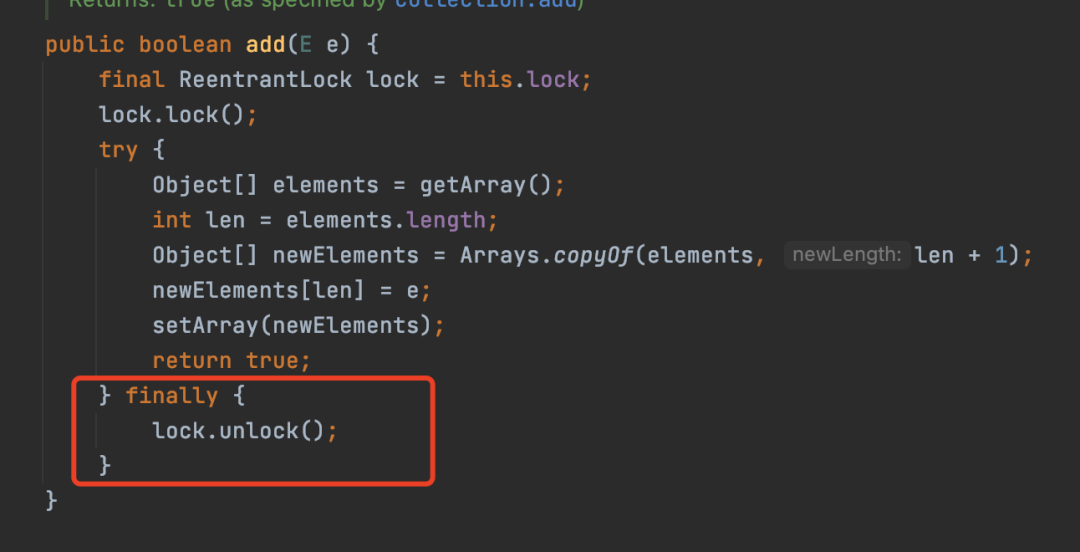
如图所示,就是CopyOnWriteArrayList的add方法的实现,最终是在finally中进行锁的释放。
28、使用线程池代替手动创建线程
使用线程池还有以下好处:
-
降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
-
提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
-
提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统 的稳定性,使用线程池可以进行统一的分配,调优和监控。
所以为了达到更好的利用资源,提高响应速度,就可以使用线程池的方式来代替手动创建线程。
如果对线程池不清楚的同学,可以看一下这篇文章:7000字+24张图带你彻底弄懂线程池
29、线程设置名称
在日志打印的时候,日志是可以把线程的名字给打印出来。
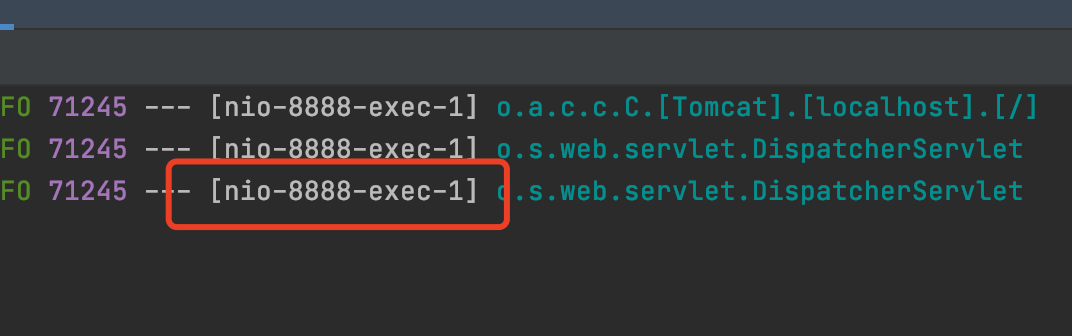
如上图,日志打印出来的就是tom猫的线程。
所以,设置线程的名称可以帮助我们更好的知道代码是通过哪个线程执行的,更容易排查问题。
30、涉及线程间可见性加volatile
在RocketMQ源码中有这么一段代码
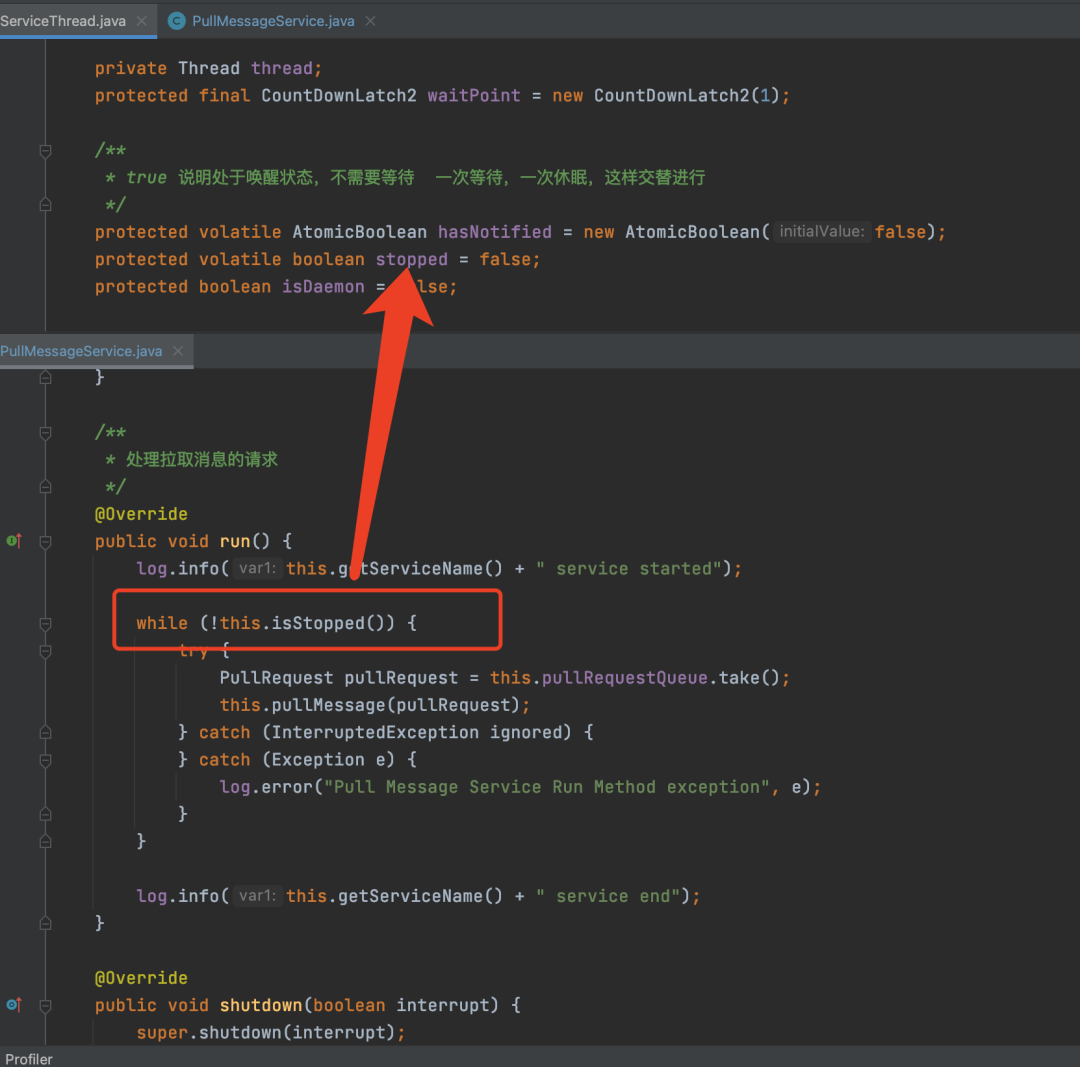
在消费者在从服务端拉取消息的时候,会单独开一个线程,执行while循环,只要stopped状态一直为false,那么就会一直循环下去,线程就一直会运行下去,拉取消息。
当消费者客户端关闭的时候,就会将stopped状态设置为true,告诉拉取消息的线程需要停止了。但是由于并发编程中存在可见性的问题,所以虽然客户端关闭线程将stopped状态设置为true,但是拉取消息的线程可能看不见,不能及时感知到数据的修改,还是认为stopped状态设置为false,那么就还会运行下去。
针对这种可见性的问题,java提供了一个volatile关键字来保证线程间的可见性。
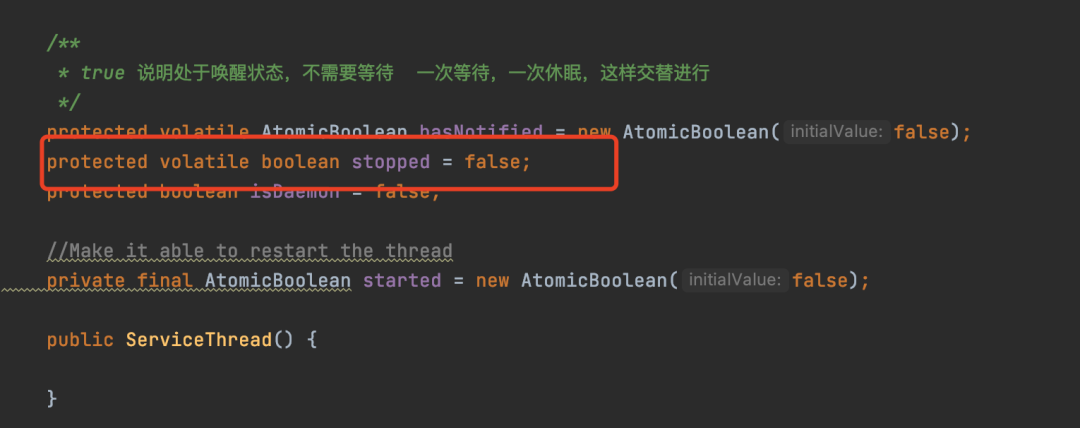
所以,源码中就加了volatile关键字。
加了volatile关键字之后,一旦客户端的线程将stopped状态设置为true时候,拉取消息的线程就能立马知道stopped已经是false了,那么再次执行while条件判断的时候,就不成立,线程就运行结束了,然后退出。
31、考虑线程安全问题
在平时开发中,有时需要考虑并发安全的问题。
举个例子来说,一般在调用第三方接口的时候,可能会有一个鉴权的机制,一般会携带一个请求头token参数过去,而token也是调用第三方接口返回的,一般这种token都会有个过期时间,比如24小时。
我们一般会将token缓存到Redis中,设置一个过期时间。向第三方发送请求时,会直接从缓存中查找,但是当从Redis中获取不到token的时候,我们都会重新请求token接口,获取token,然后再设置到缓存中。
整个过程看起来是没什么问题,但是实则隐藏线程安全问题。
假设当出现并发的时候,同时来两个线程AB从缓存查找,发现没有,那么AB此时就会同时调用token获取接口。假设A先获取到token,B后获取到token,但是由于CPU调度问题,线程B虽然后获取到token,但是先往Redis存数据,而线程A后存,覆盖了B请求的token。
这下就会出现大问题,最新的token被覆盖了,那么之后一定时间内token都是无效的,接口就请求不通。
针对这种问题,可以使用double check机制来优化获取token的问题。
所以,在实际中,需要多考虑考虑业务是否有线程安全问题,有集合读写安全问题,那么就用线程安全的集合,业务有安全的问题,那么就可以通过加锁的手段来解决。
32、慎用异步
虽然在使用多线程可以帮助我们提高接口的响应速度,但是也会带来很多问题。
事务问题
一旦使用了异步,就会导致两个线程不是同一个事务的,导致异常之后无法正常回滚数据。
cpu负载过高
之前有个小伙伴遇到需要同时处理几万调数据的需求,每条数据都需要调用很多次接口,为了达到老板期望的时间要求,使用了多线程跑,开了很多线程,此时会发现系统的cpu会飙升
意想不到的异常
还是上面的提到的例子,在测试的时候就发现,由于并发量激增,在请求第三方接口的时候,返回了很多错误信息,导致有的数据没有处理成功。
虽然说慎用异步,但不代表不用,如果可以保证事务的问题,或是CPU负载不会高的话,那么还是可以使用的。
33、减小锁的范围
减小锁的范围就是给需要加锁的代码加锁,不需要加锁的代码不要加锁。这样就能减少加锁的时间,从而可以较少锁互斥的时间,提高效率。
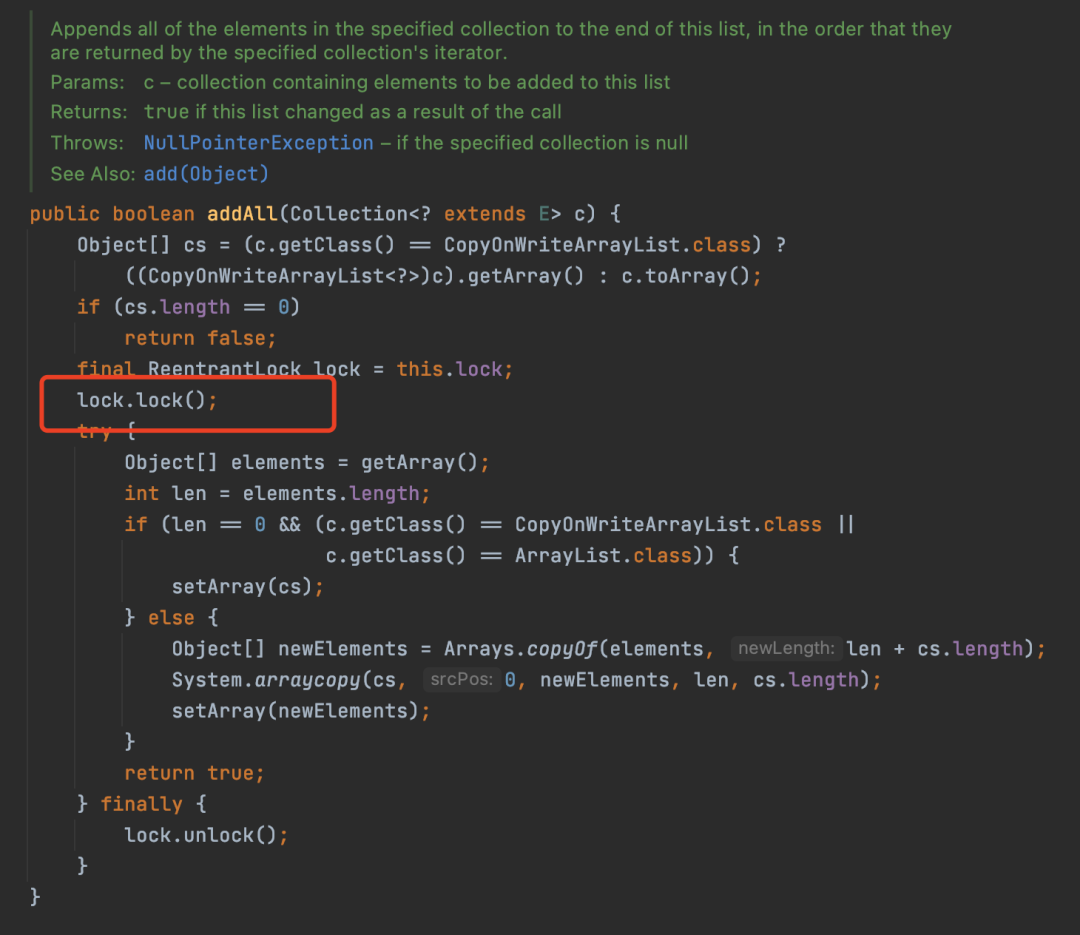
比如CopyOnWriteArrayList的addAll方法的实现,lock.lock(); 代码完全可以放到代码的第一行,但是作者并没有,因为前面判断的代码不会有线程安全的问题,不放到加锁代码中可以减少锁抢占和占有的时间。
34、有类型区分时定义好枚举
比如在项目中不同的类型的业务可能需要上传各种各样的附件,此时就可以定义好不同的一个附件的枚举,来区分不同业务的附件。
不要在代码中直接写死,不定义枚举,代码阅读起来非常困难,直接看到数字都是懵逼的。。
35、远程接口调用设置超时时间
比如在进行微服务之间进行rpc调用的时候,又或者在调用第三方提供的接口的时候,需要设置超时时间,防止因为各种原因,导致线程”卡死“在那。
我以前就遇到过线上就遇到过这种问题。当时的业务是订阅kafka的消息,然后向第三方上传数据。在某个周末,突然就接到电话,说数据无法上传了,通过排查线上的服务器才发现所有的线程都线程”卡死“了,最后定位到代码才发现原来是没有设置超时时间。
36、集合使用应当指明初始化大小
比如在写代码的时候,经常会用到List、Map来临时存储数据,其中最常用的就是ArrayList和HashMap。但是用不好可能也会导致性能的问题。
比如说,在ArrayList中,底层是基于数组来存储的,数组是一旦确定大小是无法再改变容量的。但不断的往ArrayList中存储数据的时候,总有那么一刻会导致数组的容量满了,无法再存储其它元素,此时就需要对数组扩容。所谓的扩容就是新创建一个容量是原来1.5倍的数组,将原有的数据给拷贝到新的数组上,然后用新的数组替代原来的数组。
在扩容的过程中,由于涉及到数组的拷贝,就会导致性能消耗;同时HashMap也会由于扩容的问题,消耗性能。所以在使用这类集合时可以在构造的时候指定集合的容量大小。
37、尽量不要使用BeanUtils来拷贝属性
在开发中经常需要对JavaBean进行转换,但是又不想一个一个手动set,比较麻烦,所以一般会使用属性拷贝的一些工具,比如说Spring提供的BeanUtils来拷贝。不得不说,使用BeanUtils来拷贝属性是真的舒服,使用一行代码可以代替几行甚至十几行代码,我也喜欢用。
但是喜欢归喜欢,但是会带来性能问题,因为底层是通过反射来的拷贝属性的,所以尽量不要用BeanUtils来拷贝属性。
比如你可以装个JavaBean转换的插件,帮你自动生成转换代码;又或者可以使用性能更高的MapStruct来进行JavaBean转换,MapStruct底层是通过调用(settter/getter)来实现的,而不是反射来快速执行。
38、使用StringBuilder进行字符串拼接
如下代码:
String str1 = "123";
String str2 = "456";
String str3 = "789";
String str4 = str1 + str2 + str3;
使用 + 拼接字符串的时候,会创建一个StringBuilder,然后将要拼接的字符串追加到StringBuilder,再toString,这样如果多次拼接就会执行很多次的创建StringBuilder,z执行toString的操作。
所以可以手动通过StringBuilder拼接,这样只会创建一次StringBuilder,效率更高。
StringBuilder sb = new StringBuilder();
String str = sb.append("123").append("456").append("789").toString();
39、@Transactional应指定回滚的异常类型
平时在写代码的时候需要通过rollbackFor显示指定需要对什么异常回滚,原因在这:
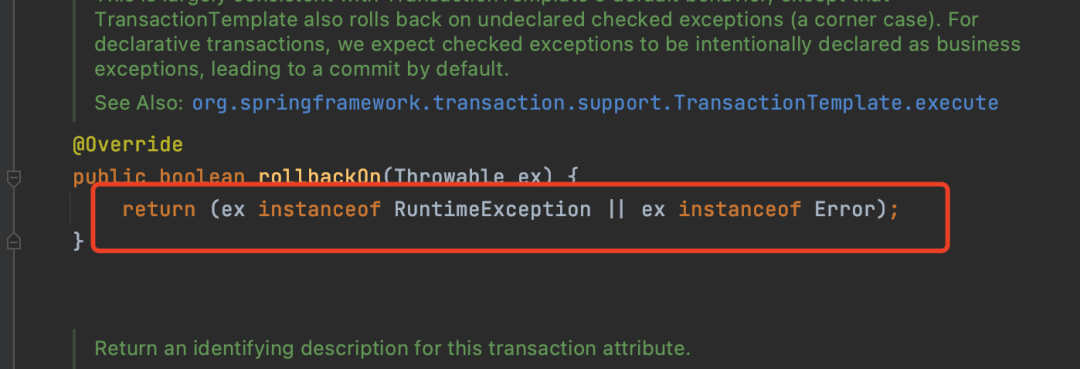
默认是只能回滚RuntimeException和Error异常,所以需要手动指定,比如指定成Expection等。
40、谨慎方法内部调用动态代理的方法
如下事务代码
@Service
public class PersonService {
public void update(Person person) {
// 处理
updatePerson(person);
}
@Transactional(rollbackFor = Exception.class)
public void updatePerson(Person person) {
// 处理
}
}
update调用了加了@Transactional注解的updatePerson方法,那么此时updatePerson的事务就是失效。
其实失效的原因不是事务的锅,是由AOP机制决定的,因为事务是基于AOP实现的。AOP是基于对象的代理,当内部方法调用时,走的不是动态代理对象的方法,而是原有对象的方法调用,如此就走不到动态代理的代码,就会失效了。
如果实在需要让动态代理生效,可以注入自己的代理对象
@Service
public class PersonService {
@Autowired
private PersonService personService;
public void update(Person person) {
// 处理
personService.updatePerson(person);
}
@Transactional(rollbackFor = Exception.class)
public void updatePerson(Person person) {
// 处理
}
}
41、需要什么字段select什么字段
查询全字段有以下几点坏处:
增加不必要的字段的网络传输
比如有些文本的字段,存储的数据非常长,但是本次业务使用不到,但是如果查了就会把这个数据返回给客户端,增加了网络传输的负担
会导致无法使用到覆盖索引
比如说,现在有身份证号和姓名做了联合索引,现在只需要根据身份证号查询姓名,如果直接select name 的话,那么在遍历索引的时候,发现要查询的字段在索引中已经存在,那么此时就会直接从索引中将name字段的数据查出来,返回,而不会继续去查找聚簇索引,减少回表的操作。
所以建议是需要使用什么字段查询什么字段。比如mp也支持在构建查询条件的时候,查询某个具体的字段。
Wrappers.query().select("name");
42、不循环调用数据库
不要在循环中访问数据库,这样会严重影响数据库性能。
比如需要查询一批人员的信息,人员的信息存在基本信息表和扩展表中,错误的代码如下:
public List<PersonVO> selectPersons(List<Long> personIds) {
List<PersonVO> persons = new ArrayList<>(personIds.size());
List<Person> personList = personMapper.selectByIds(personIds);
for (Person person : personList) {
PersonVO vo = new PersonVO();
PersonExt personExt = personExtMapper.selectById(person.getId());
// 组装数据
persons.add(vo);
}
return persons;
}
遍历每个人员的基本信息,去数据库查找。
正确的方法应该先批量查出来,然后转成map:
public List<PersonVO> selectPersons(List<Long> personIds) {
List<PersonVO> persons = new ArrayList<>(personIds.size());
List<Person> personList = personMapper.selectByIds(personIds);
//批量查询,转换成Map
List<PersonExt> personExtList = personExtMapper.selectByIds(person.getId());
Map<String, PersonExt> personExtMap = personExtList.stream().collect(Collectors.toMap(PersonExt::getPersonId, Function.identity()));
for (Person person : personList) {
PersonVO vo = new PersonVO();
//直接从Map中查找
PersonExt personExt = personExtMap.get(person.getId());
// 组装数据
persons.add(vo);
}
return persons;
}
43、用业务代码代替多表join
如上面代码所示,原本也可以将两张表根据人员的id进行关联查询。但是不推荐这么,阿里也禁止多表join的操作

而之所以会禁用,是因为join的效率比较低。
MySQL是使用了嵌套循环的方式来实现关联查询的,也就是for循环会套for循环的意思。用第一张表做外循环,第二张表做内循环,外循环的每一条记录跟内循环中的记录作比较,符合条件的就输出,这种效率肯定低。
44、装上阿里代码检查插件
我们平时写代码由于各种因为,比如什么领导啊,项目经理啊,会一直催进度,导致写代码都来不及思考,怎么快怎么来,cv大法上线,虽然有心想写好代码,但是手确不听使唤。所以我建议装一个阿里的代码规范插件,如果有代码不规范,会有提醒,这样就可以知道哪些是可以优化的了。
如果你有强迫症,相信我,装了这款插件,你的代码会写的很漂亮。
45、其他
5. Divergent Change (发散式变化)
对程序进行维护时, 如果添加修改组件, 要同时修改一个类中的多个方法, 那么这就是 Divergent Change。举个汽车的例子,某个汽车厂商生产三种品牌的汽车:BMW、Benz和LaoSiLaiSi,每种品牌又可以选择燃油、纯电和混合动力。反例如下:
/**
* 公众号:捡田螺的小男孩
*/
public class Car {
private String name;
void start(Engine engine) {
if ("HybridEngine".equals(engine.getName())) {
System.out.println("Start Hybrid Engine...");
} else if ("GasolineEngine".equals(engine.getName())) {
System.out.println("Start Gasoline Engine...");
} else if ("ElectricEngine".equals(engine.getName())) {
System.out.println("Start Electric Engine");
}
}
void drive(Engine engine,Car car) {
this.start(engine);
System.out.println("Drive " + getBrand(car) + " car...");
}
String getBrand(Car car) {
if ("Baoma".equals(car.getName())) {
return "BMW";
} else if ("BenChi".equals(car.getName())) {
return "Benz";
} else if ("LaoSiLaiSi".equals(car.getName())) {
return "LaoSiLaiSi";
}
return null;
}
}
如果新增一种品牌新能源电车,然后它的启动引擎是核动力呢,那么就需要修改Car类的start和getBrand方法啦,这就是代码坏味道:Divergent Change (发散式变化)。
如何优化呢?一句话总结:拆分类,将总是一起变化的东西放到一块。
★”
运用提炼类(Extract Class) 拆分类的行为。
如果不同的类有相同的行为,提炼超类(Extract Superclass) 和 提炼子类(Extract Subclass)。
正例如下:
因为Engine是独立变化的,所以提取一个Engine接口,如果新加一个启动引擎,多一个实现类即可。如下:
//IEngine
public interface IEngine {
void start();
}
public class HybridEngineImpl implements IEngine {
@Override
public void start() {
System.out.println("Start Hybrid Engine...");
}
}
因为drive方法依赖于Car,IEngine,getBand方法;getBand方法是变化的,也跟Car是有关联的,所以可以搞个抽象Car的类,每个品牌汽车继承于它即可,如下
public abstract class AbstractCar {
protected IEngine engine;
public AbstractCar(IEngine engine) {
this.engine = engine;
}
public abstract void drive();
}
//奔驰汽车
public class BenzCar extends AbstractCar {
public BenzCar(IEngine engine) {
super(engine);
}
@Override
public void drive() {
this.engine.start();
System.out.println("Drive " + getBrand() + " car...");
}
private String getBrand() {
return "Benz";
}
}
//宝马汽车
public class BaoMaCar extends AbstractCar {
public BaoMaCar(IEngine engine) {
super(engine);
}
@Override
public void drive() {
this.engine.start();
System.out.println("Drive " + getBrand() + " car...");
}
private String getBrand() {
return "BMW";
}
}
细心的小伙伴,可以发现不同子类BaoMaCar和BenzCar的drive方法,还是有相同代码,所以我们可以再扩展一个抽象子类,把drive方法推进去,如下:
public abstract class AbstractRefinedCar extends AbstractCar {
public AbstractRefinedCar(IEngine engine) {
super(engine);
}
@Override
public void drive() {
this.engine.start();
System.out.println("Drive " + getBrand() + " car...");
}
abstract String getBrand();
}
//宝马
public class BaoMaRefinedCar extends AbstractRefinedCar {
public BaoMaRefinedCar(IEngine engine) {
super(engine);
}
@Override
String getBrand() {
return "BMW";
}
}
如果再添加一个新品牌,搞个子类,继承AbstractRefinedCar即可,如果新增一种启动引擎,也是搞个类实现IEngine接口即可
6. Shotgun Surgery(散弹式修改)
当你实现某个小功能时,你需要在很多不同的类做出小修改。这就是Shotgun Surgery(散弹式修改)。它跟发散式变化(Divergent Change) 的区别就是,它指的是同时对多个类进行单一的修改,发散式变化指在一个类中修改多处。反例如下:
public class DbAUtils {
@Value("${db.mysql.url}")
private String mysqlDbUrl;
...
}
public class DbBUtils {
@Value("${db.mysql.url}")
private String mysqlDbUrl;
...
}
多个类使用了db.mysql.url这个变量,如果将来需要切换mysql到别的数据库,如Oracle,那就需要修改多个类的这个变量!
如何优化呢?将各个修改点,集中到一起,抽象成一个新类。
★可以使用 Move Method (搬移函数)和 Move Field (搬移字段)把所有需要修改的代码放进同一个类,如果没有合适的类,就去new一个。
”
正例如下:
public class DbUtils {
@Value("${db.mysql.url}")
private String mysqlDbUrl;
...
}
7. Feature Envy (依恋情节)
某个函数为了计算某个值,从另一个对象那里调用几乎半打的取值函数。通俗点讲,就是一个函数使用了大量其他类的成员,有人称之为红杏出墙的函数。反例如下:
public class User{
private Phone phone;
public User(Phone phone){
this.phone = phone;
}
public void getFullPhoneNumber(Phone phone){
System.out.println("areaCode:" + phone.getAreaCode());
System.out.println("prefix:" + phone.getPrefix());
System.out.println("number:" + phone.getNumber());
}
}
如何解决呢?在这种情况下,你可以考虑将这个方法移动到它使用的那个类中。例如,要将 getFullPhoneNumber()从 User 类移动到Phone类中,因为它调用了Phone类的很多方法。
8. Data Clumps(数据泥团)
数据项就像小孩子,喜欢成群结队地呆在一块。如果一些数据项总是一起出现的,并且一起出现更有意义的,就可以考虑,按数据的业务含义来封装成数据对象。反例如下:
public class User {
private String firstName;
private String lastName;
private String province;
private String city;
private String area;
private String street;
}
正例:
public class User {
private UserName username;
private Adress adress;
}
class UserName{
private String firstName;
private String lastName;
}
class Address{
private String province;
private String city;
private String area;
private String street;
}
9. Primitive Obsession (基本类型偏执)
多数编程环境都有两种数据类型,结构类型和基本类型。这里的基本类型,如果指Java语言的话,不仅仅包括那八大基本类型哈,也包括String等。如果是经常一起出现的基本类型,可以考虑把它们封装成对象。我个人觉得它有点像Data Clumps(数据泥团) 举个反例如下:
// 订单
public class Order {
private String customName;
private String address;
private Integer orderId;
private Integer price;
}
正例:
// 订单类
public class Order {
private Custom custom;
private Integer orderId;
private Integer price;
}
// 把custom相关字段封装起来,在Order中引用Custom对象
public class Custom {
private String name;
private String address;
}
当然,这里不是所有的基本类型,都建议封装成对象,有关联或者一起出现的,才这么建议哈。
10. Switch Statements (Switch 语句)
这里的Switch语句,不仅包括Switch相关的语句,也包括多层if...else的语句哈。很多时候,switch语句的问题就在于重复,如果你为它添加一个新的case语句,就必须找到所有的switch语句并且修改它们。
示例代码如下:
String medalType = "guest";
if ("guest".equals(medalType)) {
System.out.println("嘉宾勋章");
} else if ("vip".equals(medalType)) {
System.out.println("会员勋章");
} else if ("guard".equals(medalType)) {
System.out.println("守护勋章");
}
...
这种场景可以考虑使用多态优化:
//勋章接口
public interface IMedalService {
void showMedal();
}
//守护勋章策略实现类
public class GuardMedalServiceImpl implements IMedalService {
@Override
public void showMedal() {
System.out.println("展示守护勋章");
}
}
//嘉宾勋章策略实现类
public class GuestMedalServiceImpl implements IMedalService {
@Override
public void showMedal() {
System.out.println("嘉宾勋章");
}
}
//勋章服务工厂类
public class MedalServicesFactory {
private static final Map<String, IMedalService> map = new HashMap<>();
static {
map.put("guard", new GuardMedalServiceImpl());
map.put("vip", new VipMedalServiceImpl());
map.put("guest", new GuestMedalServiceImpl());
}
public static IMedalService getMedalService(String medalType) {
return map.get(medalType);
}
}
当然,多态只是优化的一个方案,一个方向。如果只是单一函数有些简单选择示例,并不建议动不动就使用动态,因为显得有点杀鸡使用牛刀了。
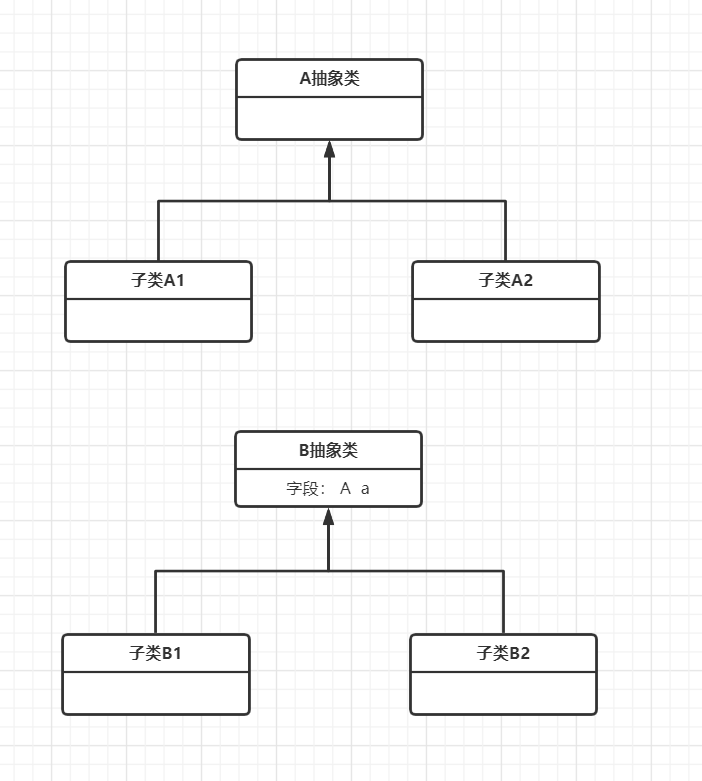
11.Parallel Inheritance Hierarchies( 平行继承体系)
平行继承体系 其实算是Shotgun Surgery的特殊情况啦。当你为A类的一个子类Ax,也必须为另一个类B相应的增加一个子类Bx。
解决方法:遇到这种情况,就要消除两个继承体系之间的引用,有一个类是可以去掉继承关系的。
12. Lazy Class (冗赘类)
把这些不再重要的类里面的逻辑,合并到相关类,删掉旧的。一个比较常见的场景就是,假设系统已经有日期工具类DateUtils,有些小伙伴在开发中,需要用到日期转化等,不管三七二十一,又自己实现一个新的日期工具类。
13. Speculative Generality(夸夸其谈未来性)
尽量避免过度设计的代码。例如:
-
只有一个if else,那就不需要班门弄斧使用多态;
-
如果某个抽象类没有什么太大的作用,就运用
Collapse Hierarchy(折叠继承体系) -
如果函数的某些参数没用上,就移除。
14. Temporary Field(令人迷惑的临时字段)
某个实例变量仅为某种特定情况而定而设,这样的代码就让人不易理解,我们称之为 Temporary Field(令人迷惑的临时字段)。反例如下:
public class PhoneAccount {
private double excessMinutesCharge;
private static final double RATE = 8.0;
public double computeBill(int minutesUsed, int includedMinutes) {
excessMinutesCharge = 0.0;
int excessMinutes = minutesUsed - includedMinutes;
if (excessMinutes >= 1) {
excessMinutesCharge = excessMinutes * RATE;
}
return excessMinutesCharge;
}
public double chargeForExcessMinutes(int minutesUsed, int includedMinutes) {
computeBill(minutesUsed, includedMinutes);
return excessMinutesCharge;
}
}
思考一下,临时字段excessMinutesCharge是否多余呢?
15. Message Chains (过度耦合的消息链)
当你看到用户向一个对象请求另一个对象,然后再向后者请求另一个对象,然后再请求另一个对象...这就是消息链。实际代码中,你看到的可能是一长串getThis()或一长串临时变量。反例如下:
A.getB().getC().getD().getTianLuoBoy().getData();
A想要获取需要的数据时,必须要知道B,又必须知道C,又必须知道D...其实A需要知道得太多啦,回头想下封装性,嘻嘻。其实可以通过拆函数或者移动函数解决,比如由B作为代理,搞个函数直接返回A需要数据。
16. Middle Man (中间人)
对象的基本特征之一就是封装,即对外部世界隐藏其内部细节。封装往往伴随委托,过度运用委托就不好:某个类接口有一半的函数都委托给其他类。可以使用Remove Middle Man优化。反例如下:
A.B.getC(){
return C.getC();
}
其实,A可以直接通过C去获取C,而不需要通过B去获取。
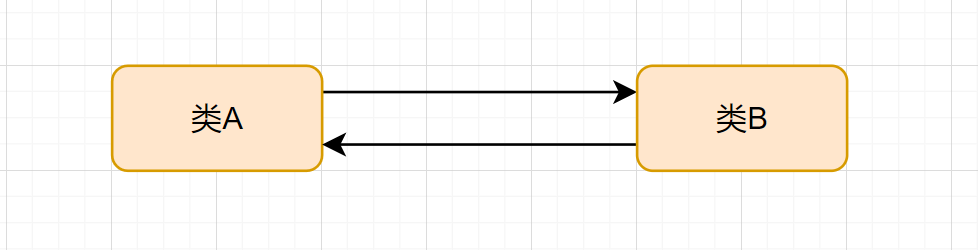
17. Inappropriate Intimacy(狎昵关系)
如果两个类过于亲密,过分狎昵,你中有我,我中有你,两个类彼此使用对方的私有的东西,就是一种坏代码味道。我们称之为Inappropriate Intimacy(狎昵关系)
建议尽量把有关联的方法或属性抽离出来,放到公共类,以减少关联。
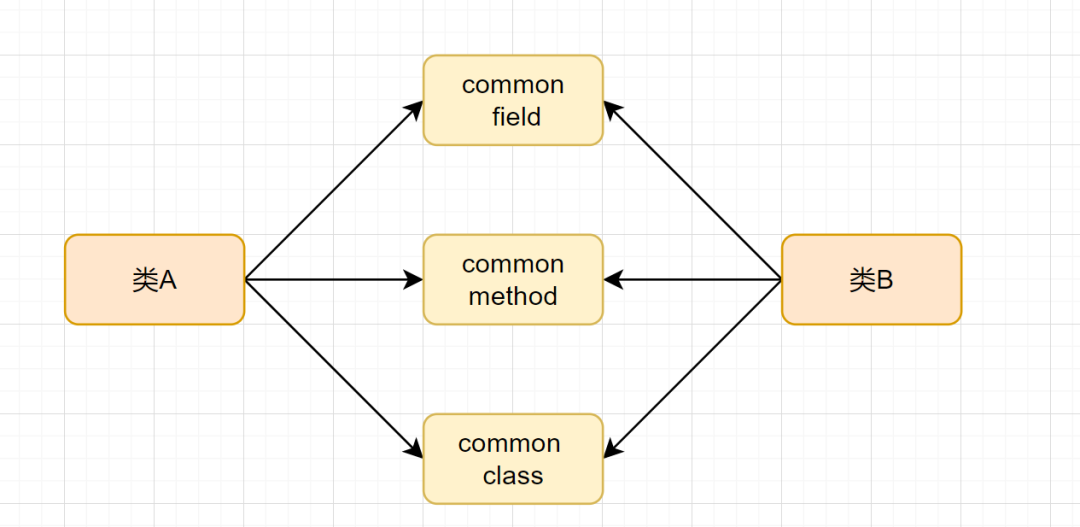
18. Alternative Classes with Different Interfaces (异曲同工的类)
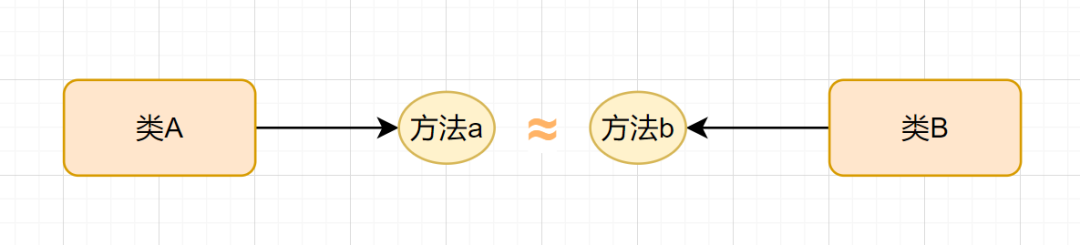
A类的接口a,和B类的接口b,做的的是相同一件事,或者类似的事情。我们就把A和B叫做异曲同工的类。
可以通过重命名,移动函数,或抽象子类等方式优化
19. Incomplete Library Class (不完美的类库)
大多数对象只要够用就好,如果类库构造得不够好,我们不可能修改其中的类使它完成我们希望完成的工作。可以酱紫:包一层函数或包成新的类。
20. Data Class (纯数据类)
什么是Data Class? 它们拥有一些字段,以及用于访问(读写)这些字段的函数。这些类很简单,仅有公共成员变量,或简单操作的函数。
如何优化呢?将相关操作封装进去,减少public成员变量。比如:
-
如果拥有public字段->
Encapsulate Field -
如果这些类内含容器类的字段,应该检查它们是不是得到了恰当地封装->
Encapsulate Collection封装起来 -
对于不该被其他类修改的字段->
Remove Setting Method->找出取值/设置函数被其他类运用的地点->Move Method把这些调用行为搬移到Data Class来。如果无法搬移整个函数,就运用Extract Method产生一个可被搬移的函数->Hide Method把这些取值/设置函数隐藏起来。
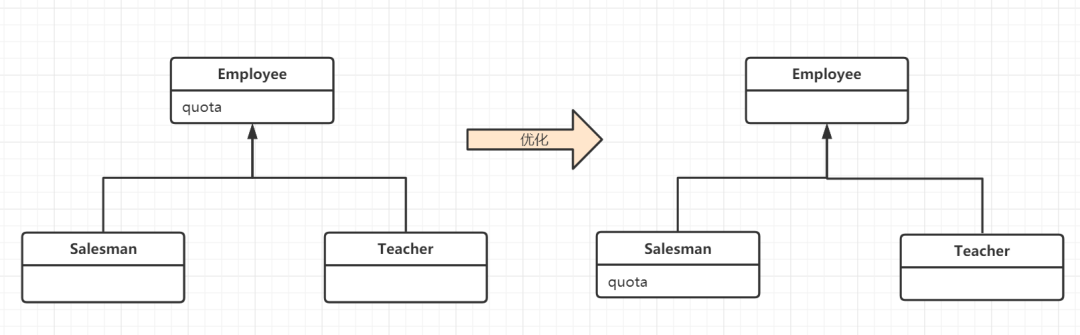
21. Refused Bequest (被拒绝的馈赠)
子类应该继承父类的数据和函数。子类继承得到所有函数和数据,却只使用了几个,那就是继承体系设计错误,需要优化。
-
需要为这个子类新建一个兄弟类->
Push Down Method和Push Down Field把所有用不到的函数下推给兄弟类,这样一来,超类就只持有所有子类共享的东西。所有超类都应该是抽象的。 -
如果子类复用了超类的实现,又不愿意支持超类的接口,可以不以为然。但是不能胡乱修改继承体系->
Replace Inheritance with Delegation(用委派替换继承).
22. Comments (过多的注释)
这个点不是说代码不建议写注释哦,而是,建议大家避免用注释解释代码,避免过多的注释。这些都是常见注释的坏味道:
-
多余的解释
-
日志式注释
-
用注释解释变量等
-
...
如何优化呢?
-
方法函数、变量的命名要规范、浅显易懂、避免用注释解释代码。
-
关键、复杂的业务,使用清晰、简明的注释
23. 神奇命名
方法函数、变量、类名、模块等,都需要简单明了,浅显易懂。避免靠自己主观意识瞎起名字。
反例:
boolean test = chenkParamResult(req);
正例:
boolean isParamPass = chenkParamResult(req);
24. 神奇魔法数
日常开发中,经常会遇到这种代码:
if(userType==1){
//doSth1
}else If( userType ==2){
//doSth2
}
...
代码中的这个1和2都表示什么意思呢?再比如setStatus(1)中的1又表示什么意思呢?看到类似坏代码,可以这两种方式优化:
-
新建个常量类,把一些常量放进去,统一管理,并且写好注释;
-
建一个枚举类,把相关的魔法数字放到一起管理。
25. 混乱的代码层次调用
我们代码一般会分dao层、service层和controller层。
-
dao层主要做数据持久层的工作,与数据库打交道。
-
service层主要负责业务逻辑处理。
-
controller层负责具体的业务模块流程的控制。
所以一般就是controller调用service,service调dao。如果你在代码看到controller直接调用dao,那可以考虑是否优化啦。反例如下:
@RestController("user")
public class UserController {
Autowired
private UserDao userDao;
@RequestMapping("/queryUserInfo")
public String queryUserInfo(String userName) {
return userDao.selectByUserName(userName);
}
}
以面向对象思想处理字符串:Joiner/Splitter/CharMatcher
JDK提供的String还不够好么?
也许还不够友好,至少让我们用起来还不够爽,还得操心!
举个栗子,比如String提供的split方法,我们得关心空字符串吧,还得考虑返回的结果中存在null元素吧,只提供了前后trim的方法(如果我想对中间元素进行trim呢)。
那么,看下面的代码示例,guava让你不必在操心这些:
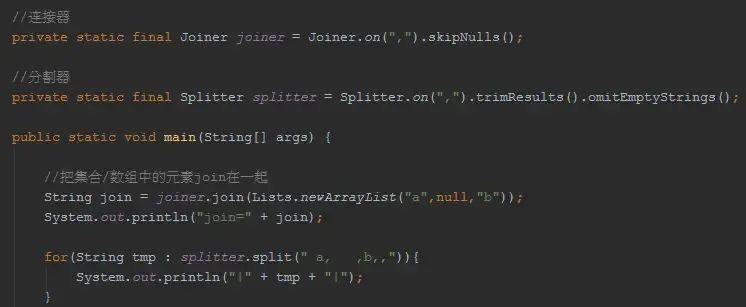
Joiner/Splitter
Joiner是连接器,Splitter是分割器,通常我们会把它们定义为static final,利用on生成对象后在应用到String进行处理,这是可以复用的。要知道apache commons StringUtils提供的都是static method。更加重要的是,guava提供的Joiner/Splitter是经过充分测试,它的稳定性和效率要比apache高出不少,这个你可以自行测试下~
发现没有我们想对String做什么操作,就是生成自己定制化的Joiner/Splitter,多么直白,简单,流畅的API!
对于Joiner,常用的方法是 跳过NULL元素:skipNulls() / 对于NULL元素使用其他替代:useForNull(String)
对于Splitter,常用的方法是:trimResults()/omitEmptyStrings()。注意拆分的方式,有字符串,还有正则,还有固定长度分割(太贴心了!)
其实除了Joiner/Splitter外,guava还提供了字符串匹配器:CharMatcher
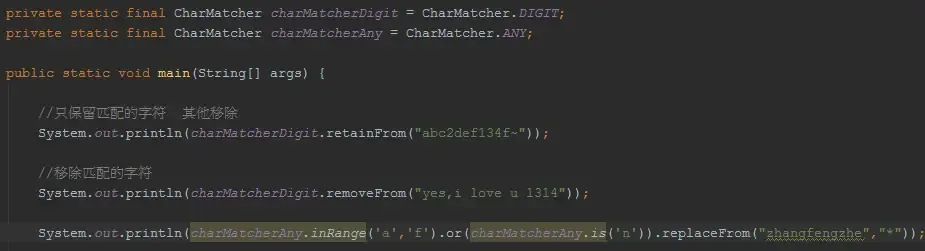
CharMatcher,将字符的匹配和处理解耦,并提供丰富的方法供你使用!
对基本类型进行支持
guava对JDK提供的原生类型操作进行了扩展,使得功能更加强大!
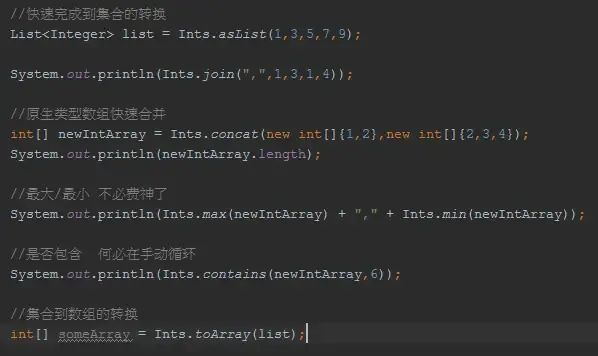
guava提供了Bytes/Shorts/Ints/Iongs/Floats/Doubles/Chars/Booleans这些基本数据类型的扩展支持,只有你想不到的,没有它没有的!
对JDK集合的有效补充
灰色地带:Multiset
JDK的集合,提供了有序且可以重复的List,无序且不可以重复的Set。那这里其实对于集合涉及到了2个概念,一个order,一个dups。那么List vs Set,and then some ?
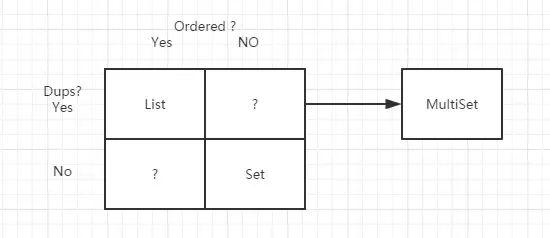
Multiset是什么,我想上面的图,你应该了解它的概念了。Multiset就是无序的,但是可以重复的集合,它就是游离在List/Set之间的“灰色地带”!(至于有序的,不允许重复的集合嘛,guava还没有提供,当然在未来应该会提供UniqueList,我猜的,哈哈)
来看一个Multiset的示例:
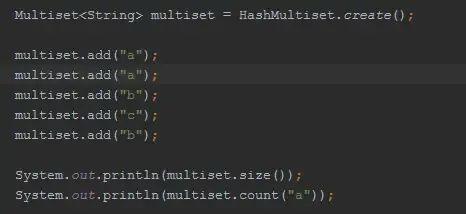
Multiset自带一个有用的功能,就是可以跟踪每个对象的数量。
Immutable vs unmodifiable
来我们先看一个unmodifiable的例子:
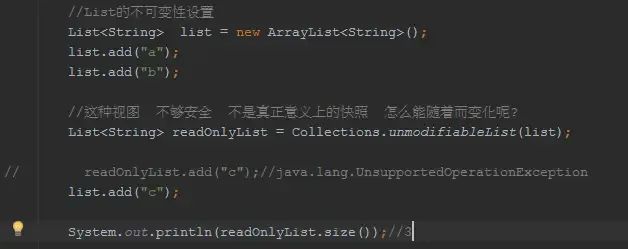
你看到JDK提供的unmodifiable的缺陷了吗?
实际上,Collections.unmodifiableXxx所返回的集合和源集合是同一个对象,只不过可以对集合做出改变的API都被override,会抛出UnsupportedOperationException。
也即是说我们改变源集合,导致不可变视图(unmodifiable View)也会发生变化,oh my god!
当然,在不使用guava的情况下,我们是怎么避免上面的问题的呢?
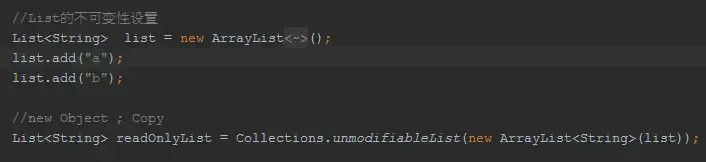
上面揭示了一个概念:Defensive Copies,保护性拷贝。
OK,unmodifiable看上去没有问题呢,但是guava依然觉得可以改进,于是提出了Immutable的概念,来看:
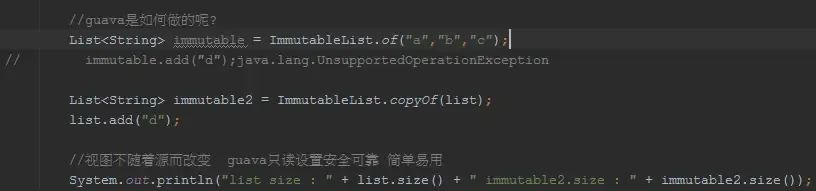
就一个copyOf,你不会忘记,如此cheap~
用Google官方的说法是:we're using just one class,just say exactly what we mean,很了不起吗(不仅仅是个概念,Immutable在COPY阶段还考虑了线程的并发性等,很智能的!),O(∩_∩)O哈哈~
guava提供了很多Immutable集合,比如ImmutableList/ImmutableSet/ImmutableSortedSet/ImmutableMap/......
看一个ImmutableMap的例子:

可不可以一对多:Multimap
JDK提供给我们的Map是一个键,一个值,一对一的,那么在实际开发中,显然存在一个KEY多个VALUE的情况(比如一个分类下的书本),我们往往这样表达:Map<k,List<v>>,好像有点臃肿!臃肿也就算了,更加不爽的事,我们还得判断KEY是否存在来决定是否new 一个LIST出来,有点麻烦!更加麻烦的事情还在后头,比如遍历,比如删除,so hard......
来看guava如何替你解决这个大麻烦的:
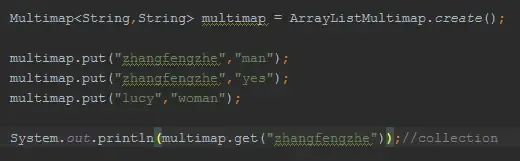
友情提示下,guava所有的集合都有create方法,这样的好处在于简单,而且我们不必在重复泛型信息了。
get()/keys()/keySet()/values()/entries()/asMap()都是非常有用的返回view collection的方法。
Multimap的实现类有:ArrayListMultimap/HashMultimap/LinkedHashMultimap/TreeMultimap/ImmutableMultimap/......
可不可以双向:BiMap
JDK提供的MAP让我们可以find value by key,那么能不能通过find key by value呢,能不能KEY和VALUE都是唯一的呢。这是一个双向的概念,即forward+backward。
在实际场景中有这样的需求吗?比如通过用户ID找到mail,也需要通过mail找回用户名。没有guava的时候,我们需要create forward map AND create backward map,and now just let guava do that for you.
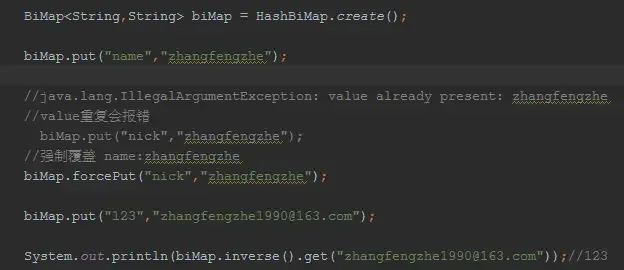
biMap / biMap.inverse() / biMap.inverse().inverse() 它们是什么关系呢?
你可以稍微看一下BiMap的源码实现,实际上,当你创建BiMap的时候,在内部维护了2个map,一个forward map,一个backward map,并且设置了它们之间的关系。
因此,biMap.inverse() != biMap ;biMap.inverse().inverse() == biMap
可不可以多个KEY:Table
我们知道数据库除了主键外,还提供了复合索引,而且实际中这样的多级关系查找也是比较多的,当然我们可以利用嵌套的Map来实现:Map<k1,Map<k2,v2>>。为了让我们的代码看起来不那么丑陋,guava为我们提供了Table。
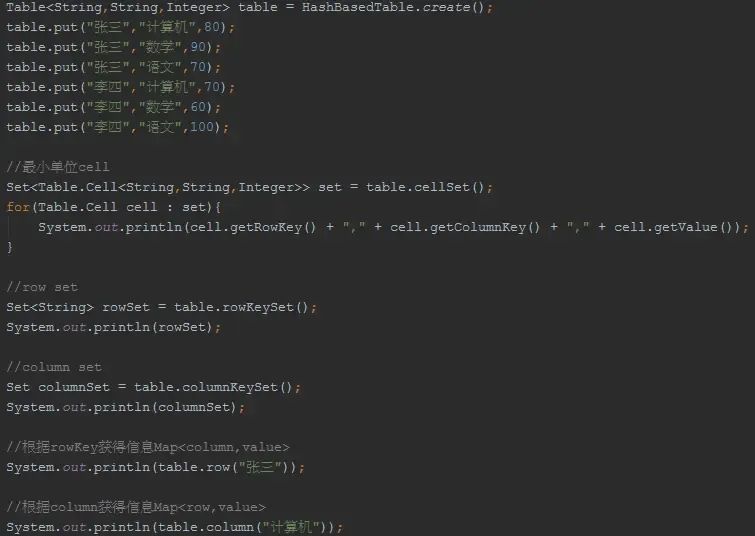
Table涉及到3个概念:rowKey,columnKey,value,并提供了多种视图以及操作方法让你更加轻松的处理多个KEY的场景。
函数式编程:Functions
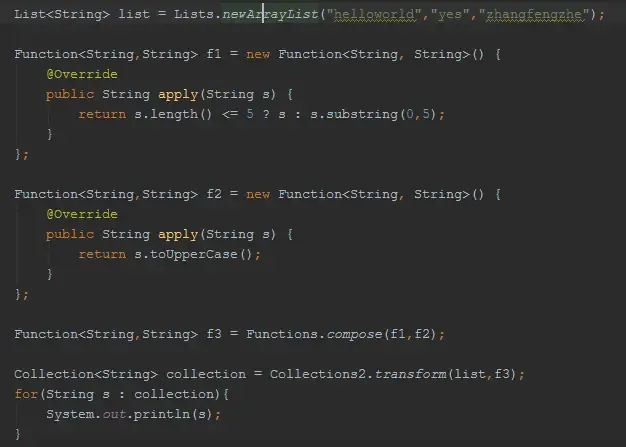
上面的代码是为了完成将List集合中的元素,先截取5个长度,然后转成大写。
函数式编程的好处在于在集合遍历操作中提供自定义Function的操作,比如transform转换。我们再也不需要一遍遍的遍历集合,显著的简化了代码!

对集合的transform操作可以通过Function完成
断言:Predicate
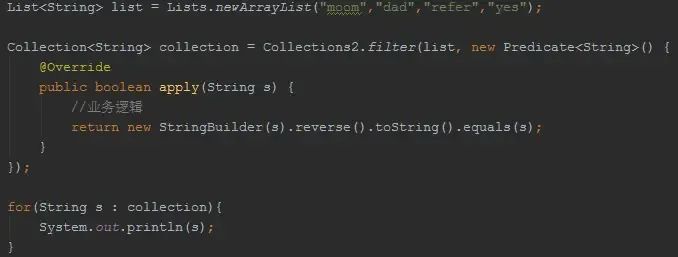
Predicate最常用的功能就是运用在集合的过滤当中!

需要注意的是Lists并没有提供filter方法,不过你可以使用Collections2.filter完成!
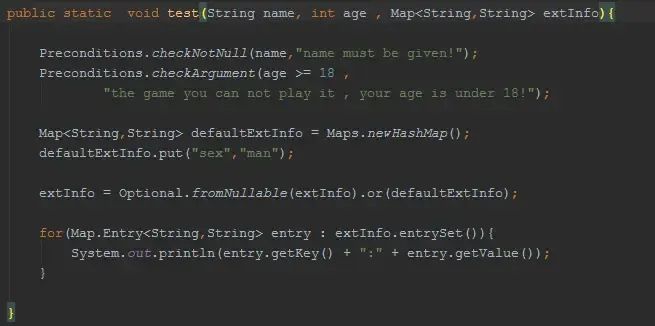
check null and other:Optional、Preconditions
在guava中,对于null的处理手段是快速失败,你可以看看guava的源码,很多方法的第一行就是:Preconditions.checkNotNull(elements);
要知道null是模糊的概念,是成功呢,还是失败呢,还是别的什么含义呢?
Cache is king
对于大多数互联网项目而言,缓存的重要性,不言而喻!
如果我们的应用系统,并不想使用一些第三方缓存组件(如redis),我们仅仅想在本地有一个功能足够强大的缓存,很可惜JDK提供的那些SET/MAP还不行!
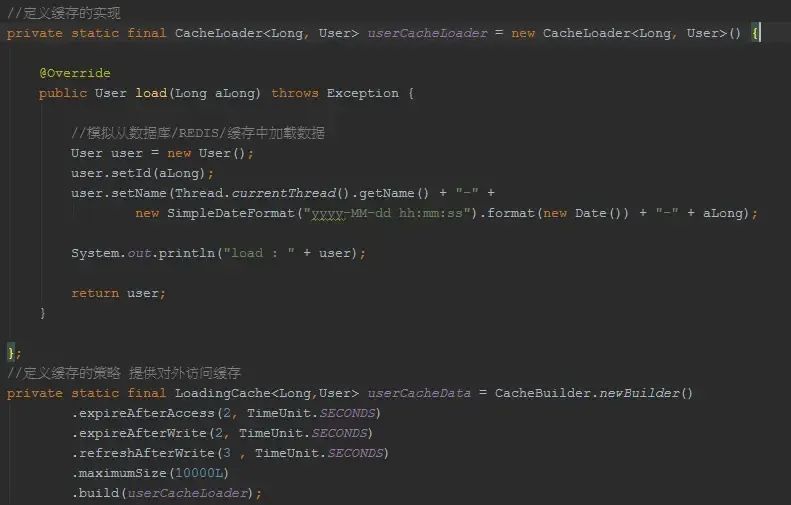
首先,这是一个本地缓存,guava提供的cache是一个简洁、高效,易于维护的。为什么这么说呢?因为并没有一个单独的线程用于刷新 OR 清理cache,对于cache的操作,都是通过访问/读写带来的,也就是说在读写中完成缓存的刷新操作!
其次,我们看到了,我们非常通俗的告诉cache,我们的缓存策略是什么,SO EASY!在如此简单的背后,是guava帮助我们做了很多事情,比如线程安全。
让异步回调更加简单
JDK中提供了Future/FutureTask/Callable来对异步回调进行支持,但是还是看上去挺复杂的,能不能更加简单呢?比如注册一个监听回调。
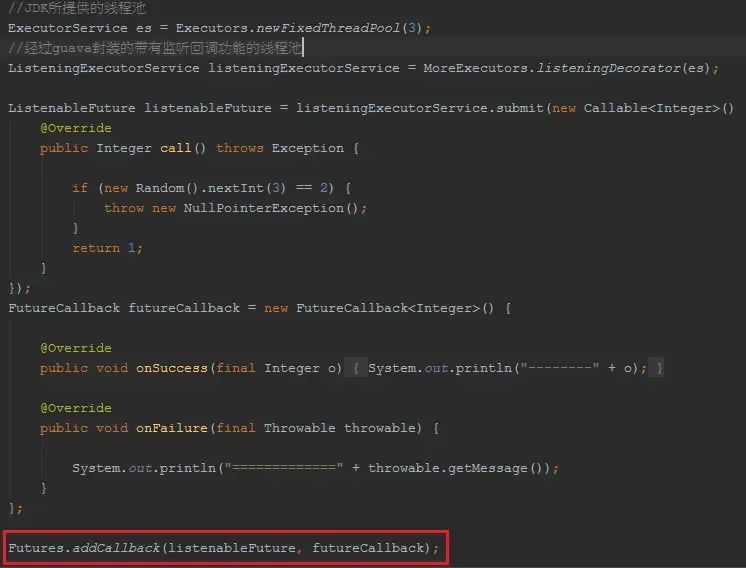
我们可以通过guava对JDK提供的线程池进行装饰,让其具有异步回调监听功能,然后在设置监听器即可!
比如反射、注解、网络、并发、IO等等
参考与感谢
-
软工实验:常见的代码坏味道以及重构举例[2]
-
22种代码的坏味道,一句话概括[3]
-
【重构】 代码的坏味道总结 Bad Smell[4]
-
Code Smell[5]
-
《重构改善既有代码的设计》
-
田螺哥
46、及时跟同事沟通
写代码的时候不能闭门造车,及时跟同事沟通,比如刚进入一个新的项目,对项目工程不熟悉,一些技术方案不了解,如果上来就直接写代码,很有可能就会踩坑。
单元测试

作为一个开发,我相信大部分人应该都写过单元测试,单元测试的好处我就不再多说了,提高代码质量、增加代码的可维护性、提升效率,减少测试成本等等。但是怎么样的单元测试才是一个比较好的,或者说有效的单元测试呢,下面我分享几点我写单元测试的一些经验。
首先我们写单元测试的一个比较核心的需求是,验证代码逻辑的正确性。不管是新增逻辑,亦或是原有的代码变更,都希望可以通过单元测试可以帮助我们提前发现问题。假设我们开发了一个登录模块,那我们可能的单元测试可能是这样的:
publicclass LoginTest {
private AuthService authService;
public void login() {
String username = "testUser";
String password = "********";
UserToken token = authService.login(username, password);
System.out.println(token);
}
}
每个测试用例,我们应该给它定义一个有意义的命名,这样便于我们后期维护,在进行方法命名时,我们可以通过 输入、动作、输出 的规则来定义,这样可以通过方法名,明确的知道这个单元测试需要什么输入,进行了什么操作,应该输出怎么样的结果,比如:
public void givenUserNameAndPassword_whenLogin_returnToken() {
String username = "testUser";
String password = "********";
UserToken userToken = authService.login(username, password);
System.out.println(userToken);
}
这部分参考BDD(Behavior-driven development,行为驱动开发)的定义,由关键字
Given,When,Then,And,But(steps)来定义某一个场景的具体步骤。
结果校验
每个单元测试,理论上都应该有一个期望值,那么我们就需要校验实际结果和期望值,通过 Assert(断言)来校验我们的测试结果,而不是只是打印结果。
public void givenUserNameAndPassword_whenLogin_returnToken() {
String username = "testUser";
String password = "********";
UserToken userToken = authService.login(username, password);
System.out.println(userToken);
String expectUserId = "001";
String realUserId = userToken.getUserId();
Assertions.assertNotNull(userToken.getToken(), "登录token不应该为空");
Assertions.assertEquals(expectUserId, realUserId, "登录用户ID不正确");
}
在对比结果时,最好可以使用有意义的变量名来对比,增加代码的可读性。
题外话:我在不同的公司时几乎都见到过单元测试中使用打印的方式来验证结果,即使错误,单元测试也可以正常运行,全靠人眼识别。
用例粒度
我们每个单元测试,除了集成测试之外,功能的粒度尽可能的小,即每个功能点一个用例,不要在一个测试用例中,堆了一大堆功能,这样做的好处是什么? 当我们某个功能点出现问题的时候,可以快速的定位到对应的异常功能,而不需要在一个超级大的用例中去排查到底是哪个功能出了问题。
一个单元测试用例最好只对应一个特定的场景
主流程集成测试
除了上面我们所说的功能点用例外,我们需要针对我们的产品中的核心流程、主要流程进行场景化的测试,即我们需要模拟用户的实际使用情况,来编排测试用例。因为即使我们每个功能点都没有问题,但并不意味着把它们整合在一起就没有问题。
public void givenUserInfo_whenRegisterAndLogin_returnToken() {
User user = User.mock();
User created = userService.register(user);
Assertions.assertNotNull(created, "注册用户失败");
String username = created.getUsername();
String password = created.getPassword();
UserToken userToken = authService.login(username, password);
String expectUserId = created.getId();
String realUserId = userToken.getUserId();
Assertions.assertNotNull(userToken.getToken(), "登录token不应该为空");
Assertions.assertEquals(expectUserId, realUserId, "登录用户ID不正确");
}
为什么只考虑核心流程和主要流程? 因为这种场景化的单测太难写了,我个人来说能写个核心流程与主流程已经算是比较勤勉了。
可重复运行
单元测试,如果它们不可以重复运行,那么测试结果可能不准确,并且如果每次运行都要手动去修改数据,或者准备环境,我相信没几个人可以常态化利用起来,十分低效,因此我们在写单元测试时,需要保证它们可重复运行。
publicclass LoginTest {
private AuthService authService;
private UserService userService;
public MySQLContainer mysqlContainer = new MySQLContainer<>(DockerImageName.parse("mysql:8.0-debian")).withExposedPorts(3306);
public void dynamicProperties(DynamicPropertyRegistry registry) {
registry.add("spring.datasource.url", () -> mysqlContainer.getJdbcUrl());
registry.add("spring.datasource.driverClassName", () -> mysqlContainer.getDriverClassName());
registry.add("spring.datasource.username", () -> mysqlContainer.getUsername());
registry.add("spring.datasource.password", () -> mysqlContainer.getPassword());
}
public void givenUserInfo_whenRegisterAndLogin_returnToken() {
User user = User.mock();
User created = userService.register(user);
Assertions.assertNotNull(created, "注册用户失败");
String username = created.getUsername();
String password = created.getPassword();
UserToken userToken = authService.login(username, password);
String expectUserId = created.getId();
String realUserId = userToken.getUserId();
Assertions.assertNotNull(userToken.getToken(), "登录token不应该为空");
Assertions.assertEquals(expectUserId, realUserId, "登录用户ID不正确");
}
}
我们通过 隔离的数据环境,以及 mock依赖服务等手段,保证每次操作都是独立的,即同样的输入在代码没有问题的情况上,理论上都会获取到同样的结果。
覆盖率
单元测试的覆盖率当然是越高越好,如果能做到100%,那简直太完美了,但是这个想法也是太理想了。 这个可以根据每个人的项目实际情况来决定,但是最少要达到 70%效果才会比较明显。覆盖可以通过一些三方框架来检测,比如 JaCoCo。
最后,跑起来
我们做了这么多的工作,最终也只有跑起来才能够看到效果,所以在maven打包的时候,不要在 maven.test.skip=true了,让测试跑起来。如果可以的话,把单元测试加到我们的CI/CD流程中,只有常态化的用起来,才可以真正的产生效果。
上面这些只是我在进行代码质量实践时的一些经验,并不适用于所有人或者场景,但是不管我们可以做到多少,怎么做, 只要开始写单元测试了,那么我们的代码质量就一定会没写时更高。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











