




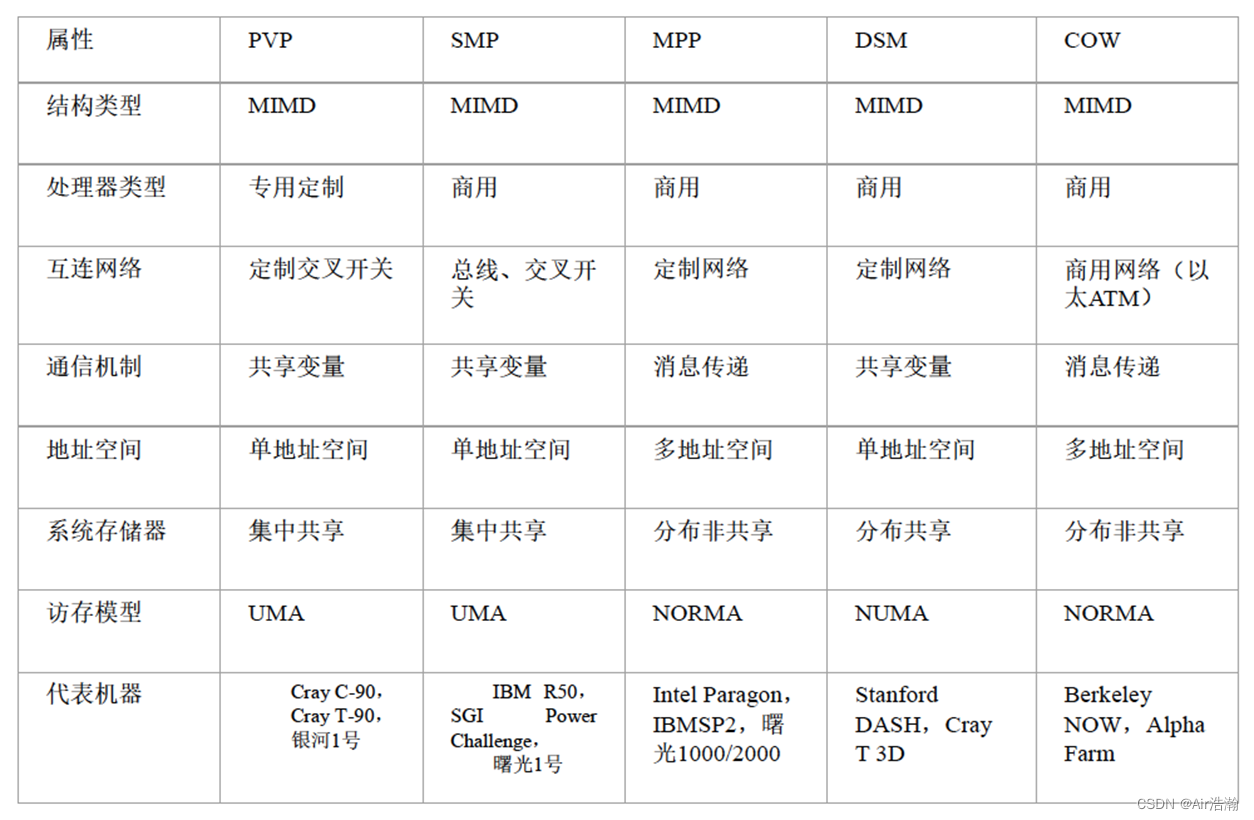
 文章详细介绍了并行计算机的不同结构模型,包括SIMD、PVP、SMP、MPP和DSM,以及各种并行计算机的访存模型如UMA、NUMA和COMA。同时,讨论了冯诺依曼体系结构中的‘存储器墙’问题,并分析了高速缓存一致性在并行计算中的重要性。
文章详细介绍了并行计算机的不同结构模型,包括SIMD、PVP、SMP、MPP和DSM,以及各种并行计算机的访存模型如UMA、NUMA和COMA。同时,讨论了冯诺依曼体系结构中的‘存储器墙’问题,并分析了高速缓存一致性在并行计算中的重要性。
文章目录
并行分布式计算 并行计算机体系结构
冯诺依曼体系存在的问题:运算器和存储器分离,导致运算器速度提升比存储器快得多,即“存储器墙”问题。
并行计算机结构模型
SIMD 单指令多数据流
CUDA 就是 SIMD 的形式,图形学中很多计算都是相同的计算形式、不同的数据流。
游戏图形计算中往往只需要单精度 SIMD,因为只需要算到屏幕中的某个像素的坐标(整数)。
PVP 并行向量处理机
定制高性能向量处理机,经由高带宽的交叉开关网络,连接共享存储器。
问题:交叉开关的成本高,适用于定制化的场景。
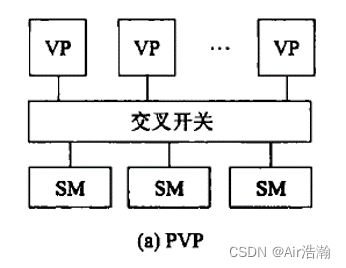
- VP:向量处理机,vector processor
- SM:共享存储器,shared memory
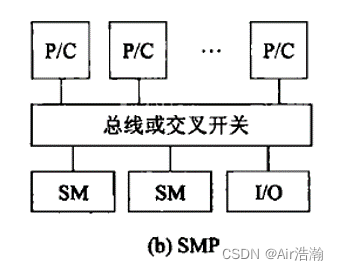
SMP 对称多处理机
商用处理器,经由高速总线(或交叉开关网络),连接共享存储器。
系统是对称的,每个处理器可以等同地访问共享存储器、IO 设备。(不同于 USMP 非对称处理机,只有部分处理器能够执行操作系统并能操作 I/O)
问题:共享存储器导致 P/C 之间的通信成本较高。
MPP 大规模并行处理机
处理节点为商用处理器,物理上的分布式存储器,专门设计和定制的高通信带宽低延迟网络。
扩展性好,能扩展到成千上万个处理器。
特点:异步 MIMD,多个进程,突破了共享内存的模式,每个处理器具有私有地址空间,所以进程间采用消息传递机制协同。
问题:改变了编程方式,一台机器上编程只能看到自己的地址空间,访问其他核和 LM 需要时钟同步。
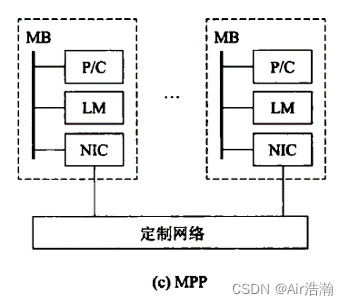
-
LM:本地存储器,Local Memory
-
NIC:网卡,Network Interface Card
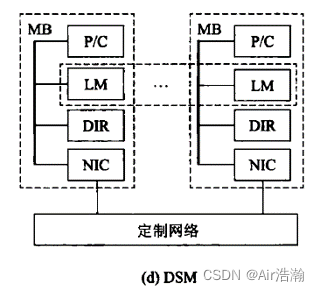
DSM 分布式共享存储多处理机
使用高速缓存目录(DIR)支持分布高速缓存一致性。
采用分布式共享存储器(逻辑上共享,由 DIR 实现),系统硬件和软件提供单一地址的编程空间。
特点:DIR 是一种硬件协议,使用 DIR 可以解决 MPP 中地址空间分隔的问题。
问题:DIR 是一种标准的协议,无法对具体的算法提供特殊优化点。
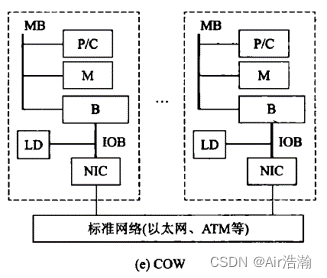
COW 工作站集群
每个节点是完整“无头工作站”(没有显示器、鼠标、键盘等),通过低成本商品网络互连。
每个节点有本地磁盘(MPP没有本地磁盘,只有本地内存),网络层耦合到 I/O 总线(MPP则是将网络层耦合到存储总线),每个节点驻留完整操作系统(MPP 的每个节点是微核)
特点:可以看作是低成本 MPP;
问题:标准以太网较慢,需要想办法降低网络负载,增加了开发难度;
总结
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 616
616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











