






译:DBDnet:图像去噪的深度提升策略
-- IEEE TRANSACTIONS ON MULTIMEDIA -- 2021
目录
一、引言
在基于学习的去噪方法中,残差学习是最常用的去噪方法。这种方法可以将有噪声的观测结果生成噪声图,进而得到无噪声图像,如图1所示。

然而,基于残差学习的方法即使采用复杂的网络也很难获得精确的噪声图,即噪声图总是包含一些噪声。作者把这种噪声称为噪声图的噪声(NoN)。直观上,NoN越多,去噪性能越低,寻找一种有效的方法来减少NoN的影响,对于获得高质量的图像至关重要。
以往基于深度学习的方法很少考虑这一问题。而在传统的图像去噪领域中,采用了基于boosting的方法,并设计了一些良好的boosting模块来解决这个问题。该模块可以迭代消除噪声图中的NON,提取出干净的噪声图。因此作者在深度学习的框架下开发了boosting算法,并充分利用它们的优势来消除NoN。
下面介绍boosting算法:
近年来,人们提出了多种基于boosting的方法,“twicing”技术是一个非常早期的研究,其boosting过程描述如下:
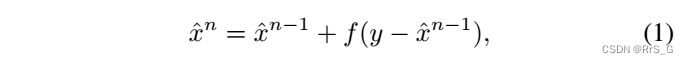
其中f是一个去噪算子,等式左边表示去噪图像的第n次迭代。
基于“twicing”技术,Bregman迭代采用了一种迭代正则化方法,该方法基于Bregman距离的概念,将残余噪声添加回观测信号。Bregman迭代的boosting过程可以写成:
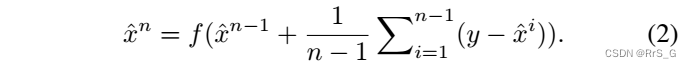
近年来,boosting算法被引入深度学习领域,以提高网络的性能。下面介绍作者的方法。
二、方法
A、动机
图像去噪的基本问题是从噪声观测y中恢复干净图像x,可以表述为:
![]()
其中v表示加性噪声映射,通常建模为零均值的高斯白噪声。残差学习网络的主要目标是从噪声观测y中生成噪声映射v的近似,这个过程可以表示为:
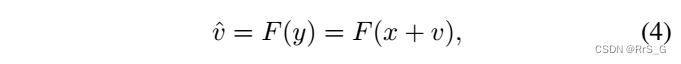
其中F表示生成噪声残差的算法,等式最左边为生成的噪声特征图(GNFM)。
此外,无噪声图像x的近似计算为:
![]()
其中等式左边为最终的去噪结果。从这个式子中看,对最终的结果影响很大,然而由于一般网络的能力限制,
将包含一些噪声(即NoN),也就是v和
是不相等的,假设存在差距u,即两者满足:
。
作者认为u受两部分影响,首先是原始图像x的高频信息(即边界信息和细节信息),特别是在生成的过程中,原始图像x的一些高频信息
会被识别为噪声,引入到
中,从而造成
的误识别部分。此外,噪声观测y的一些像素虽然被噪声污染了,但仍会被识别为干净像素。因此,不能完全从噪声观测中提取噪声图,
会包含一些未恢复的噪声信息
。
在这种情况下,u可以用来表示。也就是说,将未恢复的噪声信息
加上,减去误识别的高频信息
,就可以从
得到干净的噪声映射v。过程可以表示为:
![]()
因此,在boost过程中,可以通过以下方式更新:
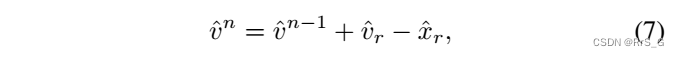
其中和
是网络模拟
和
生成的特征映射。
通过这种操作,NoN可以逐渐减少。
B、NoN消除模块
在Eq.(7)的激励下,消除NoN的过程可以分解为生成特征图、生成特征图
的过程。为此,作者提出了两种不同的NoN消除模块来生成这两种特征图。接下来,将分别详细介绍这两个非消除模块的具体实现。
(1)、模块A:模块A可以从同时生成
和
,其整体结构如图2(A)所示。
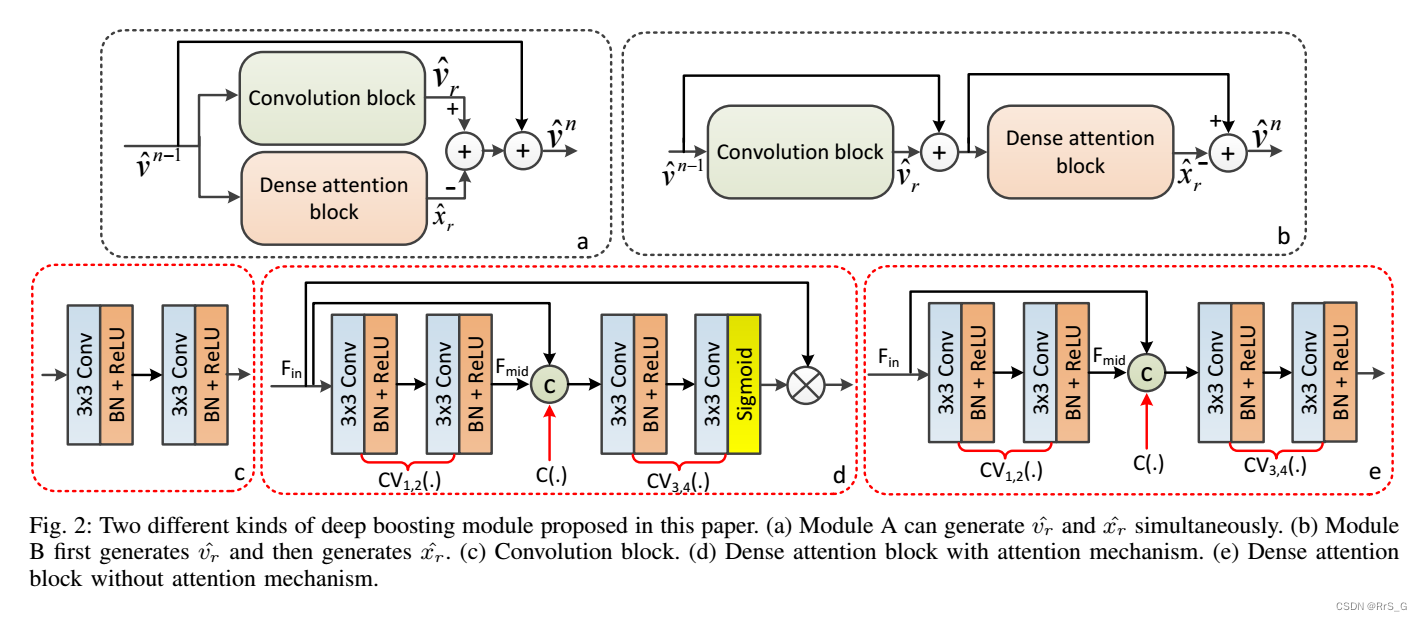
使用一个卷积块来提取未恢复的噪声映射和一个密集注意块来提取虚假高频信息
。注意,
是噪声映射v的一部分,可以很容易地从
中提取它。但是
是原始图像x的一部分而不是v的,所以为了精确提取它,作者采用了密集注意块(信息捕捉能力强)。为了提高密集注意块的复杂性和信息捕获能力,作者引入了两种先进的深度学习技术(密集连接和注意力机制),如图2(d)所示。
整个过程可以描述为:
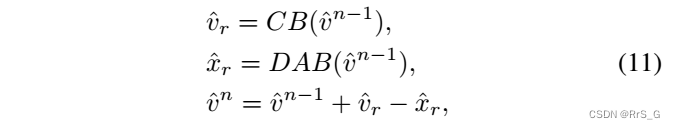
CB是卷积块,DAB表示密集注意块。
(2)、模块B:作者发现从中直接提取
和
是不精确的,因为它们在被提取过程中会互相影响,模块B就是解决这个问题的,具体如图2(b)所示。模块B首先生成
,然后减去它再作为下一个模块的输入。整个过程表示如下:
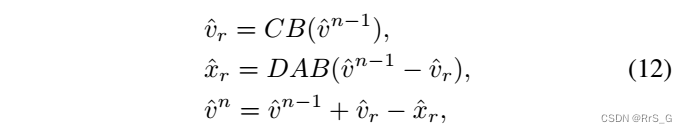
C、网络结构
在获得以上两种NoN消除模块后,将它们插入到网络中,生成本文的DBDnet。网络结构如图3所示。
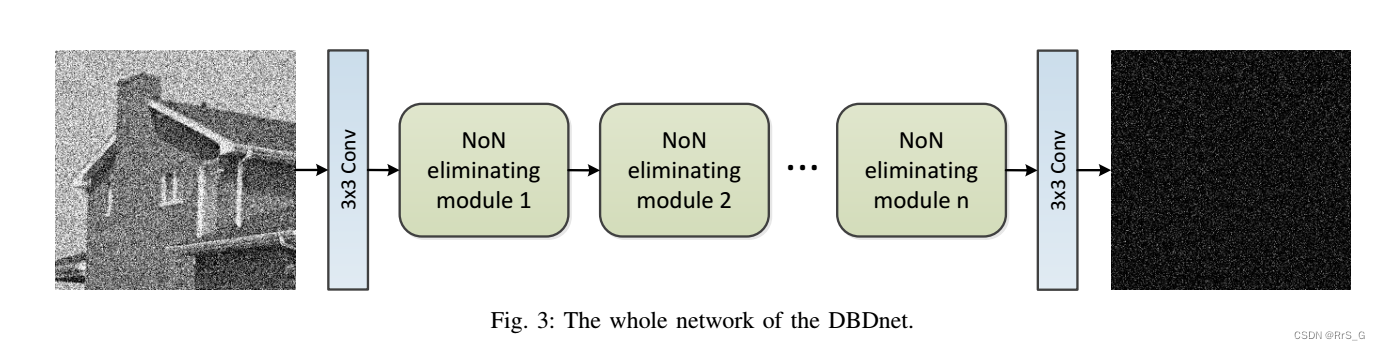
以噪声观测值y为输入,采用卷积层提取,经历过n个NoN消除模块,最后经过一个卷积层得到最终预测的噪声图。具体算法如下:
 其中
其中表示第n个NoN消除模块。
优化目标如下:
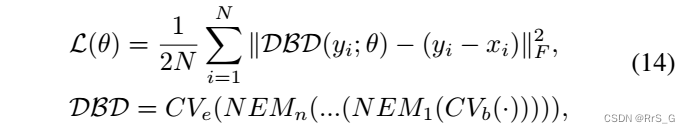
三、实验结果
下面是部分实验结果。
灰度图:
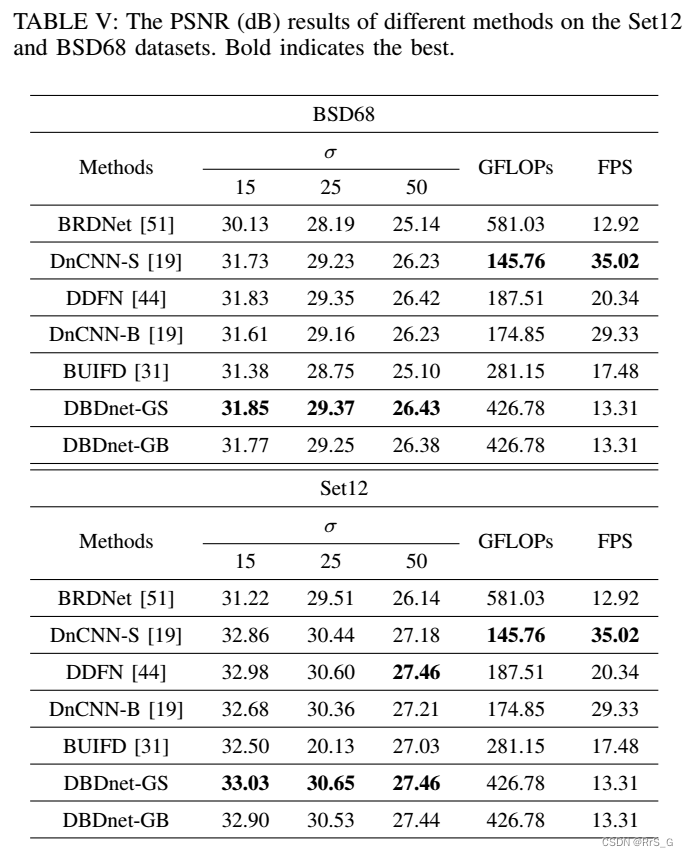
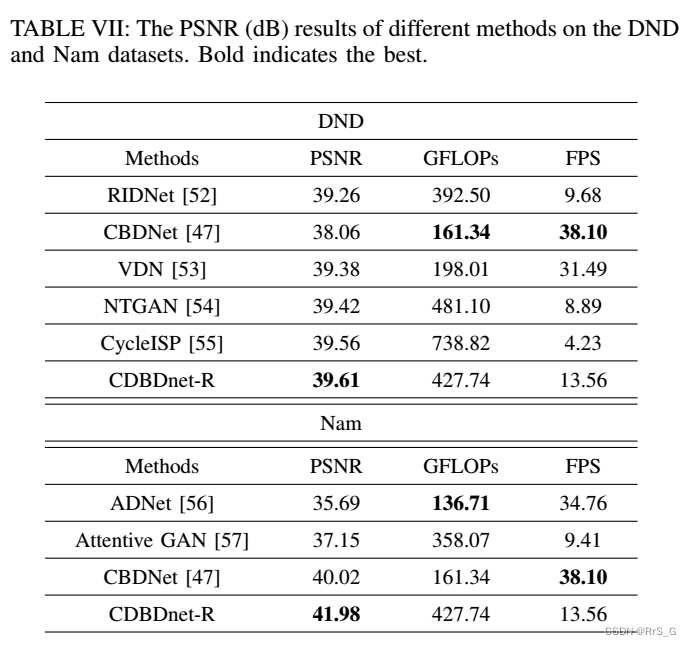
其中GFLOPs为计算复杂度,FPS为推断速度。

真实图像:

代码:
pcl111/DBDNet: Code of "DBDnet: A Deep Boosting Strategy for Image Denoising" (github.com)















 2269
2269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









