







 本文介绍了PASCALVOC2012和SBD数据集的组成,以及在处理过程中遇到的问题,如`convert_labels.py`转换时的`numpy.AxisError`和边界标注的忽略。通过解决这些问题,如正确使用`convert_labels.py`并确保边界区域被标记,可以提高模型复现结果的准确性。
本文介绍了PASCALVOC2012和SBD数据集的组成,以及在处理过程中遇到的问题,如`convert_labels.py`转换时的`numpy.AxisError`和边界标注的忽略。通过解决这些问题,如正确使用`convert_labels.py`并确保边界区域被标记,可以提高模型复现结果的准确性。
目录
3.1 使用convert_labels.py转换出错:numpy.AxisError: axis 2 is out of bounds for array of dimension 0
3.2 转换方法错误导致复现结果不佳:转换过程中标注的边界被忽略
1. 数据集组成
PASCAL 5i (PASCAL VOC 2012 Aug) 增强数据集由PASCAL VOC 2012数据集和SBD组成,两个数据集的图片数如下表所示
| 数据集 | 训练集(train) | 验证集(val) | 测试集(test) |
| VOC 2012 | 1464 | 1449 | 一般用不上 |
| SBD | 8498 | 2857 | 0 |
整个PASCAL 5i增强数据集一共有12031个样本和标注能够使用,从中划分训练集和验证集,具体组成如下:
1.1 训练集:10582/5923张图片怎么来的
pascal-5i增强数据集的训练集(aug_train)在使用中有两个版本,一个版本为10582个样本,另一个版本为5923个样本:
1.1.1 训练集版本一:10582张
10582张样本的训练集的组成如下:
即由 PASCAL VOC 2012的训练集、SBD的训练集、SBD的验证集组成,并去除其中的重复样本,最终数量为10582个样本。这里可以理解为,验证一般只用原VOC 2012的验证集进行验证,因此可以把SBD的验证集用来训练,增加训练集样本数量。
具体的list见这位大佬的博客:How to use 10,582 trainaug images on DeeplabV3 code? | Starsky's Blog - 11zHexo (sun11.me)list内容在这里:trainaug.txt
1.1.2 训练集版本二:5923张
5923张样本的训练集的组成如下:
即由 PASCAL VOC 2012的训练集、SBD的训练集组成,并去除其中的重复样本,最终数量为5923个样本。这个版本直接把SBD的验证集弃用了,不用于训练也不用于验证。
PFENet给出了5923张训练集的list:去重后训练集list
1.2 验证集
pascal-5i增强数据集的验证集(aug_val)共有1449张图片,与PASCAL VOC 2012的验证集(voc_val)一致,直接使用即可
2. 数据集下载
PASCAL VOC 2012数据集可前往官网下载:官网链接
向下找到Development Kit,下载训练/验证集training/validation data
(注意:测试集test需要单独下载,但官方并未公布测试集的groundtruth,也就是只有图片没有标注,一般不用下载)

SBD原来的下载页面现在变成了作者的个人简介,大部分博客使用的都是原来的下载链接。我没找到新的官方链接,只能在其他大佬的博客中,通过云盘分享来下载
有些博客分享了处理完成的数据集,但有些处理方法可能会导致复现结果不佳,具体看下文3.2
3. 数据集处理
这一步是最容易出错的地方
VOC 2012数据集用的是彩色的标注图片,SBD数据集用的是.mat格式的标注,为了统一,需要把两种都转换成灰度图,SBD的官方文件内有两种转换脚本可以使用,具体操作不再赘述,可以参考大佬们的博客PASCAL VOC 2012数据集及其增强版介绍_pascal voc 2012其增强版 网盘-CSDN博客PASCAL VOC2012 & 增强数据集_segmentationclassaug voc2012-CSDN博客,
最终文件夹内应该要有12031张图片和灰度图(10582张train+1449张val,train和val通过对应的list区分),但是需要注意以下两个问题
3.1 使用convert_labels.py转换出错:numpy.AxisError: axis 2 is out of bounds for array of dimension 0
参考博客:http://t.csdnimg.cn/oQxSM
或
参考博客:PASCAL VOC2012 & 增强数据集_segmentationclassaug voc2012-CSDN博客的评论区
convert_labels.py里面img = imread(img_name)改成img = imread(img_name)[:,:,0:3]
3.2 转换方法错误导致复现结果不佳:转换过程中标注的边界被忽略
发现这个问题是源于对小样本语义分割PFENet的复现,复现结果的mIoU始终比论文相差5个点左右,后续对GFS-Seg的CAPL复现仍然有差距,然后在PFENet的github的issue里面发现了原因:https://github.com/dvlab-research/PFENet/issues/6

由于存在不同的对数据集的预处理方法,有的方法在将PNG转换成灰度图过程中,PASCAL VOC的边界区域会被标记为255,以2007_000032.png举例来说,可以看以下对比:



如果你处理完后,图片像中间那样没有把边界区域标成白色,那么复现结果很可能会有一定差距
3.2.1 为什么边界区域的转换会影响实验结果?
我们可以打开CAPL代码的util下的util.py,找到intersectionAndUnion方法:
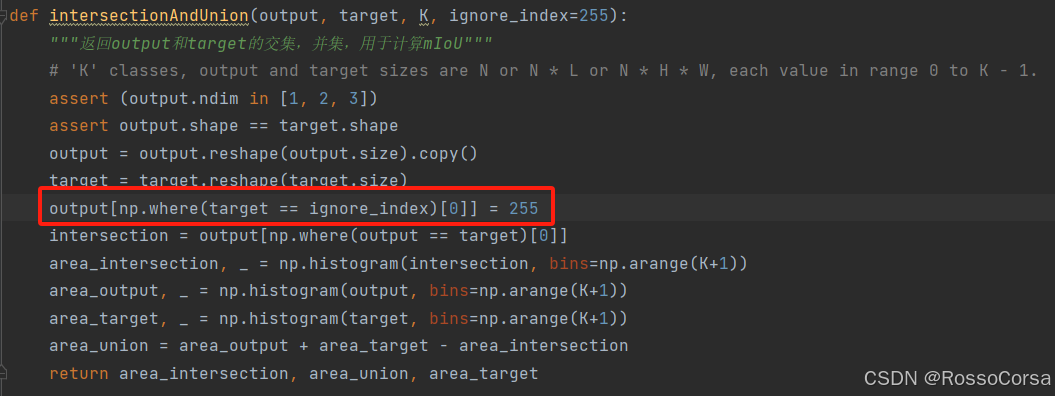
在计算平均交并比mIoU的过程中,需要计算模型输出output和标注target的交集和并集。由于模型只能分割20个类+背景类,而target中却有边界标注,因此需要另外处理。在计算交集和并集之前,可以发现,代码把output中和target中边界所在位置的值直接修改为了边界标注值。也就是说,不管output怎么划分,和target区别多大,都默认target的边界位置是正确分割的。因此如果数据集在预处理时没有给target标注上边界,那么计算mIoU的时候就少了这部分一定准确的值。
印象中我是使用了SBD的官方转换工具进行转换,得到了中间那种只标注类、不标注边界的灰度图(肉眼能模糊看得见person类),但有些大佬的博客中的结果是下图那种标注了白色边界的灰度图,可能是因为将边界转换成白色并默认其分割正确这种方法是后续某篇论文里才提出的?
Any way,如果你处理完了没有白色边界,可以按以下解决办法重新转换一遍:
3.2.2 PASCAL VOC的边界处理
进入SBD转换工具的utils.py文件,找到pascal_palette()方法,如下:

在palette后面加上:
(224, 224, 192) : 255如下图所示:

随后再重新运行一遍convert_lables.py,应该就会生成带白色边界的灰度图,文件夹内如下图所示:

具体的原理是:在将PNG图片转换成灰度图的过程中,会将每个类的RGB颜色与其类别号一一对应,将由各种颜色组成的PNG图片,转换成由类别号组成的灰度图。而增加的一行代码,则是增加了边界颜色和标注255的对应关系,从而使边界在灰度图中以255即白色的形式出现,而不是被忽略。
使用带白色边界的PASCAL VOC灰度图进行复现,复现结果会很明显有好转,以对CAPL的复现结果举例,相比于不带白边的标注,使用带白边的标注结果很明显更好,能够复现原论文表现
| 1shot | 5shot | |
| 论文 | 54.38 | 55.72 |
| 复现(标注无白边) | 50.43 | 52.56 |
| 复现(标注有白边) | 54.72 | 57.06 |
3.2.3 SBD的边界处理
由于作者只提到了PASCAL VOC的边界处理,并且只处理PASCAL VOC进行复现已经能得到不错的结果,因此我没有再对SBD的边界进行处理。但有很多同学问到.mat转换后没有边界,我又回头翻了一下代码,在这里提供一下大致的思路:
首先确定.mat的格式,使用在线matlab打开其中一个.mat文件,可以看到有一个名为GTcls的struct类

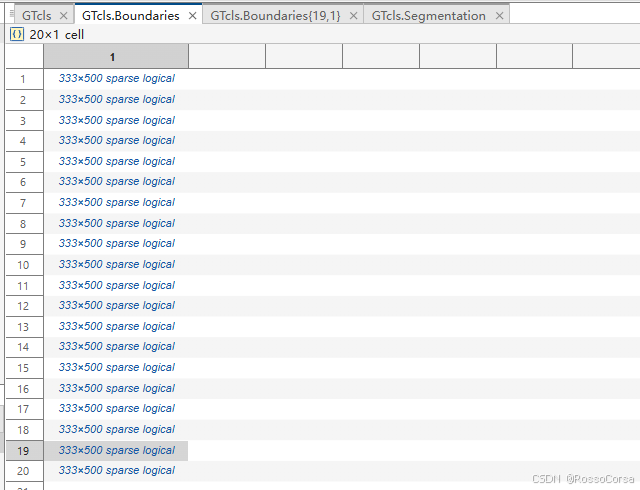
而GTcls结构体内又由Boundaries, Segmentation, CategoriesPresent三个字段组成

我们从后往前一一解释这三个字段:
CategoriesPresent数组存储的是这一张图片包含类别的编号(图中为15号和19号),用途不大可以忽略;
Segmentation数组存储的则是完整图片大小的标注,转换工具就是将其读入转换成灰度图;
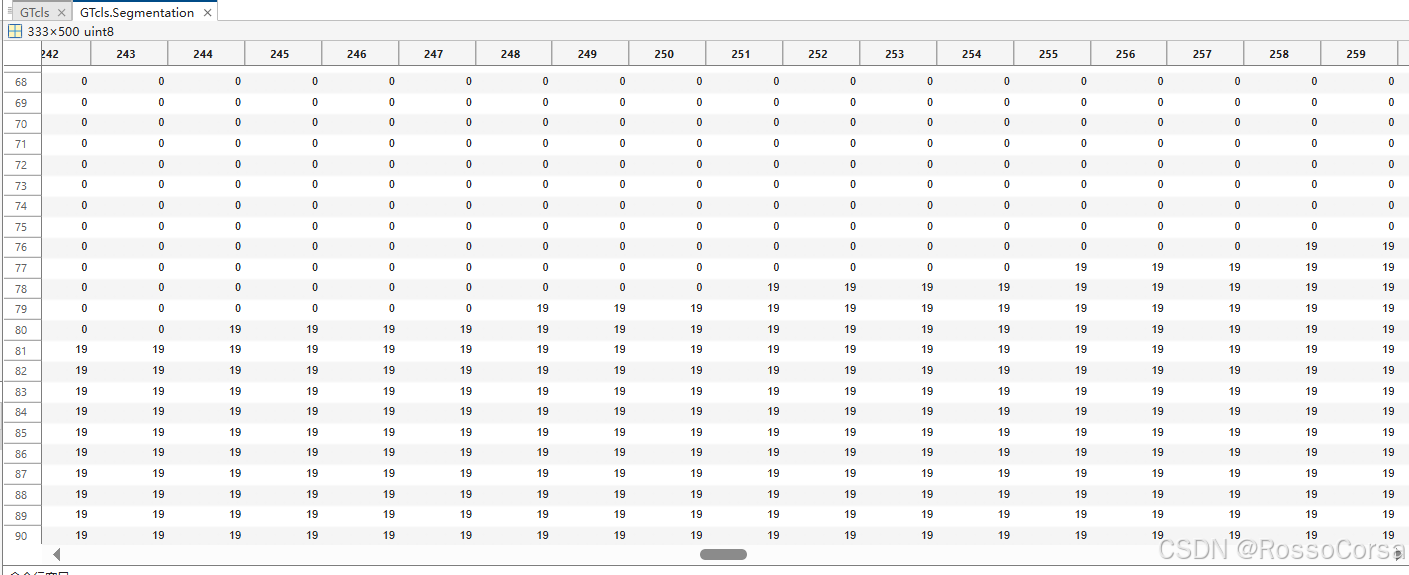
Boundaries则是用20个稀疏矩阵,分别标注20个类的边界
其中没有出现的2号类边界为全0

出现的19号类的边界则在边界位置标注为1
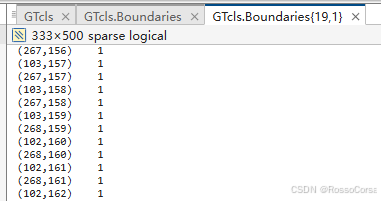
随后我们查看转换工具的代码,首先看到mat2png.py中的convert_mat2png方法,其中的一句代码将.mat文件读入成了灰度图数组
再看到该代码调用的utils.py文件中的mat2png_hariharan方法,可以发现只读入了.mat的GTcls结构体中的Segmentation字段,而没有读入标注边界的Boundaries字段

因此改造思路大致为:将Boundaries字段也读入,并将Boundaries中20个类的边界矩阵叠加到一起(即不区分是哪个类的边界),将其中的边界标注1修改为255,最后将其叠加到读入的Segmentation矩阵上即可

















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









