







关于并行,你知道多少?思考多少?
听到“并行”这个词汇,我最先想到的是在多车道上飞驰的汽车,它们是并行运行的。它们之间完全独立吗?并不见得,当一个车道上的车要变道时要打开方向灯,相邻车道的车都会减速避让。可见,并行是发生在大部分时间,有时候有串行的成分在里面。从更宏观的层面来看,一般的问题都有“并行”和“串行”两种特性同时存在。其实,再说的直白点,任何一件事情都有独立性的部分,也有相关性的部分。哦,对了。我得解释一下“并行”的英文:parallelism。很相关的一个概念是“并发”,其英文:concurrency。顺便解释一下这两个概念,并行侧重于同时处理多个任务的能力,并发则侧重于并发的关键是你有处理多个任务的能力,不一定要同时。并发是一种设计理念,让一件事情完成的效率最高,并发设计的好的话,并行占比高,整个事情完成的效率就高。详细的见参考资料3Concurrency is not parallelism。
说实话,这个话题太大,网上资料也很丰富。我写这篇文章的目的是激发大家关于“并行”的思考,然后做一个概况性质的介绍,让大家对“并行”有一个正确的感性认识。
并行这个概念太大,我们下面把范围缩小,重点讨论并行计算的话题。
冯诺依曼计算机体系结构
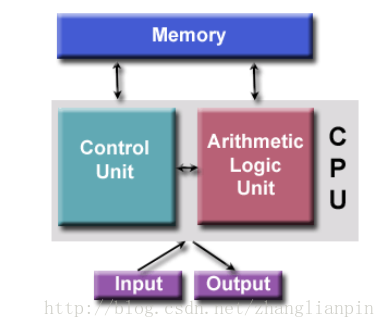
什么是并行计算?
我们都知道计算实际上是一系列确定的步骤。聊并行计算哪能少了串行计算,直接上图:

并行计算也得看图说话:
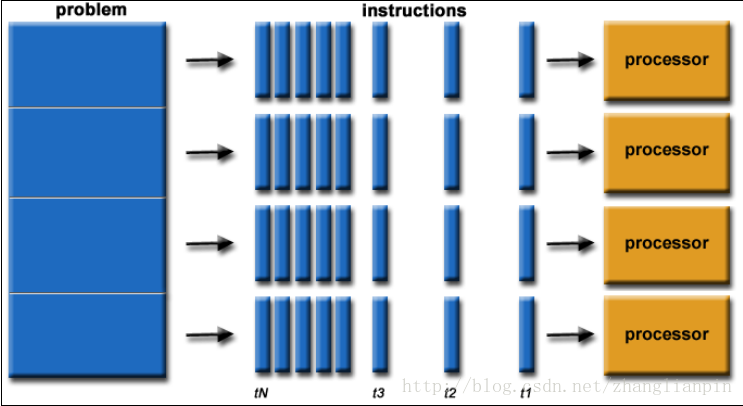
这里我们假定了要解决的问题完全可分为4个独立运行的部分,由4个processors来独立运行。实际问题中,独立性和关联性是一个“太极”关系,就涉及到划分的粒度和通讯的频率等等问题。
为什么用并行计算?
现实世界中存在大量并行
. 自然社会中,每时每刻都在发生大量的有相互关联的事件。
. 相比于串行计算模型,并行计算模型更有利于我们为现实世界建模。
. 下面有好多并行的例子。
更直接的原因
使用并行技术可以节约大量的时间&金钱
tag:大规模的运算集群可以由比较廉价的计算机组成用于完成大规模的计算任务,比如阿里巴巴的双十一。利用的通用的便宜的X86服务器组成超大规模nodes运算集群。- 可以用来解决超大规模的问题
Grand Challenge Problems。 - 提供高并发性
想想阿里,百度,腾讯可以同时为多少人提供服务吧。 可以充分利用网络上的计算资源(非本地计算资源)
SETI@home
Folding@home
了解下这两个开源项目,你就明白啥意思了。让你更了解你所使用的并行计算机硬件架构,充分发挥它的性能
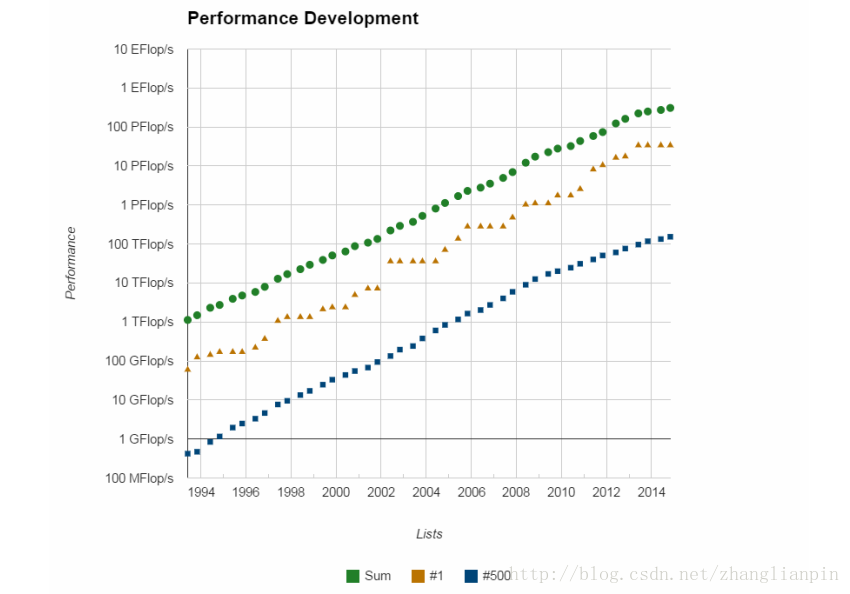
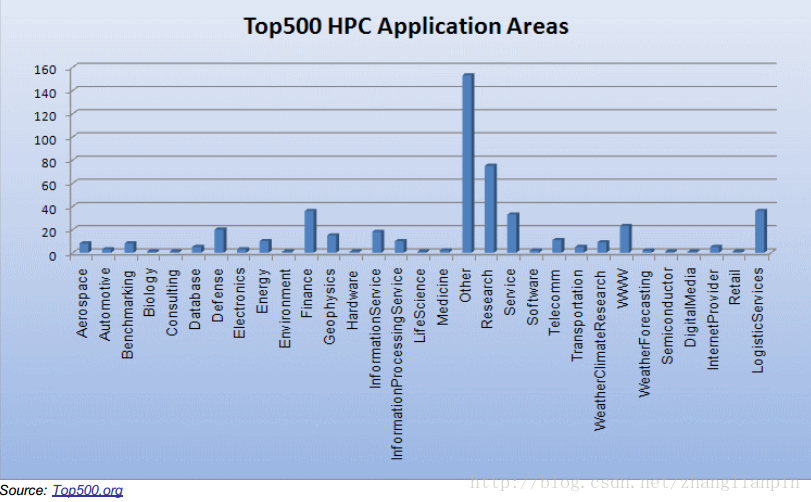
目前,随着网络数据量越来越大,大数据下所需要的计算力会更大
全球对计算力的需求一直在成上升趋势,且大规模计算机集群提供的运算力也在逐年提升。
数据来源:top500.org有了上面这些原因,相信你也对高并发程序设计感兴趣了吧。


谁在用并行计算?
- 科学、工程领域
- 工业、商业
- 全球各种各样的APP

硬件提供了哪些支持?
其实,硬件从下面这些方面都提供了并行支持。
1. 片内级
. 片内级并行
. 片内多线程
. 单片多处理器
2. CPU级
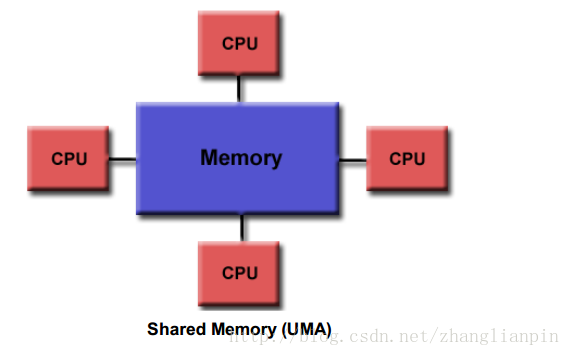
. UMA对称多处理器系统
. NUMA多处理器系统
. COMA多处理器系统
3. 计算机级
. MPP—大规模并行处理器
. 集群计算
上个图,一目了然。

硬件上来说,我们现在使用的手机和笔记本实际上都是单CPU多核心的,比如我的笔记本是4核8线程的,就是说我的电脑有一个CPU,这个CPU有4个core,每个core上还提供了intel的超线程技术。那从操作系统这一级来看我拥有8个独立的cpu可以同时使用。
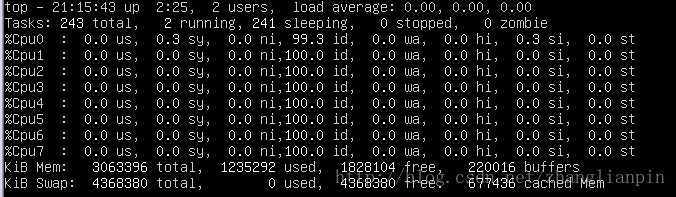
这种架构就是标准的SMP系统,所有的核平等共享Cache,interrupt,和硬件资源。
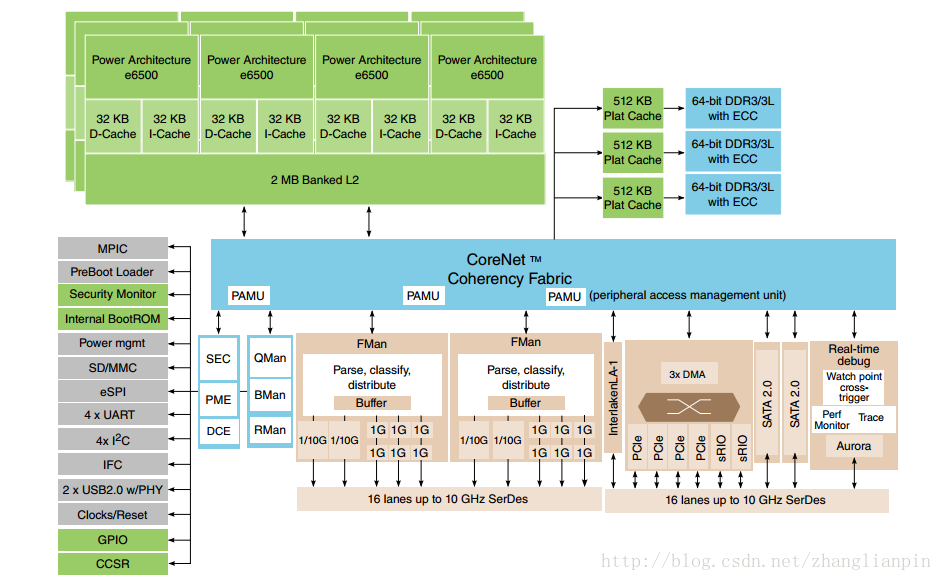
这个是PowerPC结构的CPU结构图。
看懂套路了吗?提高性能的方式也就两个:1,增强当个core的频率(每秒执行指令的次数)2,增加core的数量。
单个CPU增加核心也是有瓶颈限制的,因为SMP中共享总线需要很高的bindwidth,还需要解决总线竞争问题。
那咋继续提升性能呢?哦,你可能也想到了,解耦,然后增加CPU的个数,CPU之间也建立bus。intel有一种技术叫QPI,就是互联CPU用的。那CPU之间共享内存,读取自己CPU的内存不用通过QPI总线,肯定比读取挂在另一个CPU上的内存要快,所以叫NUMA。
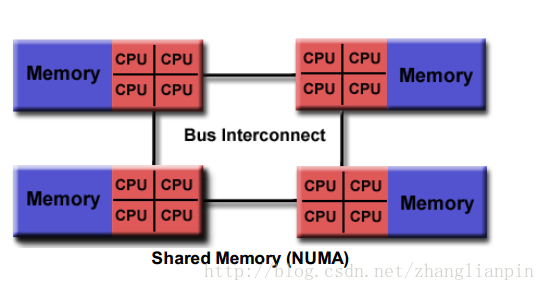
NUMA往细了分还可以分为CC-NUMA、NC-NUMA等。
那这种耦合度的扩展限制在CPU互联bus上,可扩展性差一些,那要接着增强计算能力,咋办?老办法,解耦,把多个机器利用bus互联。这就产生了MPP(Massively Parallel Processors)、COW(Cluster of
Workstations)。
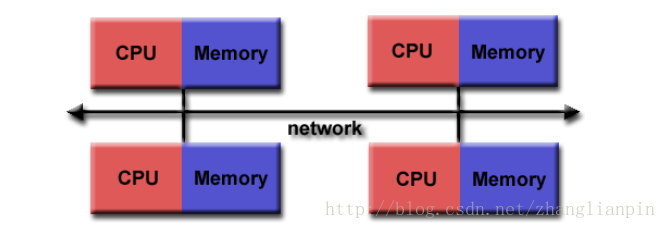
但是,目前超大规模的集群运算,一般单个节点都是SMP的,或者是NUMA的,然后用高性能BUS将不同的机器再互联起来。
我们目前市面上见到的4路服务器、16路服务器,一般是NUMA架构的服务器,见到的8单元服务器,一般是指COW架构的服务器。
软件提供了哪些支持?
通过上面关于硬件并行的介绍,我们也了解到要想合理的发挥这些机器的性能,还是需要了解这些机器的硬件架构,主要是要理解耦合性和内聚性,以及在软件设计时充分考虑如何利用这些硬件特性,才能设计出高效、经济的软件系统。
等会,什么时候软件设计人员开始需要了解硬件细节了?其实,大部分硬件细节都通过OS,系统库给封装了,对软件开发人员透明。这个其实也是个很有争议的话题:能否在不了解底层细节的情况下,开发出好的软件?
我的想法是,计算机体系结构是分层的,我们必须站在中间这一层看问题,比如你是做OS的,你往上要看应用,往下要看硬件。要想把一个工具发挥到极值,还是需要了解你所使用的工具的,所谓人剑合一就是这个意思。
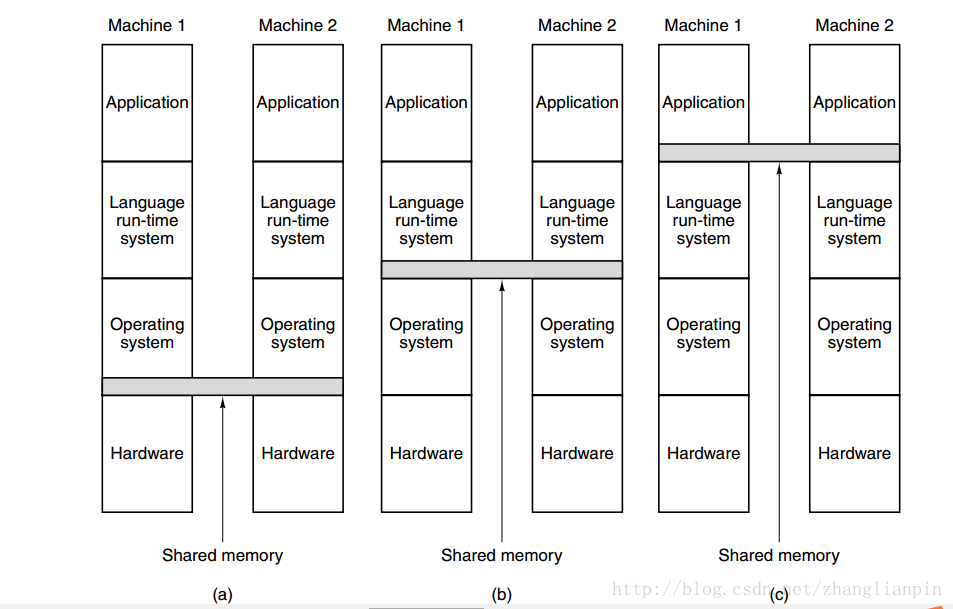
扯远了,在我们常见的SMP系统上,单个机器是符合冯诺依曼计算机体系结构的,各个core的抽象是在OS这一层做的。os+开发库,可以让软件开发人员透明地使用并行开发方法,比如我们常用的并发库—POSIX Threads。当然还有其他的一些线程库。这个我们很熟悉,但是到了NUMA架构的机器上,是谁做的抽象呐?答案还是OS,因为到目前为止的体系架构仍然还是硬件级共享内存的。你想linux kernel就可以识别NUMA架构的计算机,安装多个CPU,比如说安装2个16核的CPU,OS起来后,你可以看到你可以直接利用的cpu是32个。也就是说基于这种架构硬件的软件开发和在普通的PC机上无太大区别。
但是到了COW或者MPP时,由于是多个独立的主机通过高速bus互联的架构,是一种非共享内存的模型,每个主机运行独立的OS,读取另外主机的内存只能通过Message方式,需要定义read、write原语。实现这种的有一个开源库叫OpenMPI。当然其他的也有很多,只是原来在SMP、NUMA上的程序要想移植到非硬件共享的平台上来,一般有两个方法:1,修改原有的软件,让其适应在非硬件共享内存的平台上运行。2,针对非硬件共享内存的平台做软件抽象,使应用程序看起来像是在共享内存环境下运行—就是使用虚拟机技术。使用虚拟机技术可以在不同层次中做共享内存抽象。
总结
说了这么多,感觉说明白了。其实说白了,并行计算机架构就是在解决一个事情:如何利用多个core来实现更高的运算能力。这和这一个问题是等价的:利用什么组织架构来管理很多人,让这些人发挥更大的改造自然的能力。
在摩尔定律失效的当下,在不同层次研究并行计算的架构就显得很重要了,我个人感觉在传统IC的基础上有以下两个方向可以继续保持摩尔定律:1,研究更专用,更高效的并行架构,包括微指令层、指令层、IC层、CPU层、整机层。2,研究如何编写更高效的软件。目前,因为原来摩尔定律带来的诟病,有太多的不合格程序员在写着不合格的程序,其中就包括我在内。
参考资料
链接打不开的话,请注意开车方式。
Introduction to Parallel Computing
Structured Computer Organization(Andrew S.Tanenbaum)
Concurrency is not parallelism














 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









