









模型细节
Transformer类
首先是model.py的Transformer类
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = VocabParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
self.freqs_cis = precompute_freqs_cis(
params.dim // params.n_heads,
params.max_seq_len * 2,
params.rope_theta,
)
输入的token是int类型, 表示vocab表中的位置, 经过self.tok_embeddings的转换, 变成了dim为4096维的向量.self.tok_embeddings本质上构造了一个vocab_size*dim的数表, 根据输入的类型为int的token位置找到数表中的对应行, 然后把这一行作为输出. VocabParallelEmbedding表示在多个GPU中平均分配vocab_size, 每个GPU只处理该GPU分配到vocab, 这样做可以并行处理, 加快处理速度。
接下来是self.n_layers层数的TransformerBlock, params.josn里指定的层数为32.
RMSNorm
然后再经过RMSNorm(Root Mean Square Normalization)归一化处理。 在机器学习中, 输入经过几层计算处理后一般都会加上一层归一化处理层, 以提高模型的稳定性。按照归一化的方向分两种:batch normalization 和 layer normalization。batch normalization是指输入数据中的某一维度的数值沿着batch方向做归一化处理,layer normalization是指一个batch中的每个输入数据沿着维度方向做归一化处理。RMSNorm属于是layer normalization
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight
R M S ( x ) = 1 N ∑ i = 1 N x i 2 RMS(x) = \sqrt{\frac{1}{N}\sum_{i=1}^{N}{x_{i}^{2}}} RMS(x)=N1i=1∑Nxi2
R M S N o r m ( x ) = γ ⋅ x R M S ( x ) + ε + β RMSNorm(x) = \gamma\cdot\frac{x}{RMS(x)+\varepsilon}+\beta RMSNorm(x)=γ⋅RMS(x)+εx+β
N是维度大小即4096, γ \gamma γ是self.wight为可以学习的参数, β \beta β为0
self.output本质上是维度变换, 把输入dim为4096的输入变成vocab_size为128256维的logits输出, 使用ColumnParallelLinear也是为了再多GPU环境中并行处理,沿着列方向切分。
位置编码
self.freqs_cis是位置编码参数,llama3使用了ROPE(Rotary Position Embedding),每个位置上的向量旋转特定的角度, 把位置信息编码到向量里面。
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device, dtype=torch.float32)
freqs = torch.outer(t, freqs)
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64
return freqs_cis
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2)) 把xq向量拍扁, 每2维数据构成一个复数
接着这个复数在复平面内旋转t*freqs_i角度, 然后再把复数向量拉直 。t是位置。
f r e q s _ i = θ − 2 i d , i = 0... d 2 freqs\_i = \theta^{-\frac{2i}{d}},i=0...\frac{d}{2} freqs_i=θ−d2i,i=0...2d
θ \theta θ是rope_theta为500000.0
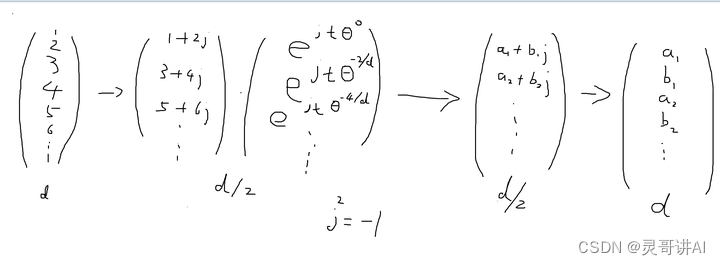
ROPE论文:
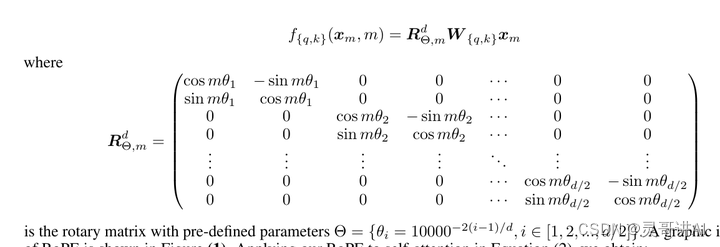
除了rope_theta参数不一样, 效果是一样的。
Transformer forward
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full((seqlen, seqlen), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=1)
# When performing key-value caching, we compute the attention scores
# only for the new sequence. Thus, the matrix of scores is of size
# (seqlen, cache_len + seqlen), and the only masked entries are (i, j) for
# j > cache_len + i, since row i corresponds to token cache_len + i.
mask = torch.hstack(
[torch.zeros((seqlen, start_pos), device=tokens.device), mask]
).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h).float()
return output
h = self.tok_embeddings(tokens)
把表示token在vocab表中位置信息转化从4096维的向量
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
self.freqs_cis在计算的时候传入的2倍的params.max_seq_len, 所以start_pos + seqlen长度不会超.
mask是因果掩模(causal mask), 使得输入的token只能看到之前的token和自己. 这是在transformer解码器里才会用到, 编码器没有这个mask, 编码器任务就像是做完型填空, 知道空格前面和后面的内容, 然后写出答案. 而解码器只能根据前面的内容预测下一个token.
Transformer Bolck
然后经过一连串的TransformerBlock, 在经过RMSNorm, 最后在转成大小为vocab_size的logits
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim,
hidden_dim=4 * args.dim,
multiple_of=args.multiple_of,
ffn_dim_multiplier=args.ffn_dim_multiplier,
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
h = x + self.attention(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward(self.ffn_norm(h))
return out
h = x + self.attention(self.attention_norm(x), start_pos, freqs_cis, mask)
输入首先经过self.attention_norm, 也就是RMSNorm, 然后经过自注意力机制计算, 再加上残差输入
然后又经过一次RMSNorm, 然后经过全连接层, 再加上上一级残差输入, 最总得到结果返回
欲知详情, 请见下回分解😊😊😊















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









