







图的进阶说明之前,说要了解,以下代码的实现,需要栈、队列、并查集的相关代码,相关代码的链接
[https://blog.csdn.net/Royalic/article/details/119832038]:
[https://blog.csdn.net/Royalic/article/details/119734144]:
[https://blog.csdn.net/Royalic/article/details/119734057]:
road_find.txt
6
8
0 2
0 1
2 1
2 3
2 4
3 5
3 4
0 5
TopoLogical.txt
6
6
0 2
0 3
1 3
2 4
3 4
4 5
traffic_project.txt
20
7
0 1
6 9
3 8
5 11
2 12
6 10
4 8
min_route_test.txt
8
15
4 5 0.35
5 4 0.35
4 7 0.37
5 7 0.28
7 5 0.28
5 1 0.32
0 4 0.38
0 2 0.26
7 3 0.39
1 3 0.29
2 7 0.34
6 2 0.40
3 6 0.52
6 0 0.58
6 4 0.93
min_create_tree_test.txt
8
16
4 5 0.35
4 7 0.37
5 7 0.28
0 7 0.16
1 5 0.32
0 4 0.38
2 3 0.17
1 7 0.19
0 2 0.26
1 2 0.36
1 3 0.29
2 7 0.34
6 2 0.40
3 6 0.52
6 0 0.58
6 4 0.93
一、有向图
在实际生活中,很多应用相关的图都是有方向性的,最直观的就是网络,可以从A页面通过链接跳转到B页面,那么a和b连接的方向是a -> b,但不能说是b -> a,此时我们就需要使用有向图来解决这一类问题,它和我们之前学习的无向图,最大的区别就在于连接是具有方向的,在代码的处理上也会有很大的不同。
1.1 有向图的定义及相关术语
定义:有向图是一副具有方向性的图,是由一组顶点和一组有方向的边组成的,每条方向的边都连着一对有序的顶点。
出度:由某个顶点指出的边的个数称为该顶点的出度。
入度:指向某个顶点的边的个数称为该顶点的入度。
有向路径:由一系列顶点组成,对于其中的每个顶点都存在一条有向边,从它指向序列中的下一个顶点。
有向环:一条至少含有一条边,且起点和终点相同的有向路径。

一副有向图中两个顶点v和w可能存在以下四种关系:
- 没有边相连;
- 存在从v到w的边v—>w;
- 存在从w到v的边w—>v;
- 既存在w到v的边,也存在v到w的边,即双向连接;
理解有向图是一件比较简单的,但如果要通过眼睛看出复杂有向图中的路径就不是那么容易了。

1.2 有向图API设计

在api中设计了一个反向图,其因为有向图的实现中,用adj方法获取出来的是由当前顶点v指向的其他顶点,如果能得到其反向图,就可以很容易得到指向v的其他顶点。
1.3 有向图实现
有向图的代码实现
package Graph;
import LinkTable.Queue;
/**
* @author Fantic
* @create 2021-08-22 22:35
*/
public class Digraph {
private final int V;//记录顶点的数量
private int E;//记录边的数量
private Queue<Integer>[] adj;//索引是顶点,对应的值是顶点的邻接表
//创建一个包含V个顶点但不含有边的有向图
public Digraph(int V) {
//初始化顶点数量
this.V = V;
//初始化边的数量
this.E = 0;
//初始化邻接表
this.adj = new Queue[V];
//初始化邻接表中的空队列
for (int i = 0; i < adj.length; i++) {
adj[i] = new Queue<Integer>();
}
}
//获取图中顶点的数量
public int V(){
return V;
}
//获取图中边的数量
public int E() {
return E;
}
//向邮箱图中添加一条边v -> w
public void addEdge(int v,int w){
//由于有向图中是有向的,v- >w边,值需要让w出现在v的邻接表中,则不需要让v出现在w的邻接表
adj[v].enqueue(w);
E++;
}
//获取由顶点v指向的边所连接的所有顶点
public Queue<Integer> adj(int v){
return adj[v];
}
//得到图的反向,显示图的传递顺序
public Digraph reverse(){
//创建新的有向图对象
Digraph digraph = new Digraph(V);
//遍历0~V所有顶点,拿到每个顶点v
for (int v = 0; v < V; v++) {
//得到原图中的v顶点对应的邻接表,原图中的边为v->w则反向图为w->v
for (Integer w : adj[v]) {
digraph.addEdge(w,v);
}
}
return digraph;
}
}
二、拓扑排序
在现实生活中,我们经常会同一时间接到很多任务去完成,但是这些任务的完成是有先后次序的。以我们学习java学科为例,我们需要学习很多知识,但是这些知识在学习的过程中是需要按照先后次序来完成的。从java基础,到jsp/servlet,到ssm,到springboot等是个循序渐进且有依赖的过程。在学习jsp前要首先掌握java基础和html基础,学习ssm框架前要掌握jsp/servlet之类才行。

为了简化问题,我们使用整数为顶点编号的标准模型来表示这个案例:

此时如果某个同学要学习这些课程,就需要指定出一个学习的方案,我们只需要对图中的顶点进行排序,让它转换为一个线性序列,就可以解决问题,这时就需要用到一种叫拓扑排序的算法。
拓扑排序:
给定一副有向图,将所有的顶点排序,使得所有的有向边均从排在前面的元素指向排在后面的元素,此时就可以明确的表示出每个顶点的优先级。下列是一副拓扑排序后的示意图:

2.1 检测有向图中的环
如果学习x课程前必须先学习y课程,学习y课程前必须先学习z课程,学习z课程前必须先学习x课程,那么一定是有问题了,我们就没有办法学习了,因为这三个条件没有办法同时满足。其实这三门课程x、y、z的条件组成了一个环 ;

因此,如果我们要使用拓扑排序解决优先级问题,首先得保证图中没有环的存在。
2.1.1 检测有向环的API设计
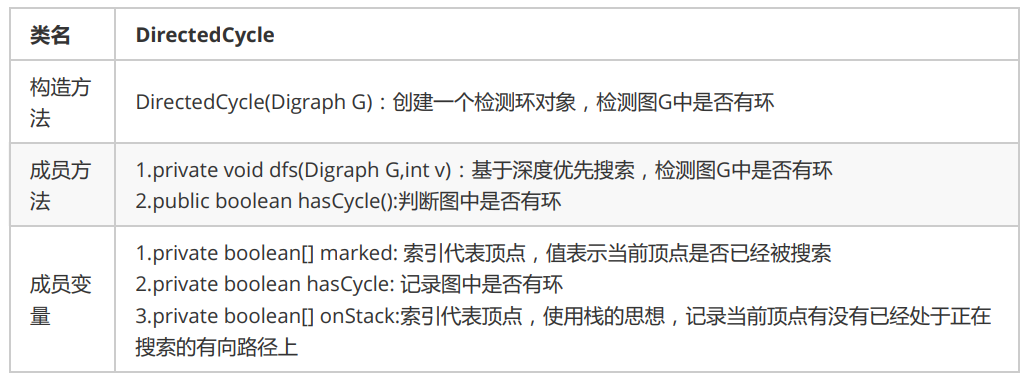
2.1.2 检测有向环实现
在API中添加了onStack[] 布尔数组,索引为图的顶点,当我们深度搜索时:
- 在如果当前顶点正在搜索,则把对应的onStack数组中的值改为true,标识进栈;
- 如果当前顶点搜索完毕,则把对应的onStack数组中的值改为false,标识出栈;
- 如果即将要搜索某个顶点,但该顶点已经在栈中,则图中有环;
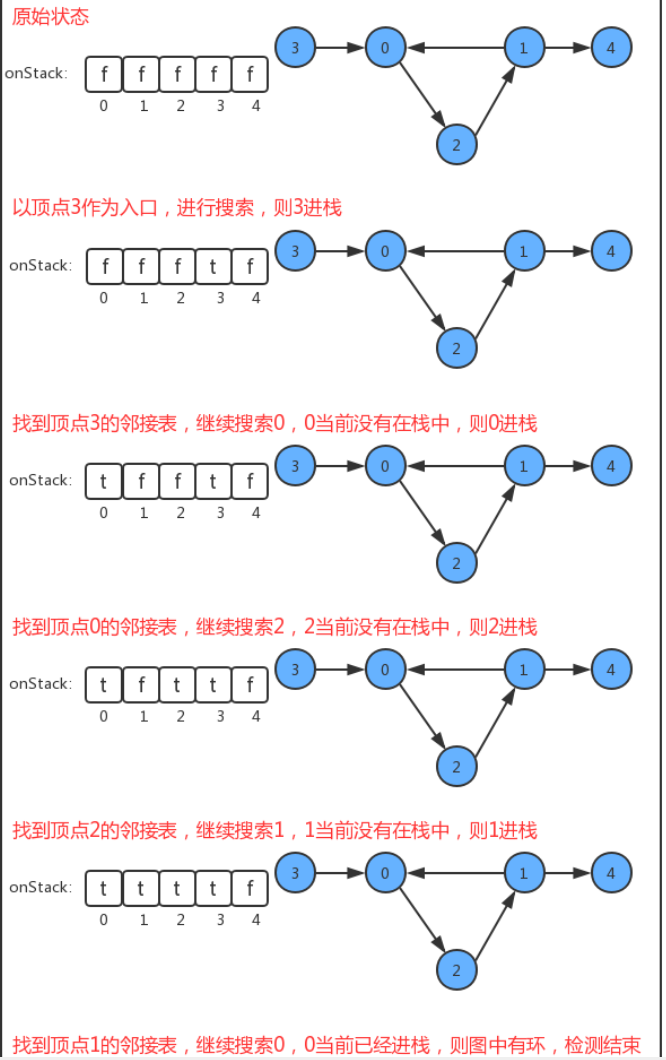

判断有向图中是否有环代码实现
package Graph;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
/**
* @author Fantic
* @create 2021-08-22 22:35
*/
//要引用有向图的实现代码
public class DirectedCycle {
//索引代表顶点,值表示当前顶点是否已经被搜索
private boolean[] marked;
//记录图中是否有环
private boolean hasCycle;
//索引代表顶点,使用栈的思想,记录当前顶点有没有处于正在搜索的有向路径中
private boolean[] onStack;
//创建一个检测环的对象,监测图中是否有环
public DirectedCycle(Digraph digraph) {
//创建一个与图的顶点数相同的marked数组
this.marked = new boolean[digraph.V()];
//默认图中没有坏
this.hasCycle = false;
//创建一个与图顶点数一样大小的onStack数组
this.onStack = new boolean[digraph.V()];
//遍历搜索图中的每一个顶点
for (int v = 0; v < digraph.V(); v++) {
//如果当前结点没有被搜索过,则进行搜索
if (!marked[v]) {
dfs(digraph, v);
}
}
}
//基于深度优先搜索,检测图中是否有环
private void dfs(Digraph digraph,int v){
//把当前顶点标记为已搜索
marked[v] = true;
//让当前顶点进栈
onStack[v] = true;
//遍历v顶点的邻接表,得到每一个顶点
for (Integer w : digraph.adj(v)) {
//如果v顶点邻接表中w顶点没有搜索过,递归调用dfs方法继续对顶点w进行邻接表的相应搜索
if (!marked[w]){
dfs(digraph,w);
}
//如果顶点已经被搜索过,则查看顶点w是否在栈中,如果在,则证明图中有环,修改hasCycle的标记,结束循环
if (onStack[w]) {
hasCycle = true;
return;
}
}
//顶点已搜索将该顶点出栈
onStack[v] = false;
}
//判断顶点w和顶点s是否相同
public boolean hasCycle() {
return hasCycle;
}
public static void main(String[] args) throws Exception{
//构建缓冲流
BufferedReader reader = new BufferedReader(new InputStreamReader
(new FileInputStream(new File("TopoLogical.txt"))));
//读取城市数目,初始化Graph图
int total = Integer.parseInt(reader.readLine());
Digraph digraph = new Digraph(total);
//读取已经修建好的道路数量
int number = Integer.parseInt(reader.readLine());
//循环读取已经修建好的道路
for (int i = 0; i < number; i++) {
String line = reader.readLine();
String[] str = line.split(" ");
int p = Integer.parseInt(str[0]);
int q = Integer.parseInt(str[1]);
digraph.addEdge(p,q);
}
reader.close();
//创建检测环对象
DirectedCycle cycle = new DirectedCycle(digraph);
//输出图中是否有环
System.out.println("图中是否有环:" + cycle.hasCycle);
}
}
2.2 基于深度优先的顶点排序
如果要把图中的顶点生成线性序列其实是一件非常简单的事,之前我们学习并使用了多次深度优先搜索,我们会发现其实深度优先搜索有一个特点,那就是在一个连通子图上,每个顶点只会被搜索一次,如果我们能在深度优先搜索的基础上,添加一行代码,只需要将搜索的顶点放入到线性序列的数据结构中,我们就能完成这件事。
2.2.1 顶点排序API设计

2.2.2 顶点排序实现
在API的设计中,我们添加了一个栈reversePost用来存储顶点,当我们深度搜索图时,每搜索完毕一个顶点,把该顶点放入到reversePost中,这样就可以实现顶点排序。

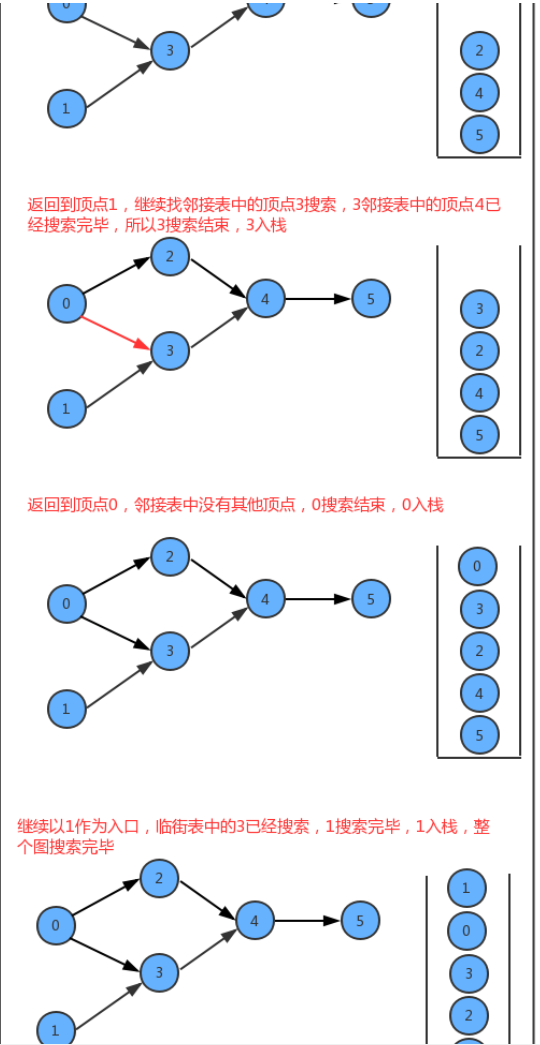

深度优先搜索中顶点排序的实现
package Graph;
import LinkTable.Stack;
/**
* @author Fantic
* @create 2021-08-22 22:36
*/
//需要引用有向图Digraph类
public class DepthFirstOrder {
//索引代表顶点,值表示当前顶点是否已经被搜索
private boolean[] marked;
//使用栈,存储顶点的序列
private Stack<Integer> reversePost;
//创建一个检测环对象,检测图中是否有环
public DepthFirstOrder(Digraph digraph) {
//创建一个和图的顶点数一样大小的marked数组
this.marked = new boolean[digraph.V()];
this.reversePost = new Stack<Integer>();
//遍历搜索图中的每一个顶点
for (int v = 0; v < digraph.V(); v++) {
//如果当前顶点没有搜索,递归调用dfs
if (!marked[v]){
dfs(digraph,v);
}
}
}
//基于深度优先搜索,对顶点进行排序
private void dfs(Digraph digraph,int v){
//把当前顶点标记为已搜索
marked[v] = true;
//遍历顶点v的邻接表,得到邻接表中每一个顶点w
for (Integer w : digraph.adj(v)) {
//如果当前顶点w没有被搜索过,则递归调用与w顶点邻接表中的每一个顶点
if (!marked[w]){
dfs(digraph,w);
}
}
//当前顶点已搜索完毕,将该顶点放入栈中
reversePost.push(v);
}
//获取顶点线性序列
public Stack<Integer> reversePost() {
return reversePost;
}
}
2.3 拓扑排序实现
前面已经实现了环的检测以及顶点排序,那么拓扑排序就很简单了,基于一幅图,先检测有没有环,如果没有环,则调用顶点排序即可。
API设计:

拓扑排序代码实现
package Graph;
import LinkTable.Stack;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
/**
* @author Fantic
* @create 2021-08-22 22:36
*/
public class TopoLogical {
//顶点的拓扑排序
private Stack<Integer> order;
//构造拓扑排序的对象
public TopoLogical(Digraph digraph){
//创建检测环对象,检测图中是否有环
DirectedCycle cycle = new DirectedCycle(digraph);
if (!cycle.hasCycle()){
//如果没有环,则创建顶点排序,进行顶点排序
DepthFirstOrder depthFirstOrder = new DepthFirstOrder(digraph);
order = depthFirstOrder.reversePost();
}
}
//判断图中是否有环
public boolean isCycle(){
//如果排序中没有元素,则图中有环
return order == null;
}
//获取拓扑排序的所有顶点
public Stack<Integer> order() {
return order;
}
public static void main(String[] args) throws Exception{
//构建缓冲流
BufferedReader reader = new BufferedReader(new InputStreamReader
(new FileInputStream(new File("TopoLogical.txt"))));
//读取城市数目,初始化Graph图
int total = Integer.parseInt(reader.readLine());
Digraph digraph = new Digraph(total);
//读取已经修建好的道路数量
int number = Integer.parseInt(reader.readLine());
//循环读取已经修建好的道路
for (int i = 0; i < number; i++) {
String line = reader.readLine();
String[] str = line.split(" ");
int p = Integer.parseInt(str[0]);
int q = Integer.parseInt(str[1]);
digraph.addEdge(p,q);
}
reader.close();
//创建拓扑排序对象
TopoLogical topoLogical = new TopoLogical(digraph);
Stack<Integer> order = topoLogical.order();
//遍历打印出按照顺序出现的排序结果
StringBuilder builder = new StringBuilder();
for (Integer v : order) {
builder.append(v + "->");
}
builder.deleteCharAt(builder.length() - 1);
builder.deleteCharAt(builder.length() - 1);
System.out.println("拓扑排序的结果是:" + builder);
}
}
三、加权无向图
加权无向图是一种为每条边关联一个权重值或是成本的图模型。这种图能够自然地表示许多应用。在一副航空图中,边表示航线,权值则可以表示距离或是费用。在一副电路图中,边表示导线,权值则可能表示导线的长度即成本,或是信号通过这条先所需的时间。此时我们很容易就能想到,最小成本的问题,例如,从西安飞纽约,怎样飞才能使时间成本最低或者是金钱成本最低?
在下图中,从顶点0到顶点4有三条路径,分别为0-2-3-4,0-2-4,0-5-3-4,那我们如果要通过那条路径到达4顶点最好呢?此时就要考虑,那条路径的成本最低。

3.1 加权无向图边的表示
加权无向图中的边我们就不能简单的使用v-w两个顶点表示了,而必须要给边关联一个权重值,因此我们可以使用对象来描述一条边。
API设计:

加权无向图边的表示
package Graph;
/**
* @author Fantic
* @create 2021-08-23 14:55
*/
public class Edge implements Comparable<Edge>{
//顶点一
private final int v;
//顶点二
private final int w;
//当前边的权重
private final double weight;
//通过顶点v和w,以及权重wieght值构造有一个边对象
public Edge(int v, int w, double weight) {
this.v = v;
this.w = w;
this.weight = weight;
}
//获取边的权重值
public double weight(){
return weight;
}
//获取边上一点
public int either(){
return v;
}
//获取边上除顶点vertex外的另一个顶点
public int other(int vertex) {
if (vertex == v){
//如果传入的顶点vertex是v,则返回另外一个顶点
return w;
}else {
//如果传入的顶点不是v,则返回v即可
return v;
}
}
//
@Override
public int compareTo(Edge that) {
int temp;
if (this.weight() > that.weight()){
temp = 1;
}else if (this.weight() < that.weight()){
temp = -1;
}else{
temp = 0;
}
return temp;
}
}
3.2 加权无向图的实现
之前我们已经完成了无向图,在无向图的基础上,我们只需要把边的表示切换成Edge对象即可。
API设计:

加权无向图的代码实现
package Graph;
import LinkTable.Queue;
/**
* @author Fantic
* @create 2021-08-22 22:36
*/
public class EdgeWeightedGraph {
//顶点总数
private final int V;
//边的数量
private int E;
//邻接表
private Queue<Edge>[] adj;
//创建一个含有V个顶点的空加权无向图
public EdgeWeightedGraph(int V) {
//初始化顶点数量
this.V = V;
//初始化边的数量
this.E = 0;
//初始化邻接表
this.adj = new Queue[V];
//初始化邻接表中的空队列
for (int i = 0; i < adj.length; i++) {
adj[i] = new Queue<Edge>();
}
}
//获取图中顶点的数量
public int V(){
return V;
}
//获取图中边的数量
public int E() {
return E;
}
//向加权无向图中添加一条边
public void addEdge(Edge edge){
//获取边的一头顶点
int v = edge.either();
//获取另一个顶点
int w = edge.other(v);
//由于是无向图,改变需要同时出现在两个顶点的邻接表中
adj[v].enqueue(edge);
adj[w].enqueue(edge);
//边的数量+1
E++;
}
//获取和顶点v关联的所有边
public Queue<Edge> adj(int v){
return adj[v];
}
//获取加权无向图的所有边
public Queue<Edge> edges() {
//创建一个队列存储所有的边
Queue<Edge> allEdge = new Queue<>();
//遍历顶点,拿到每个顶点的邻接表
for (int v = 0; v < this.V; v++) {
//遍历邻接表,拿到邻接表中的每条边
for (Edge e : adj(v)) {
//在无向图中,每条边对象都会在两个顶点的邻接表中出现一次
//出了当前顶点v,获取边的另一顶点w,如果v<w则添加边,确保只统计一次
if (e.other(v) < v){
allEdge.enqueue(e);
}
}
}
return allEdge;
}
}
四、最小生成树
4.1 最小生成树定义及相关约定
定义: 图的生成树是它的一棵含有其所有顶点的无环连通子图,一副加权无向图的最小生成树它的一棵权值(树中所有边的权重之和)最小的生成树

**约定:**只考虑连通图。最小生成树的定义说明它只能存在于连通图中,如果图不是连通的,那么分别计算每个连通图子图的最小生成树,合并到一起称为最小生成森林。

所有边的权重都各不相同。如果不同的边权重可以相同,那么一副图的最小生成树就可能不唯一了,虽然我们的算法可以处理这种情况,但为了好理解,我们约定所有边的权重都各不相同。
4.2 最小生成树原理
4.2.1 树的性质
1.用一条边接树中的任意两个顶点都会产生一个新的环;
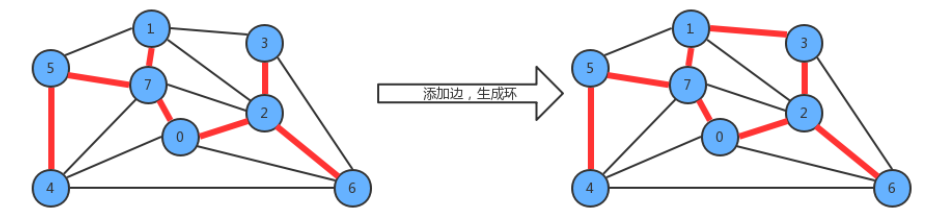
2.从树中删除任意一条边,将会得到两棵独立的树;

4.2.2 切分定理
要从一副连通图中找出该图的最小生成树,需要通过切分定理完成。
**切分:**将图的所有顶点按照某些规则分为两个非空且没有交集的集合。
**横切边:**连接两个属于不同集合的顶点的边称之为横切边。
例如我们将图中的顶点切分为两个集合,灰色顶点属于一个集合,白色顶点属于另外一个集合,那么效果如下:

切分定理: 在一副加权图中,给定任意的切分,它的横切边中的权重最小者必然属于图中的最小生成树。
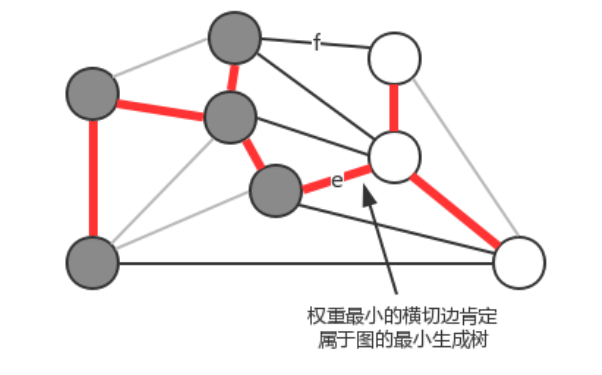
==注意:==一次切分产生的多个横切边中,权重最小的边不一定是所有横切边中唯一属于图的最小生成树的边 。

4.3 贪心算法
贪心算法是计算图的最小生成树的基础算法,它的基本原理就是切分定理,使用切分定理找到最小生成树的一条边,不断的重复直到找到最小生成树的所有边。如果图有V个顶点,那么需要找到V-1条边,就可以表示该图的最小生成树。


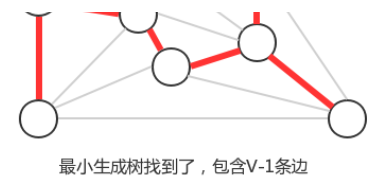
计算图的最小生成树的算法有很多种,但这些算法都可以看做是贪心算法的一种特殊情况,这些算法的不同之处在于保存切分和判定权重最小的横切边的方式。
4.4 Prim算法
学习第一种计算最小生成树的方法叫Prim算法,它的每一步都会为一棵生成中的树添加一条边。一开始这棵树只有一个顶点,然后会向它添加V-1条边,每次总是将下一条连接树中的顶点与不在树中的顶点且权重最小的边加入到树中。
**Prim算法的切分规则:**把最小生成树中的顶点看做是一个集合,把不在最小生成树中的顶点看做是另外一个集合。

4.4.1 Prim算法API设计
4.4.2 Prim算法的实现原理
Prim算法始终将图中的顶点切分成两个集合,最小生成树顶点和非最小生成树顶点,通过不断的重复做某些操作,可以逐渐将非最小生成树中的顶点加入到最小生成树中,直到所有的顶点都加入到最小生成树中。
我们在设计API的时候,使用最小索引优先队列存放树中顶点与非树中顶点的有效横切边,那么它是如何表示的呢?我们可以让最小索引优先队列的索引值表示图的顶点,让最小索引优先队列中的值表示从其他某个顶点到当前顶点的边权重。

初始化状态,先默认0是最小生成树中的唯一顶点,其他的顶点都不在最小生成树中,此时横切边就是顶点0的邻接表中0-2,0-4,0-6,0-7这四条边,我们只需要将索引优先队列的2、4、6、7索引处分别存储这些边的权重值就可以表示了。
现在只需要从这四条横切边中找出权重最小的边,然后把对应的顶点加进来即可。所以找到0-7这条横切边的权重最小,因此把0-7这条边添加进来,此时0和7属于最小生成树的顶点,其他的不属于,现在顶点7的邻接表中的边也成为了横切边,这时需要做两个操作:
- 0-7这条边已经不是横切边了,需要让它失效:只需要调用最小索引优先队列的delMin()方法即可完成;
- 2和4顶点各有两条连接指向最小生成树,需要只保留一条:
- 4-7的权重小于0-4的权重,所以保留4-7,调用索引优先队列的change(4,0.37)即可,
- 0-2的权重小于2-7的权重,所以保留0-2,不需要做额外操作。
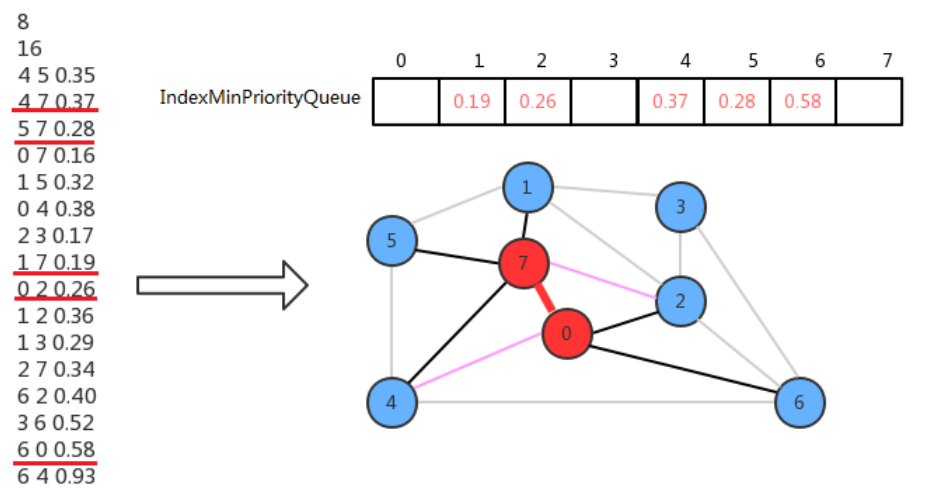
我们不断重复上面的动作,就可以把所有的顶点添加到最小生成树中。
4.4.3 代码
Prim算法 代码实现
package Graph;
import LinkTable.Queue;
import Priority.IndexMinPriorityQueue;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
public class PrimMST {
//索引代表顶点,值表示当前顶点和最小生成树之间的最短边
private Edge[] edgeTo;
//索引代表顶点,值表示当前顶点和最小生成树之间的最短边的权重
private double[] distTo;
//索引代表顶点,如果当前顶点已经在树中,则值为true,否则为false
private boolean[] marked;
//存放树中顶点与非树中顶点之间的有效横切边
private IndexMinPriorityQueue<Double> pq;
//根据一副加权无向图,创建最小生成树计算对象
public PrimMST(EdgeWeightedGraph G) {
创建一个和图的顶点数一样大小的Edge数组,表示边
this.edgeTo = new Edge[G.V()];
//创建一个和图的顶点数一样大小的double数组,表示权重,并且初始化数组中的内容为无穷大,无穷大即表示不存在这样的边
this.distTo = new double[G.V()];
for (int i = 0; i < distTo.length; i++) {
distTo[i] = Double.POSITIVE_INFINITY;
}
//创建一个和图的顶点数一样大小的boolean数组,表示当前顶点是否已经在树中
this.marked = new boolean[G.V()];
//创建一个和图的顶点数一样大小的索引优先队列,存储有效横切边
pq = new IndexMinPriorityQueue<Double>(G.V());
//默认让顶点0进入到树中,但是树中只有一个顶点0,因此,0顶点默认没有和其他的顶点相连,所以让distTo对应位置处的值存储0.0
distTo[0] = 0.0;
pq.insert(0,0.0);
//遍历索引最小优先队列,拿到最小和N切边对应的顶点,把该顶点加入到最小生成树中
while (!pq.isEmpty()){
visit(G,pq.delMin());
}
}
//将顶点v添加到最小生成树中,并且更新数据
private void visit(EdgeWeightedGraph G, int v) {
//把顶点v添加到最小生成树中
marked[v] = true;
//更新数据
for (Edge e : G.adj(v)) {
//获取e边的另外一个顶点(当前顶点是v)
int w = e.other(v);
//判断另外一个顶点是不是已经在树中,如果在树中,则不做任何处理,如果不再树中,更新数据
if (marked[w]){
continue;
}
//判断边e的权重是否小于从w顶点到树中已经存在的最小边的权重;
if (e.weight()<distTo[w]){
//更新数据
edgeTo[w] = e;
distTo[w] = e.weight();
//如果pq中存储的有效横切边已经包含了w顶点,则需要修正最小索引优先队列w索引关联的权重值
if (pq.contains(w)){
pq.changeItem(w,e.weight());
}else{
//如果pq中存储的有效横切边不包含w顶点,则需要向最小索引优先队列中添加v-w和其权重值
pq.insert(w,e.weight());
}
}
}
}
//获取最小生成树的所有边
public Queue<Edge> edges() {
//创建队列对象
Queue<Edge> allEdges = new Queue<>();
//遍历edgeTo数组,拿到每一条边,如果不为null,则添加到队列中
for (int i = 0; i < edgeTo.length; i++) {
if (edgeTo[i]!=null){
allEdges.enqueue(edgeTo[i]);
}
}
return allEdges;
}
public static void main(String[] args) throws Exception{
//构建缓冲流
BufferedReader br = new BufferedReader(new InputStreamReader
(new FileInputStream(new File("min_create_tree_test.txt"))));
int total = Integer.parseInt(br.readLine());
EdgeWeightedGraph G = new EdgeWeightedGraph(total);
int edgeNumbers = Integer.parseInt(br.readLine());
for (int e = 1;e<=edgeNumbers;e++){
String line = br.readLine();//4 5 0.35
String[] strs = line.split(" ");
int v = Integer.parseInt(strs[0]);
int w = Integer.parseInt(strs[1]);
double weight = Double.parseDouble(strs[2]);
//构建加权无向边
Edge edge = new Edge(v, w, weight);
G.addEdge(edge);
}
//创建一个PrimMST对象,计算加权无向图中的最小生成树
PrimMST primMST = new PrimMST(G);
//获取最小生成树中的所有边
Queue<Edge> edges = primMST.edges();
//遍历打印所有的边
for (Edge e : edges) {
int v = e.either();
int w = e.other(v);
double weight = e.weight();
System.out.println(v+"-"+w+" :: "+weight);
}
}
}
4.5 kruskal算法
kruskal算法是计算一副加权无向图的最小生成树的另外一种算法,它的主要思想是按照边的权重(从小到大)处理它们,将边加入最小生成树中,加入的边不会与已经加入最小生成树的边构成环,直到树中含有V-1条边为止。
kruskal算法和prim算法的区别:
Prim算法是一条边一条边的构造最小生成树,每一步都为一棵树添加一条边。kruskal算法构造最小生成树的时候也是一条边一条边地构造,但它的切分规则是不一样的。它每一次寻找的边会连接一片森林中的两棵树。如果一副加权无向图由V个顶点组成,初始化情况下每个顶点都构成一棵独立的树,则V个顶点对应V棵树,组成一片森林,kruskal算法每一次处理都会将两棵树合并为一棵树,直到整个森林中只剩一棵树为止。
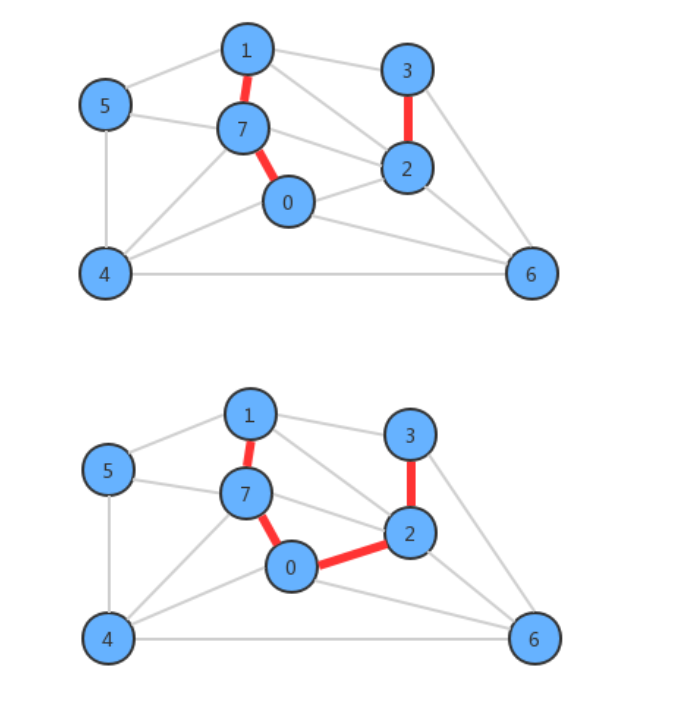
4.5.1 kruskal算法API设计

4.5.2 kruskal算法的实现原理
在设计API的时候,使用了一个MinPriorityQueue pq存储图中所有的边,每次使用pq.delMin()取出权重最小的
边,并得到该边关联的两个顶点v和w,通过uf.connect(v,w)判断v和w是否已经连通,如果连通,则证明这两个顶
点在同一棵树中,那么就不能再把这条边添加到最小生成树中,因为在一棵树的任意两个顶点上添加一条边,都会形成环,而最小生成树不能有环的存在,如果不连通,则通过uf.connect(v,w)把顶点v所在的树和顶点w所在的树合并成一棵树,并把这条边加入到mst队列中,这样如果把所有的边处理完,最终mst中存储的就是最小生树的所有边。





4.5.3 代码
kruskal算法代码实现
package Graph;
import LinkTable.Queue;
import Priority.MinPriorityQueue;
import UnionFind.UnionFindTreeWeight;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
/**
* @author Fantic
* @create 2021-08-22 22:37
*/
public class KruskalMST {
//保存最小生成树的所有边
private Queue<Edge> mst;
//索引代表顶点,使用uf.connect(v,w)可以判断顶点v和顶点w是否在同一颗树中,使用uf.union(v,w)可以把顶点v所在的树和顶点w所在的树合并
private UnionFindTreeWeight uf;
//存储图中所有的边,使用最小优先队列,对边按照权重进行排序
private MinPriorityQueue<Edge> pq;
//根据一副加权无向图,创建最小生成树计算对象
public KruskalMST(EdgeWeightedGraph G) {
//初始化mst
this.mst = new Queue<Edge>();
//初始化uf
this.uf = new UnionFindTreeWeight(G.V());
//初始化最小优先队列pq,容量比图的边的数量大1,并把图中所有的边放入pq中
this.pq = new MinPriorityQueue<>(G.E()+1);
//把图中所有的边存储到pq中
for (Edge e : G.edges()) {
pq.insert(e);
}
//如果优先队列pq不为空,也就是还有边未处理,并且mst中的边还不到V-1条,继续遍历
while(!pq.isEmpty() && mst.size()<G.V()-1){
//找到权重最小的边
Edge e = pq.delMin();
//找到该边的两个顶点
/*
通过uf.connect(v,w)判断v和w是否已经连通,
如果连通:
则证明这两个顶点在同一棵树中,那么就不能再把这条边添加到最小生成树中,因为在一棵
树的任意两个顶点上添加一条边,都会形成环,
而最小生成树不能有环的存在;
如果不连通:
则通过uf.connect(v,w)把顶点v所在的树和顶点w所在的树合并成一棵树,并把这条边加入
到mst队列中
*/
int v = e.either();
int w = e.other(v);
//判断这两个顶点是否已经在同一颗树中,如果在同一颗树中,则不对该边做处理,如果不在一棵树中,则让这两个顶点属于的两棵树合并成一棵树
if (uf.isConnected(v,w)){
continue;
}
uf.union(v,w);
//让边e进入到mst队列中
mst.enqueue(e);
}
}
//获取最小生成树的所有边
public Queue<Edge> edges() {
return mst;
}
public static void main(String[] args) throws Exception{
//构建缓冲流
BufferedReader br = new BufferedReader(new InputStreamReader
(new FileInputStream(new File("min_create_tree_test.txt"))));
int total = Integer.parseInt(br.readLine());
EdgeWeightedGraph G = new EdgeWeightedGraph(total);
int edgeNumbers = Integer.parseInt(br.readLine());
for (int e = 1;e<=edgeNumbers;e++){
String line = br.readLine();//4 5 0.35
String[] strs = line.split(" ");
int v = Integer.parseInt(strs[0]);
int w = Integer.parseInt(strs[1]);
double weight = Double.parseDouble(strs[2]);
//构建加权无向边
Edge edge = new Edge(v, w, weight);
G.addEdge(edge);
}
//创建一个KruskalMST对象,计算加权无向图中的最小生成树
KruskalMST kruskalMST = new KruskalMST(G);
//获取最小生成树中的所有边
Queue<Edge> edges = kruskalMST.edges();
//遍历打印所有的边
for (Edge e : edges) {
int v = e.either();
int w = e.other(v);
double weight = e.weight();
System.out.println(v+"-"+w+" :: "+weight);
}
/*
0-7 :: 0.16
2-3 :: 0.17
0-2 :: 0.26
1-3 :: 0.29
1-5 :: 0.32
4-5 :: 0.35
6-2 :: 0.4
*/
}
}
五、加权有向图
之前学习的加权无向图中,边是没有方向的,并且同一条边会同时出现在该边的两个顶点的邻接表中,为了能够处理含有方向性的图的问题,我们需要实现以下加权有向图。
5.1加权有向图边的表示
API设计 :

加权有向图边的代码表示
package Graph;
/**
* @author Fantic
* @create 2021-08-23 16:59
*/
public class DirectedEdge {
private final int v;//起点
private final int w;//终点
private final double weight;//当前边的权重
//通过顶点v和w,以及权重weight值构造一个边对象
public DirectedEdge(int v, int w, double weight) {
this.v = v;
this.w = w;
this.weight = weight;
}
//获取边的权重值
public double weight(){
return weight;
}
//获取有向边的起点
public int from(){
return v;
}
//获取有向边的终点
public int to(){
return w;
}
}
5.2 加权有向图的实现
加权有向图的代码实现
package Graph;
import LinkTable.Queue;
/**
* @author Fantic
* @create 2021-08-22 22:37
*/
public class EdgeWeightedDigraph {
//顶点总数
private final int V;
//边的总数
private int E;
//邻接表
private Queue<DirectedEdge>[] adj;
//创建一个含有V个顶点的空加权有向图
public EdgeWeightedDigraph(int V) {
//初始化顶点数量
this.V = V;
//初始化边的数量
this.E = 0;
//初始化邻接表
this.adj = new Queue[V];
for (int i = 0; i < adj.length; i++) {
adj[i] = new Queue<DirectedEdge>();
}
}
//获取图中顶点的数量
public int V() {
return V;
}
//获取图中边的数量
public int E() {
return E;
}
//向加权有向图中添加一条边e
public void addEdge(DirectedEdge e) {
//边e是有方向的,所以只需要让e出现在起点的邻接表中即可
int v = e.from();
adj[v].enqueue(e);
E++;
}
//获取由顶点v指出的所有的边
public Queue<DirectedEdge> adj(int v) {
return adj[v];
}
//获取加权有向图的所有边
public Queue<DirectedEdge> edges() {
//遍历图中的每一个顶点,得到该顶点的邻接表,遍历得到每一条边,添加到队列中返回即可
Queue<DirectedEdge> allEdges = new Queue<>();
for (int v = 0;v<V;v++){
for (DirectedEdge edge : adj[v]) {
allEdges.enqueue(edge);
}
}
return allEdges;
}
}
六、最短路径
有了加权有向图之后,我们立刻就能联想到实际生活中的使用场景,例如在一副地图中,找到顶点a与地点b之间的路径,这条路径可以是距离最短,也可以是时间最短,也可以是费用最小等,如果我们把 距离/时间/费用 看做是成本,那么就需要找到地点a和地点b之间成本最小的路径,也就是我们接下来要解决的最短路径问题。
6.1 最短路径定义及性质
**定义:**在一副加权有向图中,从顶点s到顶点t的最短路径是所有从顶点s到顶点t的路径中总权重最小的那条路径。

性质:
- 路径具有方向性;
- 权重不一定等价于距离。权重可以是距离、时间、花费等内容,权重最小指的是成本最低
- 只考虑连通图。一副图中并不是所有的顶点都是可达的,如果s和t不可达,那么它们之间也就不存在最短路径,为了简化问题,这里只考虑连通图。
- 最短路径不一定是唯一的。从一个顶点到达另外一个顶点的权重最小的路径可能会有很多条,这里只需要找出一条即可。
最短路径树:给定一副加权有向图和一个顶点s,以s为起点的一棵最短路径树是图的一副子图,它包含顶点s以及从s可达的所有顶点。这棵有向树的根结点为s,树的每条路径都是有向图中的一条最短路径。
6.2 最短路径树API设计
计算最短路径树的经典算法是dijstra算法,为了实现它,先设计如下API:

6.3 松弛技术
松弛这个词来源于生活:一条橡皮筋沿着两个顶点的某条路径紧紧展开,如果这两个顶点之间的路径不止一条,还有存在更短的路径,那么把皮筋转移到更短的路径上,皮筋就可以放松了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RxJxAIYD-1629715981525)(C:/Users/dell/AppData/Roaming/Typora/typora-user-images/image-20210823170552732.png)]
松弛这种简单的原理刚好可以用来计算最短路径树。
在我们的API中,需要用到两个成员变量edgeTo和distTo,分别存储边和权重。一开始给定一幅图G和顶点s,我们只知道图的边以及这些边的权重,其他的一无所知,此时初始化顶点s到顶点s的最短路径的总权重disto[s]=0;顶点s到其他顶点的总权重默认为无穷大,随着算法的执行,不断的使用松弛技术处理图的边和顶点,并按一定的条件更新edgeTo和distTo中的数据,最终就可以得到最短路劲树。
边的松弛:
放松边v->w意味着检查从s到w的最短路径是否先从s到v,然后再从v到w?
如果是,则v-w这条边需要加入到最短路径树中,更新edgeTo和distTo中的内容:edgeTo[w]=表示v->w这条边的DirectedEdge对象,distTo[w]=distTo[v]+v->w这条边的权重;
如果不是,则忽略v->w这条边。
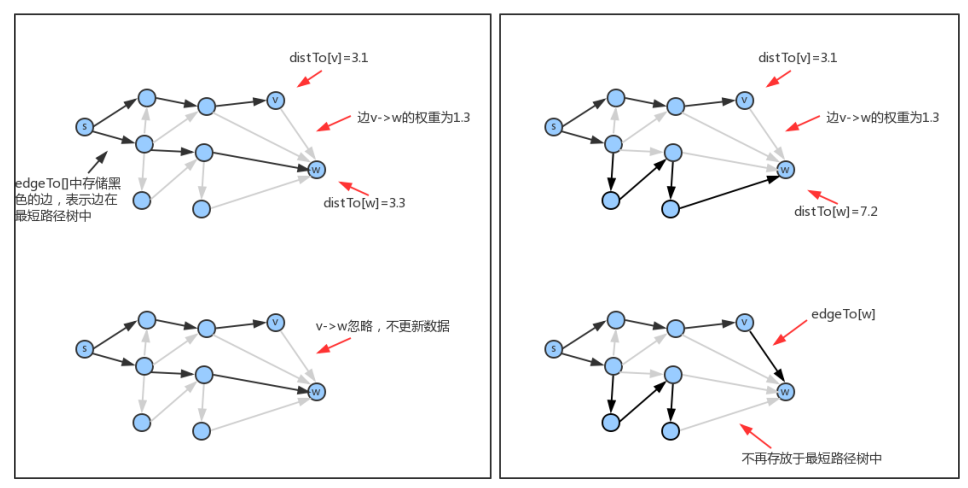
顶点的松弛:
顶点的松弛是基于边的松弛完成的,只需要把某个顶点指出的所有边松弛,那么该顶点就松弛完毕。例如要松弛顶点v,只需要遍历v的邻接表,把每一条边都松弛,那么顶点v就松弛了。
如果把起点设置为顶点0,那么找出起点0到顶点6的最短路径0->2->7>3->6的过程如下:

6.4 Dijstra算法实现
Disjstra算法的实现和Prim算法很类似,构造最短路径树的每一步都是向这棵树中添加一条新的边,而这条新的边是有效横切边pq队列中的权重最小的边。
Dijstra算法代码实现
package Graph;
import LinkTable.Queue;
import Priority.IndexMinPriorityQueue;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
/**
* @author Fantic
* @create 2021-08-22 22:37
*/
public class DijkstraSP {
//索引代表顶点,值表示从顶点s到当前顶点的最短路径上的最后一条边
private DirectedEdge[] edgeTo;
//索引代表顶点,值从顶点s到当前顶点的最短路径的总权重
private double[] distTo;
//存放树中顶点与非树中顶点之间的有效横切边
private IndexMinPriorityQueue<Double> pq;
//根据一副加权有向图G和顶点s,创建一个计算顶点为s的最短路径树对象
public DijkstraSP(EdgeWeightedDigraph G, int s){
//初始化edgeTo
this.edgeTo = new DirectedEdge[G.V()];
//初始化distTo
this.distTo = new double[G.V()];
for (int i = 0; i < distTo.length; i++) {
distTo[i] = Double.POSITIVE_INFINITY;
}
//初始化pq
this.pq = new IndexMinPriorityQueue<>(G.V());
//找到图G中以顶点s为起点的最短路径树
//默认让顶点s进入到最短路径树中
distTo[s] = 0.0;
pq.insert(s,0.0);
//遍历pq
while(!pq.isEmpty()){
//松弛图G中的顶点
relax(G,pq.delMin());
}
}
//松弛图G中的顶点v
private void relax(EdgeWeightedDigraph G, int v){
for (DirectedEdge edge : G.adj(v)) {
//获取到该边的终点w
int w = edge.to();
//起点s到顶点w的权重是否大于起点s到顶点v的权重+边e的权重,如果大于,则修改s->w的路径:
//edgeTo[w]=e,并修改distTo[v] = distTo[v]+e.weitht(),如果不大于,则忽略
if (distTo(v)+edge.weight()<distTo(w)){
distTo[w] = distTo[v]+edge.weight();
edgeTo[w] = edge;
//判断pq中是否已经存在顶点w,如果存在,则更新权重,如果不存在,则直接添加
if (pq.contains(w)){
pq.changeItem(w,distTo(w));
}else{
pq.insert(w,distTo(w));
}
}
}
}
//获取从顶点s到顶点v的最短路径的总权重
public double distTo(int v){
return distTo[v];
}
//判断从顶点s到顶点v是否可达
public boolean hasPathTo(int v){
return distTo[v]<Double.POSITIVE_INFINITY;
}
//查询从起点s到顶点v的最短路径中所有的边
public Queue<DirectedEdge> pathTo(int v){
//判断从顶点s到顶点v是否可达,如果不可达,直接返回null
if (!hasPathTo(v)){
return null;
}
//创建队列对象
Queue<DirectedEdge> allEdges = new Queue<>();
while (true){
DirectedEdge e = edgeTo[v];
if (e==null){
break;
}
allEdges.enqueue(e);
v = e.from();
}
return allEdges;
}
public static void main(String[] args) throws Exception{
//创建一副加权有向图
BufferedReader br = new BufferedReader(new InputStreamReader
(new FileInputStream(new File("min_route_test.txt"))));
int total = Integer.parseInt(br.readLine());
EdgeWeightedDigraph G = new EdgeWeightedDigraph(total);
int edgeNumbers = Integer.parseInt(br.readLine());
for(int i=1;i<=edgeNumbers;i++){
String line = br.readLine();//4 5 0.35
String[] strs = line.split(" ");
int v = Integer.parseInt(strs[0]);
int w = Integer.parseInt(strs[1]);
double weight = Double.parseDouble(strs[2]);
DirectedEdge e = new DirectedEdge(v, w, weight);
G.addEdge(e);
}
//创建DijkstraSP对象,查找最短路径树
DijkstraSP dijkstraSP = new DijkstraSP(G, 0);
//查找最短路径,0->6的最短路径
Queue<DirectedEdge> edges = dijkstraSP.pathTo(6);
//遍历打印
for (DirectedEdge edge : edges) {
System.out.println(edge.from()+"->"+edge.to()+" :: "+edge.weight());
}
}
}
















 190
190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











