






前言:亲爱的小伙伴们,你们通过百度搜索找到本文章的还是从B站评论来的呢?如果你是从B站评论来的,那么恭喜你,这个评论也是一个python的selenium小项目自动发送的。这个小项目的源代码也在下面的本地pdf笔记里面哦,欢迎大家下载学习(代码仅供学习参考使用)。
本笔记从零基础开始(不含python)从urllib到selenium再到xpath,bs4,requests,scrapy框架。根据B站的多个教学视频综合学习归纳总结(具体是哪些视频可以单独询问),并且对于视频教程中过时内容进行了自主学习,笔记成型于2024年5月9日,后续也进行了一些补充。所有案例均可实现(网络视频教学中很多已经不适用现在的框架了)。可以免去同学们学习过程中解决错误所浪费的大量时间精力。希望能对各位同学有所帮助。
从0到实战,内含多个实战案例,最终结合selenium,scrapy框架,xpath等实现淘宝网的爬取。
可本地下载,适合小白学习。如果链接失效请联系,由于这里的笔记是直接复制本地文件,所以图片内容无法展示,且爬取某宝以及自动发送评论的代码因为各种原因无法上传,pdf中的则是完整内容,内含xpath插件以及爬取淘宝案例教学。需要的小伙伴可以下载百度网盘中的pdf版本(更新md版方便修改补充)。下载地址:网盘链接

线上版:
网络爬虫技术
urllib
基础操作
urllib是python内置对于url操作的库
import urllib.request
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
res = response.read().decode('utf-8')
print(res)
一个类型六个方法
import urllib.request url = "http://www.baidu.com" # 模拟浏览器向服务器发送请求 response = urllib.request.urlopen(url) # HTTPResponse类型 # print(type(response)) # 一个字节一个字节读 # content = response.read() # print(content) # 返回多少个字节 # content = response.read(10) # print(content) # 读取一行 # content = response.readline() # print(content) # 读取一行知道读完 # content = response.readlines() # print(content) # 返回状态码 print(response.getcode()) # 返回url地址 print(response.geturl()) # 返回响应头 print(response.getheaders())
下载内容
import urllib.request # 下载网页 url_page = 'http://www.baidu.com' # 两个参数,url地址和name # urllib.request.urlretrieve(url_page, 'baidu.html') # 下载图片 # urllib.request.urlretrieve(url='https://img0.baidu.com/it/u=4171982618,1877587227&fm=253&fmt=auto&app=120&f=JPEG?w=750&h=500',filename='lisa.jpg') # 下载视频 url = 'https://f.video.weibocdn.com/o0/1cwUEIpulx08e6gn721W01041200vkh70E010.mp4?label=mp4_720p&template=1280x720.25.0&media_id=5023422250418218&tp=8x8A3El:YTkl0eM8&us=0&ori=1&bf=4&ot=h&ps=3lckmu&uid=3ZoTIp&ab=,8013-g0,3601-g39&Expires=1713321712&ssig=B6AD8OUGE0&KID=unistore,video' urllib.request.urlretrieve(url, filename='zjj.mp4')
请求对象的定制
https协议具有UA(user-agent)反爬
import urllib.request
url = 'https://www.baidu.com'
# url的组成
# http/https
# 协议
# http 80 https 443
# redis 6379
# mongodb 27017
# oracle 1521
# https://www.baidu.com/s?wd = 周杰伦
# http/https www.baidu.com 80/443 s wd = 周杰伦 #
# 协议 主机 端口 路径 参数 锚点
# 返爬user-agent不完整
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
# 定制request
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode('utf8'))
编解码
百度的时候我们输入中文进行检索,但是我们将浏览器地址复制下来发现中文变成一串代码
https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6 https://www.baidu.com/s?wd=周杰伦 如果我们使用中文在urllib爬取会出现报错 UnicodeEncodeError: 'ascii' codec can't encode characters in position 10-13: ordinal not in range(128)
urllib.parse.quote方法
该方法用于将中文转换成unicode编码
使用urllib.parse中的方法quote('汉字')对中文进行转换成unicode编码格式
import urllib.parse
parse_chinese = urllib.parse.quote("张三")
print(parse_chinese) # 输出结果:%E5%BC%A0%E4%B8%89
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6'
# 模拟浏览器发送请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 对中文进行转换unicode
name = urllib.parse.quote('周杰伦')
url = url + name
# 请求对象的定制
# Request定制
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
urllib.parse.urlencode方法
该方法用于多个中文参数转换成unicode
import urllib.parse
data = {
'wd': '周杰伦',
'sex': '男'
}
encodes = urllib.parse.urlencode(data)
print(encodes)
wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7
# urlencode应用场景:多参数转换unicode
# import urllib.parse
# data = {
# 'wd': '周杰伦',
# 'sex': '男',
# 'local': '台湾'
# }
#
# encodes = urllib.parse.urlencode(data)
# print(encodes)
# 获取https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7&local=%E5%8F%B0%E6%B9%BE网页源代码
import urllib.request
import urllib.parse
base_url = 'https://www.baidu.com/s?'
data = {
'wd': '周杰伦',
'sex': '男',
'local': '台湾'
}
new_data = urllib.parse.urlencode(data)
# 请求资源路径
url = base_url + new_data
print(url)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
爬虫发送post请求
post请求必须进行编码,编码之后还得调用encode('utf-8')
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
data = {
'kw': 'spider'
}
# post请求的参数,必须进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
print(data)
# post请求的参数,是不会拼接在url的后面的,而是需要放在请求对象定制的参数中
request = urllib.request.Request(url=url, data=data, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应数据
content = response.read().decode('utf-8')
import json
obj = json.loads(content)
print(obj)
# post 请求方式的参数必须编码 data = urllib.parse.urlencode(data).encode('utf-8')
# 编码之后必须调用encode方法
# 参数是放在请求对象定制的方法中,request = urllib.request.Request(url=url, data=data, headers=headers)
post请求百度之详细翻译
解决cookie反爬
urllib爬取ajax—get请求更新发送过来的数据
下载豆瓣电影的数据
# get 请求
# 获取豆瓣电影的第一页的数据并且保存起来
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers = {
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 定制request
request = urllib.request.Request(url=url, headers=headers)
# 获取响应数据
response = urllib.request.urlopen(request)
context = response.read().decode('utf-8')
# 将数据下载到本地,默认使用的是gbk的编码,需要在open中指定编码格式为utf8
# fp = open('豆瓣.json', 'w', encoding='utf-8')
# fp.write(context)
# 另一种形式
with open("豆瓣.json", 'w', encoding="utf-8") as fp:
fp.write(context)
爬取豆瓣前10页的电影信息
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
url1 = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20'
url2 = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=40&limit=20'
url3 = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=60&limit=20'
# page 1 2 3 4
# start 0 20 40 60
# start(page-1)*20
# 下载豆瓣电影前10页的电影
# 1、请求对象定制
# 2、获取响应的数据
# 3、下载数据
import urllib.parse
import urllib.request
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data = {
'start': (page - 1) * 20,
'limit': 20
}
data = urllib.parse.urlencode(data)
url = base_url + data
print(url)
headers = {
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page, content):
with open("douban" + str(page) + ".json", 'w', encoding="utf-8") as fd:
fd.write(content)
# 程序入口
if __name__ == '__main__':
start_page = int(input("请输入起始的页码"))
end_page = int(input("请输入结束的页码"))
for page in range(start_page, end_page + 1):
request = create_request(page)
# 获取响应数据
content = get_content(request)
# 下载
down_load(page, content)
处理ajax-post请求发送的数据
爬取肯德基地址前10页的数据,肯德基的网页是通过点击下标post请求上传给服务器,返回的数据。
# cname: 北京
# pid:
# pageIndex: 1
# pageSize: 10
#
# cname: 北京
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request
import urllib.parse
def get_request(page):
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '北京',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
request = urllib.request.Request(url=url, data=data, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content, page):
with open("肯德基\kfc" + str(page) + ".json", 'w', encoding='utf-8') as fd:
fd.write(content)
if __name__ == '__main__':
start_page = int(input("请输入起始页码"))
end_page = int(input("请输入结束页码"))
for page in range(start_page, end_page + 1):
request = get_request(page)
content = get_content(request)
down_load(content, page)
URLError\HTTPError
import urllib.request
import urllib.error
# url = 'https://blog.csdn.net/Xixi0864/article/details/1378732571'
url = "https://www.goudan111.com"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
try:
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
except urllib.request.HTTPError: # 当出现HTTPError错误时
print("系统正在升级...")
except urllib.request.URLError: # 当出现URLError错误时
print("系统正在升级懂吗?")
urllib中的cookie登录
一些数据必须是登录之后才能看到的数据。如果我们使用python爬取链接的时候需要加上headers中的cookie,这是一种简单的防止爬取的方式。
import urllib.request
url = 'https://www.wsy.com/search.htm?accurate=&site_id=1&search_type=item&q=%E7%9A%AE%E8%A1%A3'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'cookie': 'cna=78L8HXFghBkCASoxyFNlAWst; xlly_s=1; thw=cn; lgc=tb02155003; dnk=tb02155003; ...'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
with open("网商园.html", 'w', encoding='utf-8') as fd:
fd.write(content)
Handler处理器
我们之前学习,如果有user-agent校验的情况就需要请求头定制。
为什么学习handler:
Handler可以定制更高级的请求头(随着业务逻辑的复杂,请求对象的定制已经满足不了我们的需求(动态cookie和代理不能使用请求对象的定制)
动态cookie:每次登录cookie都不一样。
# 使用handler访问百度,获取网页源代码
import urllib.request
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
# handler build_opener open
# 获取handler对象
handler = urllib.request.HTTPHandler()
# 获取opener对象
opener = urllib.request.build_opener(handler)
# 调用open方法
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)
代理服务器
# 使用handler访问百度,获取网页源代码
import urllib.request
url = 'https://www.ip138.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
# response = urllib.request.urlopen(request)
# handler builder_opener open
proxies = { # 代理IP地址
'http': '59.54.238.36:18010'
}
# 创建handler
handler = urllib.request.ProxyHandler(proxies=proxies)# 传入参数是IP的字典
opener = urllib.request.build_opener(handler) # 创建opener
response = opener.open(request)
content = response.read().decode('utf-8')
with open("daili.html", 'w', encoding='utf-8') as fd:
fd.write(content)
IP代理池
import urllib.request
# 一个简易的代理池里面有很多ip
proxies = [
{'http': '59.54.238.36:18010'},
{'http': '59.54.238.36:23565'},
]
import random
proxies = random.choice(proxies)
url = 'https://www.baidu.com/s?wd=IP'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
handler = urllib.request.HTTPHandler() # 获取handler
opener = urllib.request.build_opener(handler) # 获取opener
response = opener.open(request)
content = response.read().decode('utf-8')
with open("dialichi.html", 'w', encoding='utf-8') as fd:
fd.write(content)
html解析
xpath解析
xpath:
注意:提前安装xpath插件
pip install lxml -i http://pypi.douban.cam/simple
导入lxml.etree
from lxml imoprt etree
etree.parse() 解析本地文件
html_tree=etree.parse('xx.html')
etree.HTML()服务器响应文件
html_tree= etree.HTML(response.read().decode('utf-8'))
html_tree.xpath(xpath路径)
xpath插件安装
给chrome浏览器安装xpath插件。
-
从网盘下载xpath的插件文件
-
在chrome中输入chrome://extensions/打开扩展程序。
-
将文件.zip文件直接拖到浏览器中
-
得到chrome插件,将插件开关开启,并且打开开发者模式。
-
重启浏览器,按住shift+ctrl+x检查是否安装成功
安装lxml库
pip install lxml -i https://pypi.douban.com/simple
xpath语法
from lxml import etree
# xpath解析
# (1)本地文件 etree.parse()
# (2)服务器响应的数据 response.read().decode('utf-8') etree.HTML()
# xpath解析本地文件
tree = etree.parse('4爬虫_xpath解析.html')
# xpath基本语法
# tree.xpath('xpath路径')
# 查找ul下面的li
# 1. 路径查询
# // :表示查询所有子节点,不考虑层级
# / : 表示查询直接子节点
li_list = tree.xpath("//body//ul/li")
li_list1 = tree.xpath("//body//li")
print(li_list1)
print(len(li_list))
# 2.过滤查找
# 查找ul下所有的带有id的li标签
# 语法: tree.xpath('//ul/li[@id]')
# text():获取标签中的内容
li_list = tree.xpath('//ul/li[@id]/text()')
print(li_list)
# 找到所有id为l1的li标签
li_list = tree.xpath('//ul/li[@id="l1"]/text()')
print(li_list)
# 查找id为l1的li标签的class属性的属性值
li_list = tree.xpath('//ul/li[@id="l1"]/@class')
print(li_list)
# 3.模糊查询
# 查询id里面包含l的li标签,l不一定在开头
li_list = tree.xpath('//ul/li[contains(@id,"l")]')
print(li_list)
li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
print(li_list)
# 查询id的值以c开头的li标签
li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
print(li_list)
# 查询id为l1和class为c1的数据
li_list = tree.xpath('//ul/li[@id="l1" and @class ="c1"]/text()')
print(li_list)
# 4、逻辑运算
li_list=tree.xpath("//ul/li[@id ='l1']/text() | //ul/li[@id='l2']/text()")
print(li_list)
1. 选取属于 bookstore 子元素的第一个 book 元素。 //bookstore/boot[1]
2. 选取属于bookstore下最后一个book元素。 //bookstore/boot[last()]
3. 选取id='1'的title //title[@id='1']
4. 选取id='1'的title的lang属性的值 //title[@id='1']/@lang
5. 选取price大于30的book //book[price>30] 33
6. 选取price大于30的book下little的属性lang的值 //book[price>30]/title/@lang eng2
7. 选取price为44的值 //book[.//price>40]//price 44
获取前x个子元素
获取div下的前10个div
div/div[position() <= 10]
用xpath随机选择相同元素
<ul class="nList">
<li class="">0</li>
<li class="">1</li>
<li class="">2</li>
<li class="">3</li>
<li class="">4</li>
<li class="">5</li>
</ul>
定位:
a=random.randint(0,6)
self.driver.find_element_by_xpath("//div[@class='lotteryView']/div[1]/div/ul[1]/li[position()='%d']"%a)------后面可以跟.text或者.clink()
例子没有写全,按例子定位只要"//ul[@class='nList']/li[position()='%d']"%a-------------------这个a是自己定义的
8
xpth限制类名的同时限制选取的数量
案例:选择类名为reply-btn的span元素并且只选择前10个
(//span[@class='reply-btn'])[position()<=10]
xpath选择某元素的父节点
xpath可以选择父节点,某个元素的父节点用**“/. .”**表示
选择id为china的节点的父节点:
//*[@id='china']/..
兄弟节点选择:
xpath选择后续兄弟节点,用following-sibling::
比如,要选择class为single_choice的元素的所有后续兄弟节点:
//*[@class='single_choice']/following-sibling::*
xpath还可以选择前面的兄弟节点,
语法: prceding-sibling::
比如,要选择 class 为 single_choice 的元素的所有前面的兄弟节点
//*[@class='single_choice']/preceding-sibling::*
选择某元素内部的元素
# 先寻找id是china的元素
china = wd.find_element(By.ID, 'china')
# 再选择该元素内部的p元素 ./表示当前节点,.//表示内部所有子节点
elements = china.find_elements(By.XPATH, './/p')
# 打印结果
for element in elements:
print('----------------')
print(element.get_attribute('outerHTML'))
根据内容选择
li_list=tree.xpath("//li[contains(text(),'北京')")
xpath和lxml以及urllib的综合使用-爬取下载图片
from lxml import etree
import urllib.request
# 1 获取网页源码
# 2 解析 解析服务器文件 tree.HTML()
# 3 打印
import urllib.request
url = "http://www.baidu.com/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器访问
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# 解析网页源码,获取想要的数据.解析服务器文件
tree = etree.HTML(content)
# 获取想要的数据
result = tree.xpath('//input[@id="su"]/@value')[0]
print(result)
下载站长素材中的图片
# 请求对象的定制
import urllib.request
from lxml import etree
url = 'https://sc.chinaz.com/tupian/meinvtupian_2.html'
url = 'https://sc.chinaz.com/tupian/meinvtupian_3.html'
def getRequest(page):
url = None
if page == 1:
url = 'https://sc.chinaz.com/tupian/meinvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/meinvtupian_' + str(page) + '.html'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
return request
# 获取网页源码
def getHTMLResource(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
# 下载
def down_load(content):
tree = etree.HTML(content)
name_list = tree.xpath("//div[@class ='container']//div/img/@alt")
src_list = tree.xpath("//div[@class ='container']//div/img/@data-original")
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
print(name, url)
urllib.request.urlretrieve(url, filename='./美女图片/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input("请输入起始页"))
end_page = int(input("请输入结束页"))
for page in range(start_page, end_page + 1):
request = getRequest(page)
content = getHTMLResource(request)
img = down_load(content)
# print(img)
Jsonpath解析
用于解析json数据,jsonpath只能解析本地文件。xpath适用于解析HTML,Jsonpath解析适用于json的解析
教程:JSONPath-简单入门_jsonpath简单入门-CSDN博客
jsonpath安装:
pip install jsonpath
jsonpath的使用:
obj= json.load(open('json文件','r',encoding='utf-8'))
ret = jsonpaht(obj,'jsonpath语文')
案例:解析json
{
"store": {
"book": [
{
"category": "修真",
"author": "六道",
"title": "坏蛋是怎么炼成的",
"price": 9.89
},
{
"category": "修真",
"author": "天蚕土豆",
"title": "斗破苍穹",
"price": 19.89
},
{
"category": "修真",
"author": "唐家三少",
"title": "斗罗大陆",
"isbn": "0-553-21311-3",
"price": 2.89
},
{
"category": "修真",
"author": "南派三叔",
"title": "星辰变",
"isbn": "0-553-19395-3",
"price": 5.89
}
],
"bicycle": {
"author": "那笔",
"color": "黑色",
"price": 19.2
}
}
}
jsonpath语法
import jsonpath
import json
# 解析json
# 书店中所有的数
obj = json.load(open('7爬虫_解析_jsonpath.json', 'r', encoding='utf-8'))
type_list = jsonpath.jsonpath(obj, '$.store.book[*].author')
# print(type_list)
# 所有作者
all_author = jsonpath.jsonpath(obj, '$..author')
# print(all_author)
# store下面的所有元素
tag_list = jsonpath.jsonpath(obj, '$.store.*')
# print(tag_list)
# store下面的所有的price
price_list = jsonpath.jsonpath(obj, '$.store..price')
# print(price_list)
# 第三本数
book = jsonpath.jsonpath(obj, '$..book[2]')
# print(book)
# 最后一本书
book = jsonpath.jsonpath(obj, '$..book[(@.length-1)]')
# print(book)
# 前两本书
# book = jsonpath.jsonpath(obj, '$..book[0,1]')
book = jsonpath.jsonpath(obj, '$..book[:2]')
# print(book)
# 条件过滤要在()前面加?
# 过滤出所有包含版本号的书
book_list = jsonpath.jsonpath(obj, '$..book[?(@.isbn)]')
# print(book_list)
# 哪本书超过10块钱
book = jsonpath.jsonpath(obj, '$..book[?(@.price>10)]')
# print(book)
jsonpath解析淘票票网站
import urllib.request
url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1714228636101_108&jsoncallback=jsonp109&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
# 'accept-encoding': ' gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'bx-v': ' 2.5.11',
'cookie': 'thw=cn; sgcookie=E100osBnkPrEtW0P6zOPyvUiaU084F5dctl3C36uHPNsaso%2F8J%2FvWdzxpSmjcbKDQijE%2BSpnofz%2BkxSw5FMpfDZ4C8aw0trVG%2Bxj8Dv%2B6CGeAK4%3D; havana_lgc_exp=1713142392623; wk_cookie2=1f2f67081a95c218ba17032d7abe4e0b; wk_unb=VyySV2N2PSBr4A%3D%3D; env_bak=FM%2BgyPYhUxUOKlrAEisf0v9cPvpEIoahBGVvaGCsLVHk; t=57fbd0772a83ecde5c26da42faf866d1; mt=ci=0_0; tracknick=; cna=78L8HXFghBkCASoxyFNlAWst; 3PcFlag=1714044772178; tfstk=f1HSCYZ-2ab5Enob-7K4hu_kYvwC949ZyMZKjDBPv8eJA2gtPWPL8Q0QO2u09Yyr4qMI7qtnaWyJA2gtPWPKTvrKdq28tbzUzywIxVt27dJZq023eF-2QAugYqe3JpyLrToySJLw7KleKwh8pXoLEyFjDrqQJkBKJiFYok6d92U8MZE_jJUKJJKbHlqR2aCRempYb3FhfkO7r0TF165Iqg-pnrBdpYp3NPifT9BKeuNSD0UjV0MbV7aTgRa1oY3qvYkuiitYKmlsRX39u_z-1kiZO0pRH8ko2fFKBefKq8zSJWGD5Or7UjNsFbxhk03aPfeoYGTrcWhqE5DykTwts0yP4FBa5B2dtUyOdoawcn1hT1GaqmYFbvDuwoq7gntfyXV8moawcn1ht7E0Vl-Xcahh.; cookie2=126be53a7b6c407e1735df9ca72d6b41; v=0; _tb_token_=e84535396eabe; xlly_s=1; isg=BBoatde4KDhNo6SRsaC8ReCIa8A8S54l3aYUkCSTpK14l7rRDNltNaXpZ2MLcxa9',
'referer': 'https://dianying.taobao.com/',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
content = content.split('(')[1].split(')')[0]
with open("8爬虫_jsonpath_解析淘票票.json", 'w', encoding="utf-8") as fd:
fd.write(content)
import json
import jsonpath
obj = json.load(open("8爬虫_jsonpath_解析淘票票.json", 'r', encoding="utf-8"))
city_list = jsonpath.jsonpath(obj, '$..regionName')
print(city_list)
BeautifulSoup



爬虫案例
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>网页标题</title>
</head>
<body>
<h1>标题1</h1>
<h2>标题2</h2>
<h3>标题3</h3>
<h4>标题4</h4>
<a href="http://www.python.com">python</a>
<div id="content" class="default">
<p>段落</p>
<a href="http://www.baidu.com">百度</a>
<a href="http://www.crazyant.com">疯狂蚂蚁</a>
<a href="http://www.iqiyi.com">爱奇艺</a>
<img src="https://zhekou-background.manmanbuy.com/image/zhekou/20231108/1d720dddedcf4614ac5992c259e8559b.jpg?x-oss-process=image%2Fformat%2Cjpg%2Fresize%2Cw_500%2Fquality%2Cq_80" alt="">
</div>
</body>
</html>
BeautifulSoup使用
from bs4 import BeautifulSoup
with open("./test.html", encoding='utf-8') as fin:
html_doc = fin.read()
soup = BeautifulSoup(html_doc, "html.parser")
links = soup.find_all("a")
for link in links:
print(link.name, link["href"], link.get_text())
img = soup.find("img")
print(img['src'])
print("*" * 10)
div_node = soup.find('div', id="content")
links_1 = div_node.find_all('a')
for link in links_1:
print(link)
1、BeautifulSoup简称:
bs4
2、BeautifulSoup和lxml一样,是一个html的解析器,主要功能也是解析和提取数据
3、优缺点:
缺点:效率没有lxml高
优点:接口人性化设计,使用方便
安装:
pip install bs4
导入:
from bs4 import BeautifulSoup
创建对象:
服务器响应的文件生成对象
soup=BeautifulSoup(response.read().decode(),"lxml")
本地文件生成对象
soup = BeautifulSoup(open('1.html'),'lxml')
注意:默认打开我呢间的编码格式gbk所需要指定打开编码格式
BeautifulSoup的基本语法
测试的html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<ul>
<li id="l1">张三</li>
<li id="l2">李四</li>
<li>王五</li>
<li>赵六</li>
<a href="" id="" class="a1">尚硅谷</a>
<span>hahaha</span>
</ul>
</div>
<a href="" title="a2">百度</a>
</body>
</html>
语法:
from bs4 import BeautifulSoup
# 通过解析本地文件
# 默认打开的文件的编码格式gbk,需要指定编码
soup = BeautifulSoup(open("9爬虫_解析_BeautifulSoup.html", encoding='utf-8'), "lxml")
# 根据标签名查找节点
# 找到的是第一个符合条件的标签
# print(soup.a)
# 获取标签的属性和属性值
# print(soup.a.attrs)
# bs4的一些函数
# find: 返回第一个符合条件的数据
# print(soup.find("a"))
# 根据title的值找到对应的标签对象
# print(soup.find("a",title ="a2"))
# 根据class的值找对应的标签对象,class需要下划线
# print(soup.find('a',class_ = 'a1'))
# find_all:返回一个列表,并且返回所有的a的标签
print(soup.find_all("a"))
# 如果想获取多个标签数,在find_all中添加的是列表的数据
print(soup.find_all(['a', 'span']))
# limit的作用是查找前几个数据
print(soup.find_all("li", limit=2))
# select(推荐)
# select方法返回一个列表 并且会返回多个数据
# print(soup.select('a'))
# 可以通过. 代表class,这种操作叫做类选择器
print(soup.select('.a1'))
# 通过#代表id,选择器选择id为l1的标签
print(soup.select("#l1"))
# 属性选择器,通过属性来寻找对应的标签
# 查找li标签中有id的标签
print(soup.select("li[id]"))
# 查找li标签中id为l2的标签
print(soup.select('li[id= "l2"]'))
print("=============后代选择器==============")
# 层级选择器
# 后代选择器
# 找到div下面的li 空格 表示后代 div li
print(soup.select("div li"))
print("============子代选择器==============")
# 子代选择器
# 某标签的第一级子标签
# 注意:很多计算机编程语言中如果不加空格不会输出内容,但是bs4中不会报错,会显示内容div > ul > li
print(soup.select("div>ul>li"))
print("==========找到a标签和li标签的所有的对象===========")
# 找到a标签和li标签的所有的对象
print(soup.select("a,li"))
节点信息
获取节点的信息,比如内容,属性等
html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<ul>
<li id="l1">张三</li>
<li id="l2">李四</li>
<li>王五</li>
<li>赵六</li>
<a href="" id="" class="a1">尚硅谷</a>
<span>hahaha</span>
</ul>
</div>
<a href="" title="a2">百度</a>
<div id="d1">
<span>
哈哈哈
</span>
</div>
<span id="s1">李四</span>
<p id="p1" class="p2">呵呵呵</p>
</body>
</html>
案例
# 节点信息
# 获取节点内容
obj = soup.select("#d1")[0] # <div id="d1"><span>哈哈哈</span></div>
obj1 = soup.select("#s1")[0] # <span id="s1">李四</span> 这个标签中只有内容,没有子标签,可以使用string属性
# 如果标签对象中,只有内容,那么string和get_text()都可以使用
# 如果标签对象中,除了内容还有标签,那么string获取不到数据,而get_text()可以
# 推荐get_text()
print(obj.get_text())
print(obj1.string)
# 节点的属性
obj = soup.select("#p1")[0]
# name是标签的名字
print(obj.name)
# 将属性值作为一个字典返回
print(obj.attrs)
# 获取节点的属性
obj = soup.select("#p1")[0]
# print(obj.attrs.get('class'))
# print(obj.get('class'))
print(obj['class'])
案例-bs4爬取网商园
import urllib.request
from bs4 import BeautifulSoup
url = 'https://www.wsy.com/search.htm?accurate=&site_id=1&search_type=item&q=T%E6%81%A4'
# 这个cookie是自己从浏览器中复制下来的。
headers = {
'cookie': 'CATEGORYPID-SITE_ID:1=30; HOMEPTYPE-SITE_ID:1=30; UM_distinctid=18f0fd2c56ce0-02bba1091bf484-3e604809-1fa400-18f0fd2c56ded; _ati=4722370614660; first_visited=1; cart_num=0; oauthtype=100; city_temp=%E6%9D%AD%E5%B7%9E; _wsy_=b25c0232b7e1b2760b76507380a3b303; usertype=1; tracknick=手机号; _BASEUSID=MTI5OTI5NzE1MzI4MDM0NTk3; search_history_goods=; LAST_SEARCH=%5B%22%E7%9A%AE%E8%A1%A3%22%2C%22T%E6%81%A4%22%2C%22%E7%89%9B%E4%BB%94%E8%A3%A4%22%5D; CNZZDATA1257041518=1091661087-1713957422-https%253A%252F%252Fwww.baidu.com%252F%7C1714266823; SERVERID=d2b88d7de3d56f8387c7530b41d19380|1714266823|1714266653',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
soup = BeautifulSoup(content, 'lxml')
# //div[@class='item-c']//div[@class='tit']/a/text()
name_list = soup.select('div[class = "item-c"] div[class = "tit"]>a')
# print(name_list)
for name in name_list:
print(name.get_text().strip())
Selenium
Selenium是什么?
Selenium是一个用于web应用程序的测试工具
直接运行在浏览器中,像真用户在操作一样
支持通过各种driver驱动真实浏览器完成测试
selenium也支持无界面浏览器操作
为什么使用Selenium? 模拟浏览器功能,自动执行网页中的js代码,实现动态加载1
如何安装Selenium
操作谷歌浏览器驱动下载地址
淘宝镜像:https://registry.npmmirror.com/binary.html?path=chromedriver/
官方镜像:https://sites.google.com/a/chromium.org/chromedriver/downloads
https://getwebdriver.com/
https://getwebdriver.com/chromedriver#stable
http://chromedriver.storage.googleapis.com/index.html
谷歌驱动和浏览器版本之间的映射
https://blog.csdn.net/qq_34562959/article/details/88572333
查看谷歌版本:右上角--帮助--关于
pip install selenium
Firefox浏览器驱动下载地址:
Edge浏览器驱动下载地址:
这是windows下的浏览器
异常处理
https://www.selenium.dev/documentation/webdriver/troubleshooting/errors/driver_location/
selenium基本使用
WebDriver | Selenium selenium官网
【Python爬虫 • selenium】selenium4新版本使用指南_selenium4教程-CSDN博客 学习
https://cloud.tencent.com/developer/article/2308489 使用
selenium4之后不需要手动指定驱动的路径到python文件中,但是需要将chrome添加到环境变量中。
selenium的演示
import time # 导入selenium包 from selenium import webdriver # 加载指定页面并关闭 # 打开浏览器 browser = webdriver.Chrome() # 指定加载页面 url = "https://www.jd.com/" browser.get(url) # 设置定时5秒 time.sleep(5) #关闭浏览器 browser.quit()
元素定位
-
•
find_element()系列:用于定位单个的页面元素。 -
•
find_elements()系列:用于定位一组页面元素,获取到的是一组列表。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 打开指定浏览器
browser = webdriver.Chrome()
# 打开指定页面
# browser.get("https://www.baidu.com/")
# 获取title
# print(browser.title)
# 通过id属性获取输入框
# input_text = browser.find_element(By.ID, 'kw')
# 向搜索框中输入内容
# input_text.send_keys("selenium")
# 通过name属性选择文件文本输入框元素,并设置内容
# browser.find_element(By.NAME, 'wd').send_keys("selenium")
# 通过id属性获取“百度一下”按钮,并执行点击操作
# browser.find_element(By.ID, 'su').click()
# 通过class属性定位
# 通过class获取百度的输入框并写入内容
# browser.find_element(By.CLASS_NAME, 's_ipt').send_keys("张三")
# 通过tag定位
# tag是标签名,定位到的标签不一定是唯一的
# browser.get("https://blog.csdn.net/")
# a = browser.find_element(By.TAG_NAME, "button").click()
# 通过link定位
# link表示包含有属性href的标签元素,如:linktext可以通过LINK_TEXT进行定位。
# browser.get("https://www.baidu.com/")
# LINK_TEXT表示的是链接文本,通过链接文本定位
# <a href="http://news.baidu.com">新闻</a>
# browser.find_element(By.LINK_TEXT, "新闻").click()
# By.PARTIAL_LINK_TEXT模糊定位,通过超链接中的文本模糊查询
browser.get("https://www.baidu.com/")
# 完整链接为<a href="http://news.baidu.com">新闻</a>
browser.find_element(By.PARTIAL_LINK_TEXT, "新").click()
# 停留5秒后进入下一步
time.sleep(6)
# 关闭浏览器
browser.quit()
通过xpath定位
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动浏览器并打开指定页面
browser = webdriver.Chrome()
browser.get("https://www.baidu.com/")
# 通过xpath定位输入框,输入内容
browser.find_element(By.XPATH, '//input[@id="kw"]').send_keys("张三")
# 通过xpath获取百度一下按钮,click
browser.find_element(By.XPATH, '//input[@id="su"]').click()
# 定时
time.sleep(5)
# 关闭
browser.quit()
通过css定位
• find_element(By.CSS_SELECTOR,'XX')根据元素的css选择器来完成定位,可以准确定位任何元素,但需要熟练掌握css选择器 • css选择器 1. 类选择器--------.XXX选择class属性为xxx的元素 2. id选择器-------- #XXX选择id属性为xxx的元素 3. 元素选择器-----XXX选择标签名为xxx的元素 4. 属性选择器-----[yyy='bbb']选择yyy属性取值为bbb的元素 5. 派生选择器-----AA>XX或AA XX选择AA标签下的XX元素 • 你可以通过获取xpath的方式来从页面获取css选择器在css里标识层级关系使用的是>或者空格(xpath里使用的是/) div#xx1>input.yy2
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动浏览器并打开指定页面
browser = webdriver.Chrome()
browser.get("https://www.baidu.com/")
"""
1. 类选择器--------.XXX选择class属性为xxx的元素
2. id选择器-------- #XXX选择id属性为xxx的元素
3. 元素选择器-----XXX选择标签名为xxx的元素
4. 属性选择器-----[yyy='bbb']选择yyy属性取值为bbb的元素
5. 派生选择器-----AA>XX或AA XX选择AA标签下的XX元素
"""
# 使用css的方式来选择,#表示id,.表示类
browser.find_element(By.CSS_SELECTOR, "#kw").send_keys("张三")
time.sleep(3)
browser.find_element(By.CSS_SELECTOR, "#kw").clear()
# browser.find_element(By.CSS_SELECTOR, '#su').click()
# 类选择器选择
a = browser.find_element(By.CSS_SELECTOR, '.c-icon')
print(a)
# 定时
time.sleep(5)
# 关闭
browser.quit()
文本的输入清除和提交
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动浏览器并打开指定页面
browser = webdriver.Chrome()
browser.get("https://www.baidu.com/")
# input_text = browser.find_element(By.ID, "kw")
# 输入文本
# input_text.send_keys("张三")
# time.sleep(2)
# 清除文本
# input_text.clear()
"""
submit()提交
• 注意:submit()只能用于包含属性type='submit'的标签,并且嵌套在form表单中。
• 也可以使用click()代替submit()使用。
• 注意:submit()和click()是有很大区别的,这里不再做具体说明。
"""
browser.find_element(By.XPATH, '//input[@id = "kw"]').send_keys("张三")
submit_tag = browser.find_element(By.XPATH, '//input[@id = "su"]')
submit_tag.submit()# 提交
# 定时
time.sleep(5)
# 关闭
browser.quit()
获取页面内容
获取页面内容 • title页面标题 • page_source 页面源码 • current_url页面连接 • text标签内文本
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动浏览器并打开指定页面
browser = webdriver.Chrome()
browser.get("https://www.baidu.com/")
# 获取网页标题
print(browser.title)
# 获取网页源代码
# print(browser.page_source)
# 获取网页链接
print(browser.current_url)
# 获取标签内文本
a = browser.find_element(By.XPATH,'//div[@id="s-top-left"]/a[1]')
print(a.text)
# 定时
time.sleep(5)
# 关闭
browser.quit()
选择Select
对于一些样式为下拉框,实际代码却不是使用select元素写的,不能使用这种方式,可以模拟人的方式获取。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://sahitest.com/demo/selectTest.htm")
# 定义select
select = Select(driver.find_element(By.ID, 's1Id'))
# 根据下标选择,从0开始,直接选择(非获取内容)
s1 = select.select_by_index(1)
time.sleep(2)
# 根据value值选择
s2 = select.select_by_value('o2')
time.sleep(2)
# 根据肉眼见到的内容选择,select中value属性的值可以和标签内的值不同
s3 = select.select_by_visible_text('o3')
time.sleep(2)
driver.close()
级联选择
找到一层一层的元素,不断进行点击即可。
弹框选择
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://sahitest.com/demo/alertTest.htm")
driver.find_element(By.NAME, 'b1').click()
# 输入内容(不显示)
driver.switch_to.alert.send_keys("张三")
# 使用alter.text获取按钮文字
time.sleep(2)
print(driver.switch_to.alert.text)
# 点击确定
driver.switch_to.alert.accept()
# 点击取消
driver.switch_to.alert.dismiss()
time.sleep(3)
文件上传
获取文件绝对路径
def get_log_path():
return os.path.join(os.path.dirname(os.path.dirname(os.path.realpath(__file__))), 'file', 'EEID.jpg')
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from utils.get_fileLogo import get_log_path
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://sahitest.com/demo/php/fileUpload.htm")
path = get_log_path()
# 获取文件上传元素
upload = driver.find_element(By.ID, 'file')
# 获取input文件上传元素
upload.send_keys(r"{}".format(path))
driver.find_element(By.NAME, 'submit').click()
time.sleep(3)
特殊元素iframe
iframe是网页中嵌套的一个页面,如果想获取到这个嵌套页面,需要使用
driver.switch_to.frame(0),里面的参数可以是id,name,index,也可以是iframe元素
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://sahitest.com/demo/iframesTest.htm")
# 进入到iframe并进行操作
driver.switch_to.frame(0)
time.sleep(3)
driver.find_element(By.CSS_SELECTOR,"td>a[class='a x']").click()
time.sleep(3)
# 方式2,frame()的参数也可以是frame元素
fd = driver.find_element(By.CSS_SELECTOR,'body > iframe')
driver.switch_to.frame(fd)
time.sleep(3)
driver.find_element(By.CSS_SELECTOR,"td>a[class='a x']").click()
time.sleep(3)
退出iframe,回到外部
driver.switch_to.parent_frame()
# 切换到主界面
driver.switch_to.default_content()
打开本地html文件
driver.get('file://地址')
前面要加file
隐式等待
.implicitly_wait(N)通过一定时长等待页面元素加载,最大等待时长N秒,如果中间某个时刻元素加载好了,就会结束等待,执行下一步操作;如果超出设置时间元素没加载出来,抛出没有这样的元素异常。
针对的是整个浏览器,只要改浏览器中某个元素还没有出现,就会触发隐式等待。并不是针对某一个元素的设置。
比如因为网络问题,按钮1没有出现,设置等待时间为10秒,如果10内这个按钮仍然没有出现则报错,如果在第6秒的时候出现了则代码继续执行。
-
隐式等待只对
find_element()和find_elements()方法有效; -
在使用显式等待时,隐式等待会被覆盖掉。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动浏览器并打开指定页面
browser = webdriver.Chrome()
browser.get("https://www.baidu.com/")
# 隐示等待
browser.implicitly_wait(5)
# 关闭
browser.quit()
time.sleep(3)
缺点
隐式等待只对 find_element() 和 find_elements() 方法有效,其他方法不受影响,因此可能会导致一些操作失败。 如果设置的隐式等待时间过长,会增加测试执行的总时间,从而降低测试效率。 在高并发环境下,多个线程使用同一个驱动器对象时,隐式等待可能会相互干扰,从而导致测试失败。 find_element与click()连起来使用会使find_element的implicitly_wait失效,即driver会一直寻找元素,不会等待设定的时间后抛出no_such_element异常。
隐式等待的使用场景:
虽然隐式等待也有一些缺点,但它仍然是Selenium中比较常用的等待方式之一。以下是一些可能需要使用隐式等待的场景: 在测试过程中,页面元素的加载时间比较稳定,且需要等待的时间比较长时,可以使用隐式等待来避免重复编写等待代码; 当需要查找的元素在不同的测试用例中都需要使用时,可以将隐式等待放到 setUp() 方法中,这样所有的测试用例都可以共享隐式等待的设置; 在进行基本的功能验证时,可以使用隐式等待来保证元素可见性,以确保测试结果的正确性。
显式等待
-
显示等待:设置一个等待时间和一个条件,在规定时间内,每隔一段时间查看下条件是否成立,如果成立那么程序就继续执行,否则就提示一个超时异常(TimeoutException)。
-
通常情况下WebDriverWait类会结合ExpectedCondition类一起使用。
是针对某个元素的等待。在设置时间内,默认每隔一段时间检测一次当前页面某个元素是否存在,如果在规定的时间内找到了元素,则执行下一步,如果超过设置时间检测不到则抛出异常。默认检测频率为0.5s,默认抛出异常为:NoSuchElementException。
# wait_obj = WebDriverWait(driver, 10)
# wait_obj.until(expected_conditions.presence_of_element_located((By.CLASS_NAME, 'site-nav-user')))
需要引入包:
from selenium.webdriver.support.wait
import WebDriverWait
WebDriverWait(driver, timeout=3).until(some_condition) WebDriverWait(driver, timeout=3).until(some_condition) 是一个使用Selenium中的显式等待实现的代码片段。它的作用是等待某个特定条件在指定时间内满足,一旦满足了条件,则继续执行后续代码。 这个语句的具体含义是: WebDriverWait(driver, timeout=3) 创建一个WebDriverWait对象,将传递给它的driver参数作为被等待的WebDriver实例,并设置最长等待时间为3秒钟。 .until(some_condition) 调用until()方法并传递一个特定的条件some_condition。该方法将等待直到条件满足或超时时间达到。
# 导入selenium模块中的webdriver模块,用于实例化浏览器对象并控制浏览器的操作
from selenium import webdriver
# 导入selenium模块中的WebDriverWait类,用于等待特定条件出现后再执行下一步操作
from selenium.webdriver.support.ui import WebDriverWait
# 导入selenium模块中的expected_conditions模块的EC别名,用于定义预期条件
from selenium.webdriver.support import expected_conditions as EC
# 创建WebDriver实例
driver = webdriver.Chrome()
# 导航到网页
driver.get("https://www.csdn.net")
# 等待页面标题包含"CSDN"
wait = WebDriverWait(driver, 5)
title_contains_csdn = EC.title_contains("CSDN")
wait.until(title_contains_csdn)
# 输出页面标题
print(driver.title)
# 关闭浏览器
driver.quit()
在上面的示例中,我们使用显式等待等待文本框中的值被清除。 until_not()方法等待文本框的文本值为空,并继续执行后续代码。 如果超时,则抛出TimeoutException异常。
显示等待用处以及缺点
显式等待的缺点与使用场景 显式等待是一种在测试自动化中常用的等待方式,它可以让脚本在执行过程中等待某个特定条件变为真时再继续执行。显式等待适用于需要等待某些特定条件才能继续执行测试的情况,例如等待页面元素加载完成、等待异步操作完成等。 显式等待的主要缺点: 容易出现异常:如果设置的超时时间太短或者条件不正确,就有可能导致脚本抛出异常而终止执行。 可读性较差:显式等待往往需要编写复杂的代码来处理,这样容易导致代码可读性较差。 对测试环境有依赖性:显式等待往往需要依赖网络状态、服务器响应速度等因素,这些因素可能会影响测试结果。 使用场景: 等待页面元素加载完成:当页面需要加载一些异步资源(如图片、视频等)时,我们可能需要使用显式等待等待页面元素加载完成后再进行下一步操作。 等待异步操作完成:在执行一些需要耗费时间的异步操作时,例如上传文件、发送请求等,我们可能需要使用显式等待等待操作完成后再进行下一步操作。 等待某些特定条件:有些测试场景需要等待某些特定条件才能继续执行测试,例如等待某个元素出现、等待某个值被更新等。这时我们可以使用显式等待来实现等待条件变为真后再继续执行测试。
expected_conditions模块
expected_conditions是Selenium的一个模块,主要用于对页面元素的加载进行判断,包括元素是否存在,可点击等等。 Expected Conditions的使用场景一般有两种: 直接在断言中使用 与WebDriverWait配合使用,显示等待页面上元素出现或者消失。 一般情况下,我们在使用expected_conditions模块时都会对其进行重命名,通过as关键字对其重命名为EC。 from selenium.webdriver.support import expected_conditions as EC
expected_conditions模块常用方法
1、判断网页title是否是特定文本(英文区分大小写),若完全相同则返回True,否则返回False。 title_is( String title) 2、判断网页title是否包含特定文本(英文区分大小写),若包含则返回True,不包含返回False。 title_contains( String title) 3、判断当前页面的url是否等于预期值 url_to_be( String url) 4、判断页面是否跳转成功,成功返回true,否则返回false url_changes(url) 5、判断当前页面的url是否包含预期字符串 url_contains( String fraction) 6、等待url中出现指定字符串或正则表达式(可以使用“或”语法,例如想检测url中是否有“ncc”或者“map”,就可以传“ncc|map”) url_matches( String regex) 7、判断一个元素存在于页面DOM树中,存在则返回元素本身,不存在则报错。 presence_of_element_located( By locator) 8、判断定位的元素范围内,至少有一个元素存在于页面当中,存在则以list形式返回元素本身,不存在则报错。 presence_of_all_elements_located( By locator) 9、判断特定元素是否存在于DOM树中并且可见,可见意为元素的高和宽都大于0,元素存在返回元素本身,否则返回False。 visibility_of_element_located( By locator) 10、同上面visibility_of_element_located(locator),不过参数从locator的元组变为元素,如果存在就返回该元素。 visibility_of(element) 11、判断某组元素是否可见 visibility_of_all_elements_located( By locator) 12、判断是否有一个元素在页面可见,如果定位到就返回列表。 visibility_of_any_elements_located(By locator) 13、判断给定文本是否出现在特定元素中,若存在则返回True,不存在返回False。 text_to_be_present_in_element(By locator, String text) 14、判断某文本是否是存在于特定元素的value值中,存在则返回True,不存在则返回False,对于查看没有value值的元素,也会返回False。 text_to_be_present_in_element_value(final By locator, final String text) 15、判断某个frame是否可以切换过去,若可以则切换到该frame,否则返回False 。 frame_to_be_available_and_switch_to_it(final By locator) 16、判断某个元素中是否不存在于dom树或不可见,如果可见返回false,不可见返回这个元素。 invisibility_of_element_located(final By locator) 17、同上面的invisibility_of_element_located一样,只不过传值是传element invisibility_of_element(final By element) 18、如果给定元素是可见的且具有非零大小,否则为null element_if_visible(WebElement element) 19、判断某元素是否可访问并且可启用,比如能够点击,若可以则返回元素本身,否则返回False。 element_to_be_clickable(final By locator) 20、判断某个元素是否被选中了,一般用在下拉列表 element_to_be_selected(WebElement element) 21、判断某个元素是否被选中了,一般用在下拉列表,locator为一个(by, path)元组。 element_located_to_be_selected(By locator) 22、判断某元素的选中状态是否与预期相同,相同则返回True,不同则返回False。 element_selection_state_to_be( WebElement element, boolean selected) 23、跟上面的element_selection_state_to_be一样,只不过传入类型为locator。 element_located_selection_state_to_be(final By locator, final boolean selected) 24、判断页面上是否存在alert,若存在则切换到alert,若不存在则返回False。 alert_is_present() 25、判断一个元素是否仍在DOM中或等待从dom中移除,传入WebElement对象,可以判断页面是否刷新了,不存在的话返回True,依旧存在返回False staleness_of(final WebElement element) 总结:这些方法与WebDriverWait类和 until()、until_not()方法组合能使用,够实现很多判断功能,如果能自己灵活封装,将会大大提高脚本的稳定性。
强制等待
强制等待是一种不建议使用的等待方式。它使用 time.sleep() 方法在代码中强制让程序等待固定的时间,而不管网页是否已经加载完成或元素是否已经出现。
强制等待的使用场景 虽然不建议频繁使用强制等待,但在一些特定情况下仍然需要考虑使用它。以下是一些可能需要使用强制等待的场景: 页面加载时间较长且不稳定:当页面或元素的加载时间比较长且不稳定时,可以使用固定时间的强制等待来确保元素加载完毕。但请注意,这种方式不是最佳实践,应尽量优化页面加载速度和稳定性。 其他等待方式无法满足需求:当其他等待方式无法满足需求时,可以考虑使用强制等待来等待某些操作的完成。但请确保在没有更好的替代方案时再采用这种方式。 调试代码:在调试代码时,可以使用强制等待来暂停程序执行,以便观察程序执行状态和结果。这对于定位问题和调试脚本非常有用。 虽然强制等待在特定的场景下可能是必要的,但请尽量避免过度使用它,并在可能的情况下选择更灵活和准确的等待方式,例如显式等待或条件等待。 虽然强制等待有其局限性,但它在特定场景下仍然是一种有效的等待方式。为了更好地管理强制等待,我们可以考虑以下几点: 设置合理的等待时间:要根据实际情况来设置合理的等待时间,避免过长或过短的等待时间。 结合其他等待方式:如果可能,应该尝试使用其他等待方式,如显式等待、隐式等待或条件等待,以提高测试效率和可靠性。 尽量避免使用:在大多数情况下,我们应该尽量避免使用强制等待,而选择更加智能和可靠的等待方式。
获取元素信息
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动浏览器并打开指定页面
browser = webdriver.Chrome()
browser.get("https://www.baidu.com/")
input_value = browser.find_element(By.ID, 'kw')
# 获取元素的属性值
attr1 = input_value.get_attribute("class")
attr2 = input_value.get_attribute("name")
print(attr1)
print(attr2)
# 获取元素的标签名
print(input_value.tag_name)
# 获取元素文本
a = browser.find_element(By.LINK_TEXT, "新闻")
print(a.text)
time.sleep(3)
# 关闭
browser.quit()
交互
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动浏览器并打开指定页面
browser = webdriver.Chrome()
browser.get("https://www.baidu.com/")
# 在百度文本框中输入内容
input_tag = browser.find_element(By.ID, "kw")
input_tag.send_keys("周杰伦")
time.sleep(2)
# 获取百度一下的按钮
button = browser.find_element(By.XPATH, '//input[@id="su"]')
time.sleep(2)
# 点击按钮
button.click()
time.sleep(2)
# 滑到底部
js_button = "document.documentElement.scrollTop=100000"
browser.execute_script(js_button)
# 获取下一页的按钮
next_button = browser.find_element(By.CLASS_NAME, "n")
# 下一页
next_button.click()
time.sleep(3)
# 浏览器截图生成图片
browser.get_screenshot_as_file("tset.png")
# 刷新页面
browser.refresh()
time.sleep(3)
# 回退到上一页
browser.back()
time.sleep(2)
# 前进一页
browser.forward()
time.sleep(3)
# 设置浏览器窗口大小
"""
maximize_window()窗口最大化。
• minimize_window()窗口最小化。
• set_window_size(width,height)调整窗口到指定尺寸。
"""
# browser.maximize_window()
# browser.minimize_window()
browser.set_window_size(100,200)
# 关闭
browser.quit()
window handles句柄切换
我们打开浏览器的新页面有两种情况: 一种是直接在当前标签页切换内容 一种是开启一个新的标签页 而selenium中每一个窗口就是一个句柄,selenium不会自动帮我们切换句柄,需要我们手动切换 获取当前浏览器的所有窗口句柄 handles=driver.window_handles # 返回值是一个列表 切换到最开始打开的窗口 driver.switch_to.window(handles[0]) 解释:如果UI自动化操作的浏览器打开了多个窗口,那么获取到的列表的最后一个元素即为最新的浏览器窗口句柄。 切换到最新打开的窗口 driver.switch_to.window(handles[-1]) 切换到倒数第二个打开的窗口 driver.switch_to.window(handles[-2]) 获取 WebDriver 对象 当前聚焦的浏览器窗口句柄 driver.current_window_handle()
# **先看下当前窗口url地址:**
print(self.browser.current_url)
# 打印所有的窗口 ['窗口ID1', '窗口ID2', '窗口ID3'] ==> 窗口句柄
windows = self.browser.window_handles
print(windows)
# 1 切换到最后的窗口
driver.switch_to.window(drivers[-1])
# 切换到最后的窗口后,打印下url,核对下是不是最后的窗口
print(driver.current_url)
2 切换到第二个窗口
# 先获取现在的窗口
current_window = self.browser.current_window_handle
# 获取第二个窗口的索引(由当前窗口索引+1)
next_window_index = windows.index(current_window) + 1
# 切换到第二个窗口
self.browser.switch_to.window(windows[next_window_index])
参考笔记:UI自动化测试之selenium工具(浏览器窗口的切换)_selenium网页登录会自动跳出新的窗口并登录-CSDN博客
selenium问题:
Selenium常见问题解析_selenium 启动慢-CSDN博客
1、回到上一个页面
wd = webDriver.chrome("webDriver路径")
# 记录一下当前handle(为了跳转回该页面做铺垫)
currentHandle = wd.current_window_handle
wd.implicitly_wait(5)
wd.get("http://******")
link = wd.get_elment_by_tag("XX")
link.click()
# 跳转到新的想要跳转的页面
for handle in wd.window_handles:
# 切换到新的页面
wd.switch_to.window(handle)
# 可以在新的页面中找到一些特有属性,作为判断依据
if "XXX" in handle.title:
break
# 这时因为已经跳转到想要跳转的页面了,所以此时的标题就是新页面的标题了
print(wd.title)
# 如何跳转回老页面
①使用类似上面跳转新页面的方法
②使用上面记录的老页面的句柄,然后调用:
wd.switch_to.window(currentHanle)
2、关闭当前页的上一页
关闭当前页 driver.close() 这里的driver必须是句柄所在driver 关闭上一页 # 获取所有句柄 handles = driver.window_handles driver.switch_to.window(handles[-2]) driver.close()
3、python selenium 浏览器自动化遇到 Message: element click intercepted:解决办法(非延迟加载)
使用js来点击
button = driver.find_element_by_xpath('//*[@id="root"]/div/div/div[1]/div/div/div[3]/div/div/div[2]/div[3]/div/div/div[2]/input')
driver.execute_script("arguments[0].click()",button)
上述办法仅适用于,JS动态加载 不可交互式元素的 input 点击事件。其他的提示无法找到元素标签的,可以在代码前,添加:time.sleep(你的秒数),前提是要导入time 函数。 或者是 : driver.refresh() #刷新网页/加载网页
Phantomjs
什么是Phantomjs?
是一个无界面浏览器
支持页面元素查询,js的执行等
由于不进行css和gui渲染,运行效率要比真实浏览器更快
已经黄了
Chrome handless
是Chrome浏览器针对浏览器59版本新增的一种模式,可以在不打开UI界面的情况下使用Chrome浏览器,运行效果和Chrome保持一致
必须chrome>60 python3.6以上 Selenium=3.4 chrmeDriver=2.31
配置
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# chromehandles的前置配置
# 创建操作项目
chrome_options = Options()
# 设置Chrome为Headless模式
chrome_options.add_argument('--headless')
# 禁用GPU加速
# 有些程序不支持GPU加速或者操作系统不兼容,会导致浏览器无法正常启动。此时,我们可以通过添加--disable-gpu参数来避免这些问题。
chrome_options.add_argument('--disable-gpu')
# 指定浏览器地址(放弃)
# path = r'C:\Program Files\Google\Chrome\Application\chrome.exe'
# 设置浏览器地址(放弃)
# chrome_options.binary_location = path
# 创建Chrome WebDriver对象,传入ChromeOptions对象
browser = webdriver.Chrome(options=chrome_options) # chrome_options已经被options替代
url = "http://www.baidu.com"
browser.get(url)
# 输出源码,如果控制台有输出则表示成功
print(browser.page_source)
封装handles
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 封装handles
def get_handles():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(options=chrome_options)
return browser
if __name__ == '__main__':
browser = get_handles()
browser.get("http://www.baidu.com")
print(browser.page_source)
selenium优化
动态加载
也就是所谓的显式加载,当需要的元素出来之后再执行。
存在动态加载场景
现在基本上都是动态网页,存在比较多页面交互元素,既然大家看到这篇文章想必都是有所需求的,默认大家对selenium使用操作比较熟悉,不熟悉的可以去看看本人之前的文章查漏补缺。等待网页元素加载是需要一定时间的,如果直接接下一步操作可能存在网页元素未完全加载的情况导致报错查找不到对应元素ElementNotInteractableException,这时候可以用到WebDriverWait这个函数:
from selenium.webdriver.support.ui import WebDriverWait
1
比如我们现在需要等待一个弹窗事件,需要等待几秒的弹出时间,但是时间又是不可控的,可能2s可能5s,那么我们想直到这个元素出现我们才做动作,就可以这么用:
# msg-item是嵌入在iframe里面
iframe = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.NAME, "private"))
)
1
2
3
4
上述代码的含义等待该元素10s,如果出现自动进行下一步操作,如果上述元素没有出现时会报错TimeoutException,一般连着try except做进一步处理。
无头浏览器
采用无头浏览器可以加快浏览器操作,不过对于一些需要输入验证码的操作无法解决,可以采用添加cookie的方式免登陆。
设置页面加载策略
一般来说我们要关注的元素并没有那么多,只需要获取到目标元素,只加载局部数据信息就好,不需要把整个页面都加载完整,这时候就以通过设置页面加载策略来优化。页面加载策略主要有以下几种: normal(默认):等待整个页面加载完成,包括所有的静态资源(如图片、CSS文件)和异步的 JavaScript 脚本。 eager:等待 HTML 完全加载和解析完成,不等待 CSS 文件、图片加载完成,也不等待 JavaScript 脚本异步执行完成。这通常会在 DOMContentLoaded 事件触发后立即发生。 none:仅等待页面开始加载,不等待任何其他内容加载完成。 使用 eager 或 none 加载策略时,页面上的某些元素可能尚未加载完成,因此在执行与这些元素相关的操作之前,可能需要实施额外的等待策略或检查元素的存在性: # 初始化 Chrome 选项 options = Options() # 设置页面加载策略为 'eager' caps = DesiredCapabilities().CHROME caps["pageLoadStrategy"] = "eager" # eager 或 none # 创建 WebDriver 实例 driver = webdriver.Chrome(desired_capabilities=caps, options=options) 这里详细开展讲述eager模式,很多场景可以直接用eager优化较多时间。设置页面加载策略为 eager 模式意味着 WebDriver 会等待 DOM(文档对象模型)加载完成后立即返回,而不必等待所有相关资源(如样式表、图片、子框架)的加载。一般依赖于页面上的静态资源(如图片和 CSS 文件),则使用 eager 模式可以加快执行速度,比如仅做基础文本页面数据爬虫。 eager优点是如果页面中某些资源加载时间过长,可能导致在 normal 模式下的测试因超时而失败。eager 模式可以减轻这种风险。但缺点也很明显,在 eager 模式下,一些通过 JavaScript 动态生成的元素可能尚未完全加载和渲染,导致自动化脚本可能无法与这些元素交互,可以先测试一下这种模式,确定无误之后可以再用。
禁用图片加载
禁用图片加载可以加快页面加载速度,减少网络流量消耗,适用于不依赖图片的任务,这不仅可以加快页面加载速度,还能减少网络带宽的使用,如果觉得eager一下关停很多加载的时候,如果你的任务不需要用到图片则就可以用此方法:
# 创建 Chrome 选项对象
chrome_options = webdriver.ChromeOptions()
# 禁用图片加载
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 启动带有自定义选项的 Chrome 浏览器
driver = webdriver.Chrome(options=chrome_options)
禁用JavaScript
禁用JavaScript 会影响网页的交互性和动态内容加载。确保任务不需要JavaScript 。Chrome 和 Firefox 等主流浏览器没有提供直接的配置选项来禁用 JavaScript。但是可以通过使用 DevTools Protocol来禁用 JavaScript:
options = Options()
driver = init_driver(options=options)
# 使用 DevTools Protocol 来禁用 JavaScript
driver.execute_cdp_cmd("Emulation.setScriptExecutionDisabled", {"value": True})
代码优化 page_source 在代码层面的优化一般都得懂selenium底层运行逻辑,比如解析HTML结构的顺序,查询元素的逻辑,举个简单的例子:我们经常会需要断言页面中的某个部分包含一些具体的文本,下面的语句的输出结果是相同的
driver.page_source driver.find_element(:tag_name => ‘body')
不过对于第二条语句来说,selenium需要去分析页面的结构,最后再找到对应的元素并输入结果,这显然是需要花费时间的。如果页面比较小的化,那么二者的差距可能不大,不过对于大的页面来说,第一条语句速度明显会更快一些。
Method 1: Search whole document text took 0.823076 seconds Method 2: Search whole document HTML took 0.039573 seconds
定位精确性
在 Selenium 中,元素的定位精确性可以影响获取元素文本(.text)的速度。:使用精确的选择器(如 ID、ClassName)通常会比使用较复杂的选择器(如 XPath、CSS 选择器)更快。这是因为精确的选择器可以更直接地定位到元素,而复杂的选择器可能需要遍历更多的 DOM 节点。
在使用 XPath 或 CSS 选择器时,最好使用尽可能短的路径。长的或复杂的路径会增加浏览器解析 DOM 的时间,在 XPath 中避免使用通配符(*),并尽量不要定位深层次的嵌套元素,因为这会增加查询的计算负担。每次与 DOM 的交互都会消耗时间,尤其是在复杂或大型的网页上。因此,尽量减少不必要的元素查找和交互。
缓存已查找的元素
对于频繁操作的元素,可以将其存储在变量中,避免重复查找。
# 第一次定位按钮并缓存它 cached_button = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "myButton"))) # 第一次点击按钮 cached_button.click()
需要注意的是,这种方法只适用于页面结构在整个会话中保持不变的情况。如果页面的DOM结构在操作过程中发生了变化(例如,页面部分刷新或完全重新加载),缓存的元素可能会变得过时(stale),此时尝试对其进行操作会导致 StaleElementReferenceException。
注意的是,这种方法只适用于页面结构在整个会话中保持不变的情况。如果页面的DOM结构在操作过程中发生了变化(例如,页面部分刷新或完全重新加载),缓存的元素可能会变得过时(stale),此时尝试对其进行操作会导致 StaleElementReferenceException。
requests库
requests是和urllib一样的作用。
文档:
官方文档:https://requests.readthedocs.io/projects/cn/zh-cn/latest/
快速上手:https://requests.readthedocs.io/projects/cn/zh-cn/latest/user/quickstart.html
安装: pip install requests
requests基本使用
import requests url = 'http://www.baidu.com' response = requests.get(url=url) # 设置响应编码格式 response.encoding = 'utf-8' # 一个类型和六个属性 print(type(response)) # 以字符串形式返回网页源码 print(response.text) # 返回url地址 print(response.url) # 返回二进制数据 print(response.content) # 返回状态码 print(response.status_code) # 返回响应头信息 print(response.headers) # 返回cookie print(response.cookies)
requests_get请求
import requests
url = 'http://www.baidu.com/s'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
data = {
'wd': '北京'
}
response = requests.get(url=url, params=data, headers=headers)
content = response.text
print(content)
# 参数使用params传递
# 参数不需要编码
# 不需要请求对象定制
# 请求资源中的路径中的?可以+也可以不加
requests_post请求
import requests
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
data = {
'kw': 'eye'
}
response = requests.post(url, data=data, headers=headers)
# 方式1:
content = response.json()
# 方式2
# content = response.text
# import json
# content = json.loads(content)
print(content)
# post请求不需要编解码
# post请求的参数是data
# 不需要请求对象的定制
requests代理
import requests
url = 'https://qifu-api.baidubce.com/ip/local/geo/v1/district?'
proxy = {
'http': '202.101.213.246:16331'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
response = requests.get(url=url, headers=headers, proxies=proxy)
content = response.text
print(content)
案例-图片验证码登录爬取
# 通过登录 进入主页面
import requests
from bs4 import BeautifulSoup
import ddddocr
"""
__VIEWSTATE: Mv2wWuOcKQjHhibEDggO2pdOqBFxk3NHo1tj+fAORgQgGvFk+5JdZR9tTCMb1pFwD0DSWcsy3xcnY2orOqrvIHcHMVq65HnzqsekMMogkxGRFzDiSAKb8bpFShCGcbnAFYpGQiBfL25DFJQWeylM8dqaUSs=
__VIEWSTATEGENERATOR: C93BE1AE
from: http://so.gushiwen.cn/user/collect.aspx
email: 自己的@qq.com
pwd: 密码
code: XE31
denglu: 登录
"""
# 登录页面url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
content = response.text
# 解析页面源码获取__VIEWSTATE __VIEWSTATEGENERATOR
soup = BeautifulSoup(content, "lxml")
state_value = soup.select("#__VIEWSTATE")[0].attrs.get('value')
state_generator_value = soup.select("#__VIEWSTATEGENERATOR")[0].attrs.get('value')
# 获取验证码图片
code = soup.select("#imgCode")[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn/RandCode.ashx' + code
print(code_url)
# 有坑
# import urllib.request
# urllib.request.urlretrieve(url=code_url, filename="code.jpg")
# requests中有一个方法session(),通过session的返回值,就能使请求变成一个对象
session = requests.session()
# 验证码url的内容
response_code = session.get(code_url)
# 此时要使用二进制数据
content_code = response_code.content
# wb模式就是将二进制数据写入到文件
with open("code.jpg", 'wb') as fd:
fd.write(content_code)
# 获取验证码的图片之后,下载到本地,在控制台输入验证码,然后将这个值给code参数就可以登录了
# code_name = input("请输入你的验证码:")
ocr = ddddocr.DdddOcr()
with open('code.jpg', 'rb') as f:
img_bytes = f.read()
code_name = ocr.classification(img_bytes)
print('识别出的验证码为:' + code_name)
# url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
# 这是post请求需要发送的参数,从浏览器复制下来
data_post = {
'__VIEWSTATE': state_value,
'__VIEWSTATEGENERATOR': state_generator_value,
'from': " http://so.gushiwen.cn/user/collect.aspx",
'email': "邮箱@qq.com",
'pwd': '密码',
'code': code_name,
'denglu': '登录'
}
response_post = session.post(url=url, headers=headers, data=data_post)
content_post = response_post.text
with open("gushiwen.html", 'w', encoding='utf-8') as fd:
fd.write(content_post)



url管理器

ddddocr库
ocr:光学字符识别。这是一个开源的第三方库,可以使用图片验证码
案例地址https://blog.csdn.net/weixin_58839230/article/details/124243584 项目地址:https://github.com/sml2h3/ddddocr
import ddddocr
ocr = ddddocr.DdddOcr()
with open('code.jpg', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
print('识别出的验证码为:' + res)
scrapy框架
教程:
从原理到实战,一份详实的 Scrapy 爬虫教程-CSDN博客
scrapy是什么? scrapy是一个未来爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或者存储历史数据等一系列的程序中
安装scrapy
pip install scrapy
scrapy基本使用
创建scrapy项目
在命令行中输入: scrapy startproject 项目名 项目名:不能使用数字开头,不能包含中文
创建的文件目录结构:
创建爬虫文件
在scrapy生成的项目中进入扫spiders文件夹创建爬虫文件
cd 项目名\项目名\spiders
创建爬虫文件
scrapy genspider 爬虫文件的名字 要爬取的网页
scrapy genspider baidu http://www.baidu.com
生成的文件:
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字
name = "baidu"
# 允许访问的域名
allowed_domains = ["www.baidu.com"]
# 起始的url地址,指的是第一次访问的域名
start_urls = ["http://www.baidu.com"]
# 是执行了start_url之后执行的方法,方法中的response就是返回的那个对象
# 相当于response= urllib.request.urlopen()
def parse(self, response):
print("张三是我")
# 运行爬虫代码
# scrapy crawl 爬虫的名字 (需要进入到spiders目录下)
# scrapy crawl baidu
# 爬取失败,因为有/robots.txt协议
# 在settings.py中进行注释
# ROBOTSTXT_OBEY = True
scrapy项目的结构
项目名字 项目名字 spider文件夹(存储爬虫文件) init 自定义的爬虫文件(重要) init items 定义数据结构的地方 爬取的数据都包含哪些 middleware 中间件, 代理 pipelines 管道 用来处理下载的数据 settings 配置文件 robots协议 ua定义等
response的属性和方法
response.text 获取的是响应的字符串
response.body 获取的是二进制数据
response.xpath 可以直接xpath方法来解析response中的内容
response.extract() 提取seletor对象那个的data属性值<class 'scrapy.selector.unified.Selector'>
response.extract_first() 提取seletor列表的第一个数据 <class 'scrapy.selector.unified.SelectorList'>
selector.get()现在get()方法也可以返回列表的第一个数据,get()是selector的方法
def parse(self, response):
# 字符串
# content = response.text
# print(content)
# 二进制数据
# b = response.body
# print(b)
span = response.xpath('//div[@id="filter"]/div[@class="tabs"]/a/span')[0]
print("&"*20)
print(type(span)) #<class 'scrapy.selector.unified.Selector'>
print(span) 现在直接输出span也是返回内容,和extract()输出的内容一样。
print(span.extract())
采集汽车之家
def parse(self, response):
a = response.xpath('//div[@id="tab2-1"]/dl[5]/dd/a[@name="a_struct"]/text()') # 这里查出来的是一个集合
print("#" * 30)
print(type(a))
print(a.extract_first()) # 获取selectorlist的第一个数据
for i in range(len(a)):
name = a[i].extract()
print("名字是:", name)
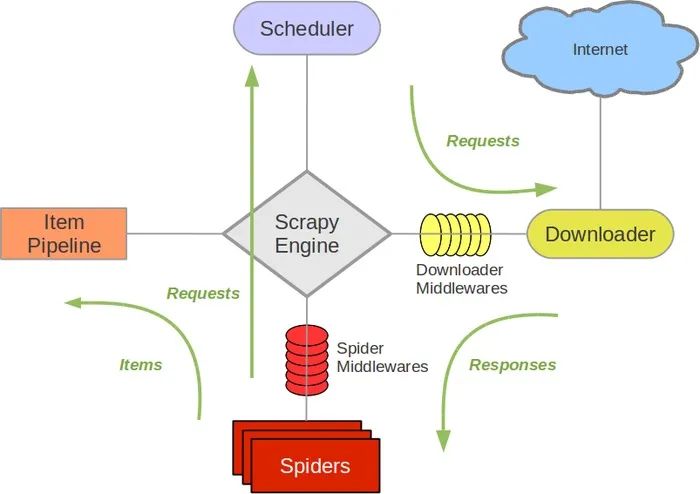
scrapy工作原理
scrapy shell
什么是scrapy shell?
scrappyshell是一个交互式shell,您可以在其中快速调试 scrape 代码,而不必运行spider。它本来是用来测试数据提取代码的,但实际上您可以使用它来测试任何类型的代码,因为它也是一个常规的Python外壳。
shell用于测试xpath或css表达式,并查看它们是如何工作的,以及它们从您试图抓取的网页中提取的数据。它允许您在编写spider时交互地测试表达式,而不必运行spider来测试每个更改。
https://www.osgeo.cn/scrapy/topics/shell.html
使用scrapy shell
命令行界面中输入scrapy shell 域名
进入到界面中直接使用response
response.body
response.text
response.xpath('xx')
scrapy当当网案例
爬取当当网图片的图片,价格,标题信息
items 定义数据结构的地方 爬取的数据都包含哪些
items.py
items.py文件是用于定义数据结构,就是指要爬取的东西是哪些
class ScrapyDang33Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 就是要下载的东西有什么
# 图片
src = scrapy.Field()
# 名字
name = scrapy.Field()
# 价格
price = scrapy.Field()
在主程序中导入items的类
import scrapy
from .. import items
class DangSpider(scrapy.Spider):
name = "dang"
allowed_domains = ["bang.dangdang.com"]
start_urls = ["http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1"]
def parse(self, response):
# pipelines 下载数据
src = "//ul[@class='bang_list clearfix bang_list_mode']/li//img/@src"
alt = "//ul[@class='bang_list clearfix bang_list_mode']/li//img/@alt"
price = "//ul[@class='bang_list clearfix bang_list_mode']/li/div[@class='price']/p/span[1]/text()"
# 所有selector对象都可以再次调用xpath对象
li_list = response.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li")
print("(((((((((((((((((((((((((((((((")
for li in li_list:
print(type(li)) # <class 'scrapy.selector.unified.Selector'>
src = li.xpath(".//img/@src").extract_first()
name = li.xpath(".//img/@alt").extract_first()
price = li.xpath(".//div[@class='price']/p/span[1]/text()").extract_first()
book = items.ScrapyDang33Item(src=src, name=name, price=price)
# 将这个对象交个pipelines下载
yield book
yield关键字作用
在 Scrapy 中,yield 语句用于生成一个 Request 或 Item 对象,并将其提交给 Scrapy 引擎进行处理。这个对象可以是一个需要下载的新页面的请求(Request),或者是从当前页面中提取的数据条目(Item)。 具体来说,在爬虫代码中,yield 通常用于以下两个方面: 在解析函数中生成 Item 对象,用于将爬取到的数据保存到数据库或者文件中。 在解析函数中生成 Request 对象,用于构造下一次请求。当爬虫解析完一个页面后,需要根据页面内容构造出下一次请求并发送给服务器。这时可以使用 yield 语句生成新的 Request 对象,并将其交给Scrapy 引擎处理。 1.带有yield的函数不是一个普通函数,而是一个generator,可以用来迭代 2.yield是一个类似return的关键字,迭代一次遇到yield时就返回yield后面的值。重点:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行 3.简要理解:yield就是一个return 返回一个值,并且记住这个返回的位置,下一次迭代就从这个位置后(下一行)开始:
yield关键字将对象交给管道了,我们需要打开管道,需要在settings中开启管道。(解开注释)
ITEM_PIPELINES = {
# 管道是可以有很多个的,那么挂到是有优先级的1-1000,值越小优先级越高
"scrapy_dang_33.pipelines.ScrapyDang33Pipeline": 300,
}
pipelines.py
该文件用于下载
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# 如果想使用管道必须在settings中开启
class ScrapyDang33Pipeline:
# 在爬虫文件开始之前执行的方法(方法名是固定的)
def open_spider(self, spider):
self.fd = open('book.json', 'a', encoding='utf-8')
# item就是yield后面传递过来的对象
def process_item(self, item, spider):
# 以下模式不推荐,使用文件操作过去频繁
# print("种类是pipelines:", type(item))
# # write方法必须写入一个字符串而不是其他对象
# with open('book.json', 'a', encoding='utf-8') as fd:
# fd.write(str(item))
# return item
self.fd.write(str(item))
# 在爬虫文件执行之后开始执行的
def close_spider(self, spider):
self.fd.close()
多管道下载
多管道下载就是在单管道的基础上增加class作为管道类,定义方法process_item,这个方法框架自己调用。
管道1
# 如果想使用管道必须在settings中开启
class ScrapyDang33Pipeline:
# 在爬虫文件开始之前执行的方法
def open_spider(self, spider):
self.fd = open('book.json', 'a', encoding='utf-8')
# item就是yield后面传递过来的对象
def process_item(self, item, spider):
# 以下模式不推荐,使用文件操作过去频繁
print("种类是pipelines:", type(item))
# # write方法必须写入一个字符串而不是其他对象
# with open('book.json', 'a', encoding='utf-8') as fd:
# fd.write(str(item))
# return item
self.fd.write(str(item))
return item
# 在爬虫文件执行之后开始执行的
def close_spider(self, spider):
self.fd.close()
import urllib.request
管道2
# 开启多条管道
# 定义管道类
# 在settings中开启管道
# "scrapy_dang_33.pipelines.ScrapyDangDang33Pipeline": 301,
class DangDangloadPipeline:
def process_item(self, item, spider):
print("item的信息是:", item)
url = item.get('src')
filename = item.get('name')
filename = './图片/'+filename + '.jpg'
urllib.request.urlretrieve(url=url, filename=filename)
return item
在settings中开启管道
ITEM_PIPELINES = {
# 管道是可以有很多个的,那么挂到是有优先级的1-1000,值越小优先级越高
"scrapy_dang_33.pipelines.ScrapyDang33Pipeline": 300,
# 开启:DangDangloadPipeline
"scrapy_dang_33.pipelines.DangDangloadPipeline": 301,
}
多页数据的下载-分页式
在主程序中定义
不同的页面地址只是略微不同,稍微修改一下url之后重复执行parse即可完成
class DangSpider(scrapy.Spider):
name = "dang"
# 如果是多页下载,必须调整allowed_domains的范围,一般只写域名
allowed_domains = ["bang.dangdang.com"]
start_urls = ["http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1"]
base_url = "http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-"
page = 1
def parse(self, response):
# pipelines 下载数据
src = "//ul[@class='bang_list clearfix bang_list_mode']/li//img/@src"
alt = "//ul[@class='bang_list clearfix bang_list_mode']/li//img/@alt"
price = "//ul[@class='bang_list clearfix bang_list_mode']/li/div[@class='price']/p/span[1]/text()"
# 所有selector对象都可以再次调用xpath对象
li_list = response.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li")
for li in li_list:
print(type(li)) # <class 'scrapy.selector.unified.Selector'>
src = li.xpath(".//img/@src").extract_first()
name = li.xpath(".//img/@alt").extract_first()
price = li.xpath(".//div[@class='price']/p/span[1]/text()").extract_first()
# 将我们爬取下来的数据封装成对象ScrapyDang33Item
book = items.ScrapyDang33Item(src=src, name=name, price=price)
print("爬取下来的数据:", type(book))
# 将这个对象交个pipelines下载
yield book
# 每一页的爬取单的业务逻辑都是用于的,我们只需要将执行那个页的请求再次调用parse方法就可以
# http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1
# http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-2
# http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-3
if self.page < 25:
self.page = self.page + 1
url = self.base_url + str(self.page)
# 怎么调用parse方法
# scrapy.Request就是scrapy的get请求
# url就是请你地址,page就是要执行的函数
yield scrapy.Request(url=url, callback=self.parse)
豆瓣爬取多页数据
from typing import Iterable
import scrapy
from scrapy import Selector, Request # 第二种方式要导包
from scrapy_douban.items import MoveItem
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["movie.douban.com"]
start_urls = ["https://movie.douban.com/top250"]
#方式2
#去掉start_urls,定义一个函数,函数返回每一个要爬取的url的地址,这样起始页就不是一个而是一组。我们将每一组的页面都执行 parse函数中的操作。得到的就是250条电影榜单的数据
def start_requests(self) -> Iterable[Request]: # ->定义返回值类型
for page in range(10):
yield Request(url=f'https://movie.douban.com/top250?start={page * 25}&filter=')
# def start_requests(self):
# for page in range(10):
# yield Request(url=f'https://movie.douban.com/top250?start={page * 25}&filter=')
def parse(self, response):
sel = Selector(response)
list_item = sel.xpath("//div[@class='item']/div[@class='pic']")
for li in list_item:
rank = li.xpath('./em/text()').get()
title = li.xpath("./a/img/@alt").get()
pic = li.xpath("./a/img/@src").get()
move = MoveItem(rank=rank, title=title, pic=pic)
yield move
# 解析新的url,方式1
#这种方式是在每一页的下面找到链接地址,得到每一页的链接地址,并将这个链接封装成Request返回,由框架处理。
#框架不会处理已经爬取过的地址,但是一般情况下第一页都有两个地址,所以会多爬取一次。第二种方式可以解决这种问题。
# href_list = sel.xpath("//div[@class='paginator']/a")
# for href in href_list:
# href = href.xpath('./@href').get()
# url = response.urljoin(href)
# yield Request(url=url)
电影天堂多页数据下载-嵌套式
我们先建立好项目:网站名字叫做樱花动漫。
我们的需求是爬取首页的图片以及图片点击之后进入的第二个页面的标题。
如图:
这是首页,我们需要将首页的图片爬取下来
这是第一个图片点击之后进入的页面,我们要将这个页面的标题爬取下来
主程序.py
import scrapy
from .. import items
class MvSpider(scrapy.Spider):
name = "mv"
allowed_domains = ["www.ddcomic.com"]
start_urls = ["https://www.ddcomic.com/"]
def parse(self, response):
#将爬取下来的页面写入test.html文件中,看看是否爬取成功
with open("test.html", 'w', encoding='utf-8') as fd:
fd.write(response.text)
#通过xpath找到首页指定的位置:图片地址和下一页的链接地址
a_list = response.xpath('//div[@class="module-items module-poster-items-base"]/a')
print('大叫好我飞机撒开机', a_list.extract_first())
print('大叫好我飞机撒开机', type(a_list))
# 爬取下来的是seletorlist集合,我们遍历这个集合得到每一个seletor对象,在这个对象里面就封装了我们需要的数据
for a in a_list:
# 第一页的图片地址和第二页的url
#selector对象是可以使用xpath的,我们通过xpath取到图片和链接地址
href = a.xpath('./@href').extract_first()
img = a.xpath("./div//div[@class='module-item-pic']/img/@data-original").extract_first()
# 第二页的地址 因为得到的地址是没有前缀的,所以需要手动加入
url = 'https://www.ddcomic.com' + href
# 对第二页发起访问 这个就是调用第二页也就是下面这个方法,meta可以将本方法中的数据传递到下一个方法中
yield scrapy.Request(url=url, callback=self.parse_scond, meta={'img': img})
#这个方法用来处理第二个页面中的内容
def parse_scond(self, response):
#在这里我们操作的就是第二个页面了,定位到第二个页面的标题的位置,将其读取出来
name = response.xpath('//div[@class="module-info-heading"]/h1/text()').extract_first()
print("第二页的标题名", name)
# 接收从第一个方法传递过来meta中的值
img = response.meta['img']
print('img的值是',img,'name的值是',name)
#将数据封装成一个对象返回给管道
movie = items.ScrapyDytt34Item(img=img, name=name)
# 将move返回给管道
yield movie
在settings.py中开启管道
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"scrapy_dytt_34.pipelines.ScrapyDytt34Pipeline": 300,
}
在pipelines.py文件中处理数据
pipelines 管道 用来处理下载的数据
class ScrapyDytt34Pipeline:
def open_spider(self,spider):
self.fd = open('move.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fd.write(str(item))
return item
def close_spider(self,spider):
self.fd.close()
将豆瓣top250数据写入excel文件
创建scrapy项目
scrapy startproject douban_scrapy
进入到spiders文件夹下,创建spider文件,指定要爬取的网页的起始地址
scrapy genspider douban https://movie.douban.com/top250
创建成功之后使用pycharm打开,每一个项目应该有自己的专属虚拟环境,每一个项目都要有自己的包,不要项目里面嵌套项目。
添加项目的虚拟环境,每一个项目都要有自己打的虚拟环境,在pycharm项目的setting中,找到Python Interpreter,选择添加interpreter
点击Add Interpreter之后发现新的环境没有依赖项,我们将本项目需要的依赖项目导入即可
打开终端,默认会自动激活虚拟环境,在这里安装依赖项
在虚拟环境中安装scrapy
pip install scrapy
安装成功即可开始我们的项目了。
关闭君子协议
在settings中设置UA
USER_AGENT = "User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
运行项目查看是否能够正常运行
scrapy crawl douban
如果运行正常则开始爬取数据
在items中定义数据结构
class MoveItem(scrapy.Item):
# define the fields for your item here like:
rank = scrapy.Field()
pic = scrapy.Field()
move_name = scrapy.Field()
describe = scrapy.Field()
在主文件中通过xpath进行爬取
def parse(self, response):
# 方式1
# sc = Selector(response)
# sc.xpath()
# 方式2
move_list = response.xpath("//ol[@class='grid_view']//div[@class='item']")
for move in move_list:
rank = move.xpath('./div[@class="pic"]/em/text()').extract_first()
pic = move.xpath('./div[@class="pic"]/a/img/@src').extract_first()
move_name = move.xpath('./div[@class="pic"]/a/img/@alt').extract_first()
describe = move.xpath('./div[@class="info"]//p[@class="quote"]/span/text()').extract_first()
# 封装成items对象,并返回给管道
yield items.MoveItem(rank=rank, pic=pic, move_name=move_name, describe=describe)
运行命令,以csv文件的形式输出结果
scrapy crawl douban -o douban.csv
这只是爬取了一页的数据,我们要爬取所有页面的数据
在parse方法中定义下一页的url地址,将其返回,由框架自己爬取下一页
def parse(self, response):
# 方式2
move_list = response.xpath("//ol[@class='grid_view']//div[@class='item']")
for move in move_list:
rank = move.xpath('./div[@class="pic"]/em/text()').extract_first()
pic = move.xpath('./div[@class="pic"]/a/img/@src').extract_first()
move_name = move.xpath('./div[@class="pic"]/a/img/@alt').extract_first()
describe = move.xpath('./div[@class="info"]//p[@class="quote"]/span/text()').extract_first()
# 封装成items对象,并返回给管道
yield items.MoveItem(rank=rank, pic=pic, move_name=move_name, describe=describe)
# 爬取每一页的数据
# 找到下一页的链接地址
next_url = response.xpath('//div[@class="paginator"]/a/@href')
# 构造出Request,将这个Request返回
for url in next_url:
# 拼接url
# url = "https://movie.douban.com/top250" + url.extract()
url = response.urljoin(url.extract())
# 将url写入Request中并返回
print(url)
yield scrapy.Request(url=url)
再次输入运行命令,结果中将其他页面的数据也会爬取出来。出现一个问题,因为首页的url有两个,所以会被爬取两次,出现多余数据。如果页面爬取过了调度器会管理,不会再爬取这些重复的页面。
scrapy crawl douban -o douban.csv
处理爬取多余数据的方式
方式1:修改起始url,将其定义成和其他url一样的格式(没成功)
https://movie.douban.com/top250
修改成
https://movie.douban.com/top250?start=0&filter=
方式2:定义可变的起始url,通过scrapy中的方法
删除原来的 start_urls = ["https://movie.douban.com/top250?start=0&filter="
自定义start_rquest方法,返回Request
def start_requests(self) -> Iterable[Request]:
for i in range(10):
url = f"https://movie.douban.com/top250?start={i*25}&filter="
print(url)
yield scrapy.Request(url=url)
在管道中定义写入excel的操作
下载openpyxl库
pip install openpyxl
导入库,定义方法进行写入操作
import openpyxl
# 写入excel表中
class DoubanScrapyPipeline:
def __init__(self):
self.wb = openpyxl.Workbook() # 打开工作蒲
self.ws = self.wb.active # 激活工作表
self.ws.append(('排名', '图片', '标题', '描述', '前言')) # 定义表格头
def process_item(self, item, spider):
# 获取到对应的数据
rank = item.get('rank', "")
pic = item.get('pic', "")
title = item.get('title', "")
describe = item.get('describe', "")
intro = item.get('intro', "")
# 写入excel表
self.ws.append((rank, pic, title, describe, intro))
return item
def close_spider(self, spider):
# 保存数据
self.wb.save("电影表单.xlsx")
开启管道:
ITEM_PIPELINES = {
"douban_scrapy.pipelines.DoubanScrapyPipeline": 300,
}
运行项目
scrapy crawl douban
爬取内页
在上面的基础上增加处理内页的方法,并且修改items中的数据结构,增加内页的数据
class MoveItem(scrapy.Item):
# define the fields for your item here like:
rank = scrapy.Field()
pic = scrapy.Field()
title = scrapy.Field()
describe = scrapy.Field()
intro = scrapy.Field()
from typing import Iterable
import scrapy
from scrapy import Request
from douban_scrapy.items import MoveItem
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["movie.douban.com"]
def start_requests(self) -> Iterable[Request]:
for i in range(10):
url = f'https://movie.douban.com/top250?start={i * 25}&filter='
yield Request(url=url)
def parse(self, response):
div_list = response.xpath("//ol[@class='grid_view']//div[@class='item']")
for li in div_list:
moveItem = MoveItem()
rank = li.xpath("./div[@class='pic']/em/text()").get()
pic = li.xpath("./div[@class='pic']/a/img/@src").get()
title = li.xpath("./div[@class='info']/div[@class='hd']/a/span[1]/text()").get()
describe = li.xpath('./div[@class="info"]//p[@class="quote"]/span/text()').extract_first()
# 内页的地址
inner_url = li.xpath("./div[@class='info']/div[@class='hd']/a/@href").get()
moveItem['rank'] = rank
moveItem['pic'] = pic
moveItem['title'] = title
moveItem['describe'] = describe
# 将内页的url地址以及本页获取到的数据传递给下一个方法处理
yield Request(url=inner_url, callback=self.second_parse, cb_kwargs={"moveItem": moveItem})
# 这也是一个钩子函数,这里处理内页
def second_parse(self, response, **kwargs):
# link - report - intra
intro = response.xpath('//div[@id="link-report-intra"]//span[@property="v:summary"]/text()').get()
print("fdsfasfasfzahngsa=====",type(intro))
print("fdsfasfasfzahngsa=====",intro)
intro = intro.strip()
moveItem = kwargs['moveItem']
moveItem['intro'] = intro
yield moveItem
将豆瓣top250数据写入数据库
在上面的基础上定义一个管道,将数据写入到数据库中
class DBSpiderPipeline:
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', password='root', database='spider',
charset='utf8')
# 获取游标
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
rank = item.get('rank', 0)
pic = item.get('pic', "")
move_name = item.get('move_name', "")
describe = item.get('describe', "")
sql = f'insert into tb_top_movie() values("{rank}","{pic}","{}","{describe}")'
print(sql)
self.cursor.execute(sql)
return item
def close_spider(self, spider):
self.conn.commit()
self.cursor.close()
self.conn.close()
批处理写入数据库
上面的代码中每次获取到数据之后立即就保存在数据库中,这样增加了IO操作,影响效率。可以使用批处理的方式,一批一批传入数据库
class DBSpiderPipeline:
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', password='root', database='spider',
charset='utf8')
# 获取游标
self.cursor = self.conn.cursor()
#定义一个列表,用于存储数据
self.data = []
def process_item(self, item, spider):
rank = item.get('rank', 0)
pic = item.get('pic', "")
move_name = item.get('move_name', "")
describe = item.get('describe', "")
# 将数据加入到列表
self.data.append((rank, pic, move_name, describe))
# 当列表中的数据等于100的时候在执行插入数据库的操作
if len(self.data) == 100:
self._writer_database()
#提交成功之后清空列表中的数据
self.data.clear()
return item
def _writer_database(self):
# 定义批处理的插入方式
sql = 'insert into tb_top_movie() values(%s,%s,%s,%s)'
self.cursor.executemany(sql, self.data)
self.conn.commit()
def close_spider(self, spider):
# 爬取完成之后剩余的数据不够100条也将剩下的数据全部插入到数据库中。
if self.data > 0:
self._writer_database()
self.conn.commit()
self.cursor.close()
self.conn.close()
IP代理
方式1:在主文件中的Request请求中有一个mate属性,这个属性的属性值是一个字典。我们可以在请求中添加代理。使用vpn代理。
def start_requests(self) -> Iterable[Request]:
for i in range(10):
url = f"https://movie.douban.com/top250?start={i * 25}&filter="
print(url)
yield scrapy.Request(url=url, meta={'proxy': 'http://36.6.144.237:8089'})
方式2:在中间件文件中进行编写,找到middlewares.py中的class:DownloaderMiddleware -process_request(),这是一个钩子函数,可以使用该方法的request参数进行代理操作。
def process_request(self, request: Request, spider):
request.meta={'proxy':''}
return None
下载中间件的使用(代理+cookie)
如果我们登录之后得到cookie,一般网站就不会进行拦截了。我们将cookie带入scrapy,在中间件中模拟用户cookie登录。
第一种方式:在请求中添加cookie
def start_requests(self) -> Iterable[Request]:
for i in range(10):
url = f"https://movie.douban.com/top250?start={i * 25}&filter="
print(url)
yield scrapy.Request(url=url, cookies='sdfasf')
方式2:采用中间件方式,在中间件类中定义下面的方法
# 对cookie进行切分,以下是一个完整的cookie,通过;分割之后得到了xxx=xxx的形式,之后我们再通过=进行切分得到字典的形式返回。
UM_distinctid=18f0fd2c56ce0-02bba1091bf484-3e604809-1fa400-18f0fd2c56ded; _ati=4722370614660; first_visited=1; search_history_goods=; CNZZDATA1257041518=1091661087-1713957422-https%253A%252F%252Fwww.baidu.com%252F%7C1714266828; _wsy_=6c3f423e5007049ef688887dcd1ac777; usertype=1; city_temp=%E5%BC%A0%E5%AE%B6%E7%95%8C; CATEGORYPID-SITE_ID:1=30; HOMEPTYPE-SITE_ID:1=30; SERVERID=f09c0b3a9e5f2e01aa660a75953d5877|1715090761|1715090760
def get_cookie_dict():
cookies_str = 'UM_distinctid=18f0fd2c56ce0-02bba1091bf484-3e604809-1fa400-18f0fd2c56ded; _ati=4722370614660; first_visited=1; search_history_goods=; CNZZDATA1257041518=1091661087-1713957422-https%253A%252F%252Fwww.baidu.com%252F%7C1714266828; _wsy_=6c3f423e5007049ef688887dcd1ac777; usertype=1; city_temp=%E5%BC%A0%E5%AE%B6%E7%95%8C; '
cookies_dict={}
for item in cookies_str.split(';'):
key,value = item.split('=',maxsplit=1)
cookies_dict[key] =value
return cookies_dict
在DownloaderMiddleware中的process_request方法中进行配置
COOKIES_DICT = get_cookie_dict()
def process_request(self, request: Request, spider):
request.cookies=COOKIES_DICT
return None
在settings中进行配置,中间件和管道一样都需要进行配置。
DOWNLOADER_MIDDLEWARES = {
"douban_scrapy_spider.middlewares.DoubanScrapySpiderDownloaderMiddleware": 543,
}
值越小越先执行
完整案例
from typing import Iterable
import scrapy
from scrapy import Selector, Request
from scrapy_douban.items import MoveItem
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["movie.douban.com"]
start_urls = ["https://movie.douban.com/top250"]
def start_requests(self) -> Iterable[Request]:
for page in range(10):
yield Request(url=f'https://movie.douban.com/top250?start={page * 25}&filter=')
def parse(self, response, **kwargs):
sel = Selector(response)
list_item = sel.xpath("//div[@class='item']/div[@class='pic']")
for li in list_item:
rank = li.xpath('./em/text()').get()
title = li.xpath("./a/img/@alt").get()
pic = li.xpath("./a/img/@src").get()
move = MoveItem(rank=rank, title=title, pic=pic)
yield move
items.py
import scrapy
class MoveItem(scrapy.Item):
rank = scrapy.Field()
title = scrapy.Field()
pic = scrapy.Field()
pipelines.py
在settings中开启管道之后
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
"""
钩子函数(方法)-->回调方法(函数)-->callback
这些都不是我们调用的,都是scrapy框架来调用。
"""
import openpyxl
class ScrapyDoubanPipeline:
def __init__(self):
self.wb = openpyxl.Workbook() # 创建工作簿,一个excel里面有很多工作表
self.ws = self.wb.active # 激活工作表
self.ws.title = 'Top250'
self.ws.append(('排名', '标题', '图片地址'))
def process_item(self, item, spider):
# self.ws.append((item['rank'], item['title'], item['pic']))
rank = item.get('rank', "")
title = item.get('title', "")
pic = item.get('pic', "")
self.ws.append((rank, title, pic))
return item
# 关闭爬虫的方法(这个固定的方法名)
def close_spider(self, spider):
self.wb.save('电影数据.xlsx')
yield的作用
在 Scrapy 中,yield 语句用于生成一个 Request 或 Item 对象,并将其提交给 Scrapy 引擎进行处理。这个对象可以是一个需要下载的新页面的请求(Request),或者是从当前页面中提取的数据条目(Item)。 具体来说,在爬虫代码中,yield 通常用于以下两个方面: 在解析函数中生成 Item 对象,用于将爬取到的数据保存到数据库或者文件中。 在解析函数中生成 Request 对象,用于构造下一次请求。当爬虫解析完一个页面后,需要根据页面内容构造出下一次请求并发送给服务器。这时可以使用 yield 语句生成新的 Request 对象,并将其交给Scrapy 引擎处理。 地址:https://blog.csdn.net/weixin_41657089/article/details/130852772
输出依赖清单项
查看清单
pip list 或者 pip freeze
输出依赖清单
pip freeze > requirements.txt
根据清单安装依赖
pip install -r requirements.txt
crawlspider
链接提取器,可以定义规则将页面中的所有链接提取出来。
演示
打开scrapy shell 网址
提取链接提取器可以提取当前页面中所有符合规则的链接 from scrapy.linkextractors import LinkExtractor #正则表达式 # \d:表示数字 +表示1到多个数字 link = LinkExtractor(allow=r'/play/4483-1-\d+\.html') #输出 link.extract_linke(response) #xpath方式 link1 = LinkExtractor(restrict_xpaths="//div[@class='module-play-list']/div/a/@href") #输出 link.extract_linke(response)
crawlSpider案例
需求读书网数据入库
创建项目:scrapy startproject dushuproject
跳转到spiders路径
创建爬虫类:scrapy genspider -t crawl 项目名 爬取的域名https://www.dushu.com/book/1188.html
items
spiders
settings
pipelines
数据保存到本地
数据保存到mysql数据库
案例:爬取每一页的读书网图片和名字
创建项目之后,在主文件中
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from .. import items
class ReadSpider(CrawlSpider):
name = "read"
allowed_domains = ["www.dushu.com"]
# 这是需要写的和其他页面一样,包含第一页,不然爬取的时候不会爬取第一页
start_urls = ["https://www.dushu.com/book/1188_1.html"]
# /book/1188_2.html ,正则表达式,页面地址
rules = (Rule(LinkExtractor(allow=r"/book/1188_\d+\.html"), callback="parse_item", follow=False),)
def parse_item(self, response):
# xpath编写地址
img_list = response.xpath("//div[@class='book-info']//a/img")
for img in img_list:
name = img.xpath('./@data-original').extract_first()
src = img.xpath('./@alt').extract_first()
book = items.ScrapyRead35Item(name=name,src=src)
#返回给管道
yield book
items.py中定义要爬取的数据的结构
class ScrapyRead35Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()
在settings中开启管道之后定义管道
class ScrapyRead35Pipeline:
def open_spider(self, spider):
self.fd = open('book.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fd.write(str(item))
return item
def close_spider(self, spider):
self.fd.close()
scrapy数据写入数据库
需要pymysql库 创建数据库数据表,数据表中的数据要和items文件中的数据保持一致
在settings中定义数据库的相关配置
DB_HOST = 'localhost' DB_POST = 3306 DB_USER = 'root' DB_PASSWORD = 'root' # 数据库名字 DB_NAME = 'spider01' # 字符编码 DB_CHARSET = 'utf8'
在pipelines文件中下载数据执行数据库操作
在管道文件中定义我们自己的管道
class MysqlPipeline:
def open_spider(self, spider):
def process_item(self, item, spider):
return item
def close_spider(self, spider):
在settings中将自己的管道加入的配置中。
ITEM_PIPELINES = {
"scrapy_crawlspider_dushu36.pipelines.ScrapyCrawlspiderDushu36Pipeline": 300,
"scrapy_crawlspider_dushu36.pipelines.MysqlPipeline": 301,
}
在自己管道中定义执行数据库相关操作
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class ScrapyCrawlspiderDushu36Pipeline:
def open_spider(self, spider):
self.fd = open("read.json", 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fd.write(str(item))
return item
def close_spider(self, spider):
self.fd.close()
# 加载settings中的文件
from scrapy.utils.project import get_project_settings
-----------------------这里是自定义的管道用于操作数据库-----------------------------------
class MysqlPipeline:
def open_spider(self, spider):
settings = get_project_settings()
# 从settings中取到相关配置赋值给我们的属性
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.password = settings['DB_PASSWORD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(host=self.host, port=self.port, user=self.user,
password=self.password, db=self.name, charset=self.charset)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = 'insert into book(name,src) values("{}","{}")'.format(item['name'], item['src'])
# 执行sql
self.cursor.execute(sql)
# 提交
self.conn.commit()
return item
# 关闭数据库
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
执行数据就能爬取13页的数据并且将其添加到数据库中
在主配置文件中,将follow设置成为True,可以爬取所分页码中所有的数据。超过13页
rules = (Rule(LinkExtractor(allow=r"/book/1188_\d+\.html"), callback="parse_item", follow=True),)
这里的follow表示是否跟进,就是按照提前连续规则进行提取
将数据输出到文本文件中
import scrapy
from scrapy import Selector
from scrapy_douban.items import MoveItem
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["movie.douban.com"]
start_urls = ["https://movie.douban.com/top250"]
def parse(self, response):
sel = Selector(response)
list_item = sel.xpath("//div[@class='item']/div[@class='pic']")
for li in list_item:
rank = li.xpath('./em/text()')
title = li.xpath("./a/img/@alt").get()
pic = li.xpath("./a/img/@src").get()
#爬取到数据后封装成item对象,直接返回
move = MoveItem(rank=rank, title=title, pic=pic)
yield move
在运行的时候输出
scrapy crawl douban -o douban.csv
支持的文件有:('json', 'jsonlines', 'jsonl', 'jl', 'csv', 'xml', 'marshal', 'pickle')
scrapy的日志信息和日志等级
在settings中进行设置
# 指定日志级别:(我们一般不改变),改变日志等级如果错误无法看到 # LOG_LEVEL = 'WARNING' #我们一般采用日志文件的方式,将日志输出到文件中 LOG_FILE = 'logdemo.log'
运行不要输出日志
scrapy crawl douban --nolog
scrapy的post请求
import scrapy
import json
class TestpostSpider(scrapy.Spider):
name = "testpost"
allowed_domains = ["fanyi.baidu.com"]
# post请求没有参数会报错
# post请求和start_urls 和parse方法没有任何关系
# start_urls = ["https://fanyi.baidu.com/sug"]
# def parse(self, response):
# pass
#post请求必须
def start_requests(self):
url = "https://fanyi.baidu.com/sug"
data = {
'kw': 'final'
}
# 发送请求
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second)
def parse_second(self, response):
# 这里的response就是执行了上面的url的返回结果
# 方式1
# obj = response.json()
# 方式2 使用json方式
content = response.text
obj = json.loads(content)
print(obj)
scrapy中的settings项
# 设置代理UA USER_AGENT = r"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)" #设置并发数量(默认16) CONCURRENT_REQUESTS = 32 #下载延迟 DOWNLOAD_DELAY = 3 #随机延迟 RANDOMIZE——DOWNLOAD_DELAY =True















 59万+
59万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









