










概叙
什么是RDMA?
RDMA(Remote Direct Memory Access),全称远端内存直接访问技术,可以在极少占用CPU的情况下,把数据从一台服务器传输到另一台服务器,或从存储到服务器。
科普文:软件架构网络系列之【高性能网络/存储之基础:TCP/IP、DMA、RDMA、Infiniband、RoCE、iWARP】-CSDN博客
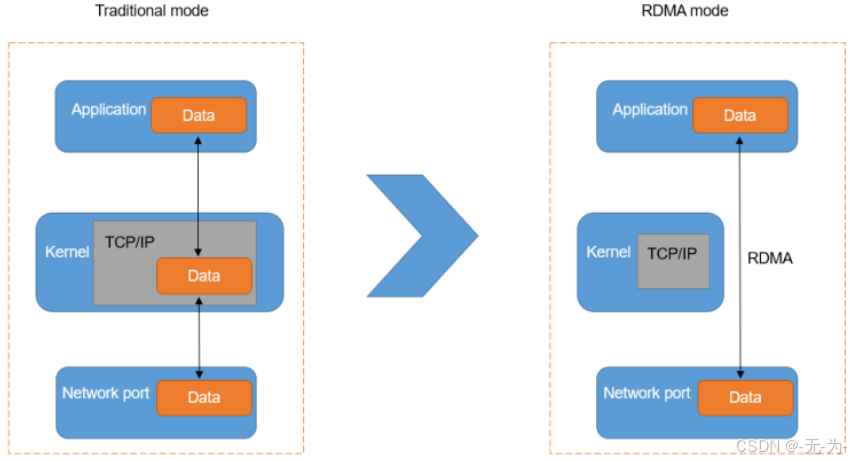
传统应用要发送数据,需要通过OS封装TCP/IP,然后依次经过主缓存、网卡缓存,再发出去。这样会导致两个限制。
- 限制一:TCP/IP协议栈处理会带来数10微秒的时延。TCP协议栈在接收发送报文时,内核需要做多次上下文的切换,每次切换需要耗费5-10微秒。另外还需要至少三次的数据拷贝和依赖CPU进行协议工作,这导致仅仅协议上处理就会带来数10微秒的固定时延,协议栈时延成为最明显的瓶颈。
- 限制二:TCP协议栈处理导致服务器CPU负载居高不下。除了固定时延较长的问题,TCP/IP网络需要主机CPU多次参与协议的内存拷贝,网络规模越大,网络带宽越高,CPU在收发数据时的调度负担越大,导致CPU持续高负载。
举例来说,40Gbps 的 TCP/IP 流能耗尽主流服务器的所有 CPU 资源;而在使用 RDMA 的 40Gbps 场景下,CPU 占用率从 100%下降到 5%,网络时延从ms 级降低到 10μs 以下。
RDMA 的内核旁路机制允许应用与网卡之间的直接数据读写,规避了 TCP/IP 的限制,将协议栈时延降低到接近 1us;同时,RDMA 的内存零拷贝机制,允许接收端直接从发送端的内存读取数据,极大的减少了 CPU 的负担,提升CPU 的效率。
在数据中心内部,超大规模分布式计算存储资源之间,如果使用传统的TCP/IP进行网络互连,将占用系统大量的计算资源,造成IO瓶颈,无法满足更高吞吐,更低时延的网络需求。
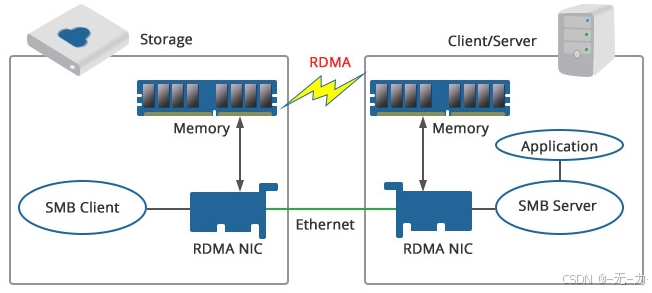
RDMA是一种高带宽、低延迟、低CPU消耗的网络互联技术,克服了传统TCP/IP网络的许多困难。
科普文:软件架构网络系列之【优化 RDMA 代码的建议和技巧】-CSDN博客
科普文:软件架构网络系列之【RDMA技术概览:特点、优缺点与应用场景】-CSDN博客
科普文:软件架构网络系列之【详解RDMA 技术架构与实践】-CSDN博客
- Remote(远程):数据在网络中的两个节点之间传输。
- Direct(直接):不需要内核参与,传输的所有处理都卸载到NIC硬件中完成。
- Memory(内存):数据直接在两个节点的应用程序的虚拟内存间传输;不需要额外的复制和缓存。
- Access(访问):访问操作有send/receive、read/write等。
如何理解RDMA和TCP技术的区别?
传统的TCP/IP方式就像是人工收费一样,需要取卡,人工核实,手动缴费,找零钱等等才能完成汽车上下高速。在车辆很多的情况下就会出现排队的情况,很浪费时间。
而RDMA则像是ETC,跳过人工取卡,收费等步骤,直接刷卡,极速通过。既节省了时间,又节省了人力。
RDMA相比TCP/IP,既降低了对计算资源的占用,又提升了数据的传输速率。
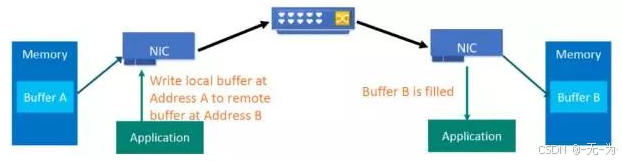
RDMA的内核旁路机制允许应用与网卡之间的直接数据读写,这样可以将服务器内的数据传输时延降低到接近1微秒。同时,RDMA的内存零拷贝机制允许接收端直接从发送端的内存读取数据,极大地减少了CPU的负担,提高了CPU的利用率。
使用RDMA的好处包括:
- 内存零拷贝(Zero Copy):RDMA应用程序可以绕过内核网络栈直接进行数据传输,不需要再将数据从应用程序的用户态内存空间拷贝到内核网络栈内存空间。
- 内核旁路(Kernel bypass):RDMA应用程序可以直接在用户态发起数据传输,不需要在内核态与用户态之间做上下文切换。
- CPU减负(CPU offload):RDMA可以直接访问远程主机内存,不需要消耗远程主机中的任何CPU,这样远端主机的CPU可以专注自己的业务,避免其cache被干扰并充满大量被访问的内存内容。
RDMA的三大协议实现
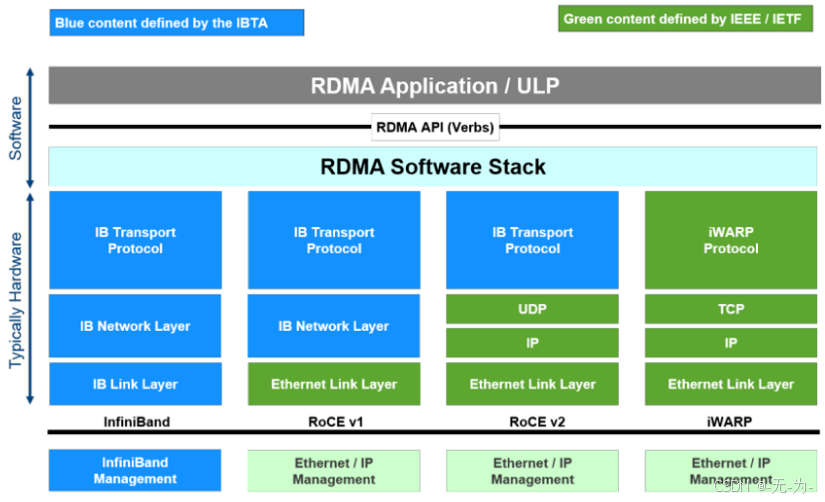
RDMA协议包含Infiniband(IB),internet Wide Area RDMA Protocol(iWARP)和RDMA over Converged Ethernet(RoCE):
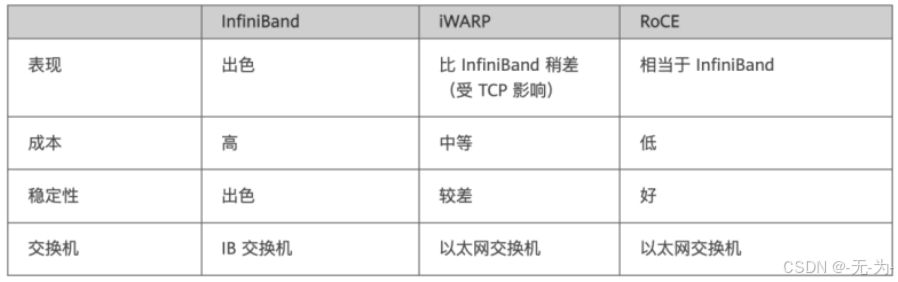
- InfiniBand:设计之初就考虑了 RDMA,重新设计了物理链路层、网络层、传输层,从硬件级别,保证可靠传输,提供更高的带宽和更低的时延。但是成本高,需要支持IB网卡和交换机。
- iWARP:基于TCP的RDMA网络,利用TCP达到可靠传输。相比RoCE,在大型组网的情况下,iWARP的大量TCP连接会占用大量的内存资源,对系统规格要求更高。可以使用普通的以太网交换机,但是需要支持iWARP的网卡。
- RoCE:基于 Ethernet的RDMA,RoCEv1版本基于网络链路层,无法跨网段,基本无应用。RoCEv2基于UDP,可以跨网段具有良好的扩展性,而且可以做到吞吐,时延相对性能较好,所以是大规模被采用的方案。RoCE消耗的资源比 iWARP 少,支持的特性比 iWARP 多。可以使用普通的以太网交换机,但是需要支持RoCE的网卡。

比较这三种技术,iWarp 由于其失去了最重要的 RDMA 的性能优势,已经逐渐被业界所抛弃。
InfiniBand 的性能最好,但是由于 InfiniBand 作为专用的网络技术,无法继承用户在 IP 网络上运维的积累和平台,企业引入 InfiniBand 需要重新招聘专人的运维人员,而且当前 InfiniBand 只有很少的市场空间(不到以太网的 1%),业内有经验的运维人员严重缺乏,网络一旦出现故障,甚至无法及时修复,OPEX 极高。
因此基于传统的以太网络来承载 RDMA,也是 RDMA 大规模应用的必然。为了保障 RDMA 的性能和网络层的通信,使用 RoCEv2 承载高性能分布式应用已经成为一种趋势。
科普文:软件架构网络系列之【RDMA 能给数据中心带来什么:数据中心网络最佳选择是RoCEv2不是InfiniBand】-CSDN博客
科普文:软件架构网络系列之【RDMA技术实现之RoCEv2:TCP的变革者还是取而代之者】-CSDN博客
科普文:软件架构网络系列之【RDMA 能给数据中心带来什么】-CSDN博客
科普文:软件架构网络系列之【RDMA 能给数据中心带来什么:可靠传输 RoCEv2】-CSDN博客
什么是RoCE?
RDMA over Converged Ethernet(RoCE)协议是一种能在以太网上进行RDMA(远程内存直接访问)的集群网络通信协议,它大大降低了以太网通信的延迟,提高了带宽的利用率。

它将收/发包的工作卸载(offload)到了网卡上,不需要像TCP/IP协议一样使系统进入内核态,减少了拷贝、封包解包等等的开销。这样大大降低了以太网通信的延迟,减少了通讯时对CPU资源的占用,缓解了网络中的拥塞,让带宽得到更有效的利用。
从 2010 年开始,RMDA 开始引起越来越多的关注,当时IBTA发布了第一个在融合以太网 (RoCE) 上运行 RMDA 的规范。然而,最初的规范将 RoCE 部署限制在单个第 2 层域,因为 RoCE 封装帧没有路由功能。
2014 年,IBTA 发布了 RoCEv2,它更新了最初的 RoCE 规范以支持跨第 3 层网络的路由,使其更适合超大规模数据中心网络和企业数据中心等。
RoCE:基于 Ethernet的RDMA,RoCEv1版本基于网络链路层,无法跨网段,基本无应用。RoCEv2基于UDP,可以跨网段具有良好的扩展性,而且可以做到吞吐,时延相对性能较好,所以是大规模被采用的方案。
RoCE消耗的资源比 iWARP 少,支持的特性比 iWARP 多。可以使用普通的以太网交换机,但是需要支持RoCE的网卡。
为什么RoCE是目前主流的RDMA协议?
先说iWARP,iWARP协议栈相比其他两者更为复杂,并且由于TCP的限制,只能支持可靠传输。所以iWARP的发展不如RoCE和Infiniband。
而Infiniband协议本身定义了一套全新的层次架构,从链路层到传输层,都无法与现有的以太网设备兼容。
举例来看,如果某个数据中心因为性能瓶颈,想要把数据交换方式从以太网切换到Infiniband技术,那么需要购买全套的Infiniband设备,包括网卡、线缆、交换机和路由器等等,成本太高.
RoCE协议的优势在这里就很明显了,用户从以太网切换到RoCE只需要购买支持RoCE的网卡就可以了,其他网络设备都是兼容的。所以RoCE相比于Infiniband主要优势在于成本更低。
RoCE v2与InfiniBand技术对比
RoCE v2和InfiniBand均为数据中心及高性能计算环境而设计,旨在提供高速、低延迟的通信解决方案。以下将从不同层面剖析两者的关键差异。
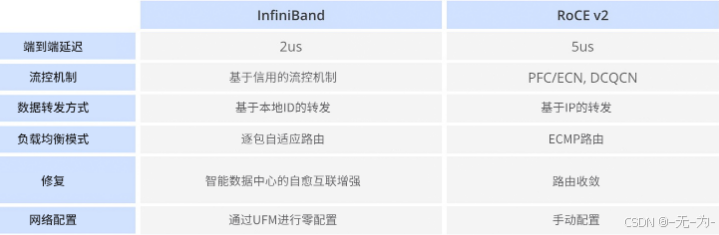
物理层架构
-
RoCE v2:依托现有的以太网基础设施,能够在同一网络中整合存储数据流和常规数据流,更易融入既有的数据中心架构。
-
InfiniBand:采用独立于以太网的专有通信架构,通常需要专门构建的InfiniBand网络,并可能涉及独立布线和专用交换机设备的部署。
协议栈与网络协议兼容性
-
RoCE v2:通过以太网实现RDMA功能,能够与传统的TCP/IP协议栈无缝集成,确保兼容性。
-
InfiniBand:配备了一套专为高速、低延迟传输优化定制的自有协议栈和网络架构,使用时可能需要特定的驱动程序和配置。
交换机制
-
RoCE v2:可在支持数据中心桥接(DCB)特性的标准以太网交换机上运行,实现无损以太网的数据传输。
-
InfiniBand:依赖于专为低延迟和高吞吐量而设计的InfiniBand交换机,确保出色的性能表现。
拥塞管理与控制
-
RoCE v2:依赖于以太网交换机的DCB特性来应对网络拥塞,通过创建无损以太网环境以避免丢包问题。但其本身不提供内置解决方案,主要依靠底层以太网基础设施的功能来管理和缓解拥塞现象。
-
InfiniBand:具备原生的拥塞控制能力,能够通过信用流控等机制保障通信过程中的数据完整性。同时整合自适应路由和先进的拥塞控制算法,能够根据实时网络状况动态调整数据传输链路,有效预防和减轻网络拥塞。
路由机制与拓扑结构
-
RoCE v2:通常采用传统的以太网路由协议进行路由决策,如路由信息协议(RIP)或开放最短路径优先(OSPF)。但其路由策略的制定和执行受限于底层以太网基础设施,需考虑现有的以太网架构特点来进行路由优化。
-
InfiniBand:具备针对低延迟、高吞吐量通信特别优化的路由机制,支持多路径设定以实现网络冗余及负载均衡。同时支持多种配置方式,具备更灵活的拓扑结构。
选择RoCE v2或InfiniBand的决策取决于现有的基础设施条件、特定应用需求以及实际环境的具体性能指标。
RoCE v2的主要优势在于能够无缝集成到已有的以太网网络架构中,适用于希望提升数据通信效率而不改变现有网络基础的企业。
而InfiniBand专为低延迟和高吞吐量设计,并配备了内置的路由优化和拥塞控制机制,适用于高度可扩展性的高性能计算场景。
目前主流的RDMA协议:RoCE详解
RoCE的诞生

RoCE,允许应用通过以太网实现远程内存访问的网络协议,也是由 IBTA 提出,是将 RDMA 技术运用到以太网上的协议。同样支持在标准以太网交换机上使用RDMA,只需要支持 RoCE 的特殊网卡,网络硬件侧无要求。
目前 RoCE 有两个协议版本,RoCEv1 和 RoCEv2:
- RoCEv1 是一种链路层协议,允许在同一个广播域下的任意两台主机直接访问;
- RoCEv2 是一种网络层协议,可以实现路由功能,允许不同广播域下的主机通过三层访问,是基于 UDP 协议封装的。但由于RDMA 对丢包敏感的特点,而传统以太网又是尽力而为存在丢包问题,所以需要交换机支持无损以太网。
RoCE协议存在RoCEv1和RoCEv2两个版本,这取决于所使用的网络适配器或网卡。
- RoCE v1:RoCE v1是基于以太网链路层实现的RDMA协议(交换机需要支持PFC等流控技术,在物理层保证可靠传输),允许在同一个VLAN中的两台主机进行通信。RoCE V1协议在以太层的typeID是0x8915。
- RoCE v2:RoCE v2克服了RoCE v1绑定到单个VLAN的限制。通过改变数据包封装,包括IP和UDP标头,RoCE v2现在可以跨L2和L3网络使用。
RDMA 对于丢包是非常敏感的。
TCP 协议丢包重传是大家都熟悉的机制,TCP 丢包重传是精确重传,发生重传时会去除接收端已接收到的报文,减少不必要的重传,做到丢哪个报文重传哪个。然而 RDMA 协议中,每次出现丢包,都会导致整个 message 的所有报文都重传。
另外,RoCEv2 是基于无连接协议的UDP 协议,相比面向连接的 TCP 协议,UDP 协议更加快速、占用 CPU 资源更少,但其不像 TCP 协议那样有滑动窗口、确认应答等机制来实现可靠传输,一旦出现丢包,RoCEv2 需要依靠上层应用检查到了再做重传,会大大降低 RDMA 的传输效率。
因此 RDMA 在无损状态下可以满速率传输,而一旦发生丢包重传,性能会急剧下降。
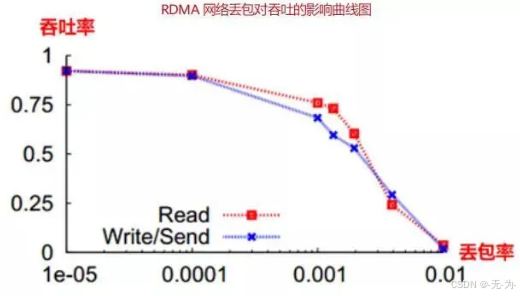
大于 0.001 的丢包率,将导致网络有效吞吐急剧下降。0.01 的丢包率即使得 RDMA 的吞吐率下降为 0,要使得 RDMA 吞吐不受影响,丢包率必须保证在 1e-05(十万分之一)以下,最好为零丢包。
RoCEv2 是将 RDMA 运行在传统以太网上,传统以太网是尽力而为的传输模式,无法做到零丢包,所以为了保证 RDMA 网络的高吞吐低时延,需要交换机支持无损以太网技术。
RoCE 则使用 UDP协议。根据 RoCEv2 规范,应该使用无损架构。不过RoCE 协议内部存在一种防范丢包的机制:发生丢包时,将把具有特定数据包序号 (PSN) 的 NACK 控制包发送给发送方,以供发送方重新发送该数据包。因此,所谓 RoCE 要求无损网络传输(无损以太网)的说法并不完全正确。RoCE 可以在无损网络或有损网络中运行。
RoCE报文格式
RoCEv1
2010年4月,IBTA发布了RoCE,此标准是作为Infiniband Architecture Specification的附加件发布的,所以也称为IBoE(InfiniBand over Ethernet)。这时的RoCE标准是在以太链路层之上用IB网络层代替了TCP/IP网络层,所以不支持IP路由功能。RoCE V1协议在以太层的typeID是0x8915。
在RoCE中,infiniband的链路层协议头被去掉,用来表示地址的GUID被转换成以太网的MAC。Infiniband依赖于无损的物理传输,RoCE也同样依赖于无损的以太传输,这一要求会给以太网的部署带来了成本和管理上的开销。
以太网的无损传输必须依靠L2的QoS支持,比如PFC(Priority Flow Control),接收端在buffer池超过阈值时会向发送方发出pause帧,发送方MAC层在收到pause帧后,自动降低发送速率。这一要求,意味着整个传输环节上的所有节点包括end、switch、router,都必须全部支持L2 QoS,否则链路上的PFC就不能在两端发挥有效作用。
RoCEv2
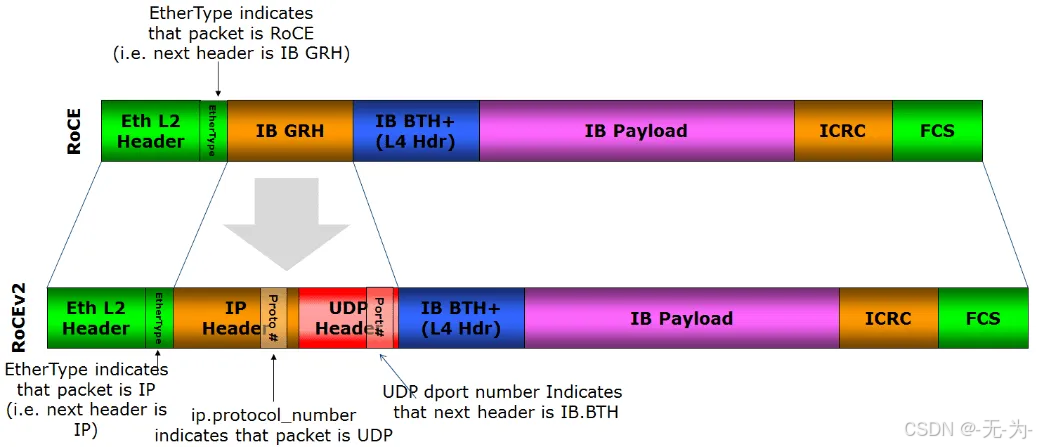
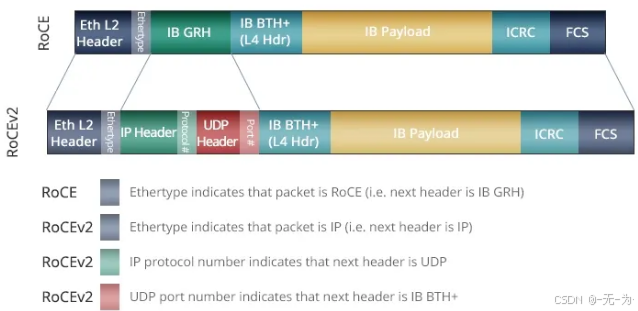
由于RoCEv1的数据帧不带IP头部,所以只能在L2子网内通信。为了解决此问题,IBTA于2014年提出了RoCE V2,RoCEv2扩展了RoCEv1,将GRH(Global Routing Header)换成UDP header + IP header,扩展后的帧结构如下图所示。
针对RoCE v1和RoCE v2,以下两点值得注意:
-
RoCE v1(Layer 2)运作在Ehternet Link Layer(Layer 2)所以Ethertype 0x8915,所以正常的Frame大小为1500 bytes,而Jumbo Frame则是9000 bytes。
-
RoCE v2(Layer 3)运作在UDP/IPv4或UDP/IPv6之上(Layer 3),采用UDP Port 4791进行传输。因为 RoCE v2的封包是在 Layer 3上可进行路由,所以有时又会称为Routable RoCE或简称RRoCE。
RoCE v2的基本特性
- IPv4和IPv6支持:RoCE v2不仅支持IPv4,还在协议设计上增加了对IPv6的支持,使其更加适用于未来网络的发展趋势。
- 多队列支持:RoCE v2引入了多队列支持,使网络能够更好地处理并发请求,提高了网络的吞吐量和并发性能。
- 硬件无关性:RoCE v2具有硬件无关性,这意味着它可以在不同厂商的以太网适配器和交换机上实现,并且能够更好地适应不同硬件环境。
- 网络层优化:RoCE v2通过对网络层进行优化,提高了网络的稳定性和性能。它能够更好地适应高负载、低延迟的应用场景,例如数据中心和高性能计算。
- 硬件加速:RoCE v2借助硬件加速技术,进一步提高了数据传输效率。硬件加速可以在适配器和交换机上实现,减轻了主机CPU的负担,降低了传输延迟。
RoCE v2的工作原理
远程直接内存访问(RDMA)允许计算机系统的内存直接读写另一台计算机系统的内存,而无需涉及主机CPU。RDMA通过绕过传统TCP/IP协议栈的方式,降低了数据传输的复杂性和延迟。
RoCE v2通常位于协议栈的传输层,直接构建在IP(Internet Protocol)协议之上。
科普文:软件架构网络系列之【RDMA技术实现之RoCEv2工作过程】-CSDN博客
如何实现RoCE?
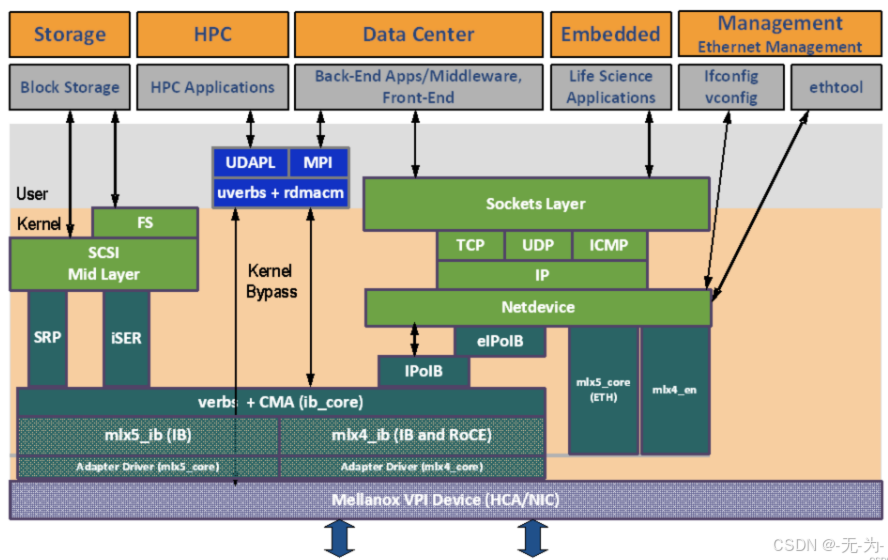
通常,为了实现RoCE,可以安装支持RoCE的网卡或卡驱动程序。所有以太网NIC都需要RoCE网络适配器卡。RoCE驱动程序在Red Hat、Linux、Microsoft Windows和其他常见操作系统中使用。
RoCE有两种可用方式:
- 对于网络交换机,可以选择使用支持PFC(优先流控制)操作系统的交换机;
- 对于机架服务器或主机,需要使用网卡。
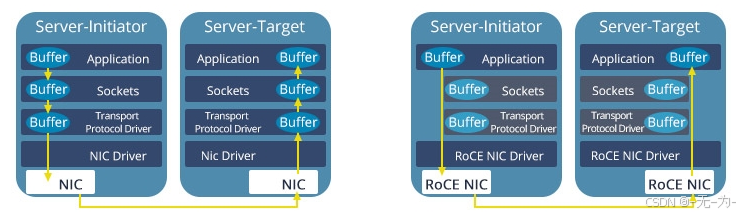
具体来说,RoCE v2使用UDP(User Datagram Protocol)作为传输层的协议,通过UDP封装RDMA协议,以便在以太网网络上进行高性能的数据传输。RoCE v2在协议栈中的位置使其能够利用RDMA技术直接访问内存,从而实现高效的数据传输。
RDMA的核心思想是通过绕过主机CPU,使远程系统可以直接读写本地内存,从而减少数据传输的延迟和主机处理的开销。
RoCE v2在以太网上实现RDMA的关键在于以下几个方面:
RoCE v2需要使用支持RDMA功能的适配器(网络接口卡)和交换机。这些硬件组件具备处理RDMA请求的能力,可以在网络中实现高效的内存访问。
数据传输流程
-
建立连接: RoCE v2使用控制路径建立连接。通信的两端通过交换控制信息建立RDMA连接,包括适配器和交换机的配置信息等。
-
数据传输: 一旦建立连接,数据传输阶段开始。在数据路径上,RoCE v2直接利用RDMA特性,绕过主机CPU,从源内存复制数据到目标内存,实现零拷贝的数据传输。
-
断开连接: 当数据传输完成后,通过控制路径发送断开连接的请求,释放RDMA连接。
控制路径主要负责建立和管理RDMA连接,其中包括连接的初始化、握手过程和错误处理。控制路径使用UDP协议,通过在UDP头部携带RDMA相关的信息来完成这些任务。这一过程通常包括适配器、交换机和操作系统的协同工作。
数据路径用于实际的数据传输,是RoCE v2实现高性能的关键。在数据路径上,RoCE v2通过适配器硬件卸载技术,直接从源内存到目标内存进行数据传输,无需中间缓冲,减少了传统TCP/IP协议栈中的多层复制和处理开销。这样的硬件卸载机制显著降低了传输延迟,提高了数据传输的效率。
RoCE v2与传统网络的比较
-
性能优势:RoCE v2 提供了更低的延迟和更高的吞吐量,相比于传统网络,这使其成为处理对性能敏感的应用(如高性能计算、大数据分析等)的理想选择。
-
RDMA支持:RoCE v2 是一种支持 RDMA 的协议,允许直接在内存之间传输数据,而无需涉及主机的CPU。这减少了数据传输的处理开销,提高了效率。
-
协议栈:RoCE v2 使用 UDP/IP 协议栈,而传统网络使用的是 TCP/IP 协议栈。由于RoCE v2直接在以太网上运行,因此避免了TCP/IP协议的一些开销,提高了性能。
-
适用性:RoCE v2 主要用于数据中心环境,尤其是对于需要低延迟和高吞吐量的应用程序。传统网络更广泛应用于企业、互联网和一般性通信。
-
适用场景:RoCE v2 通常用于需要大规模数据中心内的高性能计算、存储和网络设备之间的通信,而传统网络更适用于一般企业网络和互联网。
-
配置和管理:RoCE v2 的部署可能需要专门的网络硬件和配置,而传统网络通常更容易配置和管理,因为它们使用广泛的标准协议。
-
兼容性:传统网络具有更广泛的兼容性,因为它们使用标准的TCP/IP协议栈,而RoCE v2需要特殊的硬件和协议支持。
RoCE的好处
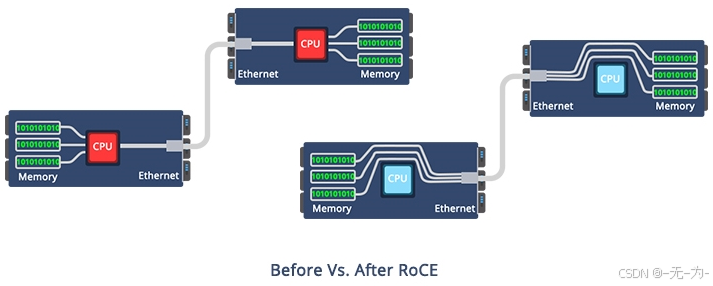
- 低CPU占用率:访问远程交换机或服务器的内存,无需消耗远程服务器上的CPU周期,从而可以充分利用可用带宽和更高的可伸缩性。
- 零复制:向远程缓冲区发送数据和接收数据。
- 高效:由于RoCE改善了延迟和吞吐量,网络性能得到了很大提高。
- 节省成本:借助RoCE,无需购买新设备或更换以太网基础设施即可处理大量数据,从而大大节省了公司的资本支出。
RoCE V2 无损先行
RoCEv2协议将RoCE协议保留的IB网络层部分替换为了以太网网络层和使用UDP协议的传输层,并且利用以太网网络层IP数据报中的DSCP和ECN字段实现了拥塞控制的功能。因此RoCE v2协议的包可以被路由,具有更好的可扩展性。
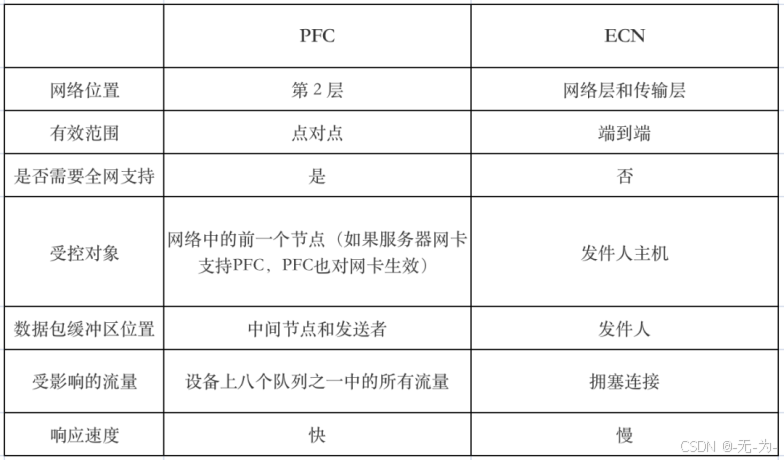
由于RDMA要求承载网络无丢包,否则效率就会急剧下降,所以RoCE技术如果选用以太网进行承载,就需要通过PFC,ECN以及DCQCN等技术对传统以太网络改造,打造无损以太网络,以确保零丢包。
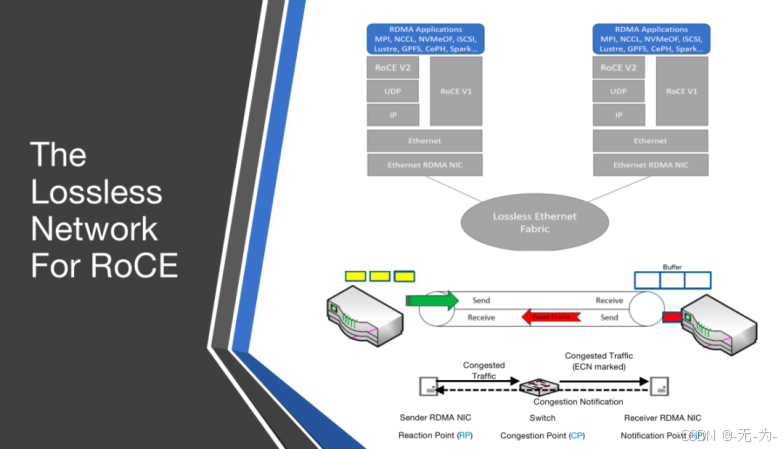
PFC:基于优先级的流量控制。PFC为多种类型的流量提供基于每跳优先级的流量控制。设备在转发报文时,通过在优先级映射表中查找报文的优先级,将报文分配到队列中进行调度和转发。当802.1p优先级报文的发送速率超过接收速率且接收端的数据缓存空间不足时,接收端向发送端发送PFC暂停帧。当发送端收到 PFC 暂停帧时,发送端停止发送具有指定 802.1p 优先级的报文,直到发送端收到 PFC XON 帧或老化定时器超时。配置PFC时,特定类型报文的拥塞不影响其他类型报文的正常转发,
ECN:显式拥塞通知。ECN 定义了基于 IP 层和传输层的流量控制和端到端拥塞通知机制。当设备拥塞时,ECN 会在数据包的 IP 头中标记 ECN 字段。接收端发送拥塞通知包(CNP)通知发送端放慢发送速度。ECN 实现端到端的拥塞管理,减少拥塞的扩散和加剧。
DCQCN(Data Center Quantized Congestion Notification):目前在RoCEv2网络种使用最广泛的拥塞控制算法。融合了QCN算法和DCTCP算法,需要数据中心交换机支持WRED和ECN。DCQCN可以提供较好的公平性,实现高带宽利用率,保证低的队列缓存占用率和较少的队列缓存抖动情况。
无损网络与RoCE拥塞控制机制
在使用RoCE协议的网络中,必须要实现RoCE流量的无损传输。因为在进行RDMA通信时,数据包必须无丢包地、按顺序地到达,如果出现丢包或者包乱序到达的情况,则必须要进行go-back-N重传,并且期望收到的数据包后面的数据包不会被缓存。
RoCE协议的拥塞控制共有两个阶段:使用DCQCN(Datacenter Quantized Congestion Notification)进行减速的阶段和使用PFC(Priority Flow Control)暂停传输的阶段。
当在网络中存在多对一通信的情况时,这时网络中往往就会出现拥塞,其具体表现是交换机某一个端口的待发送缓冲区消息的总大小迅速增长。如果情况得不到控制,将会导致缓冲区被填满,从而导致丢包。因此,在第一个阶段,当交换机检测到某个端口的待发送缓冲区消息的总大小达到一定的阈值时,就会将RoCE数据包中IP层的ECN字段进行标记。当接收方接收到这个数据包,发现ECN字段已经被交换机标记了,就会返回一个CNP(Congestion Notification Packet)包给发送方,提醒发送方降低发送速度。
当网络中的拥塞情况进一步恶化时,交换机检测到某个端口的待发送队列长度达到一个更高的阈值时,交换机将向消息来源的上一跳发送PFC的暂停控制帧,使上游服务器或者交换机暂停向其发送数据,直到交换机中的拥塞得到缓解的时候,向上游发送一个PFC控制帧来通知上有继续发送。
将RoCE应用到HPC上存在的问题
HPC网络的核心需求有两个:①低延迟;②在迅速变化的流量模式下仍然能保持低延迟。
将RoCE应用到HPC中有如下问题:
- 以太网交换机的延迟相比于IB交换机以及一些HPC定制网络的交换机要高一些
- RoCE的流量控制、拥塞控制策略还有一些改进的空间
- 以太网交换机的成本还是要高一些
国内厂家的无损网络方案
华为
华为iLossless智能无损算法方案是一个通过人工智能实现网络拥塞调度和网络自优化的AI算法,其以Automatic ECN为核心,并在超高速数据中心交换机引入深度强化学习DRL(Deep Reinforcement Learning)。基于iLossless智能无损算法,华为发布了超融合数据中心网络CloudFabric 3.0解决方案,引领智能无损进入1.0时代。
2022年,华为超融合数据中心网络提出了智能无损网算一体技术和创新直连拓扑架构,可实现270k大规模算力枢纽网络,时延在智能无损1.0的基础上,可进一步降低25%。
华为智能无损2.0基于在网计算(In-network computing)和拓扑感知(Topology-Aware Computing)实现网络和计算协同。网络参与计算信息的汇聚和同步,减少计算信息同步的次数;同时,通过调度确保计算节点就近完成计算任务,减少通信跳数,进一步降低应用时延。
新华三
新华三推出的AI ECN智能无损算法,能根据网络流量模型(N打1的Incast值、队列深度、大小流占比等流量特征),通过强化学习算法对流量模型进行AI训练,实时感知和预测网络流量变化趋势,自动调节出最优的ECN水线,进行队列的精确调度。在尽量避免触发网络PFC流控的同时,兼顾时延敏感小流和吞吐敏感大流的转发,进一步保障整网的最优性能。
新华三AD-DC SeerFabric无损网络解决方案。基于云边AI协同架构,通过对业界AI ECN调优算法的优化创新,结合新华三数据中心交换机的本地AI Inside能力,在保障零丢包的情况下,尽可能提升吞吐率、降低时延,保障网络业务的精确转发和网络服务质量的确定性。同时,通过精细化的智能运维,实现RoCE网络的业务体验可视。
浪潮
2022年4月,浪潮网络以支持RoCE技术的数据中心以太网交换机为核心,推出了典型的无损以太网解决方案,具备以下优势:
1)计算、存储、网络、AIStation无缝融合。支持PFC、ECN等网络流控技术,以构建端到端、无损、低延时的RDMA承载网络。而交换机完美的缓存优势,可平滑吸收突发流量,有效应对TCP incast。
2)故障主动发现、自动倒换。RoCE-SAN网络与存储业务协同、故障快速感知,交换机快速检测到故障状态,并通知给相关业务域内订阅通知消息的服务器,以便业务快速切换到冗余路径,降低对业务的影响。针对大型无损以太网环境下PFC死锁的问题,可以提供芯片级防PFC死锁机制,实现自动检测PFC死锁及恢复。
3)存储即插即用。RoCE-SAN网络能够自动发现设备服务器与存储设备的接入,并通知服务器自动建立与存储设备的连接关系。
RoCE v2配置和部署
RoCE v2的配置步骤
RoCE v2的配置涉及适配器(网络接口卡)和交换机的设置。
注意:在进行配置之前,请确保所有硬件和驱动程序都支持RoCE v2,并且网络基础设施已经准备好。
适配器配置:
-
安装适配器: 将RoCE v2兼容的适配器插入服务器的PCIe插槽中。
-
安装适配器驱动程序: 安装适配器制造商提供的RoCE v2驱动程序。确保使用最新版本的驱动程序,以确保最佳性能和稳定性。
-
启用RDMA功能: 在服务器上启用RDMA功能,通常通过操作系统中的网络设置或适配器配置实现。确保RDMA功能处于启用状态。
-
配置IP地址和子网掩码: 为RoCE v2适配器配置IP地址和子网掩码。这可以通过操作系统网络设置或适配器管理工具来完成。
交换机配置:
-
选择RoCE v2兼容的交换机: 确保网络交换机支持RoCE v2。在选择交换机时,最好选择具有RoCE v2支持的型号,并查看厂商文档以获取详细信息。
-
启用PFC(Priority Flow Control): RoCE v2依赖于PFC以确保流的有序传输。在交换机上启用PFC,并为RoCE流配置适当的优先级。
-
配置DCB(Data Center Bridging): 配置DCB以确保RoCE v2流量得到适当的带宽和优先级。确保为RoCE v2流配置足够的带宽,以满足性能需求。
-
启用ECN(Explicit Congestion Notification): RoCE v2支持ECN,它可以帮助在网络拥塞时进行流量控制。在交换机上启用ECN,并在适配器上相应地配置。
网络参数设置:
-
配置子网: RoCE v2通常在一个子网内运行,确保适配器和交换机配置的子网是一致的。
-
配置MTU(Maximum Transmission Unit): RoCE v2通常需要使用较大的MTU,以提高性能。在适配器和交换机上配置相同的MTU值,确保网络链路的一致性。
-
启用IPv6: RoCE v2可以使用IPv6进行通信。如果您的网络支持IPv6,请确保适配器和交换机上启用了IPv6,并相应地配置地址。
-
验证连接: 在完成配置后,通过使用RDMA工具或其他测试工具验证RoCE v2连接。确保数据可以通过RoCE v2网络正确传输。
RoCE v2典型的部署方案
RoCE v2在不同网络环境下具有各种部署方案,以满足不同应用的需求。
科普文:软件架构Linux系列之【RoCE应用:工商银行率先完成金融高性能存储网络体系重构】吴仲阳 曾金 余学山-CSDN博客
科普文:软件架构网络系列之【RDMA应用:一文看懂高性能网络】-CSDN博客
科普文:软件架构网络系列之【高性能存储网络的革新之路 NVMe over RDMA】-CSDN博客
1. 数据中心网络:
- 大规模分布式存储
- 虚拟化环境
- 高性能计算集群
采用leaf-spine拓扑,确保低延迟和高吞吐量。使用RoCE v2的适配器和交换机,以构建支持RDMA的高性能网络。
在leaf和spine交换机上启用PFC和DCB,以支持RoCE流的有序传输和带宽保障。
配置Jumbo Frames以支持更大的MTU,提高RoCE性能。
使用RoCE v2在不同的子网内运行,确保网络隔离和性能优化。
在虚拟机主机上配置RoCE v2,以支持虚拟机之间的高性能通信,提高虚拟化工作负载的性能。
2. 企业网络:
- 数据库应用
- 大规模文件共享
- 视频流传输
采用适用于企业环境的传统三层网络结构,但在需要高性能通信的关键节点上部署RoCE v2。
在关键交换机上启用PFC和DCB,确保对关键应用的高性能支持。
根据需要提高MTU,以提高性能,特别是对于大规模文件共享或视频传输等场景。
使用RoCE v2在不同的子网内运行,确保关键应用的网络隔离。
配置必要的网络安全性措施,确保RoCE v2的数据传输是安全的。
3. 高性能计算:
- 科学计算
- 模拟
- 渲染
采用高性能计算集群所需的高性能网络拓扑,如Fat-Tree或Dragonfly。
在高性能计算网络中启用PFC和DCB,以支持大规模计算集群中的RDMA通信。
配置较大的MTU,以提高数据传输效率。
使用RoCE v2在不同的子网内运行,确保计算节点之间的高性能通信。
配置支持RDMA的分布式文件系统,以提高文件访问性能。
RoCE v2硬件和软件要求
RoCE v2网络的部署涉及多个方面的硬件和软件要求。以下是一份详细的清单,包括适配器型号、交换机规格、操作系统支持等:
适配器(网络接口卡)要求:
-
制造商和型号:适用于RoCE v2的InfiniBand和以太网混合适配器,如Mellanox ConnectX-6, ConnectX-6 Dx等。
-
RoCE v2支持:适配器必须明确支持RoCE v2。确保选购的适配器驱动程序和固件版本与RoCE v2的最新规范兼容。
-
性能特性:选择适合性能需求的适配器,考虑带宽、端对端延迟等性能特性。
-
PCIe兼容性:适配器必须与服务器的PCIe插槽兼容,确保适配器能够正常安装并发挥其性能。
交换机要求:
-
制造商和型号:选择RoCE v2兼容的交换机,如Mellanox Spectrum交换机系列,Cisco Nexus 9000系列等。
-
RoCE v2支持:交换机必须支持RoCE v2,并且有关配置选项的文档必须是清晰和完整的。
-
PFC和DCB支持:交换机必须支持Priority Flow Control(PFC)和Data Center Bridging(DCB),以确保RoCE流量的有序传输和带宽保障。
-
高带宽端口:选择具有足够端口带宽的交换机,以满足高性能网络的需求。
操作系统和驱动程序要求:
-
操作系统支持:确保选择的适配器和交换机支持所使用操作系统,如Linux(特别是RDMA支持的Linux发行版,如RHEL、Ubuntu)、Windows Server等。
-
驱动程序和固件:安装适配器制造商提供的最新驱动程序和固件版本,以确保兼容性和最佳性能。
其他要求:
-
MTU设置:在网络链路上配置Jumbo Frames以支持更大的MTU,提高RoCE性能。
-
子网划分:使用RoCE v2在不同的子网内运行,确保网络隔离和性能优化。
-
安全性配置:针对特定环境的安全性需求配置适当的网络安全性措施。
-
网络管理工具:配置和管理RoCE v2网络可能需要使用适当的网络管理工具,确保对网络状态有全面的了解。
在部署RoCE v2网络之前,请务必仔细查阅所有相关硬件和软件的文档,确保所选的设备和配置满足特定环境的需求。另外,进行适当的性能测试和验证,以确保RoCE v2网络的稳定性和性能。
RoCE v2应用案例
数据中心网络的优化
RoCE v2在数据中心网络中的应用能够显著提高性能和效率,特别是在虚拟化环境中。
RoCE v2通过实现RDMA,使虚拟机之间的数据传输不再依赖于主机的CPU,从而降低了处理开销,提高了性能。RoCE v2的设计目标之一是提供低延迟和高吞吐量。在虚拟化环境中,这对于支持多个虚拟机之间的高性能通信至关重要。RoCE v2支持在虚拟化环境中实现网络隔离,确保虚拟机之间的通信是安全的。这对于多租户数据中心非常重要。
RoCE v2通常支持Jumbo Frames,RoCE v2适用于大规模的并发工作负载,尤其是在数据中心环境中,支持大量同时进行的数据传输,提高了整体性能。
在分布式计算集群中,RoCE v2的低延迟和高吞吐量使得节点之间的通信更为高效。这对于分布式计算任务的协同处理非常关键。RoCE v2广泛用于优化分布式存储系统,加速存储访问,提高存储性能。这对于大规模数据存储和处理非常关键。
存储系统的性能提升
RoCE v2在存储系统中的应用可以显著提升存储性能和降低访问延迟,尤其在大规模数据存储和高频读写操作方面。
比如一家科研机构拥有大规模的科学数据集,需要在分布式存储系统中进行高效的数据传输和存取。为了提高存储性能,他们采用了RoCE v2技术。选用RoCE v2兼容的网络适配器,并确保每个存储节点都能够支持RoCE v2。常见的选择包括Mellanox ConnectX-6等适配器。部署RoCE v2兼容的交换机,确保在存储网络中启用PFC和DCB以支持RoCE流的有序传输和带宽保障。部署支持RDMA的分布式存储系统,确保存储节点之间可以通过RoCE v2进行直接内存访问,降低CPU开销。配置支持Jumbo Frames的MTU,提高数据包大小以减少每个数据包的头部开销,从而提高数据传输效率。针对高频读写操作进行存储系统的优化,确保系统能够充分利用RoCE v2的低延迟和高吞吐量。
RoCE v2的低延迟特性允许存储节点之间以更迅速的速度进行通信,降低了数据访问的延迟,尤其在大规模数据存储中体现明显。RoCE v2支持高吞吐量的数据传输,使存储系统能够处理更多的请求,提高了整体存储性能。在大规模数据传输场景下,RoCE v2的优越性能使得数据能够以更高效的方式在存储节点之间传输,加速了数据的备份、恢复和迁移过程。对于高频读写操作,RoCE v2的性能优势使得存储系统能够更快速地响应请求,提供更佳的响应时间。
超大规模集群的应用
RoCE v2在超大规模集群中,如云计算环境和超大规模计算集群中的应用,对网络性能有着显著的影响,并能够有效地支持大规模并行计算。在云计算环境中,RoCE v2可以用于提高虚拟机之间的通信性能,特别是在需要低延迟和高吞吐量的应用场景下。RoCE v2可用于加速分布式存储系统,提高云环境中的存储性能。RoCE v2的特性使得在云环境中实现低延迟和高吞吐量的通信,为云服务提供商提供更高性能的服务。在虚拟化环境中,RoCE v2可优化虚拟机之间的数据传输,降低CPU开销,提高整体虚拟化性能。RoCE v2的网络隔离特性允许在云环境中有效地支持多租户,确保每个租户之间的通信是隔离和安全的。
RoCE v2可用于高性能计算(HPC)集群中,支持大规模分布式计算任务的通信需求。在科学研究、气象模拟等场景中,RoCE v2加速大规模数据传输,提高数据处理效率。RoCE v2支持高度并发的通信,适用于超大规模计算集群中成千上万的节点之间的通信需求。对于需要协同工作的大规模计算任务,RoCE v2的低延迟特性有助于降低任务之间的通信延迟,提高整体计算效率。RoCE v2可用于优化分布式文件系统,加速大规模数据的读写操作。
RoCE v2的低延迟特性对超大规模集群中的任务协同和数据传输非常重要,有助于降低通信延迟,提高响应速度。RoCE v2在网络中提供高吞吐量,支持大规模数据的快速传输,对于高性能计算和大规模存储系统至关重要。RoCE v2支持网络隔离,确保在超大规模集群中的多个租户或任务之间的通信是安全和隔离的。
RoCE v2安全性和管理
RoCE v2网络的安全性考虑
RoCE v2本身并不提供数据传输的加密和认证机制。RoCE v2专注于提供低延迟和高吞吐量的远程直接内存访问(RDMA)功能,而安全性方面通常需要通过其他机制来保障。在RoCE v2网络中,通常会采用一些额外的安全性措施来确保数据的保密性和完整性。
在RoCE v2网络中,可以使用IPsec(Internet Protocol Security)来提供数据传输的加密和认证。IPsec是一种在网络层提供安全性的协议,可以用于对RoCE v2流量进行加密和认证,确保数据在传输过程中的保密性和完整性。通过在网络中实施网络隔离,可以确保RoCE v2流量不受未经授权的访问。这可以通过VLAN(Virtual Local Area Network)或其他网络隔离技术来实现。确保物理层的安全性,包括适配器和交换机的物理安全性。防止未经授权的访问和物理攻击,以保护RoCE v2网络的安全性。在RoCE v2网络中,可以使用认证和授权机制来确保只有经过授权的设备和用户能够访问网络资源。这包括对适配器和交换机的身份验证和授权。
设立审计和监控机制,以便实时监测RoCE v2网络的流量和活动。通过记录和分析网络流量,可以及时发现异常行为并采取相应的安全措施。在应用层面使用加密协议,例如TLS/SSL,对于需要特别保密性的数据传输场景,可以在应用层面实现额外的加密保护。定期维护和更新RoCE v2网络的软件和硬件组件,以保持系统的安全性。确保使用最新版本的驱动程序、固件和操作系统,并及时安装安全补丁。
网络管理的最佳实践
RoCE v2网络的最佳管理实践涵盖了监控、故障排除、性能优化等多个方面。
使用网络监控工具定期检查RoCE v2网络的性能和流量状况。监控关键性能指标,如延迟、吞吐量和错误率。启用适配器、交换机和操作系统的详细日志记录功能,以便追踪和分析任何潜在问题。定期审查日志,特别关注错误、警告和异常事件。
运行定期的故障排除测试,确保RoCE v2网络的各个部分都能正常工作。这可能包括链路测试、适配器自检等。使用网络诊断工具,如Wireshark等,对RoCE v2流量进行抓包和分析,以便定位和解决网络问题。配置适配器和交换机以支持远程故障排除,以便远程诊断和解决问题,减少维护时间。
配置支持Jumbo Frames的MTU,以提高RoCE v2网络的性能。确保网络链路上所有设备都能够支持所配置的MTU。在交换机上启用Priority Flow Control(PFC)和Data Center Bridging(DCB),以确保RoCE流的有序传输和带宽保障,提高性能。定期检查适配器厂商的网站,获取最新的适配器固件更新,并确保适配器上安装了最新的稳定版本。
在RoCE v2网络中使用网络隔离,确保不同子网的通信隔离,提高网络的安全性。根据需要配置适配器和交换机上的访问控制列表(ACL),限制对RoCE v2网络的未经授权访问。
定期进行软硬件的维护,包括适配器和交换机的固件更新、操作系统的升级等。定期检查RoCE v2网络的物理连接,确保所有连接都牢固可靠。


















 4063
4063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











