







 本文详细介绍了PASCAL-5I数据集的制作过程,包括从PASCALVOC数据集抽样、类别划分、图片归类、数据集生成,以及对数据集中类别分布的可视化分析。
本文详细介绍了PASCAL-5I数据集的制作过程,包括从PASCALVOC数据集抽样、类别划分、图片归类、数据集生成,以及对数据集中类别分布的可视化分析。
1.前言
PASCAL-5I数据集是基于上一篇文章《pascal voc aug数据集》制作而成。本篇介绍了pascal-5i数据集原理以及制作过程,并可视化分析pasca-5i的类别分布。
PASCAL VOC AUG目录如下
- pascal_voc_aug
- JPEGImages
- SegmentationClassAug
- train.txt
- trainval.txt
- val.txt
1.1 流程分析
总体分为以下步骤:
- 将pascal voc aug数据集的mask图片按照图片包含的类别归类
- 根据归类结果,和类别划分,生成数据集
- 将数据集类别情况详细统计
1.2 pascal-5i数据集介绍
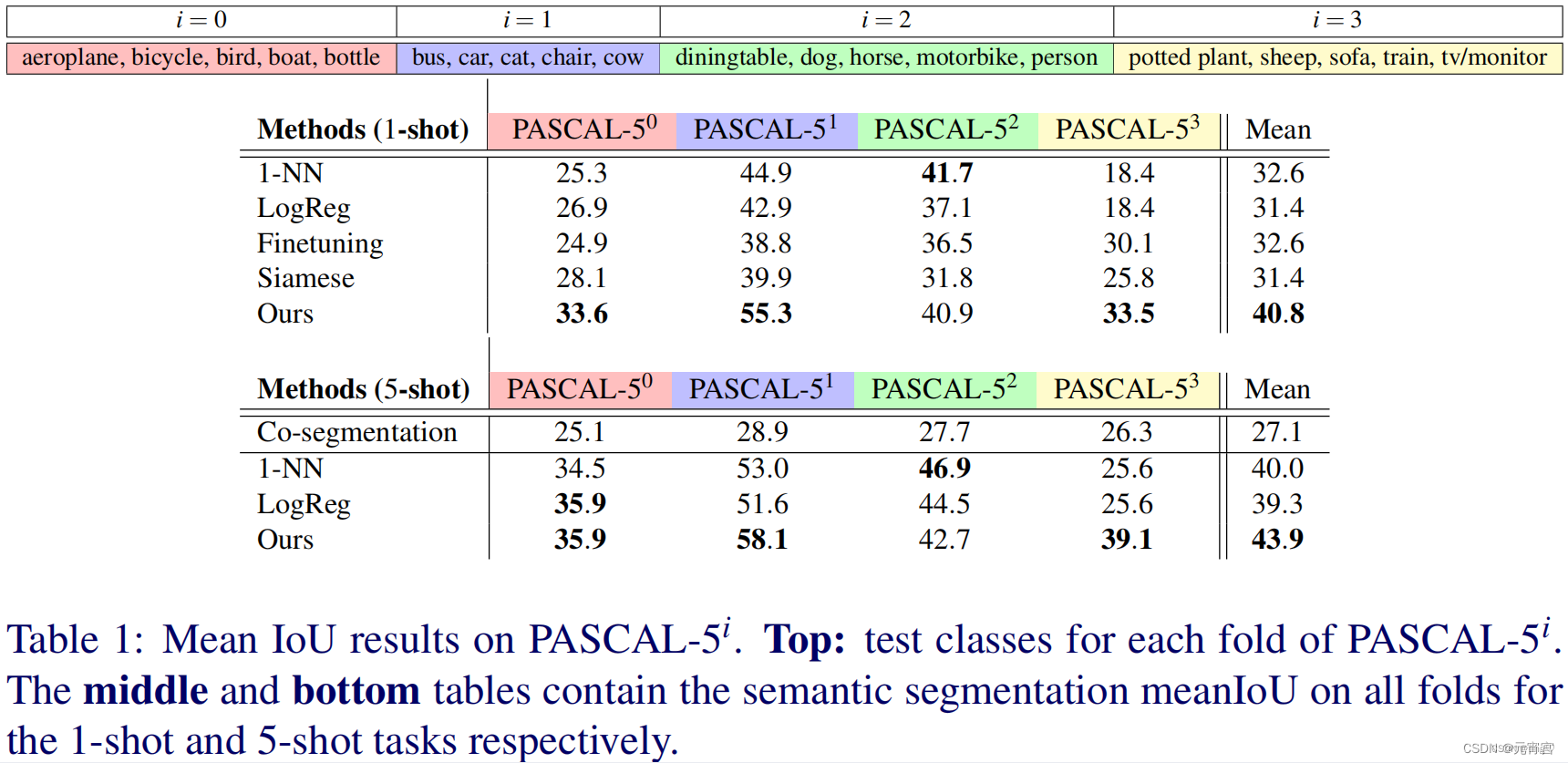
pascal-5i来自于《One-Shot Learning for Semantic Segmentation》这篇经典小样本语义分割论文。它从PASCAL VOC 20个语义类的集合L中,我们抽样5个,并将它们视为测试标签集 L t e s t = { 5 i + 1 , . . . , 5 i + 5 } L_{test}=\{5i+1,...,5i+5\} Ltest={ 5i+1,...,5i+5},其中i为the fold number,剩下的15个形成了训练标签集 L t r a i n = { 5 i + 1 , . . . , 5 i + 5 } L_{train}=\{5i+1,...,5i+5\} Ltrain={ 5i+1,...,5i+5}。其实思路和k-fold交叉验证很像.
其中pascal-5i训练集来自pasca_voc_aug的训练集.其mask经过处理,也就是把非查询集的类别标记为背景.同样pascal-5i的验证集来自pasca_voc_aug的验证集.
2.图片归类
具体说明:如果某张训练集图片包含1,2,3类,那么他的文件名会被记录在train目录下的1.txt、2.txt、3.txt.
def generate_class(mode):
"""
将图片进行归类
:param mode: train or val
:return:
"""
dic={
}
data_list = txt_to_list(mode)
for file_name in tqdm(data_list):
mask_path = os.path.join(config.mask_path, file_name + ".png")
mask = Image.open(mask_path)
mask_arr=np.array(mask)
class_set=set(np.unique(mask_arr)) - {
0 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 51
51

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









