







环境
- Python3安装
- nltk库安装
在cmd中输入pip install nltk,如果显示pip不是内部或外部命令,那就是未配置环境变量,自行百度。 - 下载StanfordParser
下载好进行解压,得到文件夹stanford-parser-full-2018-10-17,文件夹的内容如下:
解压文件夹中的stanford-parser-3.9.2-models.jar,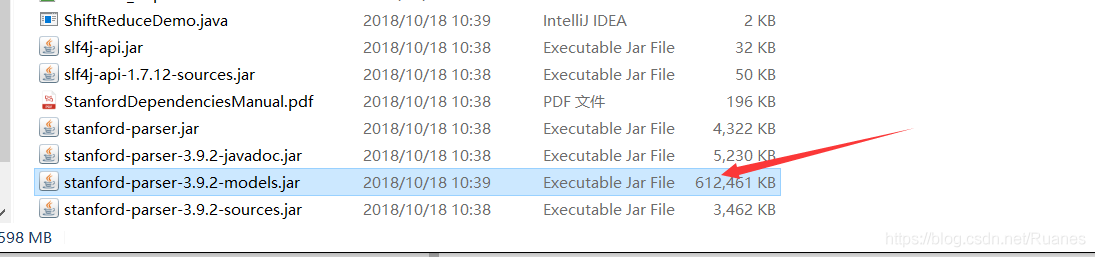
得到
使用
import os
from nltk.parse import stanford
# 这里的三个引用文件都是根据我的目录来的
# 只需要根据你的实际目录更改D:\Google\stanford-parser-full-2018-10-17即可
os.environ['STANFORD_PARSER'] = r"D:\Google\stanford-parser-full-2018-10-17\stanford-parser.jar"
os.environ['STANFORD_MODELS'] = r"D:\Google\stanford-parser-full-2018-10-17\stanford-parser-3.9.2-models.jar"
parser = stanford.StanfordDependencyParser(model_path=r"D:\Google\stanford-parser-full-2018-10-17\edu\stanford\nlp\models\lexparser\chinesePCFG.ser.gz")
res = list(parser.parse(['我','爱','NLP']))
for row in res[0].triples():
print(row)
输出:
(('爱', 'VV'), 'nsubj', ('我', 'PN'))
(('爱', 'VV'), 'dobj', ('NLP', 'NN'))
('爱', 'VV')表示爱是句子中的VV(动词)
('我', 'PN')表示我是句子中的PN(代词)
('NLP', 'NN')表示NLP是句子中的NN(名词)
nsubj表示我是爱的名词主语
dobj表示NLP是爱的直接宾语
更多句法符号表示见https://www.jianshu.com/p/5c461cf096c4















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









